Öğretici: Azure Databricks not defterinden sanal ağdaki SQL Server Linux Docker kapsayıcısını sorgulama
Bu öğreticide Azure Databricks'i bir sanal ağdaki SQL Server Linux Docker kapsayıcısıyla tümleştirme adımları anlatılmaktadır.
Bu öğreticide şunların nasıl yapılacağını öğreneceksiniz:
- Azure Databricks çalışma alanını sanal ağa dağıtma
- Ortak ağa Linux sanal makinesi yükleme
- Docker'ı yükleme
- Microsoft Linux üzerinde SQL Server docker kapsayıcısı yükleme
- Databricks not defterinden JDBC kullanarak SQL Server sorgulama
Önkoşullar
Bir sanal ağda Databricks çalışma alanı oluşturun.
Windows için Ubuntu'u yükleyin.
SQL Server Management Studio indirin.
Linux sanal makinesi oluşturma
Azure portal Sanal Makineler simgesini seçin. Ardından + Ekle'yi seçin.

Temel Bilgiler sekmesinde Ubuntu Server 18.04 LTS'yi seçin ve VM boyutunu B2s olarak değiştirin. Bir yönetici kullanıcı adı ve parolası seçin.
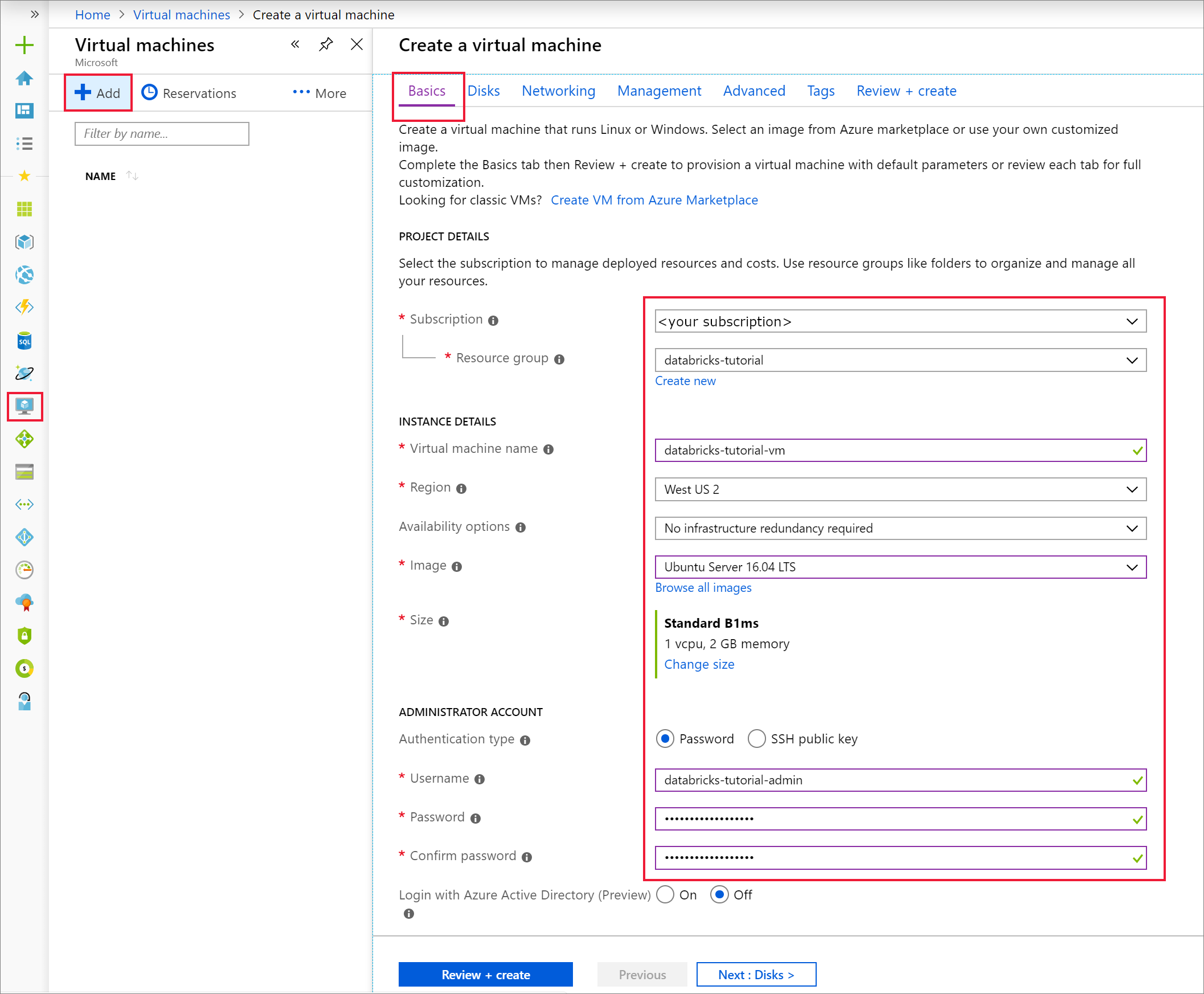
Ağ sekmesine gidin. Azure Databricks kümenizi içeren sanal ağı ve genel alt ağı seçin. Sanal makineyi dağıtmak için Gözden geçir + oluştur'u ve ardından Oluştur'u seçin.

