Azure HDInsight’ta Apache Hive sorgularını iyileştirme
Bu makalede, Apache Hive sorgularınızın performansını geliştirmek için kullanabileceğiniz en yaygın performans iyileştirmelerinden bazıları açıklanmaktadır.
Küme türü seçimi
Azure HDInsight'ta apache Hive sorgularını birkaç farklı küme türünde çalıştırabilirsiniz.
İş yükü gereksinimleriniz için performansı iyileştirmeye yardımcı olması için uygun küme türünü seçin:
- için en iyi duruma getirmek için
ad hocEtkileşimli Sorgu kümesi türünü seçin. - Toplu işlem olarak kullanılan Hive sorgularını iyileştirmek için Apache Hadoop küme türünü seçin.
- Spark ve HBase küme türleri Hive sorguları da çalıştırabilir ve bu iş yüklerini çalıştırıyorsanız uygun olabilir.
Çeşitli HDInsight küme türlerinde Hive sorguları çalıştırma hakkında daha fazla bilgi için bkz . Azure HDInsight'ta Apache Hive ve HiveQL nedir?.
Çalışan düğümlerinin ölçeğini genişletme
HDInsight kümesindeki çalışan düğümlerinin sayısını artırmak, çalışmanın paralel olarak çalıştırılacak daha fazla eşleyici ve azaltıcı kullanmasına olanak tanır. HDInsight'ta ölçeği artırmanın iki yolu vardır:
Küme oluştururken Azure portalını, Azure PowerShell'i veya komut satırı arabirimini kullanarak çalışan düğümlerinin sayısını belirtebilirsiniz. Daha fazla bilgi için bkz. HDInsight kümesi oluşturma. Aşağıdaki ekran görüntüsünde Azure portalında çalışan düğümü yapılandırması gösterilmektedir:
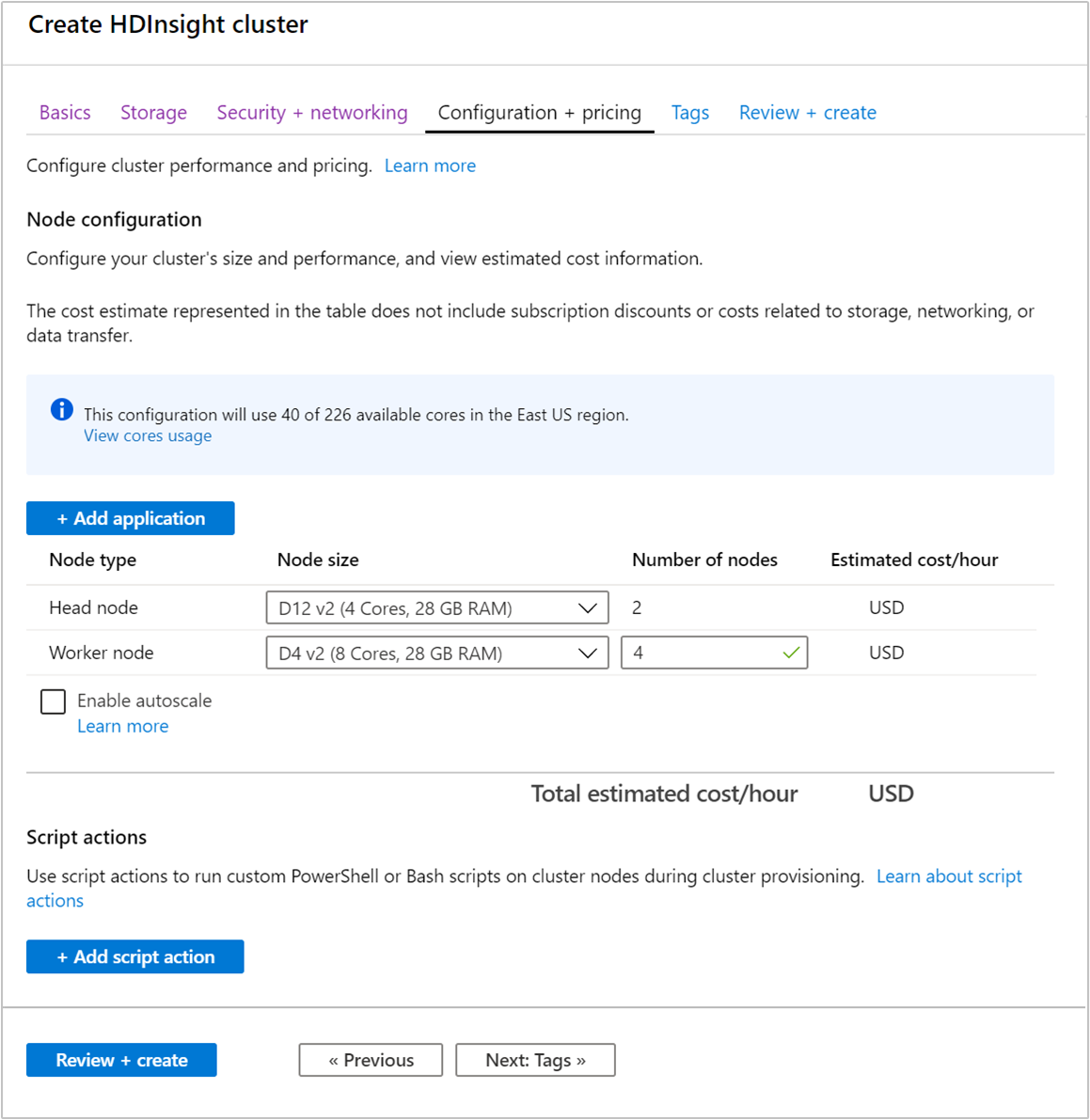
Oluşturulduktan sonra, kümenin ölçeğini yeniden oluşturmadan genişletmek için çalışan düğümlerinin sayısını da düzenleyebilirsiniz:

HDInsight'ı ölçeklendirme hakkında daha fazla bilgi için bkz . HDInsight kümelerini ölçeklendirme
Eşleme Azaltma yerine Apache Tez kullanma
Apache Tez , MapReduce altyapısına alternatif bir yürütme altyapısıdır. Linux tabanlı HDInsight kümelerinde Tez varsayılan olarak etkinleştirilmiştir.
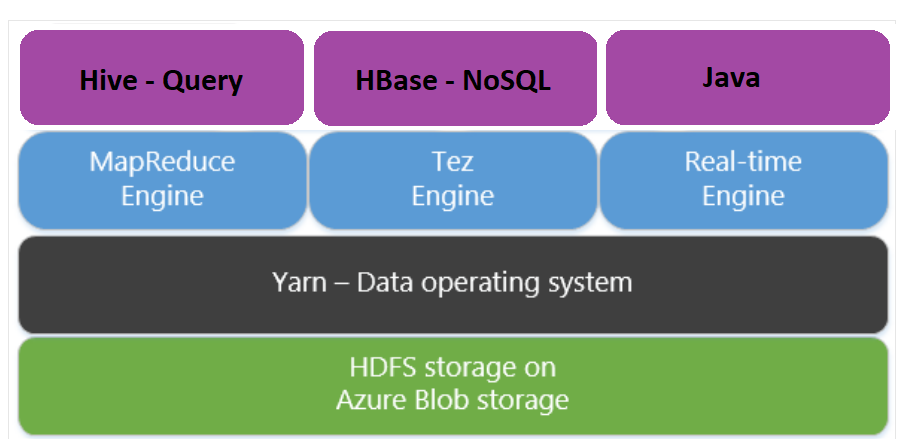
Tez daha hızlıdır çünkü:
- MapReduce altyapısında tek bir iş olarak Döngüsel Olmayan Yönlü Grafı (DAG) yürütün. DAG, her eşleyici kümesinin bir azaltıcı kümesi tarafından izlenmesini gerektirir. Bu gereksinim, her Hive sorgusu için birden çok MapReduce işinin kapatılmasına neden olur. Tez'in böyle bir kısıtlaması yoktur ve karmaşık DAG'yi iş başlatma ek yükünü en aza indiren tek bir iş olarak işleyebilir.
