Azure HDInsight kümelerini otomatik olarak ölçeklendirme
Azure HDInsight'ın ücretsiz Otomatik Ölçeklendirme özelliği, müşteriler tarafından benimsenen küme ölçümlerine ve ölçeklendirme ilkesine göre kümenizdeki çalışan düğümlerinin sayısını otomatik olarak artırabilir veya azaltabilir. Otomatik Ölçeklendirme özelliği, performans ölçümlerine veya ölçek artırma ve ölçeği azaltma işlemlerinin tanımlı zamanlamasına göre önceden belirlenmiş sınırlar içindeki düğüm sayısını ölçeklendirerek çalışır
Nasıl çalışır?
Otomatik Ölçeklendirme özelliği, ölçeklendirme olaylarını tetikleme amacıyla iki tür koşul kullanır: çeşitli küme performans ölçümleri için eşikler (yük tabanlı ölçeklendirme olarak adlandırılır) ve zaman tabanlı tetikleyiciler (zamanlama tabanlı ölçeklendirme olarak adlandırılır). Yük tabanlı ölçeklendirme, en iyi CPU kullanımını sağlamak ve çalıştırma maliyetini en aza indirmek için kümenizdeki düğüm sayısını ayarladığınız bir aralık içinde değiştirir. Zamanlama tabanlı ölçeklendirme, ölçeği artırma ve ölçeği azaltma işlemlerinin zamanlamasına göre kümenizdeki düğüm sayısını değiştirir.
Aşağıdaki videoda, Otomatik Ölçeklendirme'nin çözdüğü zorluklara ve HDInsight ile maliyetleri denetlemenize nasıl yardımcı olabileceğine ilişkin genel bir bakış sunulmaktadır.
Yük tabanlı veya zamanlama tabanlı ölçeklendirmeyi seçme
Zamanlama tabanlı ölçeklendirme kullanılabilir:
- İşlerinizin sabit zamanlamalarla ve öngörülebilir bir süreyle çalıştırılması beklendiğinde veya Günün belirli saatlerinde düşük kullanım tahmin ettiğinizde Örneğin, çalışma sonrası ve gün sonu işlerinde test ve geliştirme ortamları.
Yük tabanlı ölçeklendirme kullanılabilir:
- Yük desenleri gün içinde önemli ölçüde ve öngörülemez şekilde dalgalandığında. Örneğin, çeşitli faktörlere göre yük desenlerinde rastgele dalgalanmalarla veri işlemeyi sırala
Küme ölçümleri
Otomatik ölçeklendirme, kümeyi sürekli izler ve aşağıdaki ölçümleri toplar:
| Metrik Sistem | Açıklama |
|---|---|
| Toplam Bekleyen CPU | Bekleyen tüm kapsayıcıların yürütülmesini başlatmak için gereken toplam çekirdek sayısı. |
| Toplam Bekleyen Bellek | Bekleyen tüm kapsayıcıların yürütülmesini başlatmak için gereken toplam bellek (MB cinsinden). |
| Toplam Ücretsiz CPU | Etkin çalışan düğümlerindeki kullanılmayan tüm çekirdeklerin toplamı. |
| Toplam Boş Bellek | Etkin çalışan düğümlerinde kullanılmayan belleğin (MB cinsinden) toplamı. |
| Düğüm Başına Kullanılan Bellek | Çalışan düğümündeki yük. 10 GB belleğin kullanıldığı bir çalışan düğümü, 2 GB kullanılan belleğe sahip bir çalışandan daha fazla yük altında kabul edilir. |
| Düğüm Başına Uygulama Ana Şablonu Sayısı | Çalışan düğümünde çalışan Application Master (AM) kapsayıcılarının sayısı. İki AM kapsayıcısı barındıran bir çalışan düğümü, sıfır AM kapsayıcısı barındıran bir çalışan düğümünden daha önemli kabul edilir. |
Yukarıdaki ölçümler 60 saniyede bir denetlenmektedir. Otomatik ölçeklendirme, bu ölçümlere göre ölçeği artırma ve azaltma kararları verir.
Yük tabanlı ölçek koşulları
Aşağıdaki koşullar algılandığında, Otomatik Ölçeklendirme bir ölçek isteği verir:
| Ölçeği büyütme | Ölçeği azaltma |
|---|---|
| Toplam bekleyen CPU, 3-5 dakikadan uzun süre boyunca toplam ücretsiz CPU'dan büyüktür. | Toplam bekleyen CPU, 3-5 dakikadan uzun süre boyunca toplam ücretsiz CPU'dan daha azdır. |
| Toplam bekleyen bellek, 3-5 dakikadan uzun süre toplam boş bellekten büyüktür. | Toplam bekleyen bellek, 3-5 dakikadan uzun süre toplam boş bellekten daha azdır. |
Ölçeği büyütmek için Otomatik Ölçeklendirme, gerekli düğüm sayısını eklemeye yönelik bir ölçek artırma isteği verir. Ölçeği artırma, geçerli CPU ve bellek gereksinimlerini karşılamak için gereken yeni çalışan düğümü sayısını temel alır.
