Azure HDInsight'ta Apache Spark kümesi için kaynakları yönetme
Apache Ambari kullanıcı arabirimi, Apache Hadoop YARN kullanıcı arabirimi ve Apache Spark kümenizle ilişkili Spark Geçmiş Sunucusu gibi arabirimlere erişmeyi ve en iyi performans için küme yapılandırmasını ayarlamayı öğrenin.
Spark Geçmiş Sunucusu'nu açma
Spark Geçmiş Sunucusu, tamamlanan ve çalışan Spark uygulamalarına yönelik web kullanıcı arabirimidir. Spark'ın Web kullanıcı arabiriminin bir uzantısıdır. Tam bilgi için bkz . Spark Geçmiş Sunucusu.
Yarn kullanıcı arabirimini açma
Spark kümesinde çalışmakta olan uygulamaları izlemek için YARN kullanıcı arabirimini kullanabilirsiniz.
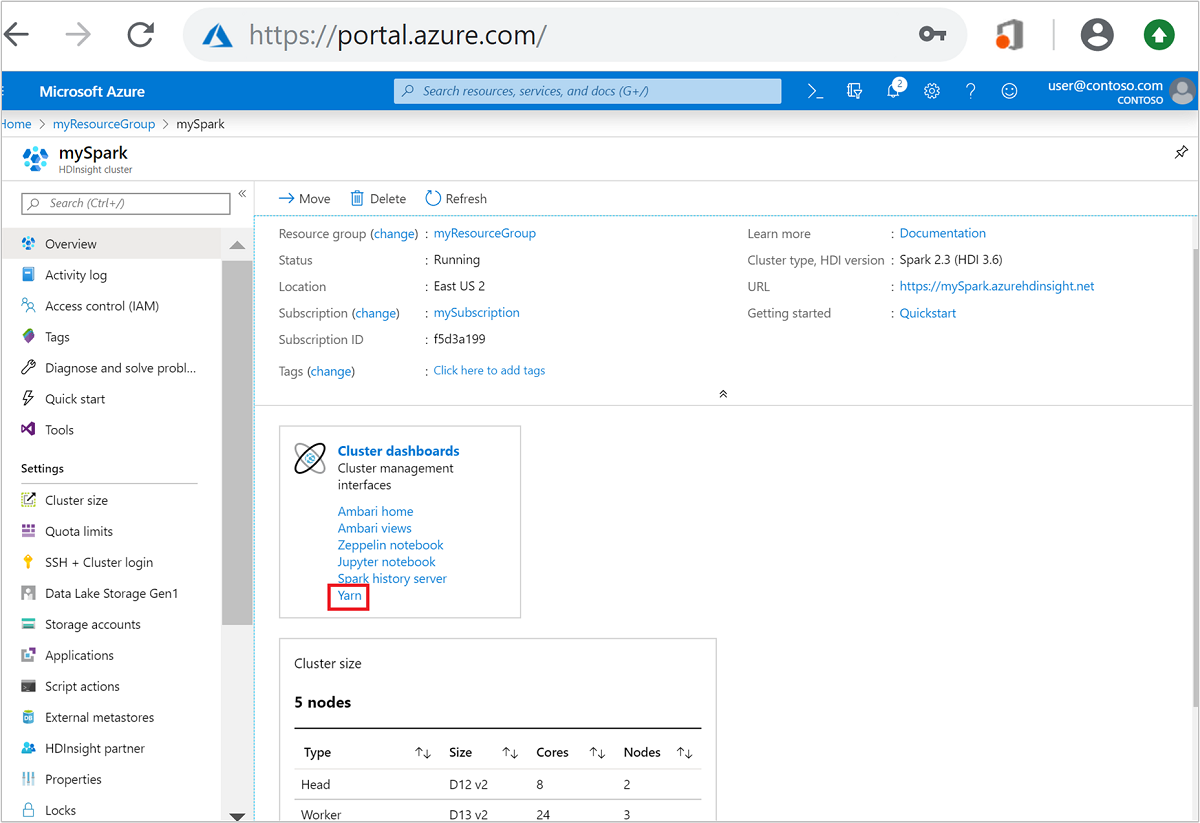
Azure portalından Spark kümesini açın. Daha fazla bilgi için bkz . Kümeleri listeleme ve gösterme.
