Visual Studio Code için Spark ve Hive Araçlarını kullanma
Visual Studio Code için Apache Spark & Hive Araçları'nı kullanmayı öğrenin. Apache Hive toplu işleri, etkileşimli Hive sorguları ve Apache Spark için PySpark betikleri oluşturmak ve göndermek için araçları kullanın. İlk olarak, Visual Studio Code'da Spark ve Hive Araçları'nın nasıl yükleneceğini açıklayacağız. Ardından Spark ve Hive Araçları'na iş gönderme adımlarını inceleyeceğiz.
Spark ve Hive Araçları, Visual Studio Code tarafından desteklenen platformlara yüklenebilir. Farklı platformlar için aşağıdaki önkoşullara dikkat edin.
Önkoşullar
Bu makaledeki adımları tamamlamak için aşağıdaki öğeler gereklidir:
- Bir Azure HDInsight kümesi. Küme oluşturmak için bkz . HDInsight'ı kullanmaya başlama. Ya da Apache Livy uç noktasını destekleyen bir Spark ve Hive kümesi kullanabilirsiniz.
- Visual Studio Code.
- Mono' ya. Mono yalnızca Linux ve macOS için gereklidir.
- Visual Studio Code için PySpark etkileşimli ortamı.
- Yerel dizin. Bu makalede C:\HD\HDexample kullanılır.
Spark ve Hive Araçlarını Yükleme
Önkoşulları karşıladıktan sonra, aşağıdaki adımları izleyerek Visual Studio Code için Spark & Hive Araçları'nı yükleyebilirsiniz:
Visual Studio Code'u açın.
Menü çubuğunda Uzantıları Görüntüle'ye >gidin.
Arama kutusuna Spark & Hive yazın.
Arama sonuçlarından Spark ve Hive Araçları'nı ve ardından Yükle'yi seçin:

Gerektiğinde Yeniden Yükle'yi seçin.
Çalışma klasörü açma
Visual Studio Code'da bir çalışma klasörü açmak ve dosya oluşturmak için şu adımları izleyin:
Menü çubuğundan Dosya>Klasör Aç... seçeneğine gidin.>C:\HD\HDexample ve ardından Klasör Seç düğmesini seçin. Klasör soldaki Gezgin görünümünde görünür.
Gezgin görünümünde HDexample klasörünü ve ardından iş klasörünün yanındaki Yeni Dosya simgesini seçin:
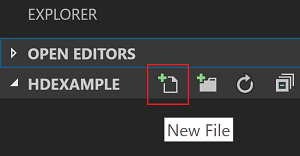
(Hive sorguları) veya (Spark betiği) dosya uzantısını
.pykullanarak.hqlyeni dosyayı adlandırın. Bu örnekte HelloWorld.hql kullanılır.
Azure ortamını ayarlama
Ulusal bir bulut kullanıcısı için, önce Azure ortamını ayarlamak için şu adımları izleyin ve ardından Azure'da oturum açmak için Azure: Oturum Aç komutunu kullanın:
Dosya>Tercihleri> Ayarlar'ne gidin.
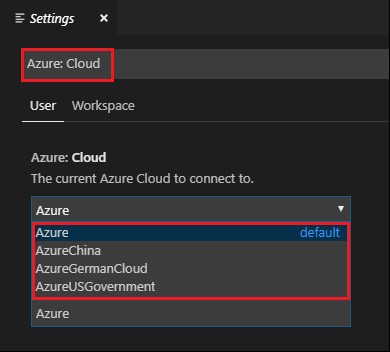
Şu dizede arama yapın: Azure: Cloud.
Listeden ulusal bulutu seçin:
Azure hesabına bağlanma
Visual Studio Code'dan kümelerinize betik gönderebilmeniz için önce kullanıcı Azure aboneliğinde oturum açabilir veya hdInsight kümesi bağlayabilir. HDInsight kümenize bağlanmak için ESP kümesi için Ambari kullanıcı adını/parolasını veya etki alanına katılmış kimlik bilgilerini kullanın. Azure'a bağlanmak için şu adımları izleyin:
Menü çubuğundan Komut Paletini Görüntüle>...'ye gidin ve Azure: Oturum Aç'ı girin:
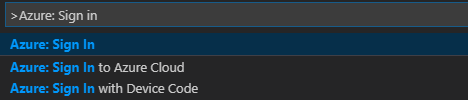
Azure'da oturum açmak için oturum açma yönergelerini izleyin. Bağlandıktan sonra, Visual Studio Code penceresinin altındaki durum çubuğunda Azure hesabınızın adı gösterilir.
Kümeyi bağlama
Bağlantı: Azure HDInsight
Apache Ambari tarafından yönetilen bir kullanıcı adı kullanarak normal bir kümeyi bağlayabilir veya etki alanı kullanıcı adı (örneğin: user1@contoso.com) kullanarak Kurumsal Güvenlik Paketi güvenli Hadoop kümesini bağlayabilirsiniz.
Menü çubuğundan Komut Paletini Görüntüle>... öğesine gidin ve Spark / Hive: Küme bağlama girin.

