Apache Spark MLlib kullanarak makine öğrenmesi uygulaması oluşturma ve veri kümesini analiz etme
Apache Spark MLlib kullanarak makine öğrenmesi uygulaması oluşturmayı öğrenin. Uygulama açık bir veri kümesi üzerinde tahmine dayalı analiz yapar. Spark'ın yerleşik makine öğrenmesi kitaplıklarından bu örnekte lojistik regresyon aracılığıyla sınıflandırma kullanılmaktadır.
MLlib, makine öğrenmesi görevleri için yararlı olan aşağıdakiler gibi birçok yardımcı program sağlayan temel bir Spark kitaplığıdır:
- Sınıflandırma
- Regresyon
- Kümeleme
- Modelleme
- Tekil değer ayrıştırma (SVD) ve asıl bileşen analizi (PCA)
- Hipotez testi ve örnek istatistikleri hesaplama
Sınıflandırmayı ve lojistik regresyonu anlama
Popüler bir makine öğrenmesi görevi olan sınıflandırma, giriş verilerini kategorilere ayırma işlemidir. Sağladığınız giriş verilerine "etiketler" atamayı öğrenmek bir sınıflandırma algoritmasının işidir. Örneğin, hisse senedi bilgilerini giriş olarak kabul eden bir makine öğrenmesi algoritması düşünebilirsiniz. Ardından hisse senedini iki kategoriye ayırır: satmanız gereken hisse senetleri ve tutmanız gereken hisse senetleri.
Lojistik regresyon, sınıflandırma için kullandığınız algoritmadır. Spark'ın lojistik regresyon API'si ikili sınıflandırma veya giriş verilerini iki gruptan birinde sınıflandırmak için kullanışlıdır. Lojistik regresyonlar hakkında daha fazla bilgi için bkz . Vikipedi.
Özetle, lojistik regresyon süreci lojistik bir işlev oluşturur. Giriş vektörlerinin bir gruba veya diğerine ait olma olasılığını tahmin etmek için işlevini kullanın.
Gıda denetleme verilerinin tahmine dayalı analiz örneği
Bu örnekte, Spark'ı gıda denetleme verileri (Food_Inspections1.csv) üzerinde tahmine dayalı analiz yapmak için kullanırsınız. Chicago Şehri veri portalı aracılığıyla alınan veriler. Bu veri kümesi, Chicago'da gerçekleştirilen gıda kuruluşu denetimleri hakkında bilgi içerir. Her kuruluşla ilgili bilgiler, bulunan ihlaller (varsa) ve inceleme sonuçları dahil. CSV veri dosyası /HdiSamples/HdiSamples/FoodInspectionData/Food_Inspections1.csv konumundaki kümeyle ilişkili depolama hesabında zaten kullanılabilir.
Aşağıdaki adımlarda, gıda denetiminden geçmek veya başarısız olmak için nelerin gerekli olduğunu görmek için bir model geliştirebilirsiniz.
Apache Spark MLlib makine öğrenmesi uygulaması oluşturma
PySpark çekirdeğini kullanarak bir Jupyter Not Defteri oluşturun. Yönergeler için bkz . Jupyter Notebook dosyası oluşturma.
Bu uygulama için gereken türleri içeri aktarın. Aşağıdaki kodu kopyalayıp boş bir hücreye yapıştırın ve SHIFT + ENTER tuşlarına basın.
from pyspark.ml import Pipeline from pyspark.ml.classification import LogisticRegression from pyspark.ml.feature import HashingTF, Tokenizer from pyspark.sql import Row from pyspark.sql.functions import UserDefinedFunction from pyspark.sql.types import *PySpark çekirdeği nedeniyle açıkça bağlam oluşturmanız gerekmez. Spark ve Hive bağlamları, ilk kod hücresini çalıştırdığınızda otomatik olarak oluşturulur.
Giriş veri çerçevesini oluşturma
Ham CSV verilerini yapılandırılmamış metin olarak belleğe çekmek için Spark bağlamını kullanın. Ardından python'ın CSV kitaplığını kullanarak verilerin her satırını ayrıştırın.
