Metin bileşeni başvurusundan N-Gram Özelliklerini Ayıklama
Bu makalede Azure Machine Learning tasarımcısındaki bir bileşen açıklanmaktadır. Yapılandırılmamış metin verilerini öne çıkarmak için Metinden N-Gram Özelliklerini Ayıkla bileşenini kullanın.
Metinden N-Gram Özelliklerini Ayıkla bileşeninin yapılandırması
Bileşen, n-gram sözlüğü kullanmak için aşağıdaki senaryoları destekler:
Serbest metin sütunundan yeni bir n-gram sözlük oluşturun.
Boş metin sütununu öne getirmek için mevcut bir metin özellikleri kümesini kullanın.
n gram kullanan bir modeli puanla veya dağıtarak.
Yeni n-gram sözlüğü oluşturma
Metinden N-Gram Özelliklerini Ayıkla bileşenini işlem hattınıza ekleyin ve işlemek istediğiniz metnin bulunduğu veri kümesini bağlayın.
Ayıklamak istediğiniz metni içeren dize türünde bir sütun seçmek için Metin sütununu kullanın. Sonuçlar ayrıntılı olduğundan, aynı anda yalnızca tek bir sütunu işleyebilirsiniz.
N-gram özelliklerinin yeni bir listesini oluşturduğunuzu belirtmek için Sözlük modunuOluştur olarak ayarlayın.
Ayıklanıp depolanacağı n gram boyutunun üst sınırını belirtmek için N-Gram boyutunu ayarlayın.
Örneğin, 3 girerseniz, tek birimleri, bigram'ları ve trigramları oluşturulur.
Weighting işlevi , belge özellik vektörlerinin nasıl derlendiği ve belgelerden sözcük dağarcığının nasıl ayıklanması gerektiği belirtir.
İkili Ağırlık: Ayıklanan n grama ikili bir iletişim durumu değeri atar. Her n-gram değeri belgede mevcut olduğunda 1, aksi takdirde 0'dır.
TF Ağırlığı: Ayıklanan n grama bir terim sıklığı (TF) puanı atar. Her n-gram değeri, belgedeki oluşum sıklığıdır.
IDF Ağırlığı: Ayıklanan n grama ters belge sıklığı (IDF) puanı atar. Her n-gram değeri, corpus boyutunun tüm corpus içindeki oluşum sıklığına bölünen günlüğüdür.
IDF = log of corpus_size / document_frequencyTF-IDF Ağırlığı: Ayıklanan n grama terim sıklığı/ters belge sıklığı (TF/IDF) puanı atar. Her n-gram değeri, TF puanının IDF puanıyla çarpılmasıdır.
En küçük sözcük uzunluğunu, n-gram cinsinden herhangi bir tek sözcükte kullanılabilecek minimum harf sayısına ayarlayın.
N-gram cinsinden herhangi bir sözcükte kullanılabilecek harf sayısı üst sınırını ayarlamak için En fazla sözcük uzunluğu kullanın.
Varsayılan olarak, sözcük veya belirteç başına en fazla 25 karaktere izin verilir.
Herhangi bir n-gram değerinin n-gram sözlüğüne eklenmesi için gereken en düşük oluşumları ayarlamak için Minimum n-gram belge mutlak sıklığını kullanın.
Örneğin, varsayılan değer olan 5'i kullanırsanız, n-gram sözlüğüne eklenmesi için herhangi bir n-gram corpus içinde en az beş kez görünmelidir.
En fazla n-gram belge oranını, belirli bir n-gram içeren satır sayısının, genel corpus içindeki satır sayısı üzerindeki en yüksek oranına ayarlayın.
Örneğin, 1 oranı her satırda belirli bir n-gram olsa bile n-gramın n-gram sözlüğüne eklenebileceğini gösterir. Daha tipik olarak, her satırda yer alan bir sözcük gürültü sözcüğü olarak kabul edilir ve kaldırılır. Etki alanına bağlı kirlilik sözcüklerini filtrelemek için bu oranı azaltmayı deneyin.
Önemli
Belirli sözcüklerin oluşum oranı tekdüzen değildir. Belgeden belgeye değişir. Örneğin, belirli bir ürünle ilgili müşteri yorumlarını analiz ediyorsanız, ürün adı çok yüksek frekanslı ve kirli bir sözcüeğe yakın olabilir, ancak diğer bağlamlarda önemli bir terim olabilir.
Özellik vektörlerini normalleştirmek için n-gram özellik vektörlerini normalleştir seçeneğini belirleyin. Bu seçenek etkinleştirilirse, her n-gram özellik vektörleri L2 normlarına bölünür.
İşlem hattını gönderin.
Var olan n-gram sözlüğü kullanma
Metinden N-Gram Özelliklerini Ayıkla bileşenini işlem hattınıza ekleyin ve işlemek istediğiniz metnin bulunduğu veri kümesini Veri Kümesi bağlantı noktasına bağlayın.
Özellik eklemek istediğiniz metni içeren metin sütununu seçmek için Metin sütununu kullanın. Varsayılan olarak, bileşen dize türündeki tüm sütunları seçer. En iyi sonuçları elde için tek seferde tek bir sütunu işleyin.
Önceden oluşturulmuş bir n-gram sözlüğü içeren kaydedilmiş veri kümesini ekleyin ve Giriş sözlüğü bağlantı noktasına bağlayın. Ayrıca Metinden N-Gram Özelliklerini Ayıkla bileşeninin yukarı akış örneğinin Sonuç sözcük dağarcığı çıkışını da bağlayabilirsiniz.
Sözlük modu için açılan listeden ReadOnly update seçeneğini belirleyin.
ReadOnly seçeneği, giriş sözlüğü için giriş corpus'unu temsil eder. Yeni metin veri kümesinden terim sıklıklarını hesaplamak yerine (sol girişte), giriş sözlüğünden gelen n gram ağırlıkları olduğu gibi uygulanır.
İpucu
Metin sınıflandırıcısı puanlarken bu seçeneği kullanın.
