Azure Databricks kümeleri için bölgesel olağanüstü durum kurtarma
Bu makalede, Azure Databricks kümeleri için yararlı olan olağanüstü durum kurtarma mimarisi ve bu tasarımı gerçekleştirme adımları açıklanmaktadır.
Azure Databricks mimarisi
Azure portalından bir Azure Databricks çalışma alanı oluşturduğunuzda, yönetilen bir uygulama aboneliğinizde seçilen Azure bölgesinde (örneğin, Batı ABD) bir Azure kaynağı olarak dağıtılır. Bu alet, aboneliğinizde kullanılabilen bir Ağ Güvenlik Grubu ve Azure Depolama hesabı olan bir Azure Sanal Ağ dağıtılır. Sanal ağ, Databricks çalışma alanına çevre düzeyi güvenlik sağlar ve ağ güvenlik grubu aracılığıyla korunur. Çalışma alanında çalışan ve sürücü VM türü ile Databricks çalışma zamanı sürümünü sağlayarak Databricks kümeleri oluşturursunuz. Kalıcı veriler depolama hesabınızda kullanılabilir. Küme oluşturulduktan sonra, işleri belirli bir kümeye ekleyerek not defterleri, REST API'leri veya ODBC/JDBC uç noktaları aracılığıyla çalıştırabilirsiniz.
Databricks denetim düzlemi Databricks çalışma alanı ortamını yönetir ve izler. Küme oluşturma gibi tüm yönetim işlemleri denetim düzleminden başlatılır. Zamanlanmış işler gibi tüm meta veriler bir Azure Veritabanı'nda depolanır ve veritabanı yedeklemeleri otomatik olarak uygulandığı eşleştirilmiş bölgelere coğrafi olarak çoğaltılır.
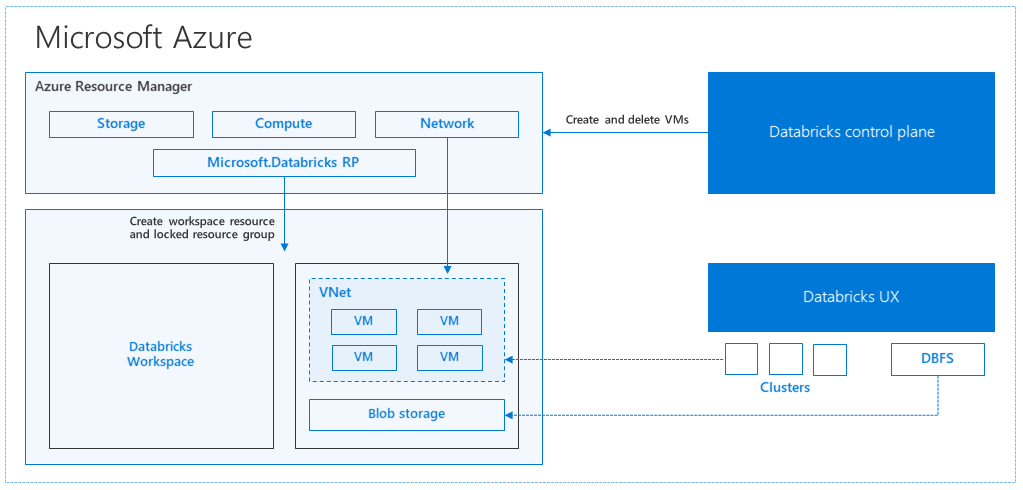
Bu mimarinin avantajlarından biri, kullanıcıların Azure Databricks'i hesaplarındaki herhangi bir depolama kaynağına bağlayabilmesidir. Önemli bir avantaj, hem işlem (Azure Databricks) hem de depolamanın birbirinden bağımsız olarak ölçeklendirilmesidir.
Bölgesel olağanüstü durum kurtarma topolojisi oluşturma
Önceki mimari açıklamasında Azure Databricks ile Büyük Veri işlem hattı için kullanılan bir dizi bileşen vardır: Azure Depolama, Azure Veritabanı ve diğer veri kaynakları. Azure Databricks, Büyük Veri işlem hattının işlem hattıdır. Bu kısa ömürlüdür, yani verileriniz Azure Depolama'de kullanılabilir durumdayken, ihtiyacınız olmadığında işlem için ödeme yapmaktan kaçınmak için işlem (Azure Databricks kümesi) sonlandırılabilir. İşlerin yüksek gecikme süresi yaşamaması için işlem (Azure Databricks) ve depolama kaynaklarının aynı bölgede olması gerekir.
