HDInsight kümesi için Apache Spark uygulamaları oluşturmak üzere IntelliJ için Azure Toolkit kullanma
Bu makalede, IntelliJ IDE için Azure Toolkit eklentisini kullanarak Azure HDInsight üzerinde Apache Spark uygulamaları geliştirme adımları gösterilmektedir. Azure HDInsight , bulutta yönetilen, açık kaynaklı bir analiz hizmetidir. Hizmet Hadoop, Apache Spark, Apache Hive ve Apache Kafka gibi açık kaynak çerçeveleri kullanmanıza olanak tanır.
Azure Toolkit eklentisini birkaç yolla kullanabilirsiniz:
- Scala Spark uygulaması geliştirin ve hdInsight Spark kümesine gönderin.
- Azure HDInsight Spark kümesi kaynaklarınıza erişin.
- Scala Spark uygulamasını yerel olarak geliştirin ve çalıştırın.
Bu makalede şunları öğreneceksiniz:
- Azure Toolkit for IntelliJ eklentisini kullanma
- Apache Spark uygulamaları geliştirme
- Azure HDInsight kümesine uygulama gönderme
Önkoşullar
HDInsight üzerinde bir Apache Spark kümesi. Yönergeler için bkz. Azure HDInsight'ta Apache Spark kümeleri oluşturma. Diğer güvenli bulut türleri (ör. kamu bulutları) desteklenmezken yalnızca genel buluttaki HDInsight kümeleri desteklenir.
Oracle Java Geliştirme seti. Bu makalede Java sürüm 8.0.202 kullanılır.
IntelliJ IDEA. Bu makalede IntelliJ IDEA Community 2018.3.4 kullanılır.
IntelliJ için Azure Toolkit. Bkz . IntelliJ için Azure Toolkit'i yükleme.
IntelliJ IDEA için Scala eklentisini yükleme
Scala eklentisini yükleme adımları:
IntelliJ IDEA’yı açın.
Hoş geldiniz ekranında Eklentileri Yapılandır'a >gidip Eklentiler penceresini açın.
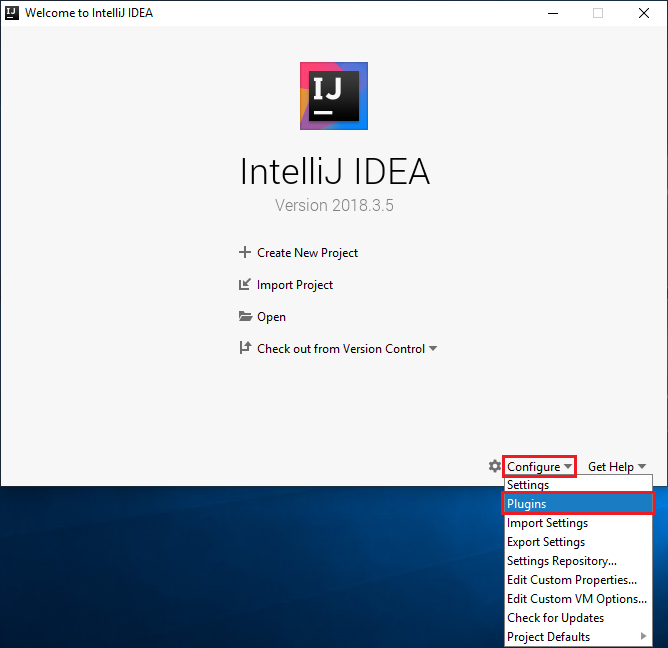
Yeni pencerede öne çıkan Scala eklentisi için Yükle'yi seçin.
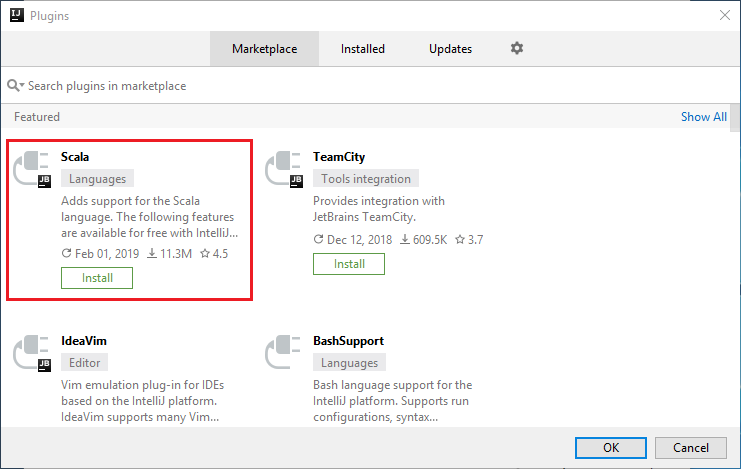
Eklenti başarıyla yüklendikten sonra IDE’yi yeniden başlatmanız gerekir.
HDInsight Spark kümesi için Spark Scala uygulaması oluşturma
IntelliJ IDEA'yı başlatın ve Yeni Proje Oluştur'u seçerek Yeni Proje penceresini açın.
Sol bölmeden Azure Spark/HDInsight'ı seçin.
Ana pencerede Spark Projesi (Scala) öğesini seçin.
Derleme aracı açılan listesinden aşağıdaki seçeneklerden birini belirleyin:
Scala için Maven proje oluşturma sihirbazı desteği.
Scala projesi için bağımlılıkları yönetmeye ve oluşturmaya yönelik SBT .