Giriş verilerini içeri aktarıp ayrıştırarak Dayanıklı Dağıtılmış Veri Kümesi (RDD) oluşturmak için aşağıdaki satırları çalıştırın.
def csvParse(s): import csv from io import StringIO sio = StringIO(s) value = next(csv.reader(sio)) sio.close() return value inspections = sc.textFile('/HdiSamples/HdiSamples/FoodInspectionData/Food_Inspections1.csv')\ .map(csvParse)Aşağıdaki kodu çalıştırarak RDD'den bir satır alın; böylece veri şemasına göz atabilirsiniz:
inspections.take(1)Çıktı şu olur:
[['413707', 'LUNA PARK INC', 'LUNA PARK DAY CARE', '2049789', "Children's Services Facility", 'Risk 1 (High)', '3250 W FOSTER AVE ', 'CHICAGO', 'IL', '60625', '09/21/2010', 'License-Task Force', 'Fail', '24. DISH WASHING FACILITIES: PROPERLY DESIGNED, CONSTRUCTED, MAINTAINED, INSTALLED, LOCATED AND OPERATED - Comments: All dishwashing machines must be of a type that complies with all requirements of the plumbing section of the Municipal Code of Chicago and Rules and Regulation of the Board of Health. OBSEVERD THE 3 COMPARTMENT SINK BACKING UP INTO THE 1ST AND 2ND COMPARTMENT WITH CLEAR WATER AND SLOWLY DRAINING OUT. INST NEED HAVE IT REPAIR. CITATION ISSUED, SERIOUS VIOLATION 7-38-030 H000062369-10 COURT DATE 10-28-10 TIME 1 P.M. ROOM 107 400 W. SURPERIOR. | 36. LIGHTING: REQUIRED MINIMUM FOOT-CANDLES OF LIGHT PROVIDED, FIXTURES SHIELDED - Comments: Shielding to protect against broken glass falling into food shall be provided for all artificial lighting sources in preparation, service, and display facilities. LIGHT SHIELD ARE MISSING UNDER HOOD OF COOKING EQUIPMENT AND NEED TO REPLACE LIGHT UNDER UNIT. 4 LIGHTS ARE OUT IN THE REAR CHILDREN AREA,IN THE KINDERGARDEN CLASS ROOM. 2 LIGHT ARE OUT EAST REAR, LIGHT FRONT WEST ROOM. NEED TO REPLACE ALL LIGHT THAT ARE NOT WORKING. | 35. WALLS, CEILINGS, ATTACHED EQUIPMENT CONSTRUCTED PER CODE: GOOD REPAIR, SURFACES CLEAN AND DUST-LESS CLEANING METHODS - Comments: The walls and ceilings shall be in good repair and easily cleaned. MISSING CEILING TILES WITH STAINS IN WEST,EAST, IN FRONT AREA WEST, AND BY THE 15MOS AREA. NEED TO BE REPLACED. | 32. FOOD AND NON-FOOD CONTACT SURFACES PROPERLY DESIGNED, CONSTRUCTED AND MAINTAINED - Comments: All food and non-food contact equipment and utensils shall be smooth, easily cleanable, and durable, and shall be in good repair. SPLASH GUARDED ARE NEEDED BY THE EXPOSED HAND SINK IN THE KITCHEN AREA | 34. FLOORS: CONSTRUCTED PER CODE, CLEANED, GOOD REPAIR, COVING INSTALLED, DUST-LESS CLEANING METHODS USED - Comments: The floors shall be constructed per code, be smooth and easily cleaned, and be kept clean and in good repair. INST NEED TO ELEVATE ALL FOOD ITEMS 6INCH OFF THE FLOOR 6 INCH AWAY FORM WALL. ', '41.97583445690982', '-87.7107455232781', '(41.97583445690982, -87.7107455232781)']]Çıkış, giriş dosyasının şeması hakkında bir fikir verir. Her kuruluşun adını ve kuruluş türünü içerir. Ayrıca, adres, denetim verileri ve konum, diğer şeylerin yanında.
Tahmine dayalı analiz için yararlı olan birkaç sütun içeren bir veri çerçevesi (df) ve geçici bir tablo (CountResults) oluşturmak için aşağıdaki kodu çalıştırın.
sqlContext, yapılandırılmış verilerde dönüşümler yapmak için kullanılır.schema = StructType([ StructField("id", IntegerType(), False), StructField("name", StringType(), False), StructField("results", StringType(), False), StructField("violations", StringType(), True)]) df = spark.createDataFrame(inspections.map(lambda l: (int(l[0]), l[1], l[12], l[13])) , schema) df.registerTempTable('CountResults')Veri çerçevesinin ilgilendiği dört sütun kimlik, ad, sonuçlar ve ihlallerdir.
Verilerin küçük bir örneğini almak için aşağıdaki kodu çalıştırın:
df.show(5)Çıktı şu olur:
+------+--------------------+-------+--------------------+ | id| name|results| violations| +------+--------------------+-------+--------------------+ |413707| LUNA PARK INC| Fail|24. DISH WASHING ...| |391234| CAFE SELMARIE| Fail|2. FACILITIES TO ...| |413751| MANCHU WOK| Pass|33. FOOD AND NON-...| |413708|BENCHMARK HOSPITA...| Pass| | |413722| JJ BURGER| Pass| | +------+--------------------+-------+--------------------+
Verileri anlama
Şimdi veri kümesinin içeriğine ilişkin bir anlayış edinmeye başlayalım.
Sonuçlar sütunundaki ayrı değerleri göstermek için aşağıdaki kodu çalıştırın:
df.select('results').distinct().show()Çıktı şu olur:
+--------------------+ | results| +--------------------+ | Fail| |Business Not Located| | Pass| | Pass w/ Conditions| | Out of Business| +--------------------+Bu sonuçların dağılımını görselleştirmek için aşağıdaki kodu çalıştırın:
%%sql -o countResultsdf SELECT COUNT(results) AS cnt, results FROM CountResults GROUP BY resultsArdından
%%sqlgelen büyü-o countResultsdf, sorgunun çıkışının Jupyter sunucusunda (genellikle küme baş düğümü) yerel olarak kalıcı olmasını sağlar. Çıkış, belirtilen countResultsdf adlı bir Pandas veri çerçevesi olarak kalıcı hale geldi. Sihir ve PySpark çekirdeğiyle kullanılabilen diğer sihirler hakkında%%sqldaha fazla bilgi için bkz . Apache Spark HDInsight kümeleri ile Jupyter Notebook'larda kullanılabilen çekirdekler.Çıktı şu olur:
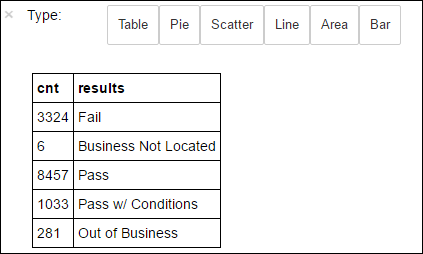
Ayrıca, verilerin görselleştirmesini oluşturmak için kullanılan bir kitaplık olan Matplotlib'i kullanarak çizim oluşturabilirsiniz. Çizimin yerel olarak kalıcı countResultsdf veri çerçevesinden oluşturulması gerektiğinden, kod parçacığı sihirle
%%localbaşlamalıdır. Bu eylem, kodun Jupyter sunucusunda yerel olarak çalıştırılmasını sağlar.%%local %matplotlib inline import matplotlib.pyplot as plt labels = countResultsdf['results'] sizes = countResultsdf['cnt'] colors = ['turquoise', 'seagreen', 'mediumslateblue', 'palegreen', 'coral'] plt.pie(sizes, labels=labels, autopct='%1.1f%%', colors=colors) plt.axis('equal')Gıda denetimi sonucunu tahmin etmek için ihlalleri temel alan bir model geliştirmeniz gerekir. Lojistik regresyon bir ikili sınıflandırma yöntemi olduğundan, sonuç verilerini iki kategoride gruplandırmak mantıklıdır: Başarısız ve Başarılı:
Başarılı
- Başarılı
- W/ koşullarını geçirme
Başarısız
- Başarısız
Vazgeç
- İş bulunamadı
- İş Yeri Dışında
Diğer sonuçları içeren veriler ("İş Yeri Yok" veya "İş Yeri Dışında") kullanışlı değildir ve yine de sonuçların küçük bir yüzdesini oluşturur.
Mevcut veri çerçevelerini(
df) her incelemenin etiket ihlalleri çifti olarak temsil edildiği yeni bir veri çerçevesine dönüştürmek için aşağıdaki kodu çalıştırın. Bu durumda etiketi0.0bir hatayı, etiketi bir başarıyı1.0, etiketi ise bu iki sonucun-1.0yanında bazı sonuçları temsil eder.def labelForResults(s): if s == 'Fail': return 0.0 elif s == 'Pass w/ Conditions' or s == 'Pass': return 1.0 else: return -1.0 label = UserDefinedFunction(labelForResults, DoubleType()) labeledData = df.select(label(df.results).alias('label'), df.violations).where('label >= 0')Etiketlenmiş verilerin bir satırını göstermek için aşağıdaki kodu çalıştırın:
labeledData.take(1)Çıktı şu olur:
[Row(label=0.0, violations=u"41. PREMISES MAINTAINED FREE OF LITTER, UNNECESSARY ARTICLES, CLEANING EQUIPMENT PROPERLY STORED - Comments: All parts of the food establishment and all parts of the property used in connection with the operation of the establishment shall be kept neat and clean and should not produce any offensive odors. REMOVE MATTRESS FROM SMALL DUMPSTER. | 35. WALLS, CEILINGS, ATTACHED EQUIPMENT CONSTRUCTED PER CODE: GOOD REPAIR, SURFACES CLEAN AND DUST-LESS CLEANING METHODS - Comments: The walls and ceilings shall be in good repair and easily cleaned. REPAIR MISALIGNED DOORS AND DOOR NEAR ELEVATOR. DETAIL CLEAN BLACK MOLD LIKE SUBSTANCE FROM WALLS BY BOTH DISH MACHINES. REPAIR OR REMOVE BASEBOARD UNDER DISH MACHINE (LEFT REAR KITCHEN). SEAL ALL GAPS. REPLACE MILK CRATES USED IN WALK IN COOLERS AND STORAGE AREAS WITH PROPER SHELVING AT LEAST 6' OFF THE FLOOR. | 38. VENTILATION: ROOMS AND EQUIPMENT VENTED AS REQUIRED: PLUMBING: INSTALLED AND MAINTAINED - Comments: The flow of air discharged from kitchen fans shall always be through a duct to a point above the roofline. REPAIR BROKEN VENTILATION IN MEN'S AND WOMEN'S WASHROOMS NEXT TO DINING AREA. | 32. FOOD AND NON-FOOD CONTACT SURFACES PROPERLY DESIGNED, CONSTRUCTED AND MAINTAINED - Comments: All food and non-food contact equipment and utensils shall be smooth, easily cleanable, and durable, and shall be in good repair. REPAIR DAMAGED PLUG ON LEFT SIDE OF 2 COMPARTMENT SINK. REPAIR SELF CLOSER ON BOTTOM LEFT DOOR OF 4 DOOR PREP UNIT NEXT TO OFFICE.")]
Giriş veri çerçevesinden lojistik regresyon modeli oluşturma
Son görev etiketlenmiş verileri dönüştürmektir. Verileri lojistik regresyon tarafından analiz edilen bir biçime dönüştürün. Lojistik regresyon algoritmasına giriş için bir dizi etiket özelliği vektör çifti gerekir. Burada "özellik vektör", giriş noktasını temsil eden bir sayı vektördür. Bu nedenle, yarı yapılandırılmış ve serbest metinde birçok açıklama içeren "ihlaller" sütununu dönüştürmeniz gerekir. Sütunu, bir makinenin kolayca anlayabileceği gerçek sayı dizisine dönüştürün.
Doğal dili işlemeye yönelik standart makine öğrenmesi yaklaşımlarından biri, her ayrı sözcüğü bir dizin atamaktır. Ardından makine öğrenmesi algoritmasına bir vektör geçirin. Böylece her dizinin değeri, metin dizesindeki bu sözcüğün göreli sıklığını içerir.
MLlib, bu işlemi yapmak için kolay bir yol sağlar. İlk olarak, her bir dizedeki tek tek sözcükleri almak için her ihlal dizesini "belirteçleştirin". Ardından, her belirteç kümesini model oluşturmak üzere lojistik regresyon algoritmasına geçirilebilen bir özellik vektöre dönüştürmek için kullanın HashingTF . İşlem hattı kullanarak bu adımların tümünü sırayla gerçekleştirebilirsiniz.
tokenizer = Tokenizer(inputCol="violations", outputCol="words")
hashingTF = HashingTF(inputCol=tokenizer.getOutputCol(), outputCol="features")
lr = LogisticRegression(maxIter=10, regParam=0.01)
pipeline = Pipeline(stages=[tokenizer, hashingTF, lr])
model = pipeline.fit(labeledData)
Başka bir veri kümesi kullanarak modeli değerlendirme
Yeni incelemelerin sonuçlarını tahmin etmek için daha önce oluşturduğunuz modeli kullanabilirsiniz. Tahminler, gözlemlenen ihlalleri temel alır. Bu modeli veri kümesi Food_Inspections1.csv eğitmişsiniz. Bu modelin gücünü yeni verilerde değerlendirmek için ikinci bir veri kümesi (Food_Inspections2.csv) kullanabilirsiniz. Bu ikinci veri kümesi (Food_Inspections2.csv), kümeyle ilişkili varsayılan depolama kapsayıcısındadır.
Model tarafından oluşturulan tahmini içeren predictionsDf adlı yeni bir veri çerçevesi oluşturmak için aşağıdaki kodu çalıştırın. Kod parçacığı, veri çerçevesini temel alan Tahminler adlı geçici bir tablo da oluşturur.
testData = sc.textFile('wasbs:///HdiSamples/HdiSamples/FoodInspectionData/Food_Inspections2.csv')\ .map(csvParse) \ .map(lambda l: (int(l[0]), l[1], l[12], l[13])) testDf = spark.createDataFrame(testData, schema).where("results = 'Fail' OR results = 'Pass' OR results = 'Pass w/ Conditions'") predictionsDf = model.transform(testDf) predictionsDf.registerTempTable('Predictions') predictionsDf.columnsAşağıdaki metne benzer bir çıktı görmeniz gerekir:
['id', 'name', 'results', 'violations', 'words', 'features', 'rawPrediction', 'probability', 'prediction']Tahminlerden birine bakın. Şu kod parçacığını çalıştırın:
predictionsDf.take(1)Test veri kümesindeki ilk giriş için bir tahmin vardır.
yöntemi,
model.transform()aynı şemaya sahip tüm yeni verilere aynı dönüşümü uygular ve verilerin nasıl sınıflandırılacağını gösteren bir tahmine ulaşır. Tahminlerin nasıl olduğunu öğrenmek için bazı istatistikler yapabilirsiniz:numSuccesses = predictionsDf.where("""(prediction = 0 AND results = 'Fail') OR (prediction = 1 AND (results = 'Pass' OR results = 'Pass w/ Conditions'))""").count() numInspections = predictionsDf.count() print ("There were", numInspections, "inspections and there were", numSuccesses, "successful predictions") print ("This is a", str((float(numSuccesses) / float(numInspections)) * 100) + "%", "success rate")Çıktı aşağıdaki metne benzer:
There were 9315 inspections and there were 8087 successful predictions This is a 86.8169618894% success rateSpark ile lojistik regresyon kullanmak, ihlal açıklamaları arasındaki ilişkinin İngilizce bir modelini sağlar. Ve belirli bir işletmenin gıda denetlemeden geçip geçmeyeceği.
Tahminin görsel gösterimini oluşturma
Artık bu testin sonuçları hakkında düşünmenize yardımcı olacak son bir görselleştirme oluşturabilirsiniz.
Daha önce oluşturulan Tahminler geçici tablosundan farklı tahminleri ve sonuçları ayıklayarak işe başlarsınız. Aşağıdaki sorgular çıkışı true_positive, false_positive, true_negative ve false_negative olarak ayırır. Aşağıdaki sorgularda kullanarak görselleştirmeyi
-qkapatır ve çıkışı (kullanarak-o) daha sonra büyüyle%%localkullanılabilecek veri çerçeveleri olarak kaydedersiniz.%%sql -q -o true_positive SELECT count(*) AS cnt FROM Predictions WHERE prediction = 0 AND results = 'Fail'%%sql -q -o false_positive SELECT count(*) AS cnt FROM Predictions WHERE prediction = 0 AND (results = 'Pass' OR results = 'Pass w/ Conditions')%%sql -q -o true_negative SELECT count(*) AS cnt FROM Predictions WHERE prediction = 1 AND results = 'Fail'%%sql -q -o false_negative SELECT count(*) AS cnt FROM Predictions WHERE prediction = 1 AND (results = 'Pass' OR results = 'Pass w/ Conditions')Son olarak, Matplotlib kullanarak çizimi oluşturmak için aşağıdaki kod parçacığını kullanın.
%%local %matplotlib inline import matplotlib.pyplot as plt labels = ['True positive', 'False positive', 'True negative', 'False negative'] sizes = [true_positive['cnt'], false_positive['cnt'], false_negative['cnt'], true_negative['cnt']] colors = ['turquoise', 'seagreen', 'mediumslateblue', 'palegreen', 'coral'] plt.pie(sizes, labels=labels, autopct='%1.1f%%', colors=colors) plt.axis('equal')Aşağıdaki çıkışı görmeniz gerekir:
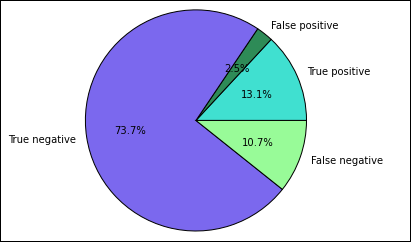
Bu grafikte "pozitif" sonuç, başarısız gıda denetimine, negatif bir sonuç ise geçirilen denetime işaret eder.
Not defterini kapatma
Uygulamayı çalıştırdıktan sonra, kaynakları serbest bırakmak için not defterini kapatmanız gerekir. Bunu yapmak için not defterindeki Dosya menüsünde Kapat ve Durdur’u seçin. Bu eylem, not defterini kapatır.