Azure HDInsight bağlı küme türünü seçin.
HDInsight kümesi URL'sini girin.
Ambari kullanıcı adınızı girin; varsayılan değer yöneticidir.
Ambari parolanızı girin.
Küme türünü seçin.
Kümenin görünen adını ayarlayın (isteğe bağlı).
Doğrulama için OUTPUT görünümünü gözden geçirin.
Not
Küme hem Azure aboneliğinde oturum açtıysa hem de bir kümeyi bağladıysa, bağlı kullanıcı adı ve parola kullanılır.
Bağlantı: Genel Livy uç noktası
Menü çubuğundan Komut Paletini Görüntüle>... öğesine gidin ve Spark / Hive: Küme bağlama girin.
Genel Livy Uç Noktası bağlı küme türünü seçin.
Genel Livy uç noktasını girin. Örneğin: http://10.172.41.42:18080.
Yetkilendirme türü Temel veya Hiçbiri'ni seçin. Temel'i seçerseniz:
Ambari kullanıcı adınızı girin; varsayılan değer yöneticidir.
Ambari parolanızı girin.
Doğrulama için OUTPUT görünümünü gözden geçirin.
Kümeleri listeleme
Menü çubuğundan Komut Paletini Görüntüle>... öğesine gidin ve Spark / Hive: Liste Kümesi girin.
İstediğiniz aboneliği seçin.
OUTPUT görünümünü gözden geçirin. Bu görünümde bağlı kümeniz (veya kümeleriniz) ve Azure aboneliğinizin altındaki tüm kümeler gösterilir:

Varsayılan kümeyi ayarlama
Kapatılırsa, daha önce açıklanan HDexample klasörünü yeniden açın.
Daha önce oluşturulan HelloWorld.hql dosyasını seçin. Betik düzenleyicisinde açılır.
Betik düzenleyicisine sağ tıklayın ve Spark / Hive: Varsayılan Kümeyi Ayarla'yı seçin.
Azure hesabınıza Bağlan veya henüz yapmadıysanız kümeyi bağlayın.
Geçerli betik dosyası için varsayılan küme olarak bir küme seçin. Araçlar, öğesini otomatik olarak güncelleştirir. VSCode\settings.json yapılandırma dosyası:

Etkileşimli Hive sorguları ve Hive toplu iş betikleri gönderme
Visual Studio Code için Spark ve Hive Araçları ile kümelerinize etkileşimli Hive sorguları ve Hive toplu iş betikleri gönderebilirsiniz.
Kapatılırsa, daha önce açıklanan HDexample klasörünü yeniden açın.
Daha önce oluşturulan HelloWorld.hql dosyasını seçin. Betik düzenleyicisinde açılır.
Aşağıdaki kodu kopyalayıp Hive dosyanıza yapıştırın ve kaydedin:
SELECT * FROM hivesampletable;Azure hesabınıza Bağlan veya henüz yapmadıysanız kümeyi bağlayın.
Sorguyu göndermek için betik düzenleyicisine sağ tıklayın ve Hive: Etkileşimli'yi seçin veya Ctrl+Alt+I klavye kısayolunu kullanın. Betiği göndermek için Hive: Batch'i seçin veya Ctrl+Alt+H klavye kısayolunu kullanın.
Varsayılan küme belirtmediyseniz bir küme seçin. Araçlar, bağlam menüsünü kullanarak betik dosyasının tamamı yerine bir kod bloğu göndermenize de olanak sağlar. Birkaç dakika sonra sorgu sonuçları yeni bir sekmede görünür:

SONUÇLAR paneli: Sonucun tamamını CSV, JSON veya Excel dosyası olarak yerel bir yola kaydedebilir veya yalnızca birden çok satır seçebilirsiniz.
MESAJLAR paneli: Bir Satır numarası seçtiğinizde, çalışan betiğin ilk satırına atlar.
Etkileşimli PySpark sorguları gönderme
Pyspark etkileşimli için önkoşul
HdInsight etkileşimli PySpark sorguları için Jupyter Uzantısı sürümünün (ms-jupyter): v2022.1.1001614873 ve Python Uzantısı sürümü (ms-python): v2021.12.1559732655, Python 3.6.x ve 3.7.x gerektiğini unutmayın.
Kullanıcılar PySpark etkileşimli işlemini aşağıdaki yollarla gerçekleştirebilir.
PY dosyasında PySpark etkileşimli komutunu kullanma
Sorguları göndermek için PySpark etkileşimli komutunu kullanarak şu adımları izleyin:
Kapatılırsa, daha önce açıklanan HDexample klasörünü yeniden açın.
Önceki adımları izleyerek yeni bir HelloWorld.py dosyası oluşturun.
Aşağıdaki kodu kopyalayıp betik dosyasına yapıştırın:
from operator import add from pyspark.sql import SparkSession spark = SparkSession.builder \ .appName('hdisample') \ .getOrCreate() lines = spark.read.text("/HdiSamples/HdiSamples/FoodInspectionData/README").rdd.map(lambda r: r[0]) counters = lines.flatMap(lambda x: x.split(' ')) \ .map(lambda x: (x, 1)) \ .reduceByKey(add) coll = counters.collect() sortedCollection = sorted(coll, key = lambda r: r[1], reverse = True) for i in range(0, 5): print(sortedCollection[i])PySpark/Synapse Pyspark çekirdeğini yükleme istemi pencerenin sağ alt köşesinde görüntülenir. PySpark/Synapse Pyspark yüklemelerine devam etmek için Yükle düğmesine tıklayabilir veya atla düğmesine tıklayarak bu adımı atlayabilirsiniz.
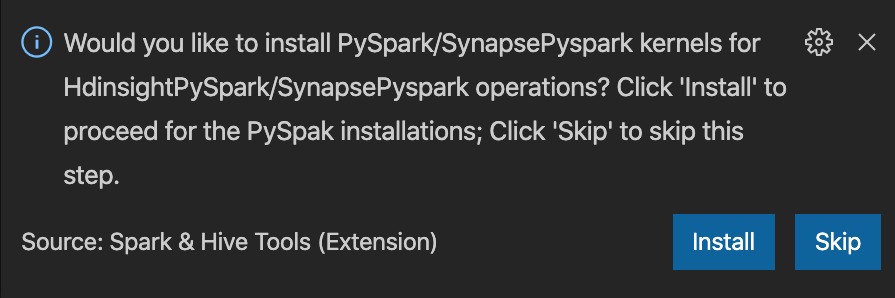
Daha sonra yüklemeniz gerekirse, Dosya>Tercihi> Ayarlar'ne gidip ayarlarda HDInsight: Pyspark Yüklemesini Atla seçeneğinin işaretini kaldırabilirsiniz.
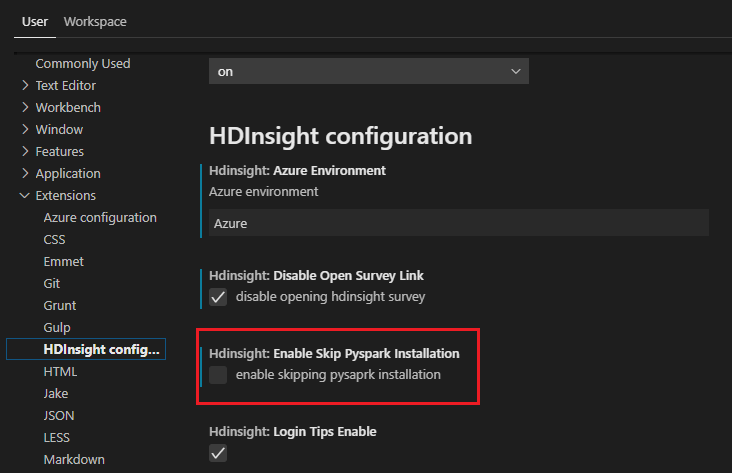
4. adımda yükleme başarılı olursa, pencerenin sağ alt köşesinde "PySpark başarıyla yüklendi" ileti kutusu görüntülenir. Pencereyi yeniden yüklemek için Yeniden Yükle düğmesine tıklayın.