Dağıtım tamamlandığında sanal makineye gidin. Genel BAKıŞ'ta Genel IP adresi ve Sanal ağ/alt ağ'a dikkat edin. Genel IP Adresini seçin
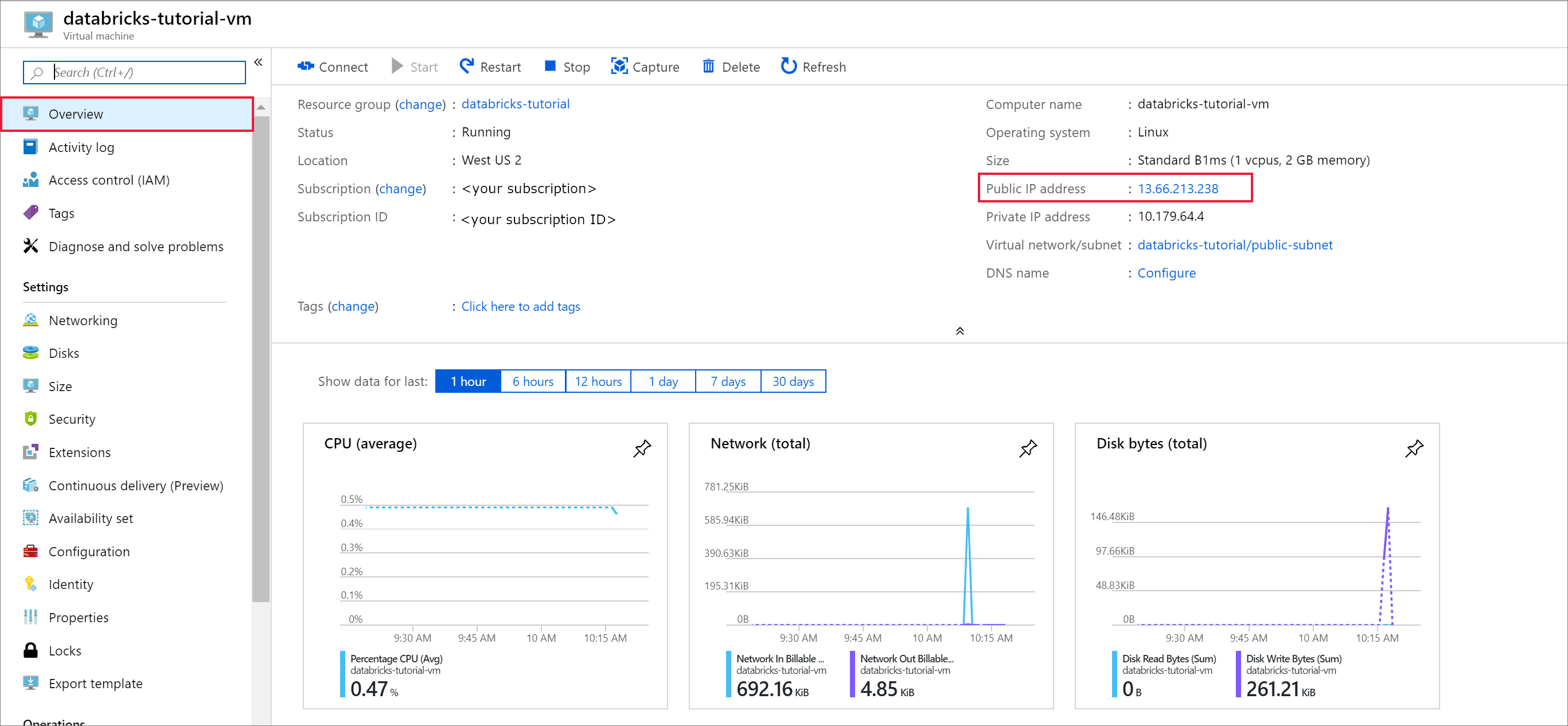
AtamayıStatik olarak değiştirin ve bir DNS adı etiketi girin. Kaydet'i seçin ve sanal makineyi yeniden başlatın.