Küme panolarından Yarn'ı seçin. İstendiğinde Spark kümesi için yönetici kimlik bilgilerini girin.
İpucu
Alternatif olarak, Yarn kullanıcı arabirimini Ambari kullanıcı arabiriminden de başlatabilirsiniz. Ambari kullanıcı arabiriminden YARN>Hızlı Bağlantıları>Etkin>Resource Manager kullanıcı arabirimine gidin.
Spark uygulamaları için kümeleri iyileştirme
Uygulama gereksinimlerine bağlı olarak Spark yapılandırması için kullanılabilecek üç temel parametre şunlardır: spark.executor.instances, spark.executor.coresve spark.executor.memory. Yürütücü, Spark uygulaması için başlatılan bir işlemdir. Çalışan düğümünde çalışır ve uygulamanın görevlerini yürütmekten sorumludur. Her küme için varsayılan yürütücü sayısı ve yürütücü boyutları, çalışan düğümlerinin sayısına ve çalışan düğümü boyutuna göre hesaplanır. Bu bilgiler küme baş düğümlerinde spark-defaults.conf depolanır.
Üç yapılandırma parametresi küme düzeyinde yapılandırılabilir (kümede çalışan tüm uygulamalar için) veya her bir uygulama için de belirtilebilir.
Ambari kullanıcı arabirimini kullanarak parametreleri değiştirme
Ambari kullanıcı arabiriminden Spark2>Yapılandırmaları>Özel spark2-defaults öğesine gidin.

Varsayılan değerler, kümede aynı anda çalışan dört Spark uygulamasının olması için uygundur. Aşağıdaki ekran görüntüsünde gösterildiği gibi bu değerleri kullanıcı arabiriminden değiştirebilirsiniz:
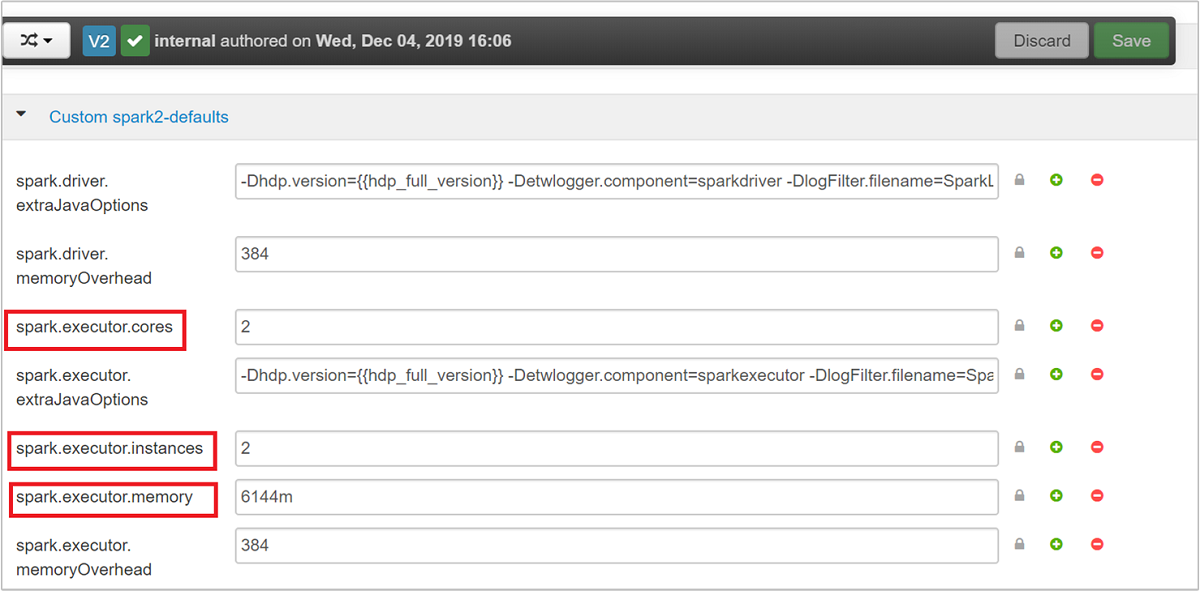
Yapılandırma değişikliklerini kaydetmek için Kaydet'i seçin. Sayfanın üst kısmında, etkilenen tüm hizmetleri yeniden başlatmanız istenir. Yeniden Başlat'ı seçin.