Diğer tüm seçenekler için önceki bölümdeki özellik açıklamalarına bakın.
İşlem hattını gönderin.
Gerçek zamanlı uç nokta dağıtmak için n gram kullanan çıkarım işlem hattı oluşturma
Test veri kümesinde tahminde bulunmak için Metinden N Gram Özelliğini Ayıkla ve Modeli Puanla'yı içeren bir eğitim işlem hattı aşağıdaki yapıda derlenir:
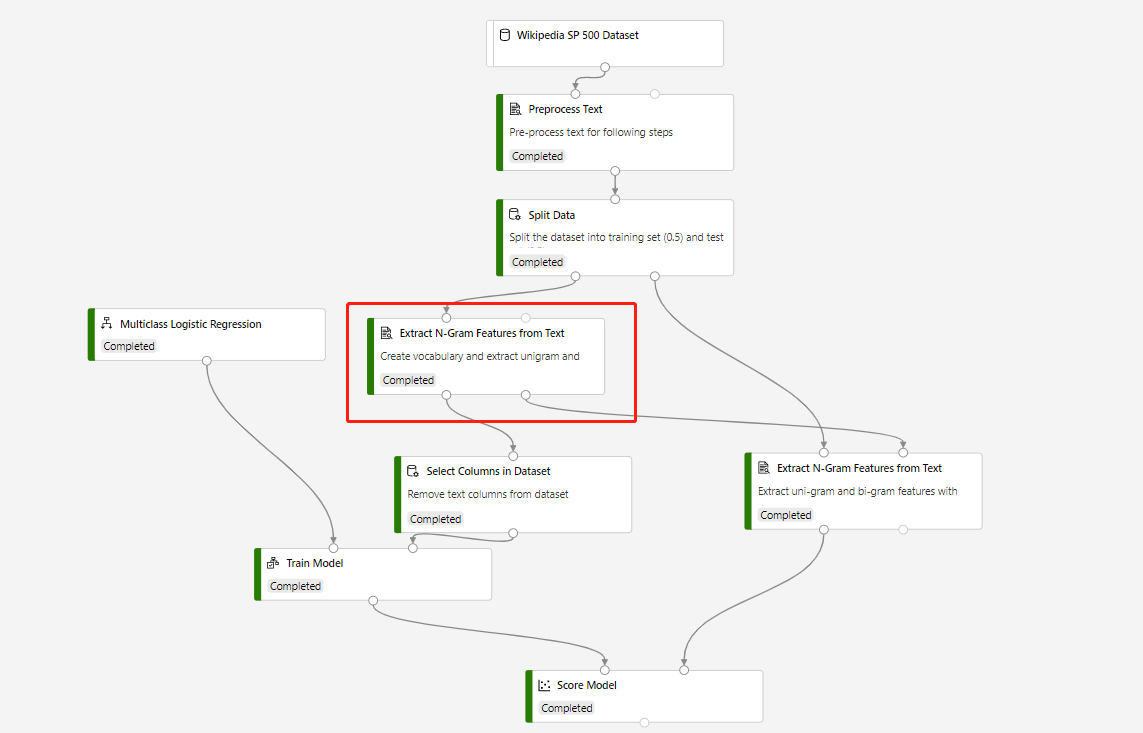
Daire içine alınmış Metinden N Gram Ayıklama ÖzelliğininSözlük moduOluştur, Puan Modeli bileşenine bağlanan bileşenin Sözcük dağarcığı modu ise ReadOnly'dir.
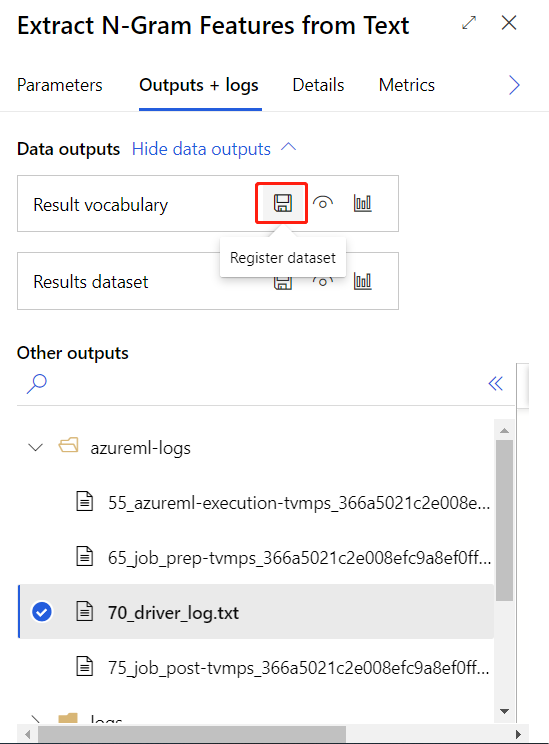
Yukarıdaki eğitim işlem hattını başarıyla gönderdikten sonra, daire içine alınmış bileşenin çıkışını veri kümesi olarak kaydedebilirsiniz.
Ardından gerçek zamanlı çıkarım işlem hattı oluşturabilirsiniz. Çıkarım işlem hattı oluşturduktan sonra çıkarım işlem hattınızı aşağıdaki gibi el ile ayarlamanız gerekir:
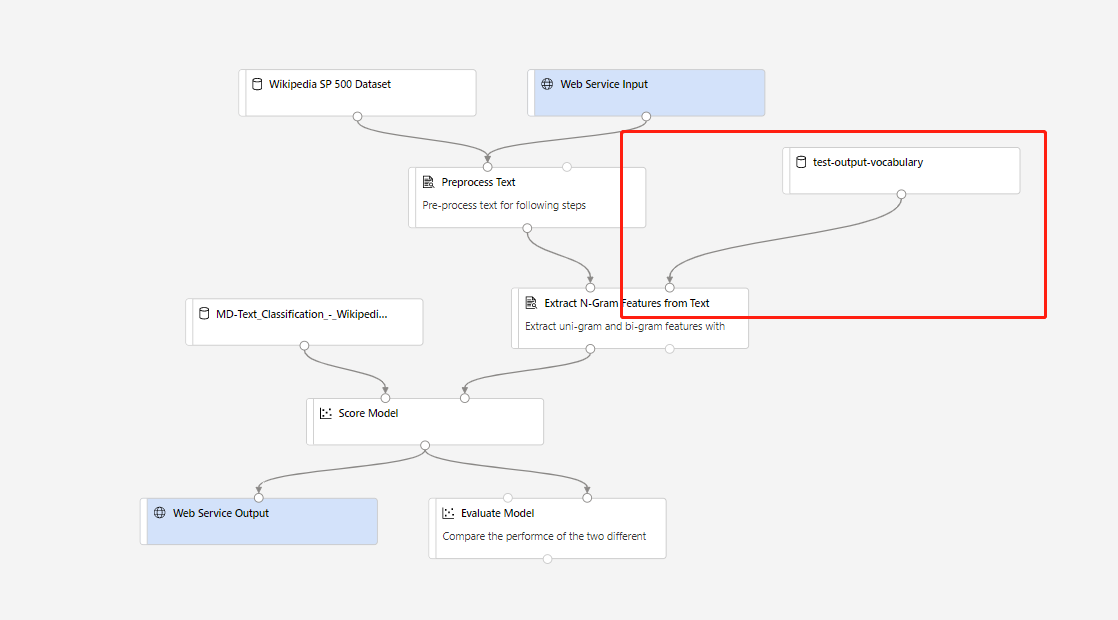
Ardından çıkarım işlem hattını gönderin ve gerçek zamanlı bir uç nokta dağıtın.
Sonuçlar
Metinden N-Gram Özelliklerini Ayıkla bileşeni iki tür çıkış oluşturur:
Sonuç veri kümesi: Bu çıkış, ayıklanan n gram ile birleştirilen analiz edilen metnin özetidir. Metin sütunu seçeneğinde seçmediğiniz sütunlar çıkışa geçirilir. Çözümlediğiniz her metin sütunu için bileşen şu sütunları oluşturur:
- n-gram oluşum matrisi: Bileşen, toplam corpus içinde bulunan her n gram için bir sütun oluşturur ve bu satır için n-gram ağırlığını belirtmek üzere her sütuna bir puan ekler.
Sonuç sözlüğü: Sözcük dağarcığı, analizin bir parçası olarak oluşturulan terim sıklığı puanlarıyla birlikte gerçek n gramlık sözlüğü içerir. Veri kümesini farklı bir giriş kümesiyle yeniden kullanmak veya daha sonraki bir güncelleştirme için kaydedebilirsiniz. Ayrıca kelime dağarcığını modelleme ve puanlama için de yeniden kullanabilirsiniz.
Sonuç sözlüğü
Sözlük, analizin bir parçası olarak oluşturulan sıklık puanlarını içeren n-gram sözlüğü içerir. DF ve IDF puanları diğer seçeneklerden bağımsız olarak oluşturulur.
- Kimlik: Her benzersiz n-gram için oluşturulan tanımlayıcı.
- NGram: N-gram. Boşluklar veya diğer sözcük ayırıcıları, alt çizgi karakteriyle değiştirilir.
- DF: Özgün korpustaki n-gram için terim sıklığı puanı.
- IDF: Özgün korpustaki n-gram için ters belge sıklığı puanı.
Bu veri kümesini el ile güncelleştirebilirsiniz, ancak hatalara neden olabilirsiniz. Örnek:
- Bileşen, giriş sözlüğünde aynı anahtara sahip yinelenen satırlar bulursa bir hata oluşur. Sözlükteki iki satırın aynı sözcüeğe sahip olmadığından emin olun.
- Sözlük veri kümelerinin giriş şeması, sütun adları ve sütun türleri de dahil olmak üzere tam olarak eşleşmelidir.
- Kimlik sütunu ve DF sütunu tamsayı türünde olmalıdır.
- IDF sütunu float türünde olmalıdır.
Not
Veri çıkışını Modeli Eğit bileşenine doğrudan bağlamayın. Eğitim Modeli'ne beslenmeden önce serbest metin sütunlarını kaldırmanız gerekir. Aksi takdirde, serbest metin sütunları kategorik özellikler olarak kabul edilir.
Sonraki adımlar
Bkz. Azure Machine Learning'de kullanılabilen bileşenler kümesi .