Menü çubuğundan Komut Paletini Görüntüle>... öğesine gidin veya Shift + Ctrl + P klavye kısayolunu kullanın ve Python: Yorumlayıcı'yı seçerek Jupyter Server'ı başlatın.

Aşağıdaki Python seçeneğini belirleyin.

Menü çubuğundan Komut Paletini Görüntüle>... öğesine gidin veya Shift + Ctrl + P klavye kısayolunu kullanın ve Geliştirici: Pencereyi Yeniden Yükle yazın.

Azure hesabınıza Bağlan veya henüz yapmadıysanız kümeyi bağlayın.
Sorguyu göndermek için tüm kodu seçin, betik düzenleyicisine sağ tıklayın ve Spark: PySpark Interactive / Synapse: Pyspark Interactive'i seçin.
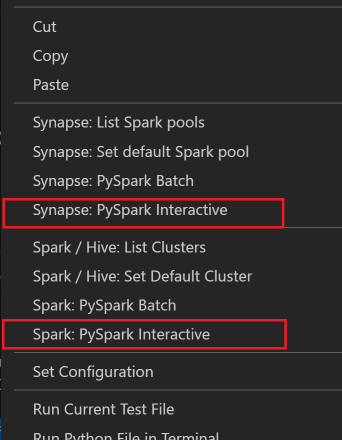
Varsayılan küme belirtmediyseniz kümeyi seçin. Birkaç dakika sonra Python Etkileşimli sonuçları yeni bir sekmede görünür. Çekirdeği PySpark /Synapse Pyspark'a geçmek için PySpark'a tıklayın; kod başarıyla çalışır. Synapse Pyspark çekirdeğine geçmek istiyorsanız Azure portalında otomatik ayarları devre dışı bırakmanız tavsiye edilir. Aksi takdirde kümeyi uyandırmak ve ilk kez kullanmak üzere synapse çekirdeğini ayarlamak uzun sürebilir. Araçlar, bağlam menüsünü kullanarak betik dosyasının tamamı yerine bir kod bloğu göndermenize de izin verirse:
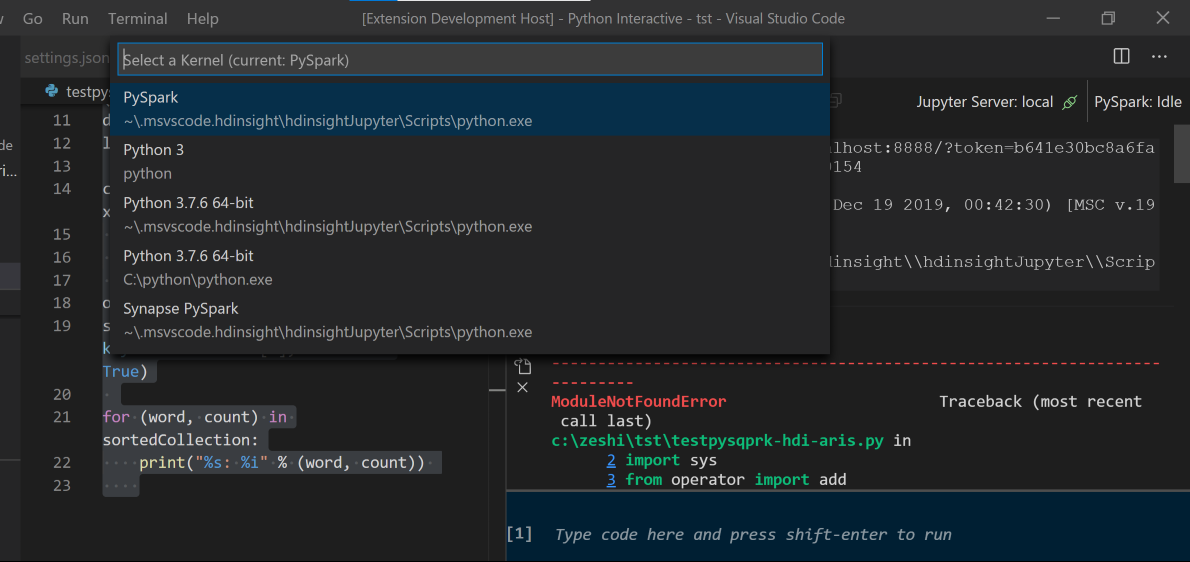
%%info yazın ve iş bilgilerini görüntülemek için Shift+Enter tuşlarına basın (isteğe bağlı):
Araç Spark SQL sorgusunu da destekler:

#%% açıklamasını kullanarak PY dosyasında etkileşimli sorgu gerçekleştirme
Not defteri deneyimi elde etmek için Py kodunun önüne ekleyin #%% .
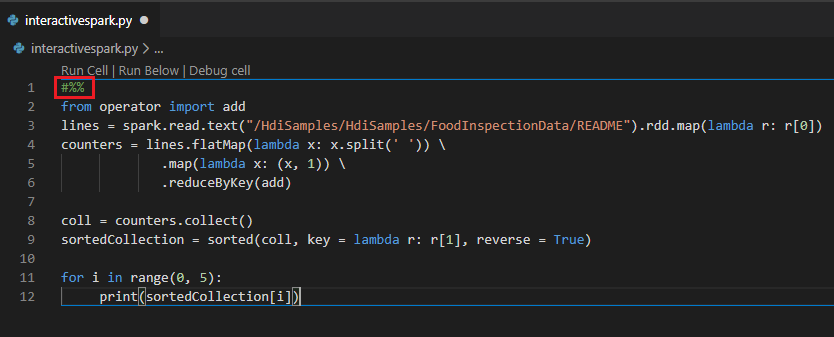
Hücreyi Çalıştır'a tıklayın. Birkaç dakika sonra Python Etkileşimli sonuçları yeni bir sekmede görünür. PySpark'a tıklayarak çekirdeği PySpark/Synapse PySpark'a geçirin ve ardından Hücreyi Yeniden Çalıştır'a tıklayın; kod başarıyla çalıştırılır.
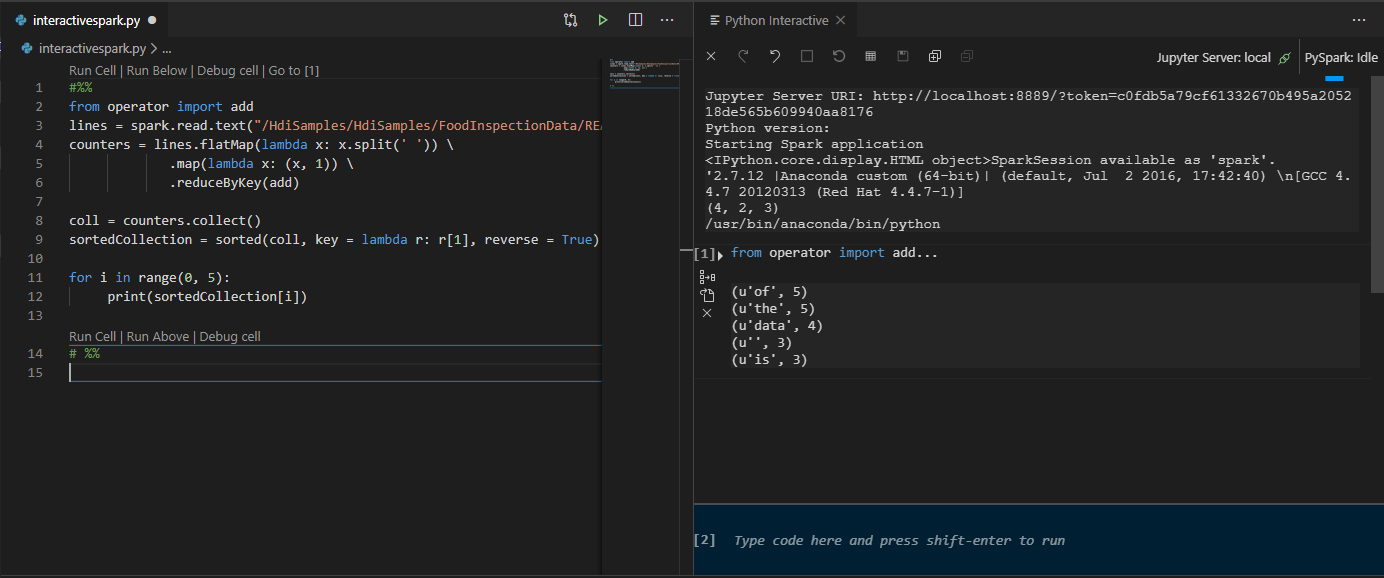
Python uzantısından IPYNB desteğinden yararlanma
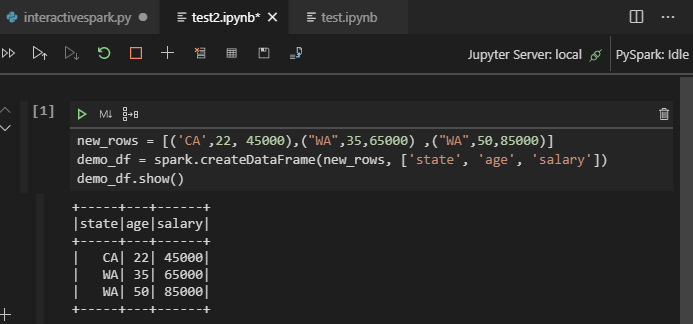
Komut Paleti'nden komutuyla veya çalışma alanınızda yeni bir .ipynb dosyası oluşturarak Jupyter Not Defteri oluşturabilirsiniz. Daha fazla bilgi için bkz . Visual Studio Code'da Jupyter Notebook'larla çalışma
Hücreyi çalıştır düğmesine tıklayın, istemleri izleyerek Varsayılan spark havuzunu ayarlayın (not defterini açmadan önce varsayılan kümeyi/havuzu her seferinde ayarlamayı kesinlikle teşvik edin) ve ardından Yeniden Yükle penceresi.