Kendi bölgesel olağanüstü durum kurtarma topolojinizi oluşturmak için şu gereksinimleri izleyin:
Ayrı Azure bölgelerinde birden çok Azure Databricks çalışma alanı sağlayın. Örneğin, Doğu ABD'de birincil Azure Databricks çalışma alanını oluşturun. İkincil olağanüstü durum kurtarma Azure Databricks çalışma alanını Batı ABD gibi ayrı bir bölgede oluşturun. Eşleştirilmiş Azure bölgelerinin listesi için bkz . Bölgeler arası çoğaltma. Azure Databricks bölgeleri hakkında ayrıntılı bilgi için bkz . Desteklenen bölgeler.
Coğrafi olarak yedekli depolama kullanın. Varsayılan olarak, Azure Databricks ile ilişkili veriler Azure Depolama'de depolanır ve Databricks işlerinden elde edilen sonuçlar Azure Blob Depolama depolanır, böylece işlenen veriler dayanıklıdır ve küme sonlandırıldıktan sonra yüksek oranda kullanılabilir durumda kalır. Küme depolama ve iş depolama alanı aynı kullanılabilirlik alanında bulunur. Bölgesel kullanılamazlığa karşı koruma sağlamak için Azure Databricks çalışma alanları varsayılan olarak coğrafi olarak yedekli depolama kullanır. Coğrafi olarak yedekli depolama ile veriler eşleştirilmiş bir Azure bölgesine çoğaltılır. Databricks coğrafi olarak yedekli depolamayı varsayılan olarak tutmanızı önerir, ancak bunun yerine yerel olarak yedekli depolama kullanmanız gerekiyorsa, çalışma alanının ARM şablonunda olarak ayarlayabilirsiniz
storageAccountSkuNameStandard_LRS.İkincil bölge oluşturulduktan sonra kullanıcıları, kullanıcı klasörlerini, not defterlerini, küme yapılandırmasını, iş yapılandırmasını, kitaplıkları, depolamayı, başlatma betiklerini geçirmeniz ve erişim denetimini yeniden yapılandırmanız gerekir. Ek ayrıntılar aşağıdaki bölümde özetlenmiştir.
Bölgesel olağanüstü durum
Bölgesel olağanüstü durumlara hazırlanmak için, ikincil bölgede başka bir Azure Databricks çalışma alanı kümesini açıkça korumanız gerekir. Bkz. Olağanüstü durum kurtarma.
Olağanüstü durum kurtarma için önerilen araçlarımız genellikle Terraform (Infra çoğaltması için) ve Delta Deep Clone (Veri çoğaltması için) araçlarıdır.
Ayrıntılı geçiş adımları
Bilgisayarınızda Databricks komut satırı arabirimini ayarlama
Bu makalede, Azure Databricks REST API üzerinde kullanımı kolay bir sarmalayıcı olduğundan otomatik adımların çoğu için komut satırı arabirimini kullanan bir dizi kod örneği gösterilmektedir.
Herhangi bir geçiş adımı gerçekleştirmeden önce databricks-cli'yi masaüstü bilgisayarınıza veya işi yapmayı planladığınız bir sanal makineye yükleyin. Daha fazla bilgi için bkz . Databricks CLI yükleme
pip install databricks-cliNot
Bu makalede sağlanan tüm Python betiklerinin Python 2.7+ < 3.x ile çalışması beklenir.
İki profil yapılandırın.
Birincil çalışma alanı için bir tane, ikincil çalışma alanı için de başka bir tane yapılandırın:
databricks configure --profile primary --token databricks configure --profile secondary --tokenBu makaledeki kod blokları, ilgili çalışma alanı komutunu kullanarak sonraki her adımda profiller arasında geçiş gerçekleştirir. Oluşturduğunuz profillerin adlarının her kod bloğuyla değiştirildiğinden emin olun.
EXPORT_PROFILE = "primary" IMPORT_PROFILE = "secondary"Gerekirse komut satırında el ile geçiş yapabilirsiniz:
databricks workspace ls --profile primary databricks workspace ls --profile secondaryMicrosoft Entra Id (eski adıyla Azure Active Directory) kullanıcılarını geçirme
Aynı Microsoft Entra Id (eski adıYla Azure Active Directory) kullanıcılarını birincil çalışma alanında bulunan ikincil çalışma alanına el ile ekleyin.
Kullanıcı klasörlerini ve not defterlerini geçirme
İç içe klasör yapısını ve kullanıcı başına not defterlerini içeren korumalı kullanıcı ortamlarını geçirmek için aşağıdaki Python kodunu kullanın.
Not
Temel alınan API bunları desteklemediğinden kitaplıklar bu adımda kopyalanmaz.
Aşağıdaki Python betiğini kopyalayıp bir dosyaya kaydedin ve Databricks komut satırınızda çalıştırın. Örneğin,
python scriptname.py.import sys import os import subprocess from subprocess import call, check_output EXPORT_PROFILE = "primary" IMPORT_PROFILE = "secondary" # Get a list of all users user_list_out = check_output(["databricks", "workspace", "ls", "/Users", "--profile", EXPORT_PROFILE]) user_list = (user_list_out.decode(encoding="utf-8")).splitlines() print (user_list) # Export sandboxed environment(folders, notebooks) for each user and import into new workspace. #Libraries are not included with these APIs / commands. for user in user_list: #print("Trying to migrate workspace for user ".decode() + user) print (("Trying to migrate workspace for user ") + user) subprocess.call(str("mkdir -p ") + str(user), shell = True) export_exit_status = call("databricks workspace export_dir /Users/" + str(user) + " ./" + str(user) + " --profile " + EXPORT_PROFILE, shell = True) if export_exit_status==0: print ("Export Success") import_exit_status = call("databricks workspace import_dir ./" + str(user) + " /Users/" + str(user) + " --profile " + IMPORT_PROFILE, shell=True) if import_exit_status==0: print ("Import Success") else: print ("Import Failure") else: print ("Export Failure") print ("All done")Küme yapılandırmalarını geçirme
Not defterleri geçirildikten sonra, isteğe bağlı olarak küme yapılandırmalarını yeni çalışma alanına geçirebilirsiniz. Tümü yerine seçmeli küme yapılandırma geçişi yapmak istemediğiniz sürece databricks-cli kullanan neredeyse tam otomatik bir adımdır.
Not
Ne yazık ki küme yapılandırma uç noktası oluşturma yok ve bu betik her kümeyi hemen oluşturmaya çalışır. Aboneliğinizde yeterli çekirdek yoksa küme oluşturma işlemi başarısız olabilir. Yapılandırma başarıyla aktarıldığı sürece hata yoksayılabilir.
Aşağıdaki betik, eskiden yeni küme kimliklerine bir eşleme yazdırır ve bu kimlikler daha sonra iş geçişi için kullanılabilir (mevcut kümeleri kullanmak üzere yapılandırılmış işler için).
Aşağıdaki Python betiğini kopyalayıp bir dosyaya kaydedin ve Databricks komut satırınızda çalıştırın. Örneğin,
python scriptname.py.import sys import os import subprocess import json from subprocess import call, check_output EXPORT_PROFILE = "primary" IMPORT_PROFILE = "secondary" # Get all clusters info from old workspace clusters_out = check_output(["databricks", "clusters", "list", "--profile", EXPORT_PROFILE]) clusters_info_list = str(clusters_out.decode(encoding="utf-8")). splitlines() print("Printting Cluster info List") print(clusters_info_list) # Create a list of all cluster ids clusters_list = [] ##for cluster_info in clusters_info_list: clusters_list.append (cluster_info.split(None, 1)[0]) for cluster_info in clusters_info_list: if cluster_info != '': clusters_list.append(cluster_info.split(None, 1)[0]) # Optionally filter cluster ids out manually, so as to create only required ones in new workspace # Create a list of mandatory / optional create request elements cluster_req_elems = ["num_workers","autoscale","cluster_name","spark_version","spark_conf","node_type_id","driver_node_type_id","custom_tags","cluster_log_conf","spark_env_vars","autotermination_minutes","enable_elastic_disk"] print("Printing Cluster element List") print (cluster_req_elems) print(str(len(clusters_list)) + " clusters found in the primary site" ) print ("---------------------------------------------------------") # Try creating all / selected clusters in new workspace with same config as in old one. cluster_old_new_mappings = {} i = 0 for cluster in clusters_list: i += 1 print("Checking cluster " + str(i) + "/" + str(len(clusters_list)) + " : " +str(cluster)) cluster_get_out_f = check_output(["databricks", "clusters", "get", "--cluster-id", str(cluster), "--profile", EXPORT_PROFILE]) cluster_get_out=str(cluster_get_out_f.decode(encoding="utf-8")) print ("Got cluster config from old workspace") print (cluster_get_out) # Remove extra content from the config, as we need to build create request with allowed elements only cluster_req_json = json.loads(cluster_get_out) cluster_json_keys = cluster_req_json.keys() #Don't migrate Job clusters if cluster_req_json['cluster_source'] == u'JOB' : print ("Skipping this cluster as it is a Job cluster : " + cluster_req_json['cluster_id'] ) print ("---------------------------------------------------------") continue #cluster_req_json.pop(key, None) for key in cluster_json_keys: if key not in cluster_req_elems: print (cluster_req_json) #cluster_del_item=cluster_json_keys .keys() cluster_req_json.popitem(key, None) # Create the cluster, and store the mapping from old to new cluster ids #Create a temp file to store the current cluster info as JSON strCurrentClusterFile = "tmp_cluster_info.json" #delete the temp file if exists if os.path.exists(strCurrentClusterFile) : os.remove(strCurrentClusterFile) fClusterJSONtmp = open(strCurrentClusterFile,"w+") fClusterJSONtmp.write(json.dumps(cluster_req_json)) fClusterJSONtmp.close() #cluster_create_out = check_output(["databricks", "clusters", "create", "--json", json.dumps(cluster_req_json), "--profile", IMPORT_PROFILE]) cluster_create_out = check_output(["databricks", "clusters", "create", "--json-file", strCurrentClusterFile , "--profile", IMPORT_PROFILE]) cluster_create_out_json = json.loads(cluster_create_out) cluster_old_new_mappings[cluster] = cluster_create_out_json['cluster_id'] print ("Cluster create request sent to secondary site workspace successfully") print ("---------------------------------------------------------") #delete the temp file if exists if os.path.exists(strCurrentClusterFile) : os.remove(strCurrentClusterFile) print ("Cluster mappings: " + json.dumps(cluster_old_new_mappings)) print ("All done") print ("P.S. : Please note that all the new clusters in your secondary site are being started now!") print (" If you won't use those new clusters at the moment, please don't forget terminating your new clusters to avoid charges")İş yapılandırmasını geçirme
Önceki adımda küme yapılandırmalarını geçirdiyseniz, iş yapılandırmalarını yeni çalışma alanına geçirmeyi tercih edebilirsiniz. Bu, tüm işler için yapmak yerine seçmeli iş yapılandırma geçişi yapmak istemediğiniz sürece databricks-cli kullanan tam otomatik bir adımdır.
Not
Zamanlanmış bir işin yapılandırması "zamanlama" bilgilerini de içerir, bu nedenle varsayılan olarak, geçirildikçe yapılandırılan zamanlamaya göre çalışmaya başlar. Bu nedenle, aşağıdaki kod bloğu geçiş sırasında zamanlama bilgilerini kaldırır (eski ve yeni çalışma alanlarında yinelenen çalıştırmaları önlemek için). Tam geçiş için hazır olduğunuzda bu tür işler için zamanlamaları yapılandırın.
İş yapılandırması için yeni veya mevcut bir küme için ayarlar gerekir. Mevcut küme kullanılıyorsa, aşağıdaki /code betiği eski küme kimliğini yeni küme kimliğiyle değiştirmeyi dener.