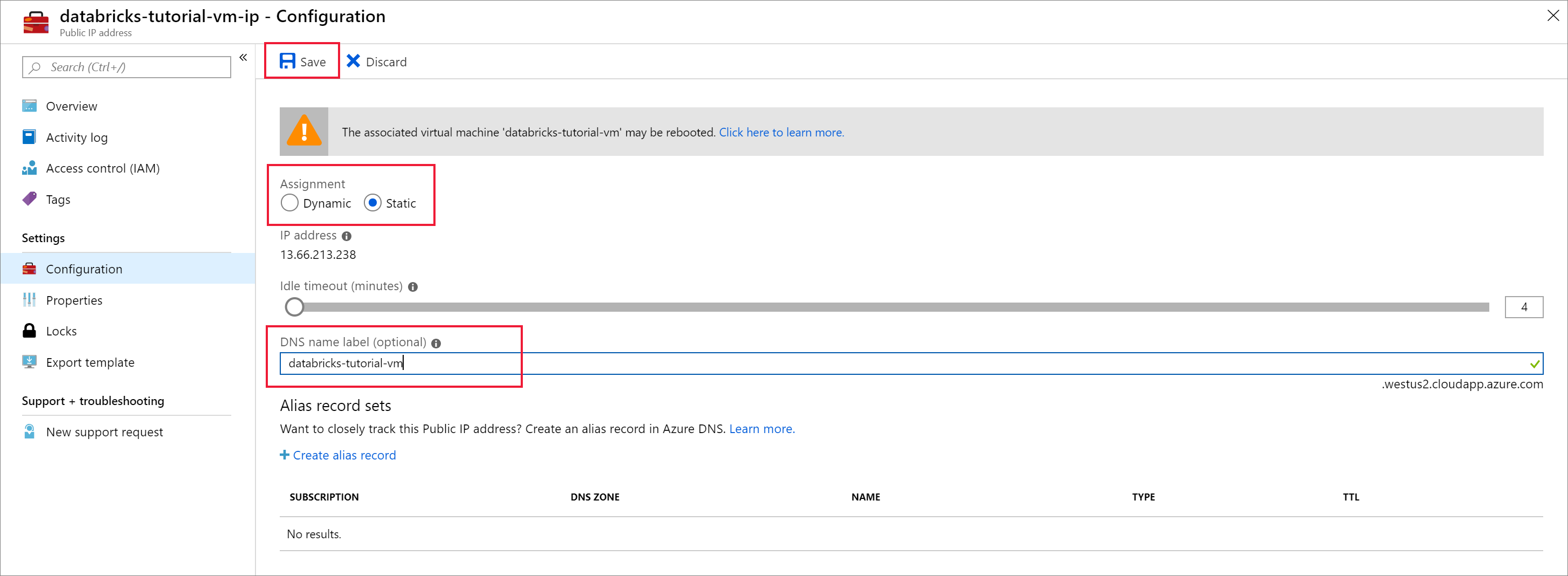
Ayarlar'ın altında Ağ sekmesini seçin. Azure Databricks dağıtımı sırasında oluşturulan ağ güvenlik grubunun sanal makineyle ilişkili olduğuna dikkat edin. Gelen bağlantı noktası kuralı ekle'yi seçin.