Jupyter Notebook'ta çalışan bir uygulamanın parametrelerini değiştirme
Jupyter Not Defteri'nde çalışan uygulamalar için, yapılandırma değişikliklerini %%configure yapmak için sihri kullanabilirsiniz. İdeal olarak, ilk kod hücrenizi çalıştırmadan önce uygulamanın başında bu tür değişiklikler yapmanız gerekir. Bunun yapılması, yapılandırmanın oluşturulduğunda Livy oturumuna uygulanmasını sağlar. Uygulamanın sonraki bir aşamasında yapılandırmayı değiştirmek istiyorsanız parametresini -f kullanmanız gerekir. Ancak bunu yaptığınızda uygulamadaki tüm ilerlemeler kaybolur.
Aşağıdaki kod parçacığı, Jupyter'da çalışan bir uygulamanın yapılandırmasını nasıl değiştireceğini gösterir.
%%configure
{"executorMemory": "3072M", "executorCores": 4, "numExecutors":10}
Yapılandırma parametreleri JSON dizesi olarak geçirilmelidir ve örnek sütunda gösterildiği gibi sihirden sonraki satırda olmalıdır.
spark-submit kullanılarak gönderilen bir uygulamanın parametrelerini değiştirme
Aşağıdaki komut, kullanılarak spark-submitgönderilen bir toplu iş uygulamasının yapılandırma parametrelerinin nasıl değiştirildiğini gösteren bir örnektir.
spark-submit --class <the application class to execute> --executor-memory 3072M --executor-cores 4 –-num-executors 10 <location of application jar file> <application parameters>
cURL kullanılarak gönderilen bir uygulamanın parametrelerini değiştirme
Aşağıdaki komut, cURL kullanılarak gönderilen bir toplu iş uygulamasının yapılandırma parametrelerinin nasıl değiştirildiğini gösteren bir örnektir.
curl -k -v -H 'Content-Type: application/json' -X POST -d '{"file":"<location of application jar file>", "className":"<the application class to execute>", "args":[<application parameters>], "numExecutors":10, "executorMemory":"2G", "executorCores":5' localhost:8998/batches
Not
JAR dosyasını küme depolama hesabınıza kopyalayın. JAR dosyasını doğrudan baş düğüme kopyalamayın.
Spark Thrift Sunucusu'nda bu parametreleri değiştirme
Spark Thrift Server, Spark kümesine JDBC/ODBC erişimi sağlar ve Spark SQL sorgularına hizmet vermek için kullanılır. Power BI, Tableau vb. gibi araçlar, Spark SQL sorgularını Spark Uygulaması olarak yürütmek üzere Spark Thrift Server ile iletişim kurmak için ODBC protokollerini kullanır. Bir Spark kümesi oluşturulduğunda, her baş düğümde biri olmak üzere iki Spark Thrift Sunucusu örneği başlatılır. Her Spark Thrift Sunucusu, YARN kullanıcı arabiriminde bir Spark uygulaması olarak görünür.