- Gereksiz yazmaları önler. MapReduce altyapısında aynı Hive sorgusunu işlemek için birden çok iş kullanılır. Her MapReduce işinin çıkışı ara veriler için HDFS'ye yazılır. Tez, her Hive sorgusu için iş sayısını en aza indirdiğinden, gereksiz yazma işlemlerini önleyebiliyor.
- Başlatma gecikmelerini en aza indirir. Tez, başlatması gereken eşleştirici sayısını azaltarak ve ayrıca iyileştirmeyi iyileştirerek başlatma gecikmesini en aza indirmeyi daha iyi sağlar.
- Kapsayıcıları yeniden kullanılır. Mümkün olduğunda Tez kapsayıcıları yeniden kullanarak kapsayıcıları başlatma gecikme süresinin azaldığından emin olun.
- Sürekli iyileştirme teknikleri. Geleneksel olarak iyileştirme, derleme aşamasında gerçekleştirilir. Ancak çalışma zamanı sırasında daha iyi iyileştirmeye olanak sağlayan girişler hakkında daha fazla bilgi sağlanır. Tez, planı çalışma zamanı aşamasına daha da iyileştirmek için sürekli iyileştirme tekniklerini kullanır.
Bu kavramlar hakkında daha fazla bilgi için bkz . Apache TEZ.
Aşağıdaki set komutuyla sorgunun ön ekini ekleyerek herhangi bir Hive sorgusunu Tez'in etkinleştirilmesini sağlayabilirsiniz:
set hive.execution.engine=tez;
Hive bölümleme
G/Ç işlemleri, Hive sorgularını çalıştırmaya yönelik önemli performans sorunlarıdır. Okunması gereken veri miktarı azaltılabilirse performans geliştirilebilir. Varsayılan olarak, Hive sorguları Hive tablolarının tamamını tarar. Ancak yalnızca az miktarda veriyi taraması gereken sorgularda (örneğin, filtrelemeli sorgular) bu davranış gereksiz ek yük oluşturur. Hive bölümleme, Hive sorgularının Yalnızca Hive tablolarındaki gerekli miktarda veriye erişmesini sağlar.
Hive bölümleme, ham veriler yeni dizinler halinde yeniden düzenlenerek uygulanır. Her bölümün kendi dosya dizini vardır. Kullanıcı bölümleyi tanımlar. Aşağıdaki diyagramda, Bir Hive tablosunu Year sütununa göre bölümleme gösterilmektedir. Her yıl için yeni bir dizin oluşturulur.
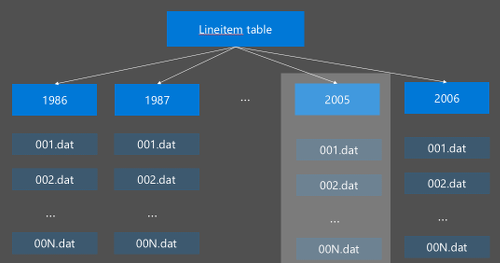
Bölümleme konusunda dikkat edilmesi gereken bazı noktalar:
- Bölüm altında kullanmayın - Yalnızca birkaç değere sahip sütunlarda bölümleme birkaç bölüme neden olabilir. Örneğin, cinsiyete göre bölümleme yalnızca oluşturulacak iki bölüm oluşturur (erkek ve kadın), bu nedenle gecikme süresini en fazla yarıya düşürün.
- Bölüm üzerinde işlem yapma - Diğer uçta ise benzersiz bir değere (örneğin, userid) sahip bir sütunda bölüm oluşturmak birden çok bölüme neden olur. Fazla bölüm, küme ad düğümünde çok fazla sayıda dizin işlemek zorunda olduğundan çok fazla strese neden olur.