Aşağıdaki Python betiğini kopyalayın ve bir dosyaya kaydedin. ve
new_cluster_iddeğeriniold_cluster_id, önceki adımda yapılan küme geçişi çıkışıyla değiştirin. Bunu databricks-cli komut satırınızda çalıştırın; örneğin,python scriptname.py.import sys import os import subprocess import json from subprocess import call, check_output EXPORT_PROFILE = "primary" IMPORT_PROFILE = "secondary" # Please replace the old to new cluster id mappings from cluster migration output cluster_old_new_mappings = {"0227-120427-tryst214": "0229-032632-paper88"} # Get all jobs info from old workspace try: jobs_out = check_output(["databricks", "jobs", "list", "--profile", EXPORT_PROFILE]) jobs_info_list = jobs_out.splitlines() except: print("No jobs to migrate") sys.exit(0) # Create a list of all job ids jobs_list = [] for jobs_info in jobs_info_list: jobs_list.append(jobs_info.split(None, 1)[0]) # Optionally filter job ids out manually, so as to create only required ones in new workspace # Create each job in the new workspace based on corresponding settings in the old workspace for job in jobs_list: print("Trying to migrate ") + job job_get_out = check_output(["databricks", "jobs", "get", "--job-id", job, "--profile", EXPORT_PROFILE]) print("Got job config from old workspace") job_req_json = json.loads(job_get_out) job_req_settings_json = job_req_json['settings'] # Remove schedule information so job doesn't start before proper cutover job_req_settings_json.pop('schedule', None) # Replace old cluster id with new cluster id, if job configured to run against an existing cluster if 'existing_cluster_id' in job_req_settings_json: if job_req_settings_json['existing_cluster_id'] in cluster_old_new_mappings: job_req_settings_json['existing_cluster_id'] = cluster_old_new_mappings[job_req_settings_json['existing_cluster_id']] else: print("Mapping not available for old cluster id ") + job_req_settings_json['existing_cluster_id'] continue call(["databricks", "jobs", "create", "--json", json.dumps(job_req_settings_json), "--profile", IMPORT_PROFILE]) print("Sent job create request to new workspace successfully") print("All done")Kitaplıkları geçirme
Şu anda kitaplıkları bir çalışma alanından diğerine geçirmenin kolay bir yolu yoktur. Bunun yerine, bu kitaplıkları yeni çalışma alanına el ile yeniden yükleyin. Özel kitaplıkları çalışma alanına ve Kitaplıklar CLI'sine yüklemek için DBFS CLI birleşimini kullanarak otomatikleştirmek mümkündür.
Azure blob depolamayı ve Azure Data Lake Depolama bağlamalarını geçirme
Not defteri tabanlı bir çözüm kullanarak tüm Azure Blob depolamayı ve Azure Data Lake Depolama (2. Nesil) bağlama noktalarını el ile yeniden bağlayın. Depolama kaynakları birincil çalışma alanına bağlanmış ve bunun ikincil çalışma alanında tekrarlanması gerekir. Bağlamalar için dış API yoktur.
Küme başlatma betiklerini geçirme
Tüm küme başlatma betikleri DBFS CLI kullanılarak eski çalışma alanından yeni çalışma alanına geçirilebilir. İlk olarak, gerekli betikleri 'den
dbfs:/dat abricks/init/..yerel masaüstünüze veya sanal makinenize kopyalayın. Ardından, bu betikleri aynı yoldaki yeni çalışma alanına kopyalayın.// Primary to local dbfs cp -r dbfs:/databricks/init ./old-ws-init-scripts --profile primary // Local to Secondary workspace dbfs cp -r old-ws-init-scripts dbfs:/databricks/init --profile secondaryErişim denetimini el ile yeniden yapılandırın ve yeniden uygulayın.
Mevcut birincil çalışma alanınız Premium veya Kurumsal katmanını (SKU) kullanacak şekilde yapılandırılmışsa, büyük olasılıkla Erişim Denetimi özelliğini de kullanıyorsunuzdur.
Erişim Denetimi özelliğini kullanıyorsanız erişim denetimini kaynaklara (Not Defterleri, Kümeler, İşler, Tablolar) el ile yeniden uygulayın.
Azure ekosisteminiz için olağanüstü durum kurtarma
Diğer Azure hizmetlerini kullanıyorsanız, bu hizmetler için de olağanüstü durum kurtarma en iyi yöntemlerini uyguladığınızı unutmayın. Örneğin, dış Hive meta veri deposu örneği kullanmayı seçerseniz Azure SQL Veritabanı, Azure HDInsight ve/veya MySQL için Azure Veritabanı için olağanüstü durum kurtarmayı göz önünde bulundurmalısınız. Olağanüstü durum kurtarma hakkında genel bilgi için bkz . Azure uygulamaları için olağanüstü durum kurtarma.
Sonraki adımlar
Daha fazla bilgi için bkz . Azure Databricks belgeleri.