Spark Thrift Server, Spark dinamik yürütücü ayırmasını spark.executor.instances kullanır ve bu nedenle kullanılmaz. Spark Thrift Server bunun yerine yürütücü sayısını belirtmek için ve spark.dynamicAllocation.minExecutors kullanırspark.dynamicAllocation.maxExecutors. ve yapılandırma parametreleri spark.executor.coresyürütücü spark.executor.memory boyutunu değiştirmek için kullanılır. Aşağıdaki adımlarda gösterildiği gibi bu parametreleri değiştirebilirsiniz:
ve parametrelerini
spark.dynamicAllocation.maxExecutorsspark.dynamicAllocation.minExecutorsgüncelleştirmek için Gelişmiş spark2-thrift-sparkconf kategorisini genişletin.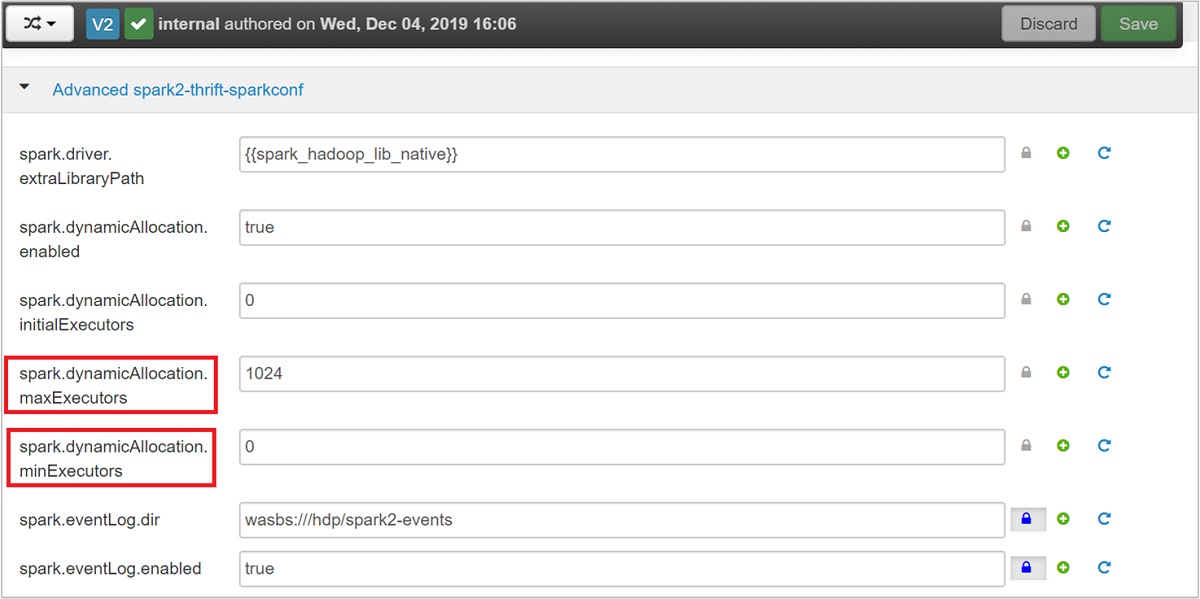
ve parametrelerini
spark.executor.coresspark.executor.memorygüncelleştirmek için Özel spark2-thrift-sparkconf kategorisini genişletin.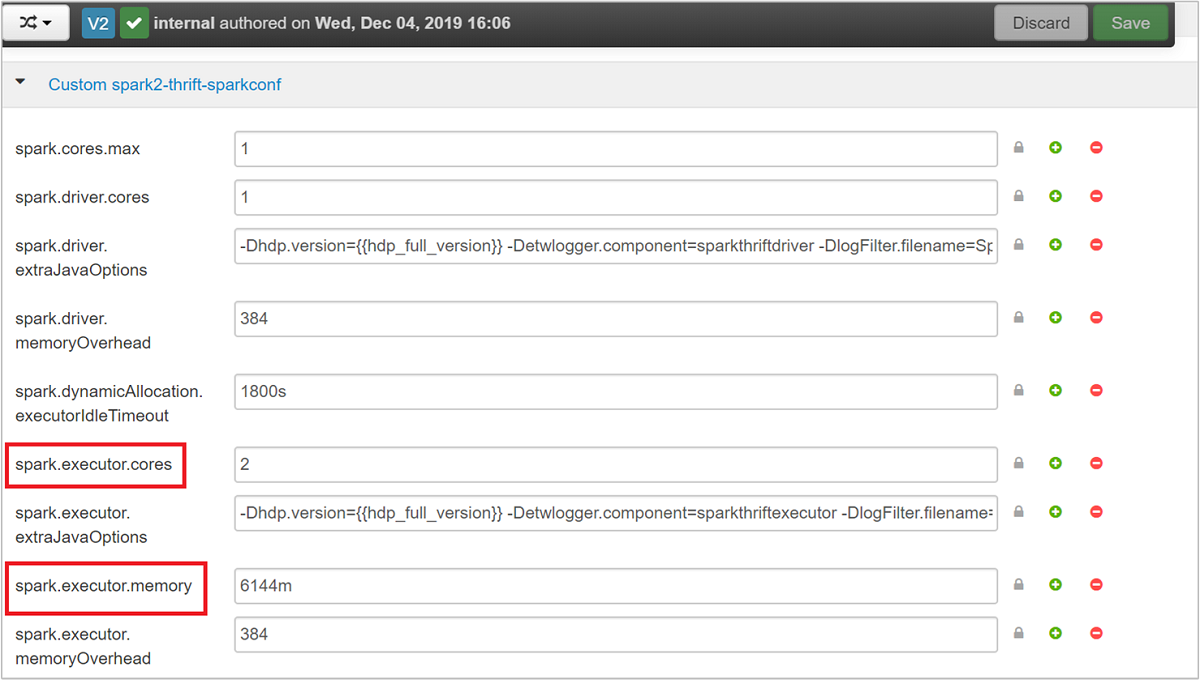
Spark Thrift Sunucusu'nun sürücü belleğini değiştirme
Spark Thrift Server sürücü belleği, baş düğümün toplam RAM boyutunun 14 GB'tan büyük olması koşuluyla baş düğüm RAM boyutunun %25'ine yapılandırılır. Aşağıdaki ekran görüntüsünde gösterildiği gibi, sürücü bellek yapılandırmasını değiştirmek için Ambari kullanıcı arabirimini kullanabilirsiniz:
Ambari kullanıcı arabiriminden Spark2 Yapılandırmaları>Gelişmiş spark2-env'ye> gidin. Ardından spark_thrift_cmd_opts değerini sağlayın.
Spark kümesi kaynaklarını geri kazanma
Spark dinamik ayırması nedeniyle, thrift sunucusu tarafından tüketilen kaynaklar yalnızca iki uygulama yöneticisinin kaynaklarıdır. Bu kaynakları geri kazanmak için kümede çalışan Thrift Server hizmetlerini durdurmanız gerekir.
Ambari kullanıcı arabiriminde, sol bölmeden Spark2'yi seçin.
Sonraki sayfada Spark2 Thrift Sunucuları'nı seçin.
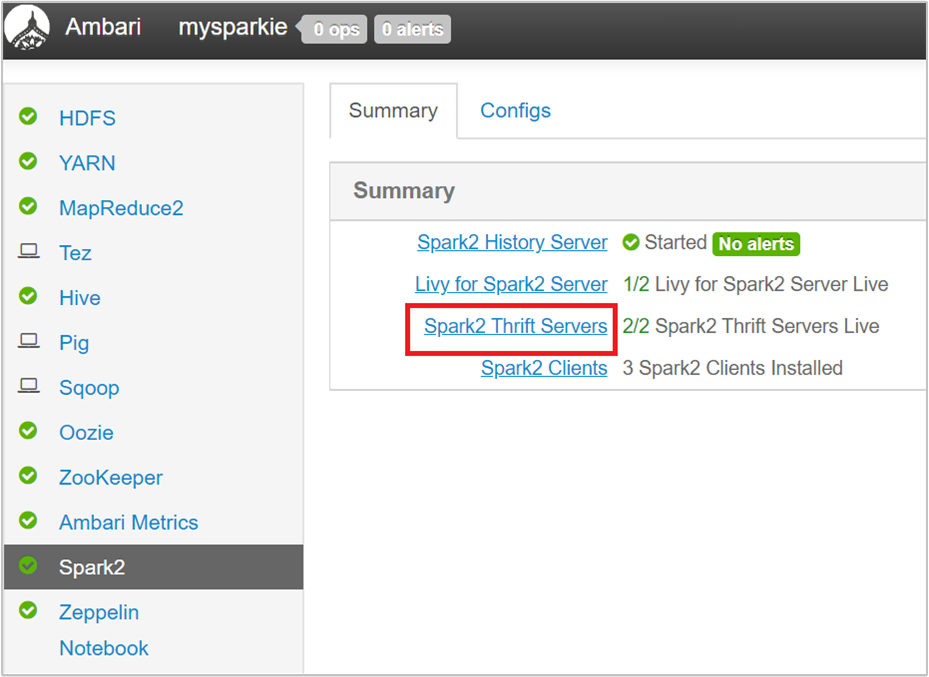
Spark2 Thrift Sunucusu'nun üzerinde çalıştığı iki baş düğüm görmeniz gerekir. Baş düğümlerden birini seçin.
Sonraki sayfada bu baş düğümde çalışan tüm hizmetler listelenir. Listeden Spark2 Thrift Server'ın yanındaki açılan düğmeyi ve ardından Durdur'u seçin.
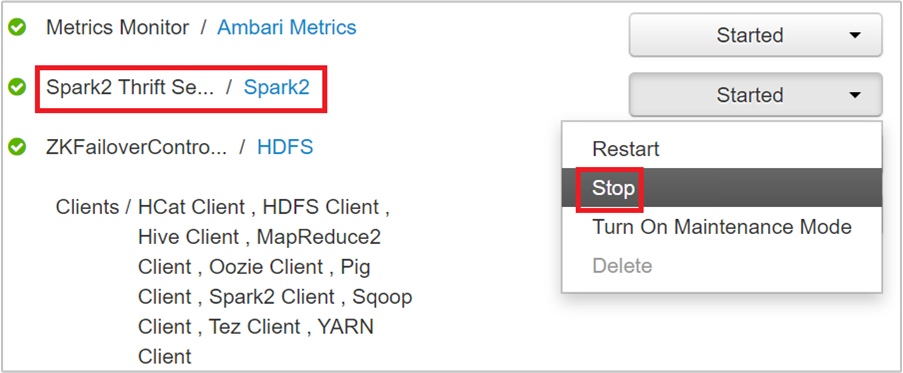
Bu adımları diğer baş düğümde de yineleyin.
Jupyter hizmetini yeniden başlatın
Makalenin başında gösterildiği gibi Ambari Web kullanıcı arabirimini başlatın. Sol gezinti bölmesinde Jupyter'ı, Hizmet Eylemleri'ni ve ardından Tümünü Yeniden Başlat'ı seçin. Bu, tüm baş düğümlerde Jupyter hizmetini başlatır.

Kaynakları izleme
Makalenin başında gösterildiği gibi Yarn kullanıcı arabirimini başlatın. Ekranın üst kısmındaki Küme Ölçümleri tablosunda Kullanılan Bellek ve Bellek Toplam sütunlarının değerlerini denetleyin. İki değer yakınsa, sonraki uygulamayı başlatmak için yeterli kaynak olmayabilir. Aynı durum Kullanılan Sanal Çekirdekler ve Sanal Çekirdek Toplamı sütunları için de geçerlidir. Ayrıca, ana görünümde bir uygulama KABUL EDİlD durumunda kaldıysa ve ÇALıŞıYOR veya BAŞARISIZ durumuna geçiş yapmıyorsa, bu da başlamak için yeterli kaynak almadığının bir göstergesi olabilir.
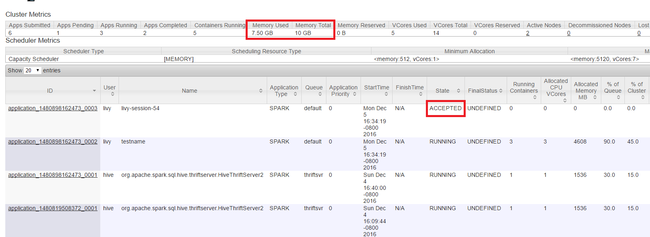
Çalışan uygulamaları sonlandırma
Yarn kullanıcı arabiriminde, sol panelden Çalışıyor'ı seçin. Çalışan uygulamalar listesinden, öldürülecek uygulamayı belirleyin ve kimliği seçin.
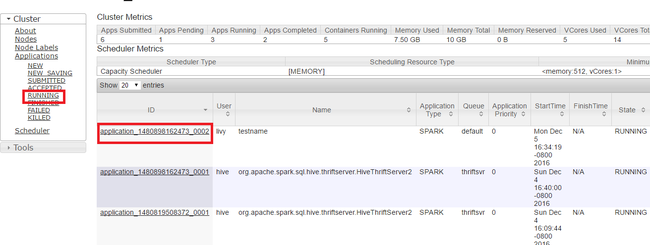
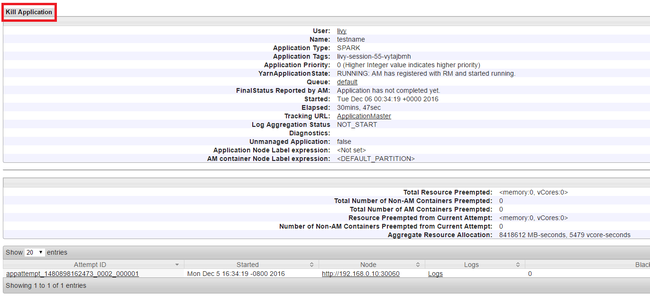
Sağ üst köşedeki Uygulamayı Öldür'e ve ardından Tamam'a tıklayın.
Ayrıca bkz.
Veri analistleri için
- Machine Learning ile Apache Spark: HVAC verilerini kullanarak bina sıcaklığını analiz etmek için HDInsight'ta Spark kullanma
- Machine Learning ile Apache Spark: Gıda denetimi sonuçlarını tahmin etmek için HDInsight'ta Spark kullanma
- HDInsight'ta Apache Spark kullanarak web sitesi günlük analizi
- HDInsight'ta Apache Spark kullanarak Application Insight telemetri veri analizi
Apache Spark geliştiricileri için
- Scala kullanarak tek başına uygulama oluşturma
- Apache Livy kullanarak apache Spark kümesinde işleri uzaktan çalıştırma
- Spark Scala uygulamaları oluşturmak ve göndermek amacıyla IntelliJ IDEA için HDInsight Araçları Eklentisini kullanma
- Apache Spark uygulamalarında uzaktan hata ayıklamak için IntelliJ IDEA için HDInsight Araçları Eklentisi'ni kullanma
- HDInsight üzerinde Apache Spark kümesiyle Apache Zeppelin not defterlerini kullanma
- HDInsight için Apache Spark kümesinde Jupyter Notebook için kullanılabilir çekirdekler
- Jupyter Notebooks ile dış paketleri kullanma
- Jupyter’i bilgisayarınıza yükleme ve bir HDInsight Spark kümesine bağlanma