- Veri dengesizliklerinden kaçının - Tüm bölümlerin eşit boyutta olması için bölümleme anahtarınızı akıllıca seçin. Örneğin, State sütununda bölümleme, veri dağılımını çarpıtabilir. California eyaleti vermont'un neredeyse 30 katı bir nüfusa sahip olduğundan bölüm boyutu büyük olasılıkla dengesizdir ve performans büyük ölçüde farklılık gösterebilir.
Bölümleme tablosu oluşturmak için Partitioned By yan tümcesini kullanın:
CREATE TABLE lineitem_part
(L_ORDERKEY INT, L_PARTKEY INT, L_SUPPKEY INT,L_LINENUMBER INT,
L_QUANTITY DOUBLE, L_EXTENDEDPRICE DOUBLE, L_DISCOUNT DOUBLE,
L_TAX DOUBLE, L_RETURNFLAG STRING, L_LINESTATUS STRING,
L_SHIPDATE_PS STRING, L_COMMITDATE STRING, L_RECEIPTDATE STRING,
L_SHIPINSTRUCT STRING, L_SHIPMODE STRING, L_COMMENT STRING)
PARTITIONED BY(L_SHIPDATE STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE;
Bölümlenmiş tablo oluşturulduktan sonra statik bölümleme veya dinamik bölümleme oluşturabilirsiniz.
Statik bölümleme , uygun dizinlerde zaten parçalanmış veriniz olduğu anlamına gelir. Statik bölümler ile hive bölümlerini dizin konumuna göre el ile eklersiniz. Aşağıdaki kod parçacığı bir örnektir.
INSERT OVERWRITE TABLE lineitem_part PARTITION (L_SHIPDATE = '5/23/1996 12:00:00 AM') SELECT * FROM lineitem WHERE lineitem.L_SHIPDATE = '5/23/1996 12:00:00 AM' ALTER TABLE lineitem_part ADD PARTITION (L_SHIPDATE = '5/23/1996 12:00:00 AM') LOCATION 'wasb://sampledata@ignitedemo.blob.core.windows.net/partitions/5_23_1996/'Dinamik bölümleme , Hive'ın sizin için otomatik olarak bölüm oluşturmasını istediğiniz anlamına gelir. Bölümleme tablosunu hazırlama tablosundan oluşturduğunuz için tek yapmanız gereken bölümlenmiş tabloya veri eklemektir:
SET hive.exec.dynamic.partition = true; SET hive.exec.dynamic.partition.mode = nonstrict; INSERT INTO TABLE lineitem_part PARTITION (L_SHIPDATE) SELECT L_ORDERKEY as L_ORDERKEY, L_PARTKEY as L_PARTKEY, L_SUPPKEY as L_SUPPKEY, L_LINENUMBER as L_LINENUMBER, L_QUANTITY as L_QUANTITY, L_EXTENDEDPRICE as L_EXTENDEDPRICE, L_DISCOUNT as L_DISCOUNT, L_TAX as L_TAX, L_RETURNFLAG as L_RETURNFLAG, L_LINESTATUS as L_LINESTATUS, L_SHIPDATE as L_SHIPDATE_PS, L_COMMITDATE as L_COMMITDATE, L_RECEIPTDATE as L_RECEIPTDATE, L_SHIPINSTRUCT as L_SHIPINSTRUCT, L_SHIPMODE as L_SHIPMODE, L_COMMENT as L_COMMENT, L_SHIPDATE as L_SHIPDATE FROM lineitem;
Daha fazla bilgi için bkz . Bölümlenmiş Tablolar.
ORCFile biçimini kullanma
Hive farklı dosya biçimlerini destekler. Örneğin:
- Metin: varsayılan dosya biçimidir ve çoğu senaryoyla çalışır.
- Avro: Birlikte çalışabilirlik senaryoları için iyi çalışır.
- ORC/Parquet: Performans için en uygun olanıdır.