Ölçeği küçültmek için, Otomatik Ölçeklendirme bazı düğümleri kaldırma isteği verir. Ölçeği azaltma, düğüm başına Application Master (AM) kapsayıcılarının sayısını temel alır. Ve geçerli CPU ve bellek gereksinimleri. Hizmet ayrıca geçerli iş yürütmeye göre hangi düğümlerin kaldırılma adayı olduğunu da algılar. Ölçeği azaltma işlemi önce düğümlerin yetkisini alır ve ardından bunları kümeden kaldırır.
Otomatik ölçeklendirme için Ambari DB boyutlandırma konusunda dikkat edilmesi gerekenler
Ambari DB'nin otomatik ölçeklendirmenin avantajlarından yararlanmak için doğru boyutlandırılmış olması önerilir. Müşteriler doğru veritabanı katmanını ve büyük boyutlu kümeler için özel Ambari DB'yi kullanmalıdır. Lütfen Veritabanı ve Baş düğüm boyutlandırma önerilerini okuyun.
Küme uyumluluğu
Önemli
Azure HDInsight Otomatik Ölçeklendirme özelliği, Spark ve Hadoop kümeleri için 7 Kasım 2019’da genel kullanıma sunulmuştu ve özelliğin önizleme sürümünde sağlanmayan geliştirmeler içeriyordu. 7 Kasım 2019’dan önce Spark kümesi oluşturduysanız ve kümenizde Otomatik Ölçeklendirme özelliğini kullanmak istiyorsanız, yeni küme oluşturma ve yeni kümede Otomatik Ölçeklendirme’yi etkinleştirme yolunu izlemeniz önerilir.
Interactive Query (LLAP) için Otomatik Ölçeklendirme, 27 Ağustos 2020'de HDI 4.0 için genel kullanıma sunuldu. Otomatik ölçeklendirme yalnızca Spark, Hadoop ve Etkileşimli Sorgu, kümelerde kullanılabilir
Aşağıdaki tabloda, Otomatik Ölçeklendirme özelliğiyle uyumlu küme türleri ve sürümleri açıklanmaktadır.
| Sürüm | Spark | Hive | Interactive Query | HBase | Kafka |
|---|---|---|---|---|---|
| ESP olmadan HDInsight 4.0 | Yes | Yes | Evet* | Hayır | Hayır |
| ESP ile HDInsight 4.0 | Yes | Yes | Evet* | Hayır | Hayır |
| ESP olmadan HDInsight 5.0 | Yes | Yes | Evet* | Hayır | Hayır |
| ESP ile HDInsight 5.0 | Yes | Yes | Evet* | Hayır | Hayır |
* Etkileşimli Sorgu kümeleri yalnızca zamanlamaya dayalı ölçeklendirme için yapılandırılabilir, yük tabanlı değil.
Kullanmaya başlayın
Yük tabanlı Otomatik Ölçeklendirme ile küme oluşturma
Yük tabanlı ölçeklendirme ile Otomatik Ölçeklendirme özelliğini etkinleştirmek için, normal küme oluşturma işleminin bir parçası olarak aşağıdaki adımları tamamlayın:
Yapılandırma + fiyatlandırma sekmesinde Otomatik ölçeklendirmeyi etkinleştir onay kutusunu seçin.
Otomatik ölçeklendirme türü altında Yük tabanlı'ya tıklayın.
Aşağıdaki özellikler için istenen değerleri girin:
- Çalışan düğümü için ilk düğüm sayısı.
- En az çalışan düğümü sayısı.
- En fazla çalışan düğümü sayısı.
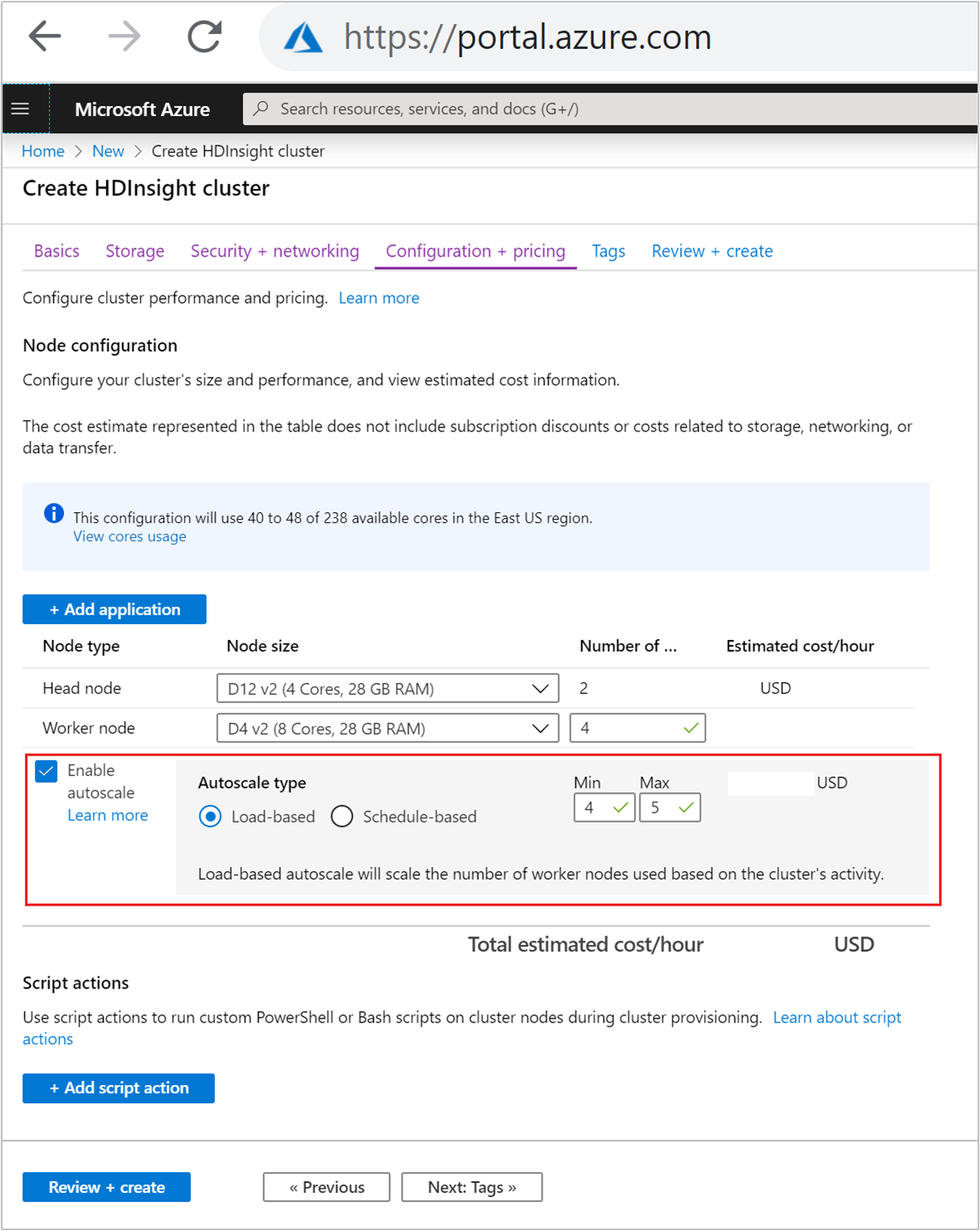
İlk çalışan düğümü sayısı, en düşük ve en yüksek düğüm (dahil) arasında olmalıdır. Bu değer, küme oluşturulduğunda ilk boyutunu tanımlar. En az çalışan düğümü sayısı üç veya daha fazla olarak ayarlanmalıdır. Kümenizin üçten az düğüme ölçeklenmesi, yetersiz dosya çoğaltması nedeniyle güvenli modda takılmasına neden olabilir. Daha fazla bilgi için bkz . Güvenli modda takılma.
Zamanlama tabanlı Otomatik Ölçeklendirme ile küme oluşturma
Zamanlama tabanlı ölçeklendirme ile Otomatik Ölçeklendirme özelliğini etkinleştirmek için, normal küme oluşturma işleminin bir parçası olarak aşağıdaki adımları tamamlayın:
Yapılandırma + fiyatlandırma sekmesinde Otomatik ölçeklendirmeyi etkinleştir onay kutusunu işaretleyin.
Kümenin ölçeğini artırma sınırını denetleyen Çalışan düğümü için düğümsayısı'nı girin.
Otomatik ölçeklendirme türü altında Zamanlama tabanlı seçeneğini belirleyin.
Otomatik ölçeklendirme yapılandırma penceresini açmak için Yapılandır'ı seçin.
Saat diliminizi seçin ve + Koşul ekle'ye tıklayın
Yeni koşulun uygulanacağı haftanın günlerini seçin.
Koşulun geçerlilik süresini ve kümenin ölçeklendirilmesi gereken düğüm sayısını düzenleyin.
Gerekirse daha fazla koşul ekleyin.
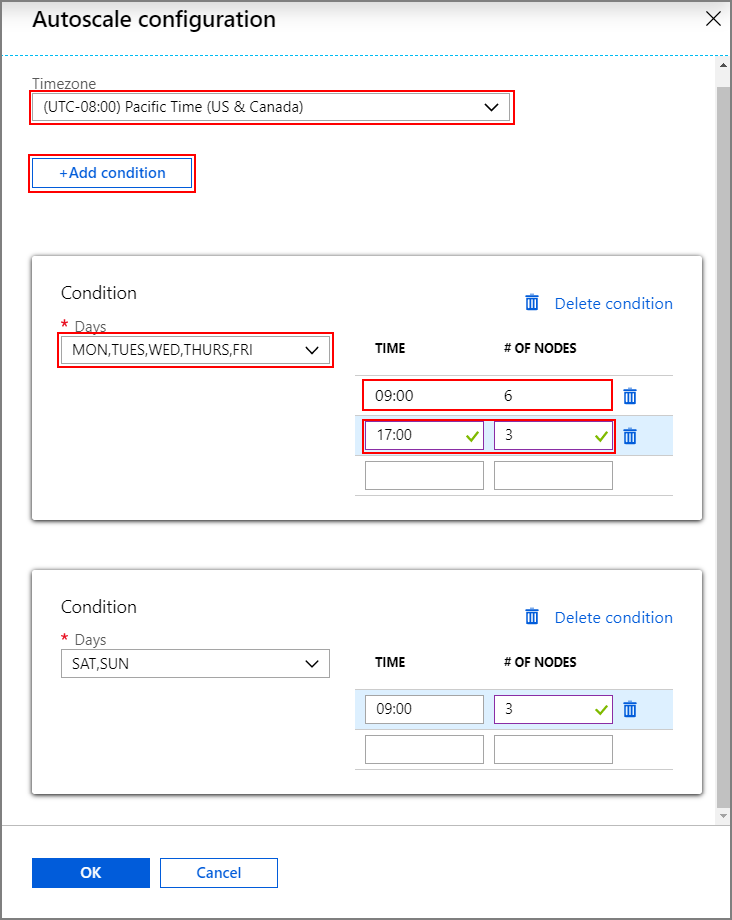
Koşul eklemeden önce düğüm sayısı 3 ile girdiğiniz en fazla çalışan düğümü sayısı arasında olmalıdır.
Son oluşturma adımları
Düğüm boyutu altındaki açılan listeden bir VM seçerek çalışan düğümleri için VM türünü seçin. Her düğüm türü için VM türünü seçtikten sonra kümenin tamamı için tahmini maliyet aralığını görebilirsiniz. VM türlerini bütçenize uyacak şekilde ayarlayın.
Aboneliğinizin her bölge için bir kapasite kotası vardır. Baş düğümlerinizin toplam çekirdek sayısı ve en fazla çalışan düğümü sayısı kapasite kotasını aşamaz. Ancak bu kota geçici bir sınırdır; kolayca artırmak için istediğiniz zaman bir destek bileti oluşturabilirsiniz.
Not
Toplam çekirdek kota sınırını aşarsanız ,'Maksimum düğüm bu bölgedeki kullanılabilir çekirdekleri aştı, lütfen başka bir bölge seçin veya kotayı artırmak için desteğe başvurun' hata iletisi alırsınız.
Azure portalını kullanarak HDInsight kümesi oluşturma hakkında daha fazla bilgi için bkz . Azure portalını kullanarak HDInsight'ta Linux tabanlı kümeler oluşturma.
Resource Manager şablonuyla küme oluşturma
Yük tabanlı otomatik ölçeklendirme
Özelliklere minInstanceCount sahip bir düğüm>computeProfileworkernode ekleyerek autoscale ve maxInstanceCount json kod parçacığında gösterildiği gibi Azure Resource Manager şablonunu yük tabanlı Otomatik Ölçeklendirme ile HDInsight kümesi oluşturabilirsiniz. Eksiksiz bir Resource Manager şablonu için bkz . Hızlı Başlangıç şablonu: Yük tabanlı otomatik ölçeklendirme etkin spark kümesi dağıtma.
{
"name": "workernode",
"targetInstanceCount": 4,
"autoscale": {
"capacity": {
"minInstanceCount": 3,
"maxInstanceCount": 10
}
},
"hardwareProfile": {
"vmSize": "Standard_D13_V2"
},
"osProfile": {
"linuxOperatingSystemProfile": {
"username": "[parameters('sshUserName')]",
"password": "[parameters('sshPassword')]"
}
},
"virtualNetworkProfile": null,
"scriptActions": []
}
Zamanlama tabanlı otomatik ölçeklendirme
Bölümüne bir düğüm computeProfile>workernode ekleyerek Azure Resource Manager şablonunu zamanlamaya dayalı Otomatik Ölçeklendirme ile HDInsight autoscale kümesi oluşturabilirsiniz. Düğüm, autoscale değişikliğin ne zaman gerçekleştiğini açıklayan ve schedule içeren bir recurrencetimezone içerir. Eksiksiz bir Resource Manager şablonu için bkz . Zamanlama tabanlı Otomatik Ölçeklendirme Etkin olarak Spark Kümesi Dağıtma.
{
"autoscale": {
"recurrence": {
"timeZone": "Pacific Standard Time",
"schedule": [
{
"days": [
"Monday",
"Tuesday",
"Wednesday",
"Thursday",
"Friday"
],
"timeAndCapacity": {
"time": "11:00",
"minInstanceCount": 10,
"maxInstanceCount": 10
}
}
]
}
},
"name": "workernode",
"targetInstanceCount": 4
}
Çalışan bir küme için Otomatik Ölçeklendirme'yi etkinleştirme ve devre dışı bırakma
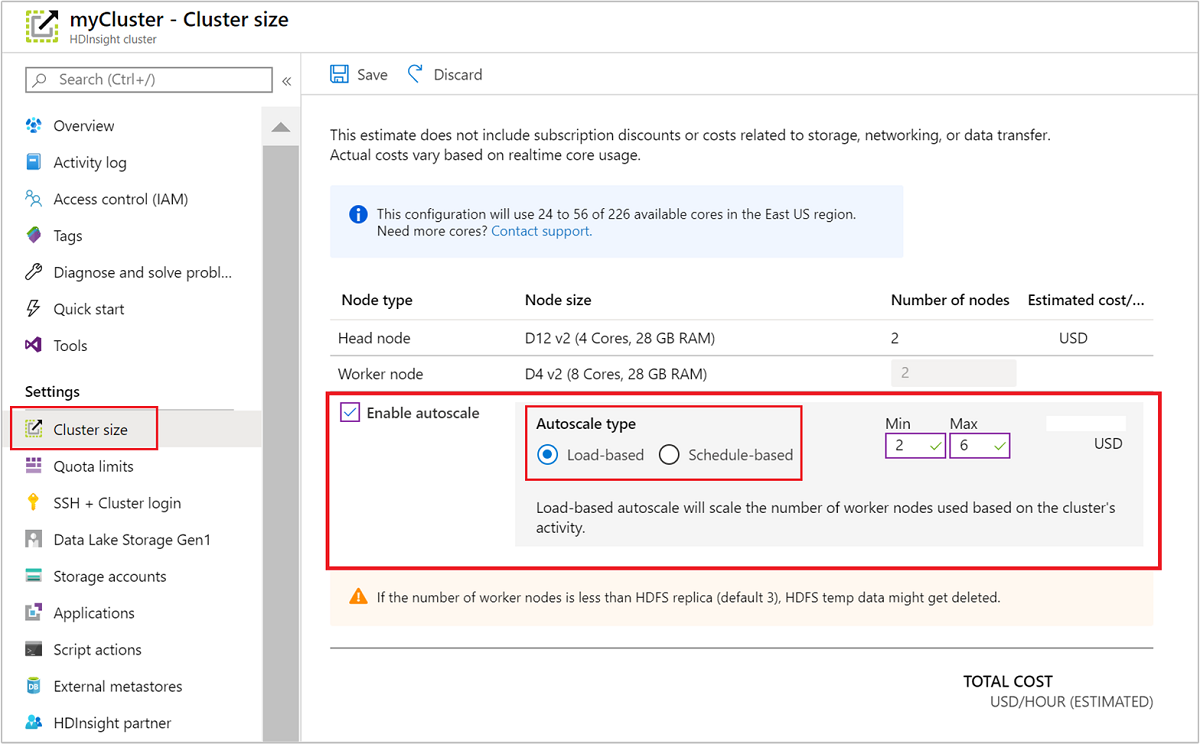
Azure portalını kullanma
Çalışan bir kümede Otomatik Ölçeklendirme'yi etkinleştirmek için Ayarlar altında Küme boyutu'nu seçin. Ardından Otomatik ölçeklendirmeyi etkinleştir'i seçin. İstediğiniz Otomatik Ölçeklendirme türünü seçin ve yük tabanlı veya zamanlama tabanlı ölçeklendirme seçeneklerini girin. Son olarak Kaydet’i seçin.