PySpark'a tıklayarak çekirdeği PySpark / Synapse Pyspark'a geçirin ve ardından Hücreyi Çalıştır'a tıklayın, bir süre sonra sonuç görüntülenir.
Not
Synapse PySpark yükleme hatası için, bağımlılığı artık diğer ekip tarafından korunmayacak olduğundan, bu da artık korunmayacaktır. Synapse Pyspark etkileşimli kullanmaya çalışıyorsanız lütfen bunun yerine Azure Synapse Analytics'i kullanmaya geçin. Ve bu uzun vadeli bir değişiklik.
PySpark toplu işini gönderme
Daha önce açıkladığınız HDexample klasörünü (kapatılırsa) yeniden açın.
Önceki adımları izleyerek yeni bir BatchFile.py dosyası oluşturun.
Aşağıdaki kodu kopyalayıp betik dosyasına yapıştırın:
from __future__ import print_function import sys from operator import add from pyspark.sql import SparkSession if __name__ == "__main__": spark = SparkSession\ .builder\ .appName("PythonWordCount")\ .getOrCreate() lines = spark.read.text('/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv').rdd.map(lambda r: r[0]) counts = lines.flatMap(lambda x: x.split(' '))\ .map(lambda x: (x, 1))\ .reduceByKey(add) output = counts.collect() for (word, count) in output: print("%s: %i" % (word, count)) spark.stop()Azure hesabınıza Bağlan veya henüz yapmadıysanız kümeyi bağlayın.
Betik düzenleyicisine sağ tıklayın ve spark: PySpark Batch veya Synapse: PySpark Batch* öğesini seçin.
PySpark işinizi göndermek için bir küme/spark havuzu seçin:

Bir Python işi gönderdikten sonra gönderme günlükleri Visual Studio Code'daki OUTPUT penceresinde görüntülenir. Spark UI URL'si ve Yarn UI URL'si de gösterilir. Toplu işi bir Apache Spark havuzuna gönderirseniz Spark geçmişi kullanıcı arabirimi URL'si ve Spark İşi Uygulaması Kullanıcı Arabirimi URL'si de gösterilir. İş durumunu izlemek için URL'yi bir web tarayıcısında açabilirsiniz.
HDInsight Kimlik Aracısı (HIB) ile tümleştirme
KIMLIK Aracısı (HIB) ile HDInsight ESP kümenize Bağlan
Kimlik Aracısı (HIB) ile HDInsight ESP kümenize bağlanmak için Azure aboneliğinde oturum açmak için normal adımları izleyebilirsiniz. Oturum açma işleminin ardından Azure Gezgini'nde küme listesini görürsünüz. Daha fazla yönerge için bkz. HDInsight kümenize Bağlan.
Kimlik Aracısı (HIB) ile HDInsight ESP kümesinde Hive/PySpark işi çalıştırma
Bir hive işi çalıştırmak için, kimlik aracısı (HIB) ile HDInsight ESP kümesine iş göndermek için normal adımları izleyebilirsiniz. Daha fazla yönerge için Etkileşimli Hive sorguları ve Hive toplu iş betikleri gönderme bölümüne bakın.
Etkileşimli bir PySpark işi çalıştırmak için, işi KIMLIK Aracısı (HIB) ile HDInsight ESP kümesine göndermek için normal adımları izleyebilirsiniz. Etkileşimli PySpark sorguları gönderme bölümüne bakın.
PySpark toplu işlemini çalıştırmak için, işi KIMLIK Aracısı (HIB) ile HDInsight ESP kümesine göndermek için normal adımları izleyebilirsiniz. Daha fazla yönerge için PySpark toplu işini gönderme bölümüne bakın.
Apache Livy yapılandırması
Apache Livy yapılandırması desteklenir. içinde yapılandırabilirsiniz. ÇALıŞMA alanı klasöründe VSCode\settings.json dosyası. Şu anda Livy yapılandırması yalnızca Python betiğini desteklemektedir. Daha fazla bilgi için bkz . Livy BENİOKU.
Livy yapılandırmasını tetikleme
1. Yöntem
- Menü çubuğundan Dosya>Tercihleri> Ayarlar'ne gidin.
- Arama ayarları kutusuna HDInsight İş Gönderimi: Livy Conf girin.
- İlgili arama sonucu için settings.json düzenle'yi seçin.
2. Yöntem
Bir dosya gönderin ve klasörün çalışma klasörüne otomatik olarak eklendiğine dikkat edin .vscode . Livy yapılandırmasını .vscode\settings.json'ı seçerek görebilirsiniz.
Proje ayarları:
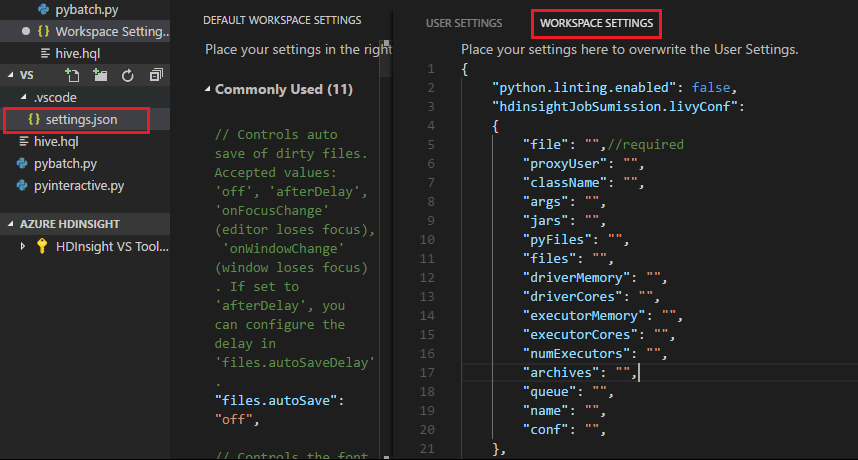
Not
driverMemory ve executorMemory ayarları için değeri ve birimi ayarlayın. Örneğin: 1g veya 1024m.
Desteklenen Livy yapılandırmaları:
POST /batches
İstek gövdesi
Adı açıklama Tür dosyası Yürütülecek uygulamayı içeren dosya Yol (gerekli) proxyUser İşi çalıştırırken kimliğine bürünecek kullanıcı String Classname Uygulama Java/Spark ana sınıfı String args Uygulama için komut satırı bağımsız değişkenleri Dize listesi Kavanoz Bu oturumda kullanılacak jar'lar Dize listesi pyFiles Bu oturumda kullanılacak Python dosyaları Dize listesi files Bu oturumda kullanılacak dosyalar Dize listesi driverMemory Sürücü işlemi için kullanılacak bellek miktarı String driverCores Sürücü işlemi için kullanılacak çekirdek sayısı Int executorMemory Yürütücü işlemi başına kullanılacak bellek miktarı String executorCores Her yürütücü için kullanılacak çekirdek sayısı Int numExecutors Bu oturum için başlatacak yürütücü sayısı Int Arşiv Bu oturumda kullanılacak arşivler Dize listesi kuyruk Gönderilecek YARN kuyruğunun adı String Adı Bu oturumun adı String conf Spark yapılandırma özellikleri key=val haritası Yanıt gövdesi Oluşturulan Batch nesnesi.
Adı açıklama Tür Kimlik Oturum kimliği Int appId Bu oturumun uygulama kimliği String Appinfo Ayrıntılı uygulama bilgileri key=val haritası Günlük Günlük satırları Dize listesi semt Toplu iş durumu String Not
Betiği gönderdiğinizde çıkış bölmesinde atanan Livy yapılandırması görüntülenir.
Explorer'dan Azure HDInsight ile tümleştirme
Hive Tablosu'nu kümelerinizde doğrudan Azure HDInsight gezgini aracılığıyla önizleyebilirsiniz:
En soldaki sütundan Azure simgesini seçin.
Sol bölmeden AZURE: HDINSIGHT'ı genişletin. Kullanılabilir abonelikler ve kümeler listelenir.
Hive meta veri veritabanını ve tablo şemasını görüntülemek için kümeyi genişletin.
Hive tablosuna sağ tıklayın. Örneğin: hivesampletable. Önizlemeyi seçin.
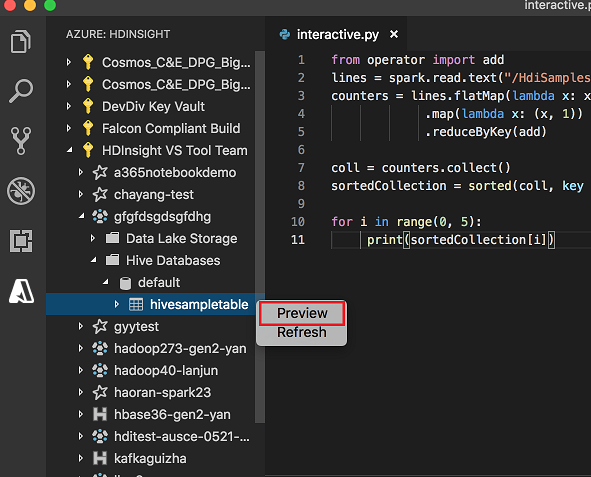
Sonuçları Önizle penceresi açılır:
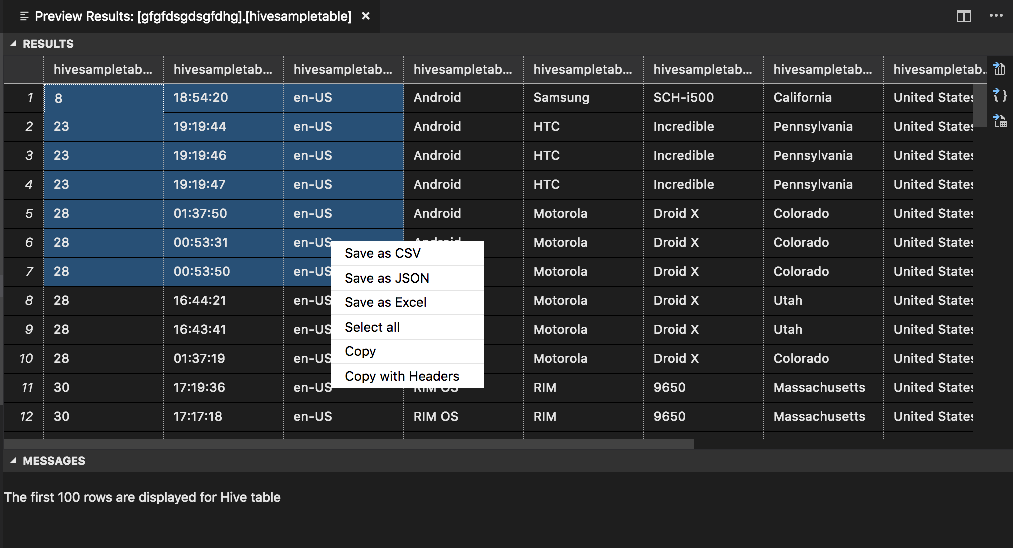
SONUÇLAR paneli
Sonucun tamamını CSV, JSON veya Excel dosyası olarak yerel bir yola kaydedebilir veya yalnızca birden çok satır seçebilirsiniz.
MESAJLAR paneli
Tablodaki satır sayısı 100'den büyük olduğunda şu iletiyi görürsünüz: "Hive tablosu için ilk 100 satır görüntüleniyor."
Tablodaki satır sayısı 100'den küçük veya buna eşit olduğunda şu iletiyi görürsünüz: "Hive tablosu için 60 satır görüntüleniyor."
Tabloda içerik olmadığında şu iletiyi görürsünüz: "
0 rows are displayed for Hive table."Not
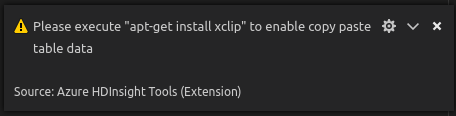
Linux'ta, tablo kopyalama verilerini etkinleştirmek için xclip'i yükleyin.
Ek özellikler
Visual Studio Code için Spark & Hive aşağıdaki özellikleri de destekler:
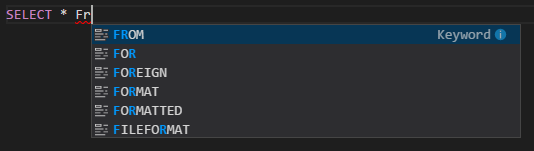
IntelliSense otomatik tamamlama. Anahtar sözcükler, yöntemler, değişkenler ve diğer programlama öğeleri için öneriler açılır. Farklı simgeler farklı nesne türlerini temsil eder:
IntelliSense hata işaretçisi. Dil hizmeti Hive betiğindeki düzenleme hatalarının altını çizer.
Söz dizimi vurguları. Dil hizmeti değişkenleri, anahtar sözcükleri, veri türünü, işlevleri ve diğer programlama öğelerini ayırt etmek için farklı renkler kullanır:

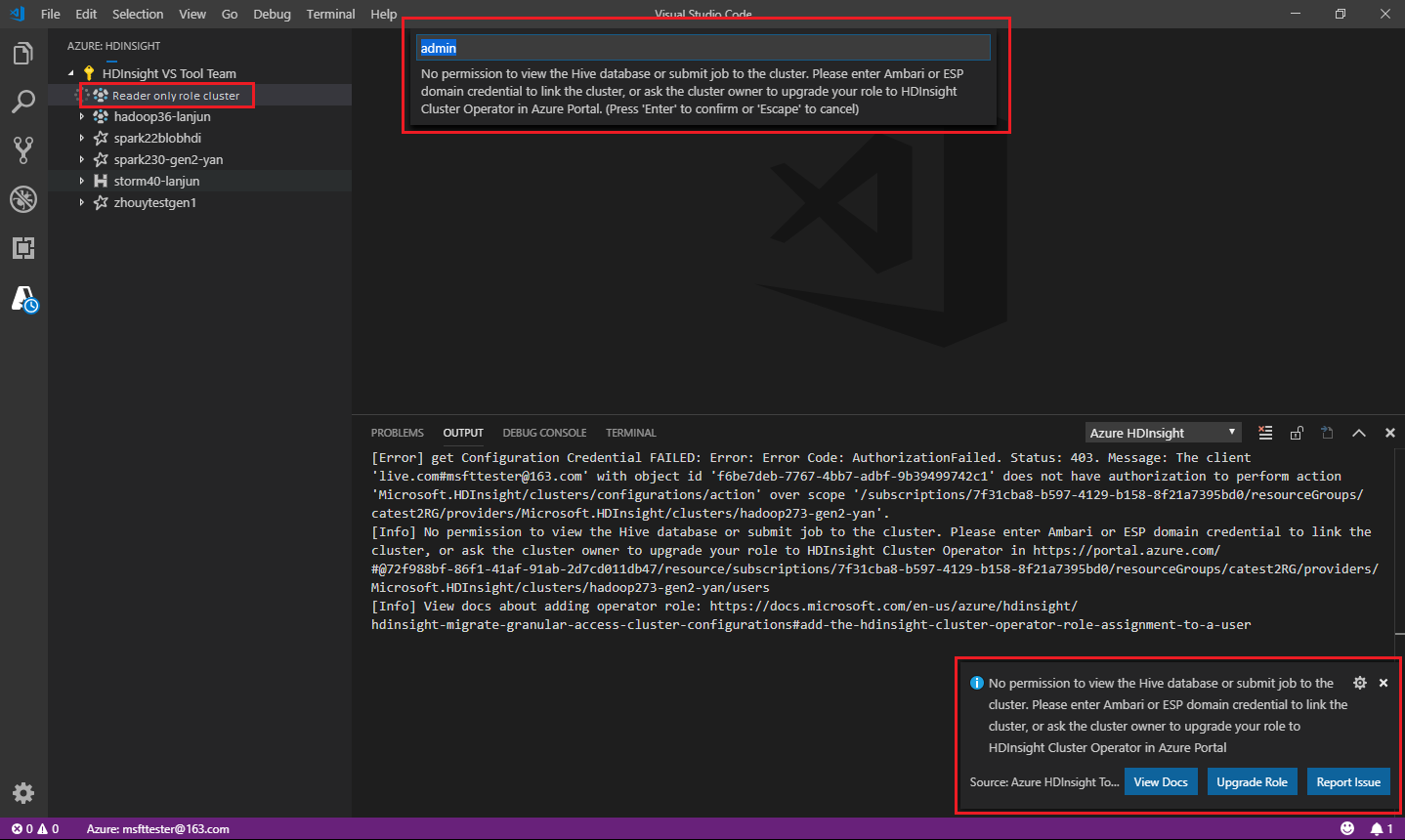
Yalnızca okuyucu rolü
Küme için yalnızca okuyucu rolü atanmış kullanıcılar HDInsight kümesine iş gönderemez veya Hive veritabanını görüntüleyemez. Rolünüzü Azure portalında HDInsight Küme Operatörü'ne yükseltmek için küme yöneticisine başvurun. Geçerli Ambari kimlik bilgileriniz varsa aşağıdaki kılavuzu kullanarak kümeyi el ile bağlayabilirsiniz.
HDInsight kümesine göz atma
HdInsight kümesini genişletmek için Azure HDInsight gezginini seçtiğinizde, küme için yalnızca okuyucu rolüne sahipseniz kümeyi bağlamanız istenir. Ambari kimlik bilgilerinizi kullanarak kümeye bağlanmak için aşağıdaki yöntemi kullanın.
İşi HDInsight kümesine gönderme
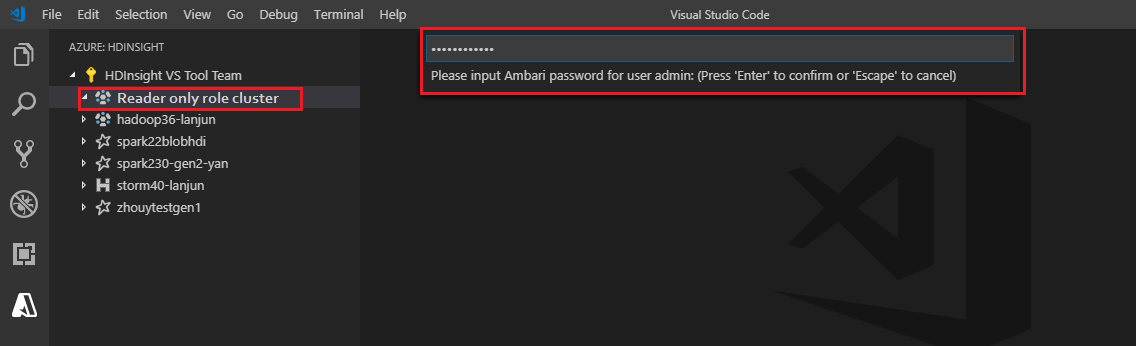
bir HDInsight kümesine iş gönderirken, küme için yalnızca okuyucu rolündeyseniz kümeyi bağlamanız istenir. Ambari kimlik bilgilerini kullanarak kümeye bağlanmak için aşağıdaki adımları kullanın.
Kümeye bağlantı
Geçerli bir Ambari kullanıcı adı girin.
Geçerli bir parola girin.
Not
Bağlı kümeyi denetlemek için kullanabilirsiniz
Spark / Hive: List Cluster:
Azure Data Lake Storage 2. Nesil
Data Lake Storage 2. Nesil hesabına göz atma
Data Lake Storage 2. Nesil hesabını genişletmek için Azure HDInsight gezginini seçin. Azure hesabınızın 2. Nesil depolamaya erişimi yoksa depolama erişim anahtarını girmeniz istenir. Erişim anahtarı doğrulandıktan sonra Data Lake Storage 2. Nesil hesabı otomatik olarak genişletilir.
Data Lake Storage 2. Nesil ile hdInsight kümesine iş gönderme
Data Lake Storage 2. Nesil kullanarak HDInsight kümesine iş gönderin. Azure hesabınızın 2. Nesil depolama alanına yazma erişimi yoksa depolama erişim anahtarını girmeniz istenir. Erişim anahtarı doğrulandıktan sonra iş başarıyla gönderilir.

Not
Depolama hesabının erişim anahtarını Azure portalından alabilirsiniz. Daha fazla bilgi için bkz . Depolama hesabı erişim anahtarlarını yönetme.
Kümenin bağlantısını kaldırma
Menü çubuğundan Komut Paletini Görüntüle'ye >gidin ve Spark / Hive: Küme bağlantısını kaldır yazın.
Bağlantısını kaldıracak bir küme seçin.
Doğrulama için ÇıKıŞ görünümüne bakın.
Oturumu kapat
Menü çubuğundan Komut Paletini Görüntüle'ye >gidin ve Azure: Oturumu Kapat yazın.
Bilinen Sorunlar
Synapse PySpark yükleme hatası.
Synapse PySpark yükleme hatası için bağımlılığı artık diğer ekip tarafından korunmayacağı için artık korunmaz. Synapse Pyspark etkileşimli kullanmaya çalışıyorsanız lütfen bunun yerine Azure Synapse Analytics'i kullanın. Ve bu uzun vadeli bir değişiklik.

Sonraki adımlar
Visual Studio Code için Spark & Hive kullanmayı gösteren bir video için bkz . Visual Studio Code için Spark & Hive.