SSH için 22 numaralı bağlantı noktasını açmak için bir kural ekleyin. Aşağıdaki ayarları kullanın:
Ayarı Önerilen değer Açıklama Kaynak IP Adresleri IP Adresleri, belirli bir kaynak IP Adresinden gelen trafiğe bu kural tarafından izin verileceğini veya trafiğin reddedileceğini belirtir. Kaynak IP adresleri <genel ip'niz> Genel IP adresinizi girin. genel IP adresinizi bulmak için bing.com adresini ziyaret edip "IP'm" ifadesini arayabilirsiniz. Kaynak bağlantı noktası aralıkları * Herhangi bir bağlantı noktasından gelen trafiğe izin verin. Hedef IP Adresleri IP Adresleri, belirli bir kaynak IP Adresi için giden trafiğe bu kural tarafından izin verileceğini veya reddedileceğini belirtir. Hedef IP adresleri <vm genel IP'niz> Sanal makinenizin genel IP adresini girin. Bunu sanal makinenizin Genel Bakış sayfasında bulabilirsiniz. Hedef bağlantı noktası aralıkları 22 SSH için 22 numaralı bağlantı noktasını açın. Öncelik 290 Kurala öncelik verin. Adı ssh-databricks-tutorial-vm Kurala bir ad verin. 
SQL için 1433 numaralı bağlantı noktasını aşağıdaki ayarlarla açmak için bir kural ekleyin:
Ayarı Önerilen değer Açıklama Kaynak Herhangi biri Kaynak, belirli bir kaynak IP Adresinden gelen trafiğe bu kural tarafından izin verileceğini veya trafiğin reddedileceğini belirtir. Kaynak bağlantı noktası aralıkları * Herhangi bir bağlantı noktasından gelen trafiğe izin verin. Hedef IP Adresleri IP Adresleri, belirli bir kaynak IP Adresi için giden trafiğe bu kural tarafından izin verileceğini veya reddedileceğini belirtir. Hedef IP adresleri <vm genel IP'niz> Sanal makinenizin genel IP adresini girin. Bunu sanal makinenizin Genel Bakış sayfasında bulabilirsiniz. Hedef bağlantı noktası aralıkları 1433 SQL Server için 22 numaralı bağlantı noktasını açın. Öncelik 300 Kurala öncelik verin. Adı sql-databricks-tutorial-vm Kurala bir ad verin. 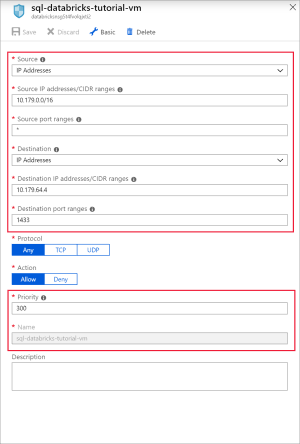
Docker kapsayıcısında SQL Server çalıştırma
Windows için Ubuntu'yı veya sanal makinede SSH kullanmanıza olanak sağlayacak başka bir aracı açın. Azure portal sanal makinenize gidin ve bağlanmanız gereken SSH komutunu almak için Bağlan'ı seçin.
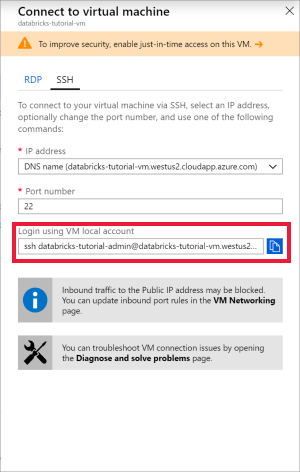
Ubuntu terminalinize komutunu girin ve sanal makineyi yapılandırırken oluşturduğunuz yönetici parolasını girin.
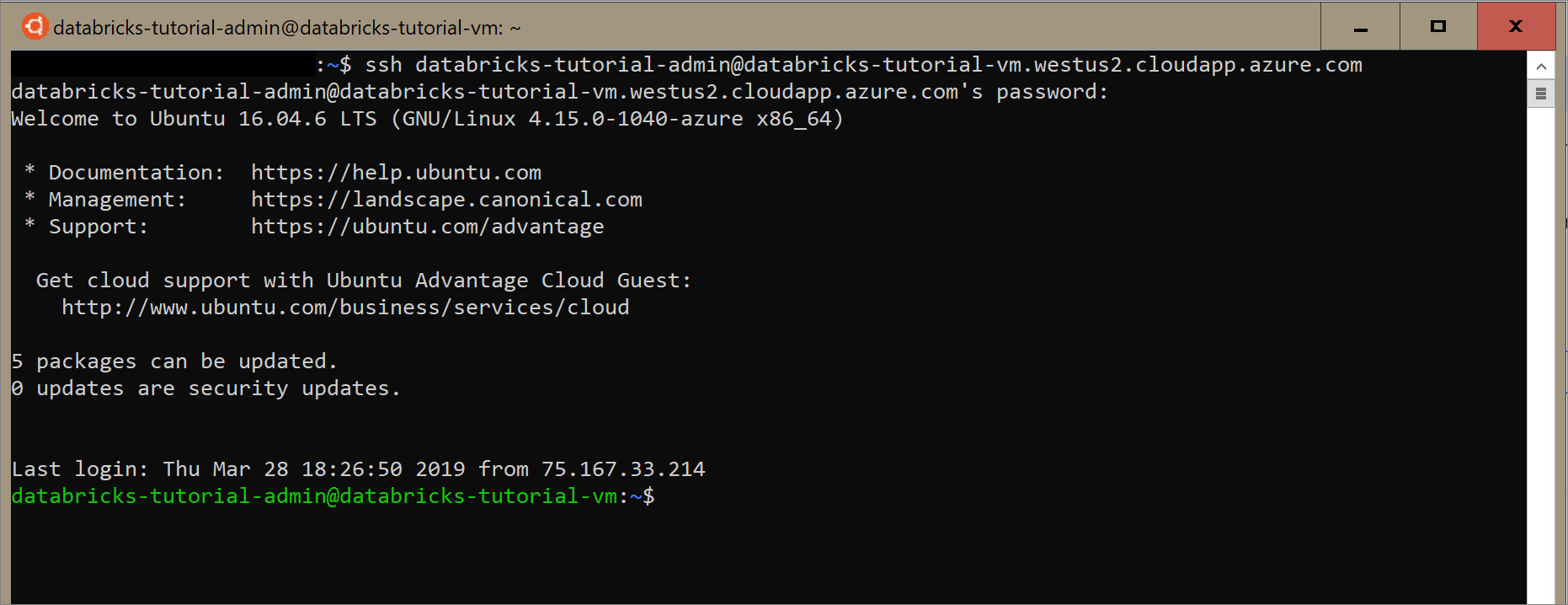
Sanal makineye Docker yüklemek için aşağıdaki komutu kullanın.
sudo apt-get install docker.ioAşağıdaki komutla Docker'ın yüklendiğini doğrulayın:
sudo docker --versionGörüntüyü yükleyin.
sudo docker pull mcr.microsoft.com/mssql/server:2017-latestGörüntüleri kontrol edin.
sudo docker imagesGörüntüden kapsayıcıyı çalıştırın.
sudo docker run -e 'ACCEPT_EULA=Y' -e 'SA_PASSWORD=Password1234' -p 1433:1433 --name sql1 -d mcr.microsoft.com/mssql/server:2017-latestKapsayıcının çalıştığını doğrulayın.
sudo docker ps -a
SQL veritabanı oluşturma
SQL Server Management Studio açın ve sunucu adını ve SQL Kimlik Doğrulaması'nı kullanarak sunucuya bağlanın. Oturum açma kullanıcı adı SA , parola ise Docker komutunda ayarlanan paroladır. Örnek komuttaki parola şeklindedir
Password1234.
Başarıyla bağlandıktan sonra Yeni Sorgu'yu seçin ve bir veritabanı, tablo oluşturmak ve tabloya bazı kayıtlar eklemek için aşağıdaki kod parçacığını girin.
CREATE DATABASE MYDB; GO USE MYDB; CREATE TABLE states(Name VARCHAR(20), Capitol VARCHAR(20)); INSERT INTO states VALUES ('Delaware','Dover'); INSERT INTO states VALUES ('South Carolina','Columbia'); INSERT INTO states VALUES ('Texas','Austin'); SELECT * FROM states GO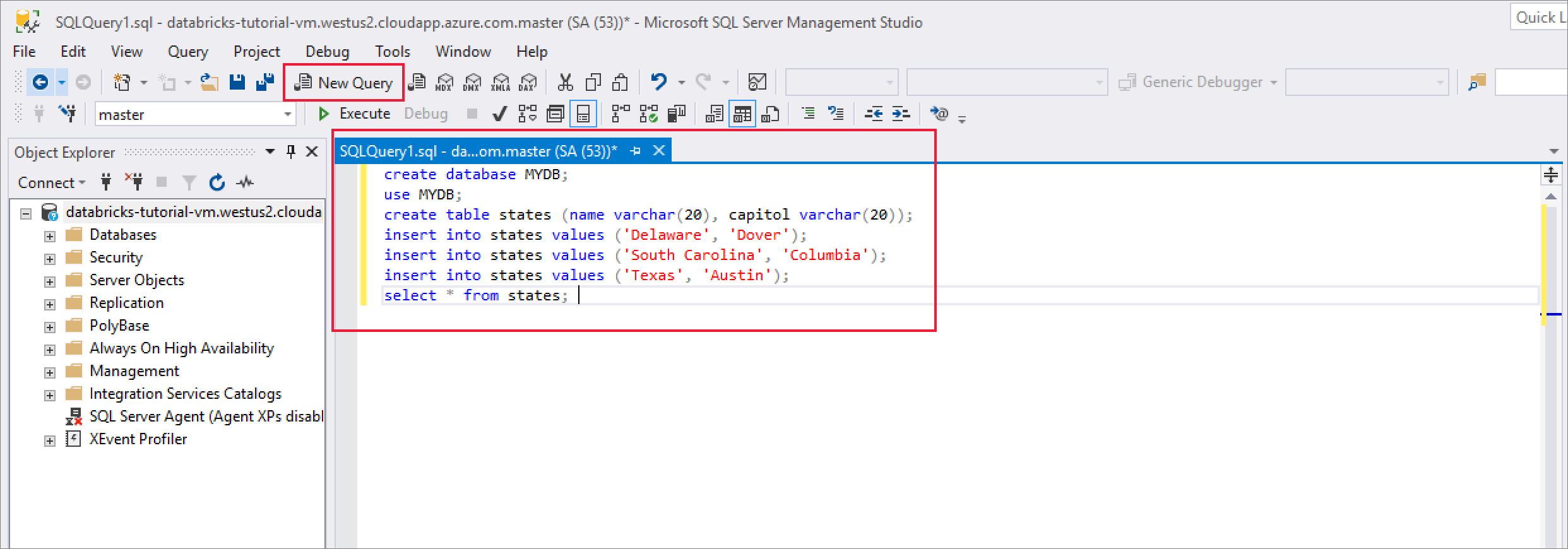
Azure Databricks'ten SQL Server sorgulama
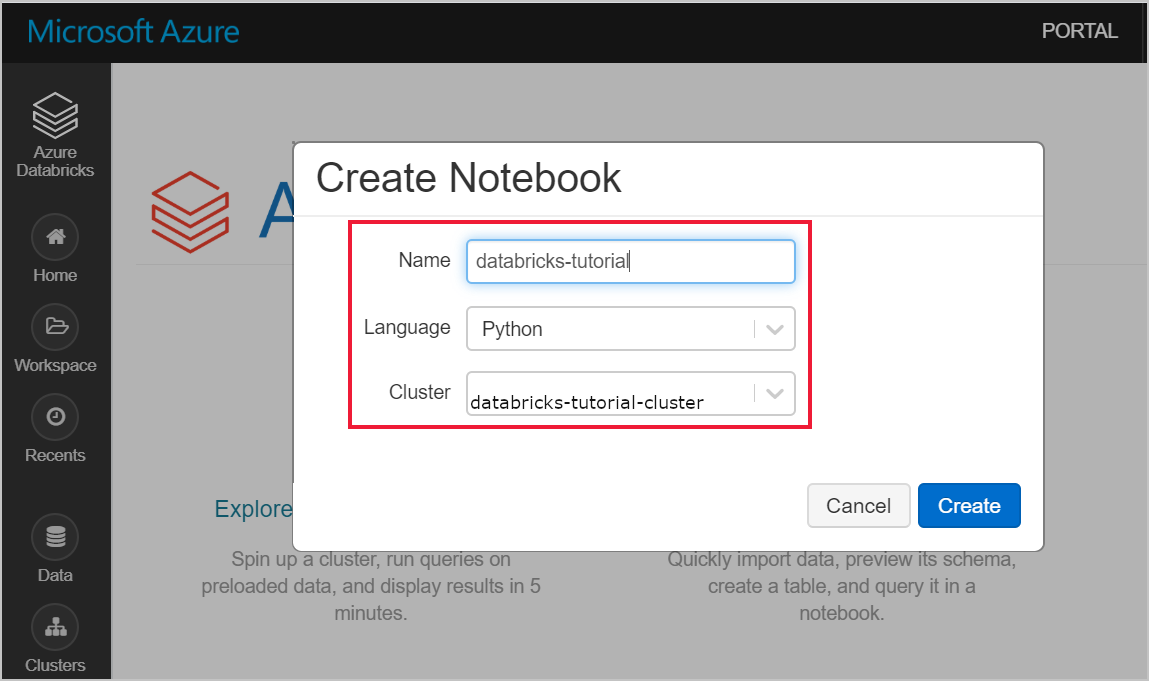
Azure Databricks çalışma alanınıza gidin ve önkoşulların bir parçası olarak bir küme oluşturduğunuzu doğrulayın. Ardından Not Defteri Oluştur'u seçin. Not defterine bir ad verin, dil olarak Python'ı seçin ve oluşturduğunuz kümeyi seçin.
SQL Server sanal makinesinin iç IP Adresine ping göndermek için aşağıdaki komutu kullanın. Bu ping başarılı olmalıdır. Çalışmıyorsa kapsayıcının çalıştığını doğrulayın ve ağ güvenlik grubu (NSG) yapılandırmasını gözden geçirin.
%sh ping 10.179.64.4Gözden geçirmek için nslookup komutunu da kullanabilirsiniz.
%sh nslookup databricks-tutorial-vm.westus2.cloudapp.azure.comSQL Server başarıyla ping işlemi yaptıktan sonra veritabanını ve tabloları sorgulayabilirsiniz. Aşağıdaki Python kodunu çalıştırın:
jdbcHostname = "10.179.64.4" jdbcDatabase = "MYDB" userName = 'SA' password = 'Password1234' jdbcPort = 1433 jdbcUrl = "jdbc:sqlserver://{0}:{1};database={2};user={3};password={4}".format(jdbcHostname, jdbcPort, jdbcDatabase, userName, password) df = spark.read.jdbc(url=jdbcUrl, table='states') display(df)
Kaynakları temizleme
Artık gerekli olmadığında kaynak grubunu, Azure Databricks çalışma alanını ve tüm ilgili kaynakları silin. İşin silinmesi gereksiz faturalamayı önler. Gelecekte Azure Databricks çalışma alanını kullanmayı planlıyorsanız kümeyi durdurup daha sonra yeniden başlatabilirsiniz. Bu Azure Databricks çalışma alanını kullanmaya devam etmeyecekseniz, aşağıdaki adımları kullanarak bu öğreticide oluşturduğunuz tüm kaynakları silin:
Azure portal sol taraftaki menüden Kaynak grupları'na ve ardından oluşturduğunuz kaynak grubunun adına tıklayın.
Kaynak grubu sayfanızda Sil'i seçin, metin kutusuna silinecek kaynağın adını yazın ve sonra yeniden Sil'i seçin.
Sonraki adımlar
Azure Databricks kullanarak verileri ayıklamayı, dönüştürmeyi ve yüklemeyi öğrenmek için sonraki makaleye ilerleyin.