REST API’yi kullanma
REST API kullanarak çalışan bir kümede Otomatik Ölçeklendirme'yi etkinleştirmek veya devre dışı bırakmak için Otomatik Ölçeklendirme uç noktasına bir POST isteği gönderin:
https://management.azure.com/subscriptions/{subscription Id}/resourceGroups/{resourceGroup Name}/providers/Microsoft.HDInsight/clusters/{CLUSTERNAME}/roles/workernode/autoscale?api-version=2018-06-01-preview
İstek yükünde uygun parametreleri kullanın. Otomatik Ölçeklendirmeyi etkinleştirmek için aşağıdaki json yükü kullanılabilir. Otomatik Ölçeklendirme'yi devre dışı bırakmak için yükü {autoscale: null} kullanın.
{ "autoscale": { "capacity": { "minInstanceCount": 3, "maxInstanceCount": 5 } } }
Tüm yük parametrelerinin tam açıklaması için yük tabanlı otomatik ölçeklendirmeyi etkinleştirme ile ilgili önceki bölüme bakın. Çalışan bir kümede otomatik ölçeklendirme hizmetinin zorla devre dışı bırakılması önerilmez.
Otomatik Ölçeklendirme etkinliklerini izleme
Küme durumu
Azure portalında listelenen küme durumu, Otomatik Ölçeklendirme etkinliklerini izlemenize yardımcı olabilir.

Görebileceğiniz tüm küme durum iletileri aşağıdaki listede açıklanmıştır.
| Küme durumu | Açıklama |
|---|---|
| Çalışıyor | Küme normal şekilde çalışıyor. Önceki tüm Otomatik Ölçeklendirme etkinlikleri başarıyla tamamlandı. |
| Güncelleştirme | Küme Otomatik Ölçeklendirme yapılandırması güncelleştiriliyor. |
| HDInsight yapılandırması | Küme ölçeğini artırma veya azaltma işlemi devam ediyor. |
| Güncelleştirme Hatası | HDInsight, Otomatik Ölçeklendirme yapılandırma güncelleştirmesi sırasında sorunlarla karşılaştı. Müşteriler güncelleştirmeyi yeniden deneyebilir veya otomatik ölçeklendirmeyi devre dışı bırakabilir. |
| Hata | Kümede bir sorun var ve kullanılabilir değil. Bu kümeyi silin ve yeni bir küme oluşturun. |
Kümenizdeki geçerli düğüm sayısını görüntülemek için kümenizin Genel Bakış sayfasındaki Küme boyutu grafiğine gidin. İsterseniz Ayarlar altında Küme boyutu'nu da seçebilirsiniz.
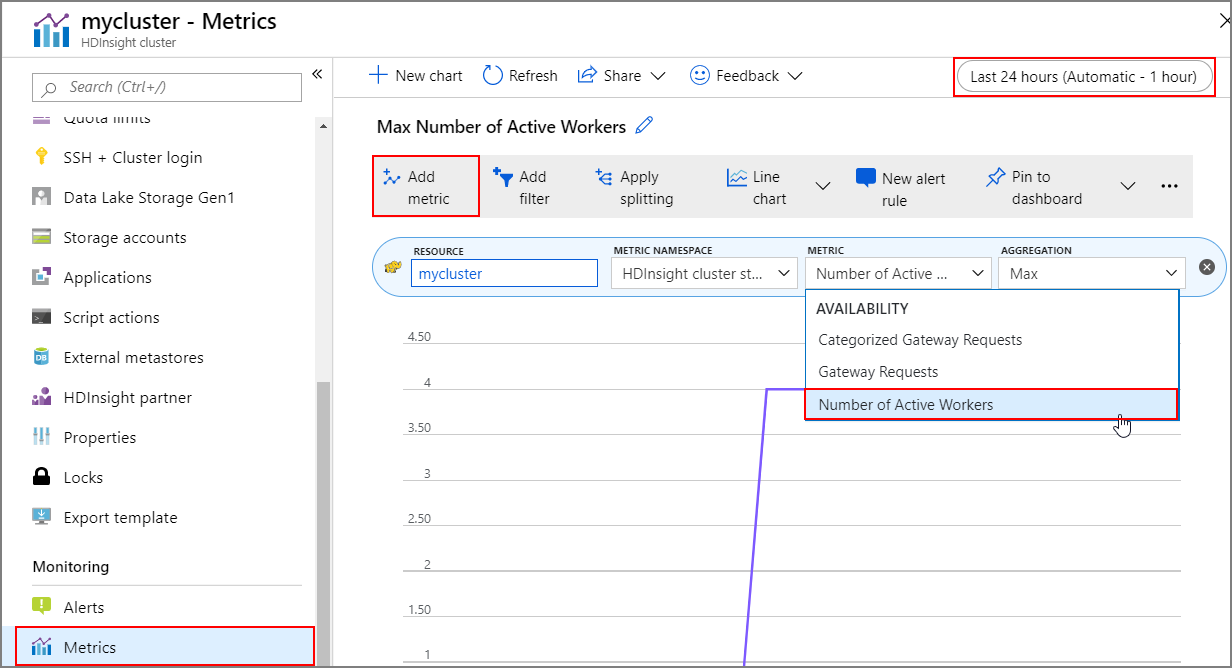
İşlem geçmişi
Küme ölçümlerinin bir parçası olarak küme ölçeğini artırma ve ölçeği azaltma geçmişini görüntüleyebilirsiniz. Ayrıca, son gün, hafta veya başka bir zaman aralığındaki tüm ölçeklendirme eylemlerini listeleyebilirsiniz.
İzleme'nin altında Ölçümler'i seçin. Ardından Ölçüm açılan kutusunda Ölçüm ekle ve Etkin Çalışan Sayısı'nı seçin. Zaman aralığını değiştirmek için sağ üstteki düğmeyi seçin.
En iyi yöntemler
Ölçeği artırma ve azaltma işlemlerinin gecikme süresini göz önünde bulundurun
Genel ölçeklendirme işleminin tamamlanması 10-20 dakika sürebilir. Özelleştirilmiş bir zamanlama ayarlarken bu gecikmeyi planlayın. Örneğin, küme boyutunun 09:00'da 20 olması gerekiyorsa, ölçeklendirme işleminin 09:00'a kadar tamamlanması için zamanlama tetikleyicisini 08:30 veya daha önceki bir saate ayarlayın.
Ölçeği azaltmaya hazırlanma
Küme ölçeğini azaltma işlemi sırasında Otomatik Ölçeklendirme, hedef boyutu karşılamak için düğümlerin yetkisini alır. Yük tabanlı otomatik ölçeklendirmede görevler bu düğümlerde çalışıyorsa Otomatik Ölçeklendirme, Spark ve Hadoop kümeleri için görevler tamamlanana kadar bekler. Her çalışan düğümü HDFS'de de bir rol üstlendiğinden, geçici veriler kalan çalışan düğümlerine kaydırılır. Tüm geçici verileri barındırmak için kalan düğümlerde yeterli alan olduğundan emin olun.
Not
Zamanlamaya dayalı Otomatik Ölçeklendirme ölçeğinin küçültülmesi durumunda, yetkisiz kullanımdan çıkarma desteklenmez. Bu, ölçeği azaltma işlemi sırasında iş hatalarına neden olabilir ve devam eden işlerin sonuçlandırılması için yeterli zamanı içerecek şekilde beklenen iş zamanlaması desenlerine göre zamanlamaların planlanması önerilir. İş hatalarını önlemek için, tamamlanma sürelerinin geçmişe yayılmasına bakarak zamanlamaları ayarlayabilirsiniz.
Kullanım deseni temelinde zamanlama tabanlı Otomatik Ölçeklendirme'yi yapılandırma
Zamanlama tabanlı Otomatik Ölçeklendirmeyi yapılandırırken küme kullanım düzeninizi anlamanız gerekir. Grafana panosu , sorgu yükünüzü ve yürütme yuvalarınızı anlamanıza yardımcı olabilir. Kullanılabilir yürütücü yuvalarını ve toplam yürütücü yuvalarını panodan alabilirsiniz.
Kaç çalışan düğümüne ihtiyaç duyulduğunu tahmin etmenin bir yolu aşağıdadır. İş yükünün çeşitlemesi için %10 arabellek daha vermenizi öneririz.
Kullanılan yürütücü yuvalarının sayısı = Toplam yürütücü yuvaları – Toplam kullanılabilir yürütücü yuvaları.
Gerekli çalışan düğümlerinin sayısı = Gerçekten kullanılan yürütücü yuvalarının sayısı / (hive.llap.daemon.num.executors + hive.llap.daemon.task.scheduler.wait.queue.size)
*hive.llap.daemon.num.executors yapılandırılabilir ve varsayılan değer 4'dür
*hive.llap.daemon.task.scheduler.wait.queue.size yapılandırılabilir ve varsayılan değer 10'dur
Özel Betik Eylemleri
Özel Betik Eylemleri çoğunlukla düğümleri (HeadNode / WorkerNodes) özelleştirmek için kullanılır ve bu da müşterilerimizin kendileri tarafından kullanılan belirli kitaplıkları ve araçları yapılandırmasına olanak tanır. Yaygın kullanım örneklerinden biri, kümede çalışan işlerin, Müşteriye ait olan üçüncü taraf kitaplığında bazı bağımlılıkları olabilir ve işin başarılı olması için düğümlerde kullanılabilir olması gerekir. Otomatik Ölçeklendirme için şu anda kalıcı olan özel betik eylemlerini destekliyoruz. Bu nedenle, ölçek artırma işleminin bir parçası olarak kümeye her yeni düğüm eklendiğinde, bu kalıcı betik eylemleri yürütülür ve kapsayıcıların veya işlerin bunlara ayrılacağını yayınlar. Özel betik eylemleri yeni düğümleri önyüklemeye yardımcı olsa da, genel ölçeği artırma gecikme süresini artıracağından ve zamanlanmış işleri etkilemeye neden olabileceğinden en düşük düzeyde tutmanız önerilir.
En düşük küme boyutuna dikkat edin
Kümenizin ölçeğini üçten az düğüme düşürmeyin. Kümenizin üçten az düğüme ölçeklenmesi, yetersiz dosya çoğaltması nedeniyle güvenli modda takılmasına neden olabilir. Daha fazla bilgi için bkz . Güvenli modda takılma.
Microsoft Entra Domain Services ve Ölçeklendirme İşlemleri
Microsoft Entra Domain Services yönetilen etki alanına katılmış Kurumsal Güvenlik Paketi (ESP) ile hdInsight kümesi kullanıyorsanız, Microsoft Entra Domain Services üzerindeki yükü azaltmanızı öneririz. Karmaşık dizin yapılarında kapsamlı eşitlemede ölçeklendirme işlemlerine etkisinden kaçınmanızı öneririz.
Yoğun kullanım senaryosu için Hive yapılandırmasını En Fazla Toplam Eşzamanlı Sorgu sayısı olarak ayarlayın
Otomatik ölçeklendirme olayları Ambari'de Hive yapılandırmasını En Fazla Toplam Eşzamanlı Sorgu sayısı olarak değiştirmez. Bu, Hive Server 2 Etkileşimli Hizmeti'nin, Etkileşimli Sorgu daemon sayısı yük ve zamanlamaya göre ölçeği artırılıp azaltılmış olsa bile herhangi bir noktada yalnızca belirli sayıda eşzamanlı sorguyu işleyebileceği anlamına gelir. Genel öneri, el ile müdahaleyi önlemek için en yüksek kullanım senaryosu için bu yapılandırmayı ayarlamaktır.
Ancak, yalnızca birkaç çalışan düğümü varsa ve toplam eşzamanlı sorgu sayısı üst sınırı çok yüksek yapılandırıldıysa Hive Server 2 yeniden başlatma hatasıyla karşılaşabilirsiniz. En azından, verilen Tez Ams sayısını (Toplam Eşzamanlı Sorgu Üst Sınırı yapılandırmasına eşittir) barındırabilecek en az çalışan düğümü sayısına ihtiyacınız vardır.
Sınırlamalar
Etkileşimli Sorgu Daemon sayısı
Otomatik ölçeklendirme özelliği etkin Etkileşimli Sorgu kümeleri varsa, otomatik ölçeklendirme yukarı/aşağı olayı da Etkileşimli Sorgu daemon'larının sayısını etkin çalışan düğümlerinin sayısına kadar artırır/küçültür. Daemon sayısındaki değişiklik Ambari'deki yapılandırmada num_llap_nodes kalıcı değildir. Hive hizmetleri el ile yeniden başlatılırsa, Ambari'deki yapılandırmaya göre Etkileşimli Sorgu daemon'larının sayısı sıfırlanır.
Etkileşimli Sorgu hizmeti el ile yeniden başlatılırsa, gelişmiş hive-interactive-env altındaki yapılandırmayı num_llap_node (Hive Etkileşimli Sorgu daemon'ını çalıştırmak için gereken düğüm sayısı) geçerli etkin çalışan düğümü sayısıyla eşleşecek şekilde el ile değiştirmeniz gerekir. Etkileşimli Sorgu Kümesi yalnızca Zamanlama Tabanlı Otomatik Ölçeklendirmeyi destekler
Sonraki adımlar
Kümeleri el ile ölçeklendirme yönergeleri hakkında bilgi için bkz. Ölçeklendirme yönergeleri