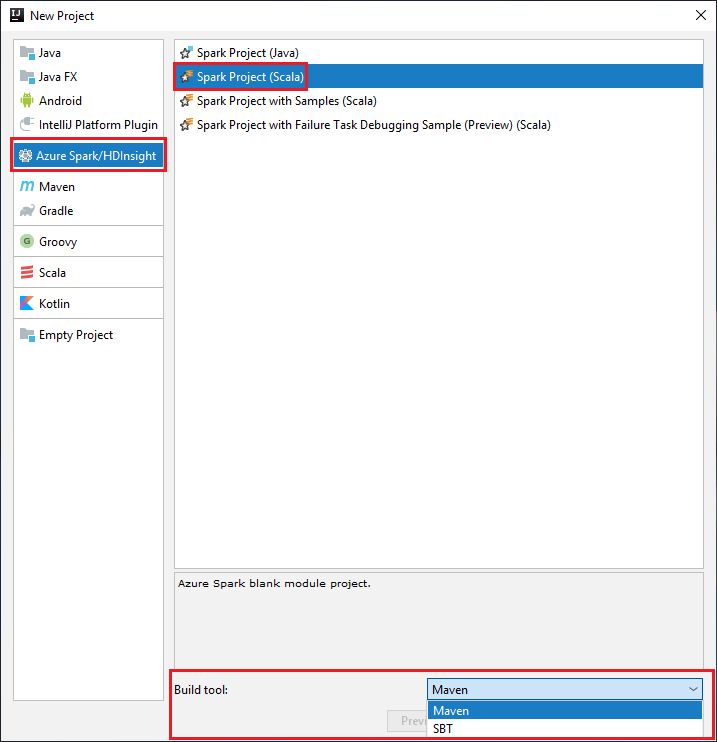
İleri'yi seçin.
Yeni Proje penceresinde aşağıdaki bilgileri sağlayın:
Özellik Açıklama Proje adı Bir ad girin. Bu makalede kullanılır myApp.Proje konumu Projenizi kaydetmek için konumu girin. Proje SDK'sı Idea'nın ilk kullanımında bu alan boş olabilir. Yeni... öğesini seçin ve JDK'nize gidin. Spark Sürümü Oluşturma sihirbazı, Spark SDK ve Scala SDK'sı için uygun sürümü tümleştirir. Spark kümesi sürümü 2.0’dan eskiyse Spark 1.x seçeneğini belirleyin. Aksi takdirde, Spark2.x seçeneğini belirleyin. Bu örnekte Spark 2.3.0 (Scala 2.11.8) kullanılır. 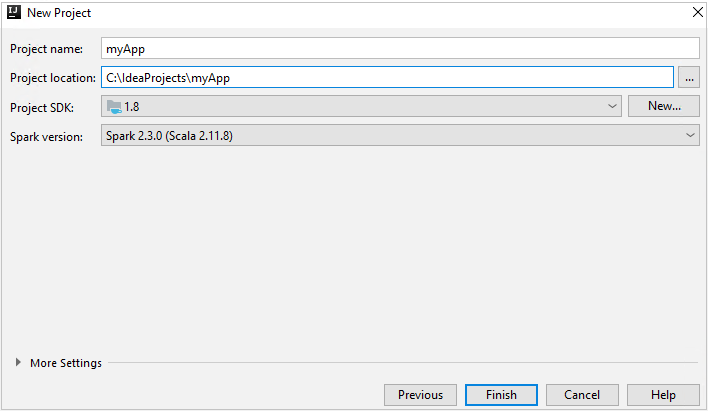
Bitir'i seçin. Projenin kullanılabilir duruma gelmesi birkaç dakika sürebilir.
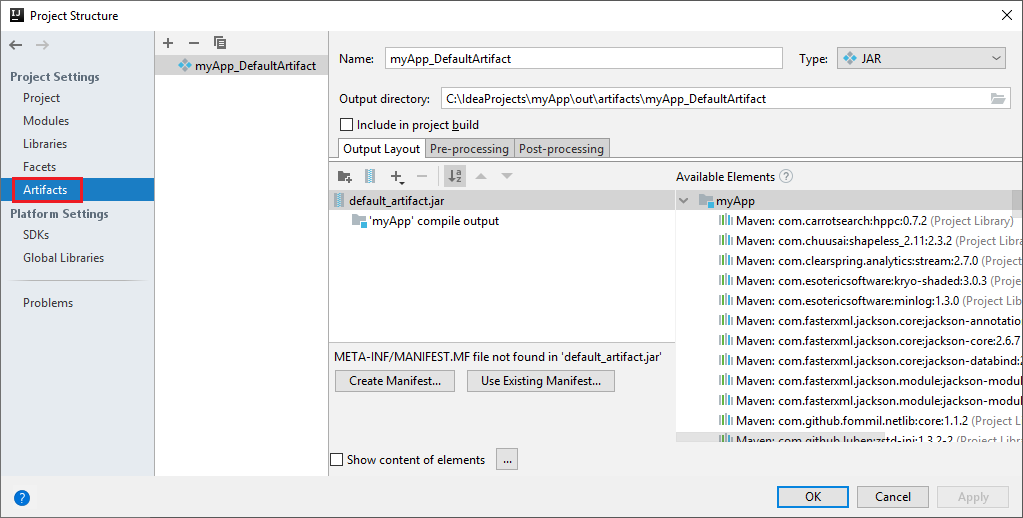
Spark projesi sizin için otomatik olarak bir yapıt oluşturur. Yapıtı görüntülemek için aşağıdaki adımları uygulayın:
a. Menü çubuğundan Dosya>Proje Yapısı.... seçeneğine gidin.
b. Proje Yapısı penceresinde Yapıtlar'ı seçin.
c. Yapıtı görüntüledikten sonra İptal'i seçin.
Aşağıdaki adımları uygulayarak uygulama kaynak kodunuzu ekleyin:
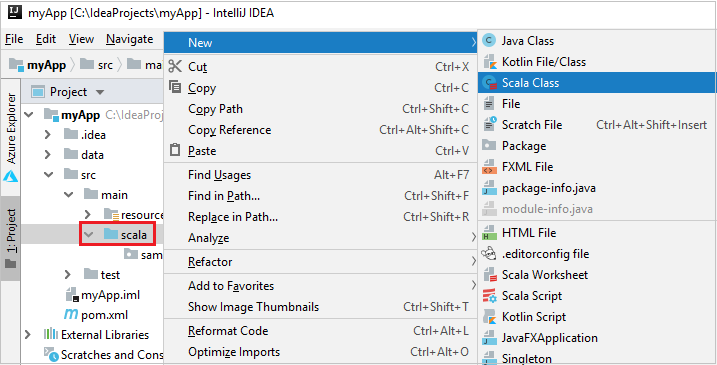
a. Project'ten myApp>src>ana>scala'ya gidin.
b. Scala'ya sağ tıklayın ve Yeni>Scala Sınıfı'na gidin.
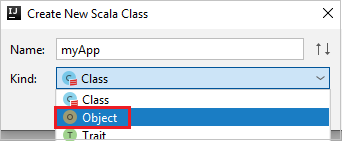
c. Yeni Scala Sınıfı Oluştur iletişim kutusunda bir ad girin, Tür açılan listesinde Nesne'yi seçin ve ardından Tamam'ı seçin.
d. Ardından myApp.scala dosyası ana görünümde açılır. Varsayılan kodu aşağıda bulunan kodla değiştirin:
import org.apache.spark.SparkConf import org.apache.spark.SparkContext object myApp{ def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("myApp") val sc = new SparkContext(conf) val rdd = sc.textFile("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") //find the rows that have only one digit in the seventh column in the CSV file val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) rdd1.saveAsTextFile("wasbs:///HVACOut") } }Kod, HVAC.csv verileri okur (tüm HDInsight Spark kümelerinde kullanılabilir), CSV dosyasındaki yedinci sütunda yalnızca bir basamak bulunan satırları alır ve çıkışı
/HVACOutküme için varsayılan depolama kapsayıcısının altına yazar.
HDInsight kümenize Bağlan
Kullanıcı Azure aboneliğinizde oturum açabilir veya bir HDInsight kümesi bağlayabilir. HDInsight kümenize bağlanmak için Ambari kullanıcı adını/parolasını veya etki alanına katılmış kimlik bilgilerini kullanın.
Azure aboneliğinizde oturum açın
Menü çubuğundan Görünüm>Aracı Windows>Azure Gezgini'ne gidin.
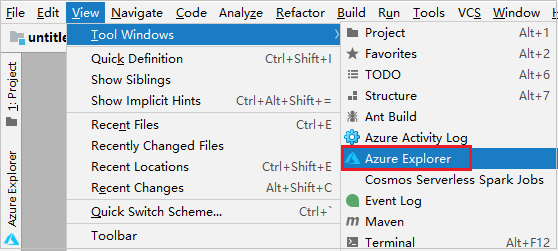
Azure Gezgini'nde Azure düğümüne sağ tıklayıp Oturum Aç'ı seçin.
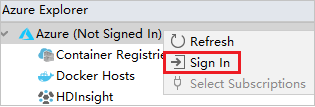
Azure Oturum Aç iletişim kutusunda Cihaz Oturum Açma'yı ve ardından Oturum aç'ı seçin.
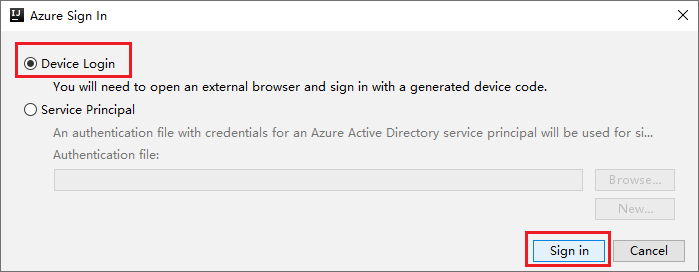
Azure Cihaz Oturum Açma iletişim kutusunda Kopyala ve Aç'a tıklayın.

Tarayıcı arabiriminde kodu yapıştırın ve İleri'ye tıklayın.

Azure kimlik bilgilerinizi girin ve tarayıcıyı kapatın.
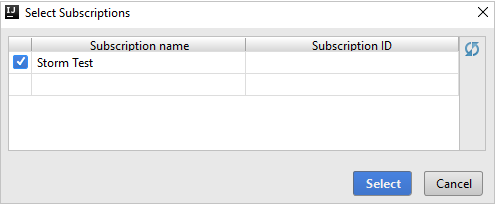
Oturum açtıktan sonra Abonelikleri Seç iletişim kutusunda, kimlik bilgileriyle ilişkili tüm Azure abonelikleri listelenir. Aboneliğinizi ve ardından Seç düğmesini seçin.
Azure Gezgini'nde HDInsight'ı genişleterek aboneliklerinizdeki HDInsight Spark kümelerini görüntüleyin.
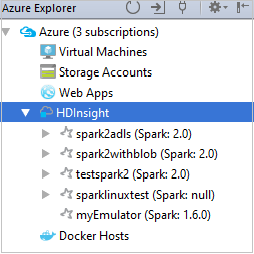
Kümeyle ilişkili kaynakları (örneğin, depolama hesapları) görüntülemek için bir küme adı düğümünü daha da genişletebilirsiniz.

Kümeyi bağlama
Apache Ambari tarafından yönetilen kullanıcı adını kullanarak HDInsight kümesini bağlayabilirsiniz. Benzer şekilde, etki alanına katılmış bir HDInsight kümesi için, etki alanını ve kullanıcı adını kullanarak bağlantı oluşturabilirsiniz; örneğin user1@contoso.com. Ayrıca Livy Service kümesini de bağlayabilirsiniz.
Menü çubuğundan Görünüm>Aracı Windows>Azure Gezgini'ne gidin.
Azure Gezgini'nden HDInsight düğümüne sağ tıklayın ve ardından Küme Bağla'yı seçin.
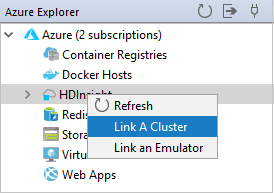
Kümeyi Bağla penceresindeki kullanılabilir seçenekler, Kaynak Türünü Bağla açılan listesinden seçtiğiniz değere bağlı olarak değişir. Değerlerinizi girin ve Tamam'ı seçin.
HDInsight Kümesi
Özellik Değer Bağlantı Kaynak Türü Açılan listeden HDInsight Kümesi'ni seçin. Küme Adı/URL Küme adını girin. Kimlik Doğrulaması Türü Temel Kimlik Doğrulaması olarak bırakın User Name Küme kullanıcı adını girin; varsayılan değer yöneticidir. Parola Kullanıcı adı için parola girin. 
Livy Hizmeti
Özellik Değer Bağlantı Kaynak Türü Açılan listeden Livy Service'i seçin. Livy Uç Noktası Livy Uç Noktası girin Küme Adı Küme adını girin. Yarn Uç Noktası isteğe bağlı. Kimlik Doğrulaması Türü Temel Kimlik Doğrulaması olarak bırakın User Name Küme kullanıcı adını girin; varsayılan değer yöneticidir. Parola Kullanıcı adı için parola girin. 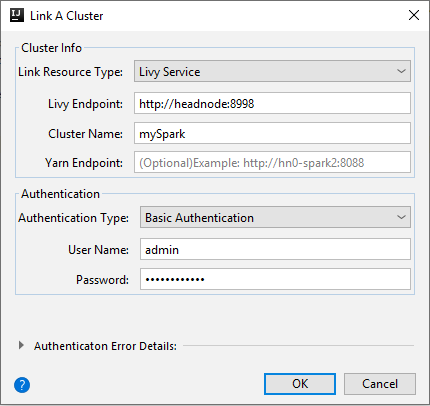
Bağlı kümenizi HDInsight düğümünden görebilirsiniz.
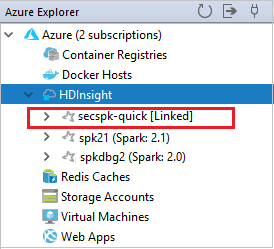
Ayrıca bir kümenin Azure Gezgini bağlantısını da kaldırabilirsiniz.
HDInsight Spark kümesinde Spark Scala uygulaması çalıştırma
Scala uygulamasını oluşturduktan sonra kümeye gönderebilirsiniz.
Project'ten myApp>src>main>scala myApp konumuna>gidin. Uygulamam'a sağ tıklayın ve Spark Uygulaması Gönder'i seçin (Büyük olasılıkla listenin en altında bulunur).
Spark Uygulaması Gönder iletişim kutusunda 1'i seçin. HDInsight üzerinde Spark.
Yapılandırmayı düzenle penceresinde aşağıdaki değerleri sağlayın ve Tamam'ı seçin:
Özellik Değer Spark kümeleri (yalnızca Linux) Uygulamanızı çalıştırmak istediğiniz HDInsight Spark kümesini seçin. Göndermek için bir Yapıt seçin Varsayılan ayarı değiştirmeyin. Ana sınıf adı Varsayılan değer, seçili dosyadaki ana sınıftır. Üç noktayı (...) ve başka bir sınıfı seçerek sınıfı değiştirebilirsiniz. İş yapılandırmaları Varsayılan anahtarları ve veya değerleri değiştirebilirsiniz. Daha fazla bilgi için bkz . Apache Livy REST API. Komut satırı bağımsız değişkenleri Gerekirse, ana sınıf için boşlukla ayrılmış bağımsız değişkenler girebilirsiniz. Başvuruda Belirtilen Jar'lar ve Başvurulan Dosyalar Başvuruda bulunan Jar'ların ve varsa dosyaların yollarını girebilirsiniz. Şu anda yalnızca ADLS 2. Nesil kümesini destekleyen Azure sanal dosya sistemindeki dosyalara da göz atabilirsiniz. Daha fazla bilgi için: Apache Spark Yapılandırması. Ayrıca bkz. Kaynakları kümeye yükleme. İş Yükleme Depolama Ek seçenekleri göstermek için genişletin. Depolama Türü Açılan listeden Karşıya yüklemek için Azure Blobunu kullan'ı seçin. Depolama Hesabı Depolama hesabınızı girin. Depolama Anahtarı Depolama anahtarınızı girin. kapsayıcıyı Depolama Hesap ve Depolama Depolama Anahtarı girildikten sonra açılan listeden depolama kapsayıcınızı seçin. 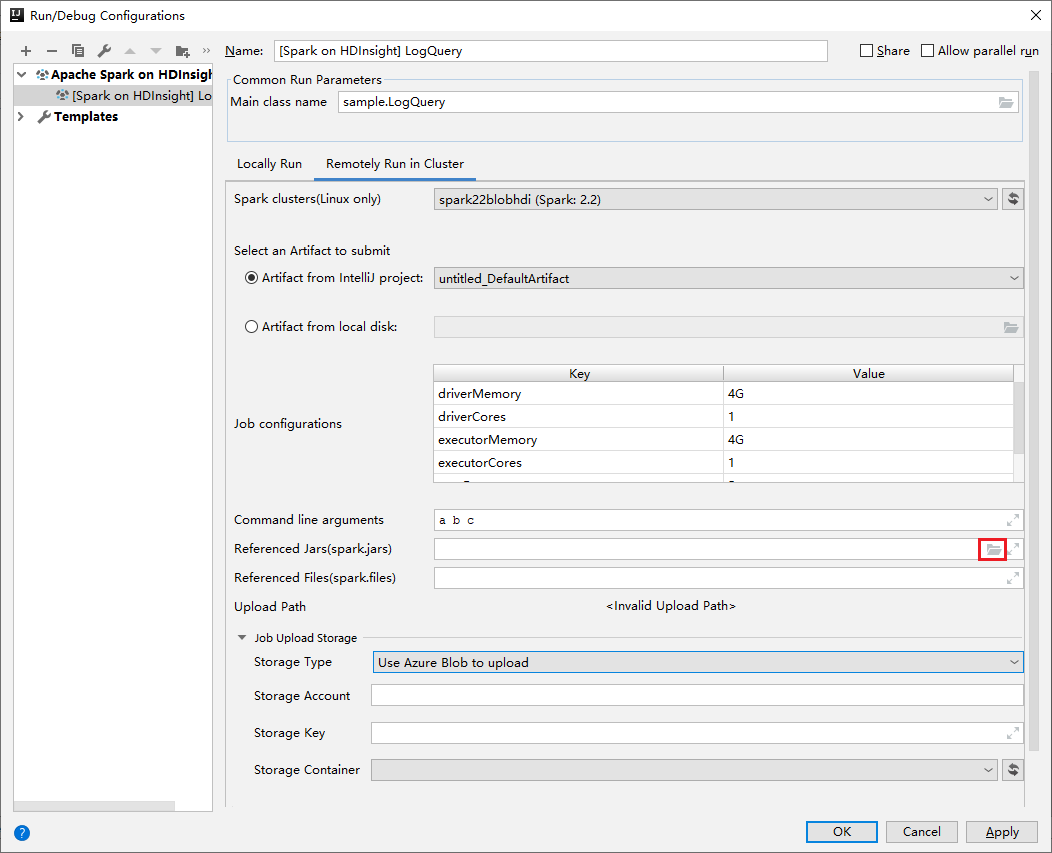
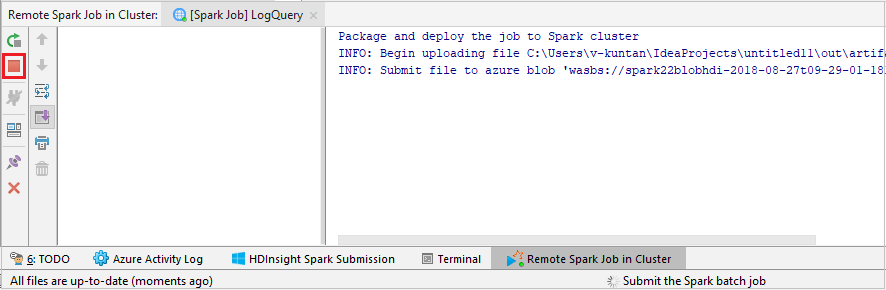
Projenizi seçili kümeye göndermek için SparkJobRun'u seçin. Kümedeki Uzak Spark İşi sekmesi, iş yürütme ilerleme durumunu en altta görüntüler. Kırmızı düğmeye tıklayarak uygulamayı durdurabilirsiniz.
HDInsight kümesinde Apache Spark uygulamalarında yerel olarak veya uzaktan hata ayıklama
Spark uygulamasını kümeye göndermenin başka bir yolunu da öneririz. Bunu yapmak için Çalıştırma/Hata Ayıklama yapılandırmaları IDE'sindeki parametreleri ayarlayabilirsiniz. Bkz . SSH aracılığıyla IntelliJ için Azure Toolkit ile HDInsight kümesinde yerel olarak veya uzaktan Apache Spark uygulamalarında hata ayıklama.
IntelliJ için Azure Toolkit kullanarak HDInsight Spark kümelerine erişme ve kümelerini yönetme
IntelliJ için Azure Toolkit'i kullanarak çeşitli işlemler yapabilirsiniz. İşlemlerin çoğu Azure Gezgini'nden başlatılır. Menü çubuğundan Görünüm>Aracı Windows>Azure Gezgini'ne gidin.
İş görünümüne erişme
Azure Gezgini'nden HDInsight><Küme>>İşleriniz'e gidin.
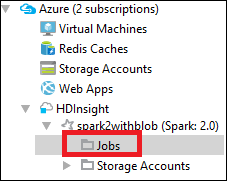
Sağ bölmede Spark İşi Görünümü sekmesi, kümede çalıştırılan tüm uygulamaları görüntüler. Daha fazla ayrıntı görmek istediğiniz uygulamanın adını seçin.

Çalışan temel iş bilgilerini görüntülemek için, iş grafiğinin üzerine gelin. Aşamalar grafiğini ve her işin oluşturduğu bilgileri görüntülemek için iş grafı üzerinde bir düğüm seçin.

Sürücü Stderr, Sürücü Stdout ve Dizin Bilgileri gibi sık kullanılan günlükleri görüntülemek için Günlük sekmesini seçin.

Spark geçmişi kullanıcı arabirimini ve YARN kullanıcı arabirimini görüntüleyebilirsiniz (uygulama düzeyinde). Pencerenin üst kısmından bir bağlantı seçin.
Spark geçmiş sunucusuna erişme
Azure Gezgini'nden HDInsight'ı genişletin, Spark kümenizin adına sağ tıklayın ve spark geçmişi kullanıcı arabirimini aç'ı seçin.
İstendiğinde, kümeyi ayarlarken belirttiğiniz kümenin yönetici kimlik bilgilerini girin.
Spark geçmişi sunucusu panosunda, çalıştırmayı yeni tamamladığınız uygulamayı aramak için uygulama adını kullanabilirsiniz. Önceki kodda, kullanarak
val conf = new SparkConf().setAppName("myApp")uygulama adını ayarlarsınız. Spark uygulamanızın adı myApp'tir.
Ambari portalını başlatma
Azure Gezgini'nden HDInsight'ı genişletin, Spark kümenizin adına sağ tıklayın ve ardından Küme Yönetim Portalını Aç(Ambari)'yi seçin.
İstendiğinde kümenin yönetici kimlik bilgilerini girin. Bu kimlik bilgilerini küme kurulum işlemi sırasında belirttiniz.
Azure aboneliklerini yönetme
Varsayılan olarak, IntelliJ için Azure Toolkit tüm Azure aboneliklerinizdeki Spark kümelerini listeler. Gerekirse, erişmek istediğiniz abonelikleri belirtebilirsiniz.
Azure Gezgini'nden Azure kök düğümüne sağ tıklayın ve ardından Abonelikleri Seç'i seçin.
AbonelikLeri Seç penceresinde, erişmek istemediğiniz aboneliklerin yanındaki onay kutularını temizleyin ve kapat'ı seçin.
Spark Konsolu
Spark Yerel Konsolu'nu (Scala) veya Spark Livy Etkileşimli Oturum Konsolu'nu (Scala) çalıştırabilirsiniz.
Spark Yerel Konsolu (Scala)
WINUTILS.EXE önkoşulunu karşıladığınızdan emin olun.
Menü çubuğundan Yapılandırmaları Düzenle... komutunu çalıştırın>.
Çalıştırma/Hata Ayıklama Yapılandırmaları penceresinde, sol bölmede HDInsight üzerinde Apache Spark[HDInsight> üzerinde Spark] myApp'e gidin.
Ana pencerede sekmeyi
Locally Runseçin.Aşağıdaki değerleri sağlayın ve tamam'ı seçin:
Özellik Değer İş ana sınıfı Varsayılan değer, seçili dosyadaki ana sınıftır. Üç noktayı (...) ve başka bir sınıfı seçerek sınıfı değiştirebilirsiniz. Ortam değişkenleri HADOOP_HOME değerinin doğru olduğundan emin olun. WINUTILS.exe konumu Yolun doğru olduğundan emin olun. 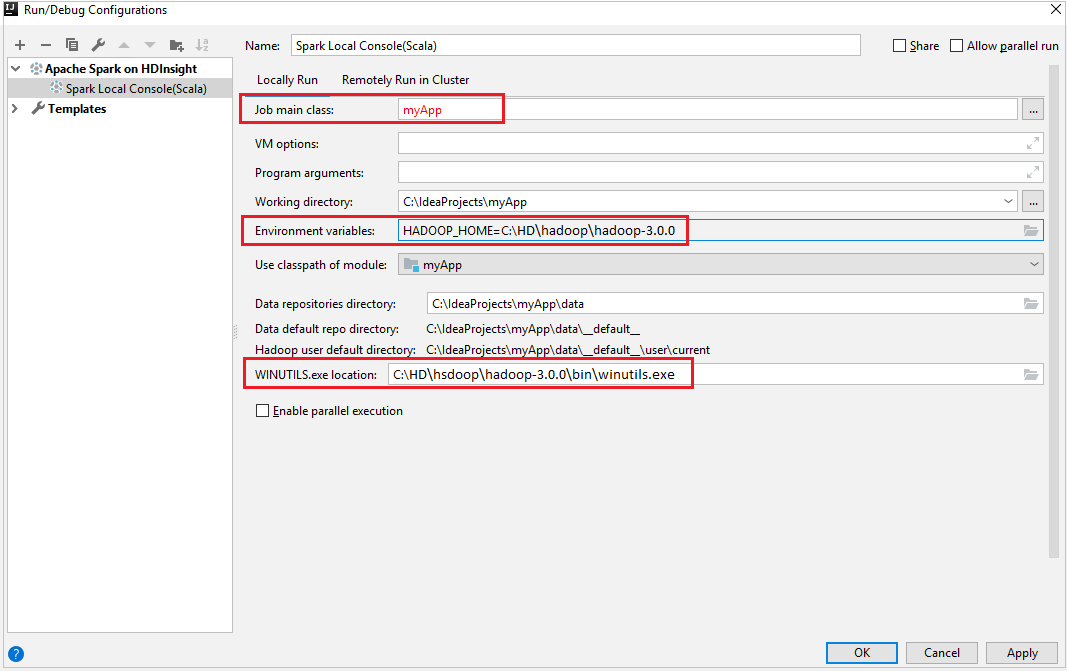
Project'ten myApp>src>main>scala myApp konumuna>gidin.
Menü çubuğundan Araçlar>Spark Konsolu Spark Yerel Konsolunu>Çalıştır (Scala) seçeneğine gidin.
Ardından, bağımlılıkları otomatik olarak düzeltmek isteyip istemediğinizi sormak için iki iletişim kutusu görüntülenebilir. Öyleyse, Otomatik Düzeltme'yi seçin.
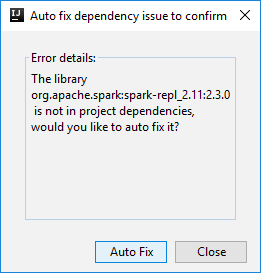
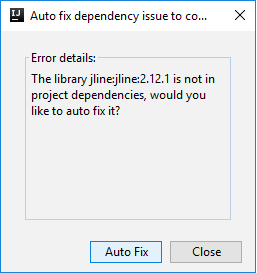
Konsol aşağıdaki resme benzer görünmelidir. Konsol penceresine yazın
sc.appNameve ardından ctrl+Enter tuşlarına basın. Sonuç gösterilir. Kırmızı düğmeye tıklayarak yerel konsolu sonlandırabilirsiniz.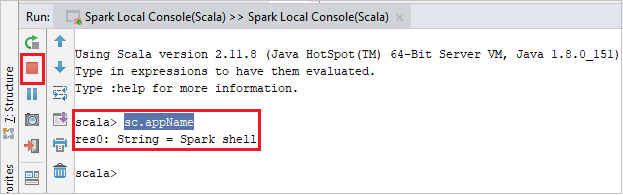
Spark Livy Etkileşimli Oturum Konsolu (Scala)
Menü çubuğundan Yapılandırmaları Düzenle... komutunu çalıştırın>.
Çalıştırma/Hata Ayıklama Yapılandırmaları penceresinde, sol bölmede HDInsight üzerinde Apache Spark[HDInsight> üzerinde Spark] myApp'e gidin.
Ana pencerede sekmeyi
Remotely Run in Clusterseçin.Aşağıdaki değerleri sağlayın ve tamam'ı seçin:
Özellik Değer Spark kümeleri (yalnızca Linux) Uygulamanızı çalıştırmak istediğiniz HDInsight Spark kümesini seçin. Ana sınıf adı Varsayılan değer, seçili dosyadaki ana sınıftır. Üç noktayı (...) ve başka bir sınıfı seçerek sınıfı değiştirebilirsiniz. 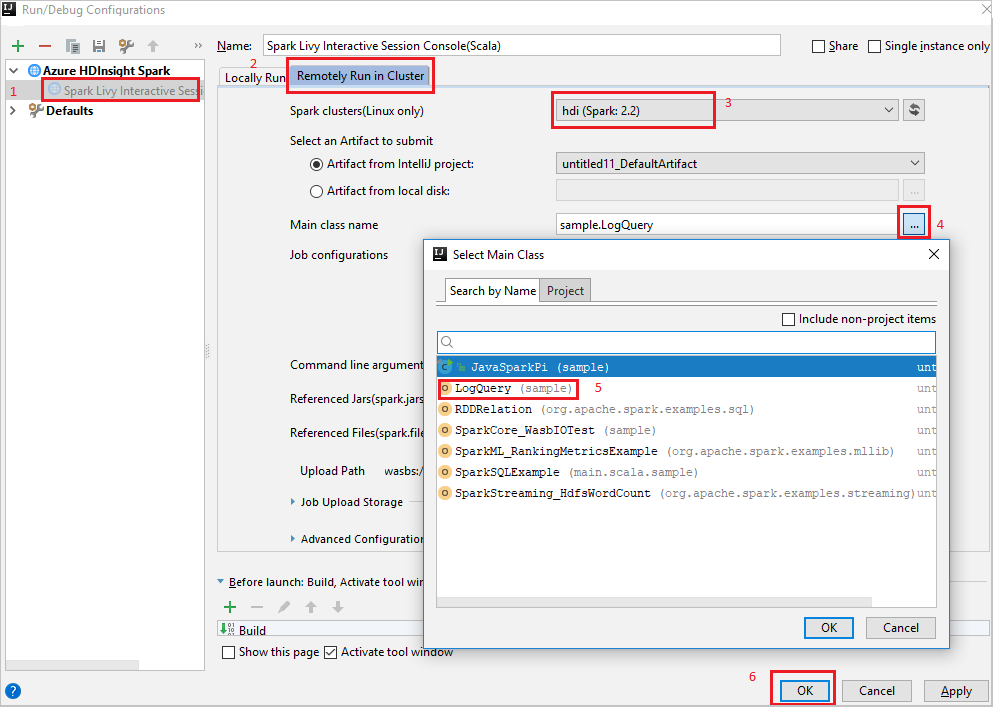
Project'ten myApp>src>main>scala myApp konumuna>gidin.
Menü çubuğundan Araçlar>Spark Konsolu>Spark Livy Etkileşimli Oturum Konsolu'nu (Scala) Çalıştır'a gidin.
Konsol aşağıdaki resme benzer görünmelidir. Konsol penceresine yazın
sc.appNameve ardından ctrl+Enter tuşlarına basın. Sonuç gösterilir. Kırmızı düğmeye tıklayarak yerel konsolu sonlandırabilirsiniz.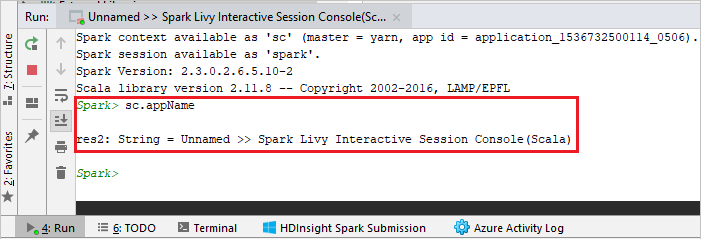
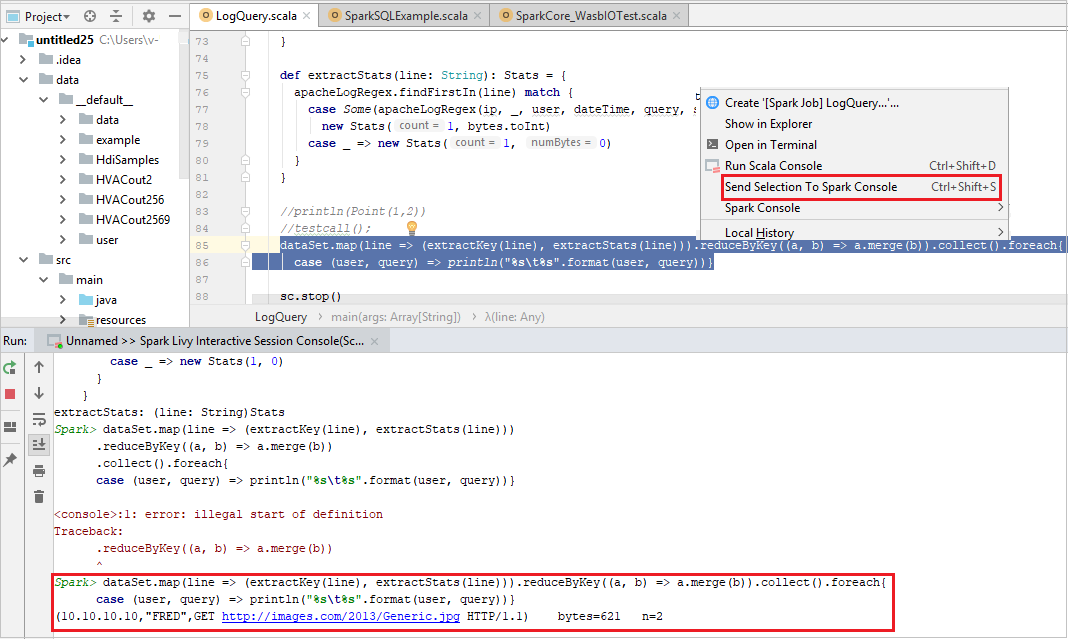
Seçimi Spark Konsoluna Gönder
Yerel konsola veya Livy Interactive Session Console'a (Scala) kod göndererek betik sonucunu tahmin etmek sizin için kullanışlıdır. Scala dosyasında bazı kodları vurgulayabilir ve ardından Seçimi Spark Konsoluna Gönder'e sağ tıklayabilirsiniz. Seçilen kod konsola gönderilir. Sonuç, konsoldaki koddan sonra görüntülenir. Varsa konsol hataları denetler.
HDInsight Kimlik Aracısı (HIB) ile tümleştirme
KIMLIK Aracısı (HIB) ile HDInsight ESP kümenize Bağlan
Kimlik Aracısı (HIB) ile HDInsight ESP kümenize bağlanmak için Azure aboneliğinde oturum açmak için normal adımları izleyebilirsiniz. Oturum açma işleminin ardından Azure Gezgini'nde küme listesini görürsünüz. Daha fazla yönerge için bkz. HDInsight kümenize Bağlan.
Kimlik Aracısı (HIB) ile HDInsight ESP kümesinde Spark Scala uygulaması çalıştırma
Kimlik Aracısı (HIB) ile HDInsight ESP kümesine iş göndermek için normal adımları izleyebilirsiniz. Daha fazla yönerge için bkz. HDInsight Spark kümesinde Spark Scala uygulaması çalıştırma.
Gerekli dosyaları oturum açma hesabınızla adlı bir klasöre yükleriz ve yapılandırma dosyasında karşıya yükleme yolunu görebilirsiniz.

Kimlik Aracısı (HIB) ile HDInsight ESP kümesinde Spark konsolu
Spark Yerel Konsolu'nu (Scala) veya Kimlik Aracısı (HIB) ile bir HDInsight ESP kümesinde Spark Livy Etkileşimli Oturum Konsolu'nu (Scala) çalıştırabilirsiniz. Daha fazla yönerge için Spark Konsolu'na bakın.
Not
Kimlik Aracısı (HIB) içeren HDInsight ESP kümesi için bir kümeyi bağlayın ve Apache Spark uygulamalarında uzaktan hata ayıklama şu anda desteklenmiyor.
Yalnızca okuyucu rolü
Kullanıcılar işi yalnızca okuyucu rolü izni olan bir kümeye gönderdiğinde Ambari kimlik bilgileri gerekir.
Bağlam menüsünden kümeyi bağlama
Yalnızca okuyucu rol hesabıyla oturum açın.
Azure Gezgini'nde, aboneliğinizdeki HDInsight kümelerini görüntülemek için HDInsight'ı genişletin. "Role:Reader" olarak işaretlenen kümelerin yalnızca okuyucu rol izni vardır.
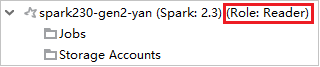
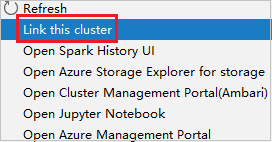
Yalnızca okuyucu rolü iznine sahip kümeye sağ tıklayın. Kümeyi bağlamak için bağlam menüsünden Bu kümeyi bağla'ya tıklayın. Ambari kullanıcı adını ve Parolayı girin.
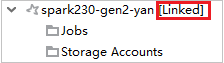
Küme başarıyla bağlanırsa HDInsight yenilenir. Kümenin aşaması bağlanır.
İşler düğümünü genişleterek kümeyi bağlama
İşler düğümü'ne tıklayın, Küme İşi Erişimi Reddedildi penceresi açılır.
Kümeyi bağlamak için Bu kümeyi bağla'ya tıklayın.

Çalıştır/Hata Ayıklama Yapılandırmaları penceresinden kümeyi bağlama
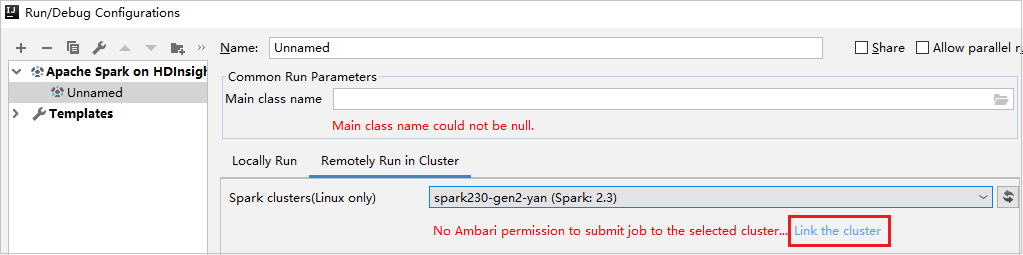
HDInsight Yapılandırması oluşturma. Ardından Kümede Uzaktan Çalıştır'ı seçin.
Spark kümeleri için yalnızca okuyucu rol iznine sahip bir küme seçin (yalnızca Linux). Uyarı iletisi gösterilir. Kümeyi bağlamak için Bu kümeyi bağla'ya tıklayabilirsiniz.
Depolama Hesaplarını Görüntüle
Yalnızca okuyucu rolü iznine sahip kümeler için Hesaplar düğümüne Depolama tıklayın Depolama Erişim Reddedildi penceresi açılır. Azure Depolama Gezgini Aç'a tıklayarak Depolama Gezgini'ne açabilirsiniz.

Bağlı kümeler için, Depolama Hesapları düğümüne tıklayın Depolama Erişim Reddedildi penceresi açılır. Azure Depolama Aç'a tıklayarak Depolama Gezgini'ne açabilirsiniz.


Mevcut IntelliJ IDEA uygulamalarını Azure Toolkit for IntelliJ kullanacak şekilde dönüştürme
IntelliJ IDEA'da oluşturduğunuz mevcut Spark Scala uygulamalarını, IntelliJ için Azure Toolkit ile uyumlu olacak şekilde dönüştürebilirsiniz. Ardından, uygulamaları bir HDInsight Spark kümesine göndermek için eklentiyi kullanabilirsiniz.
IntelliJ IDEA aracılığıyla oluşturulan mevcut bir Spark Scala uygulaması için ilişkili
.imldosyayı açın.Kök düzeyinde, aşağıdaki metne benzer bir modül öğesidir:
<module org.jetbrains.idea.maven.project.MavenProjectsManager.isMavenModule="true" type="JAVA_MODULE" version="4">Modül öğesinin aşağıdaki metin gibi görünmesi için öğesini düzenleyerek ekleyin:
UniqueKey="HDInsightTool"<module org.jetbrains.idea.maven.project.MavenProjectsManager.isMavenModule="true" type="JAVA_MODULE" version="4" UniqueKey="HDInsightTool">Değişiklikleri kaydedin. Uygulamanız artık IntelliJ için Azure Toolkit ile uyumlu olmalıdır. Project'te proje adına sağ tıklayarak test edebilirsiniz. Açılır menüde artık Spark Uygulamasını HDInsight'a Gönder seçeneği vardır.
Kaynakları temizleme
Bu uygulamayı kullanmaya devam etmeyecekseniz, aşağıdaki adımlarla oluşturduğunuz kümeyi silin:
Azure Portal’ında oturum açın.
Üstteki Arama kutusuna HDInsight yazın.
Hizmetler'in altında HDInsight kümeleri'netıklayın.
Görüntülenen HDInsight kümeleri listesinde, bu makale için oluşturduğunuz kümenin yanındaki ... öğesini seçin.
Sil'i seçin. Evet'i seçin.

Hatalar ve çözüm
Aşağıdaki gibi derleme başarısız hataları alırsanız src klasörünü Kaynak olarak işaretlerini kaldırın:

Bu sorunu çözmek için src klasörünü Kaynaklar olarak işaretlerini kaldırın:
Dosya'ya gidin ve Proje Yapısı'nı seçin.
Proje Ayarlar altındaki Modüller'i seçin.
src dosyasını seçin ve Kaynak olarak işaretini kaldırın.
Uygula düğmesine tıklayın ve ardından tamam düğmesine tıklayarak iletişim kutusunu kapatın.

Sonraki adımlar
Bu makalede, Scala'da yazılmış Apache Spark uygulamaları geliştirmek için IntelliJ için Azure Toolkit eklentisini kullanmayı öğrendiniz. Ardından bunları doğrudan IntelliJ tümleşik geliştirme ortamından (IDE) bir HDInsight Spark kümesine gönderdi. Apache Spark'a kaydettiğiniz verilerin Power BI gibi bir BI analiz aracına nasıl çekilebileceğini görmek için sonraki makaleye ilerleyin.