ORC (İyileştirilmiş Satır Sütunlu) biçimi Hive verilerini depolamanın son derece verimli bir yoludur. ORC, diğer biçimlerle karşılaştırıldığında aşağıdaki avantajlara sahiptir:
- DateTime ve karmaşık ve yarı yapılandırılmış türler de dahil olmak üzere karmaşık türler için destek.
- %70'e kadar sıkıştırma.
- her 10.000 satırı dizine alır ve bu da satırları atlar.
- çalışma zamanı yürütmesinde önemli bir düşüş.
ORC biçimini etkinleştirmek için önce ORC olarak depolanan yan tümcesiyle bir tablo oluşturursunuz:
CREATE TABLE lineitem_orc_part
(L_ORDERKEY INT, L_PARTKEY INT,L_SUPPKEY INT, L_LINENUMBER INT,
L_QUANTITY DOUBLE, L_EXTENDEDPRICE DOUBLE, L_DISCOUNT DOUBLE,
L_TAX DOUBLE, L_RETURNFLAG STRING, L_LINESTATUS STRING,
L_SHIPDATE_PS STRING, L_COMMITDATE STRING, L_RECEIPTDATE STRING,
L_SHIPINSTRUCT STRING, L_SHIPMODE STRING, L_COMMENT STRING)
PARTITIONED BY(L_SHIPDATE STRING)
STORED AS ORC;
Ardından, hazırlama tablosundan ORC tablosuna veri eklersiniz. Örneğin:
INSERT INTO TABLE lineitem_orc
SELECT L_ORDERKEY as L_ORDERKEY,
L_PARTKEY as L_PARTKEY ,
L_SUPPKEY as L_SUPPKEY,
L_LINENUMBER as L_LINENUMBER,
L_QUANTITY as L_QUANTITY,
L_EXTENDEDPRICE as L_EXTENDEDPRICE,
L_DISCOUNT as L_DISCOUNT,
L_TAX as L_TAX,
L_RETURNFLAG as L_RETURNFLAG,
L_LINESTATUS as L_LINESTATUS,
L_SHIPDATE as L_SHIPDATE,
L_COMMITDATE as L_COMMITDATE,
L_RECEIPTDATE as L_RECEIPTDATE,
L_SHIPINSTRUCT as L_SHIPINSTRUCT,
L_SHIPMODE as L_SHIPMODE,
L_COMMENT as L_COMMENT
FROM lineitem;
Apache Hive Dili kılavuzunda ORC biçimi hakkında daha fazla bilgi edinebilirsiniz.
Vektörleştirme
Vektörleştirme, Hive'ın bir kerede bir satır işlemek yerine 1024 satırlık bir toplu işlemi birlikte işlemesine olanak tanır. Bu, daha az iç kodun çalıştırılması gerektiğinden basit işlemlerin daha hızlı yapıldığı anlamına gelir.
Hive sorgunuzun vektörleştirme ön ekini etkinleştirmek için aşağıdaki ayara sahip olun:
set hive.vectorized.execution.enabled = true;
Daha fazla bilgi için bkz . Vektörleştirilmiş sorgu yürütme.
Diğer iyileştirme yöntemleri
Göz önünde bulundurabileceğiniz daha fazla iyileştirme yöntemi vardır, örneğin:
- Hive demetleme: Sorgu performansını iyileştirmek için büyük veri kümelerini kümelemenize veya segmentlere ayırmanıza olanak tanıyan bir tekniktir.
- Birleştirme iyileştirmesi: Birleştirmelerin verimliliğini artırmak ve kullanıcı ipuçları ihtiyacını azaltmak için Hive'ın sorgu yürütme planlamasının iyileştirilmesi. Daha fazla bilgi için bkz . Birleştirme iyileştirmesi.
- Azaltıcıları artırın.
Sonraki adımlar
Bu makalede, birçok yaygın Hive sorgu iyileştirme yöntemi öğrendiniz. Daha fazla bilgi için aşağıdaki makalelere bakın: