Filtre Tabanlı Özellik Seçimi
Bu makalede, Azure Machine Learning tasarımcısında Filtre Tabanlı Özellik Seçimi bileşeninin nasıl kullanılacağı açıklanmaktadır. Bu bileşen, giriş veri kümenizdeki en büyük tahmine dayalı güce sahip sütunları belirlemenize yardımcı olur.
Genel olarak özellik seçimi , belirtilen bir çıkış verilip girişlere istatistiksel testler uygulama işlemini ifade eder. Amaç, hangi sütunların çıktı hakkında daha tahmine dayalı olduğunu belirlemektir. Filtre Tabanlı Özellik Seçimi bileşeni, aralarından seçim yapabileceğiniz birden çok özellik seçimi algoritması sağlar. Bileşen, Pearson bağıntısı ve kikare değerleri gibi bağıntı yöntemlerini içerir.
Filtre Tabanlı Özellik Seçimi bileşenini kullandığınızda, bir veri kümesi sağlar ve etiketi veya bağımlı değişkeni içeren sütunu tanımlarsınız. Ardından özellik önemini ölçmek için kullanılacak tek bir yöntem belirtirsiniz.
Bileşen, en iyi özellik sütunlarını içeren bir veri kümesini tahmine dayalı güce göre derecelendirerek oluşturur. Ayrıca, seçilen ölçümden özelliklerin adlarını ve puanlarını da alır.
Filtre tabanlı özellik seçimi nedir?
İlgisiz öznitelikleri bulmak için seçilen ölçümü kullandığınızdan, özellik seçimi için bu bileşen "filtre tabanlı" olarak adlandırılır. Ardından modelinizdeki yedekli sütunları filtreleyebilirsiniz. Verilerinize uygun tek bir istatistiksel ölçü seçersiniz ve bileşen her özellik sütunu için bir puan hesaplar. Sütunlar, özellik puanlarına göre sıralanmış olarak döndürülür.
Doğru özellikleri seçerek sınıflandırmanın doğruluğunu ve verimliliğini geliştirebilirsiniz.
Tahmine dayalı modelinizi oluşturmak için genellikle yalnızca en iyi puana sahip sütunları kullanırsınız. Özellik seçimi puanları zayıf olan sütunlar veri kümesinde bırakılabilir ve model oluştururken yoksayılabilir.
Özellik seçimi ölçümü seçme
Filter-Based Özellik Seçimi bileşeni, her sütundaki bilgi değerini değerlendirmek için çeşitli ölçümler sağlar. Bu bölümde her ölçümün genel bir açıklaması ve nasıl uygulandığı gösterilir. Her ölçümü kullanmaya yönelik ek gereksinimleri teknik notlarda ve her bileşeni yapılandırma yönergelerinde bulabilirsiniz.
Pearson bağıntısı
Pearson'un korelasyon istatistiği veya Pearson korelasyon katsayısı, istatistiksel modellerde değer olarak
rda bilinir. İki değişken için bağıntının gücünü gösteren bir değer döndürür.Pearson'un korelasyon katsayısı, iki değişkenin kovaryansı alınarak ve standart sapmalarının çarpımlarına bölünerek hesaplanır. İki değişkendeki ölçek değişiklikleri katsayıyı etkilemez.
Kikare
İki yönlü kikare testi, beklenen değerlerin gerçek sonuçlara ne kadar yakın olduğunu ölçen istatistiksel bir yöntemdir. yöntemi, değişkenlerin rastgele olduğunu ve bağımsız değişkenlerin yeterli bir örneğinden çekildiğini varsayar. Elde edilen kikare istatistiği, sonuçların beklenen (rastgele) sonuçtan ne kadar uzak olduğunu gösterir.
İpucu
Özel özellik seçimi yöntemi için farklı bir seçeneğe ihtiyacınız varsa , R Betiği Yürüt bileşenini kullanın.
Filter-Based Özellik Seçimini yapılandırma
Standart bir istatistiksel ölçüm seçersiniz. Bileşen, bir sütun çifti arasındaki bağıntıyı hesaplar: etiket sütunu ve özellik sütunu.
Filter-Based Özellik Seçimi bileşenini işlem hattınıza ekleyin. Bunu tasarımcıdaki Özellik Seçimi kategorisinde bulabilirsiniz.
Olası özelliklerden en az iki sütun içeren bir giriş veri kümesini bağlayın.
Bir sütunun çözümlendiğinden ve özellik puanının oluşturulduğundan emin olmak için , Meta Verileri Düzenle bileşenini kullanarak IsFeature özniteliğini ayarlayın.
Önemli
Giriş olarak sağladığınız sütunların olası özellikler olduğundan emin olun. Örneğin, tek bir değer içeren bir sütunun bilgi değeri yoktur.
Bazı sütunların kötü özelliklere neden olacağını biliyorsanız, bunları sütun seçiminden kaldırabilirsiniz. Ayrıca, Meta Verileri Düzenle bileşenini kullanarak bunları Kategorik olarak işaretleyebilirsiniz.
Özellik puanlama yöntemi için, puanları hesaplamada kullanılacak aşağıdaki yerleşik istatistiksel yöntemlerden birini seçin.
Yöntem Gereksinimler Pearson bağıntısı Etiket metin veya sayısal olabilir. Özellikler sayısal olmalıdır. Kikare Etiketler ve özellikler metin veya sayısal olabilir. İki kategorik sütun için özellik önemini hesaplama amacıyla bu yöntemi kullanın. İpucu
Seçili ölçümü değiştirirseniz diğer tüm seçimler sıfırlanır. Bu nedenle, önce bu seçeneği ayarladığınızdan emin olun.
Yalnızca daha önce özellik olarak işaretlenmiş sütunlar için puan oluşturmak için Yalnızca özellik sütunlarında çalıştır seçeneğini belirleyin.
Bu seçeneği temizlerseniz bileşen, istenen özellik sayısı bölümünde belirtilen sütun sayısına kadar ölçütleri karşılayan herhangi bir sütun için puan oluşturur.
Hedef sütun için Sütun seçiciyi başlat'ı seçerek etiket sütununu ada veya dizine göre seçin. (Dizinler tek tabanlıdır.)
İstatistiksel bağıntı içeren tüm yöntemler için bir etiket sütunu gereklidir. Etiket sütunu veya birden çok etiket sütunu seçmediğinizde bileşen bir tasarım zamanı hatası döndürür.İstenen özellik sayısı alanına sonuç olarak döndürülmesini istediğiniz özellik sütunlarının sayısını girin:
Belirtebileceğiniz en az özellik sayısı birdir, ancak bu değeri artırmanızı öneririz.
Belirtilen istenen özellik sayısı veri kümesindeki sütun sayısından büyükse tüm özellikler döndürülür. Sıfır puana sahip özellikler bile döndürülür.
Özellik sütunlarından daha az sonuç sütunu belirtirseniz, özellikler azalan puana göre sıralanır. Yalnızca en önemli özellikler döndürülür.
İşlem hattını gönderin.
Önemli
Çıkarımda Filtre Tabanlı Özellik Seçimi'ni kullanacaksanız, özellik seçilen sonucunu depolamak için Sütun Dönüştürmeyi Seç'i ve seçilen özelliği puanlama veri kümesine uygulamak için Dönüşümü Uygula'yı kullanmanız gerekir.
Sütun seçimlerinin puanlama işlemi için aynı olduğundan emin olmak için işlem hattınızı oluşturmak için aşağıdaki ekran görüntüsüne bakın.
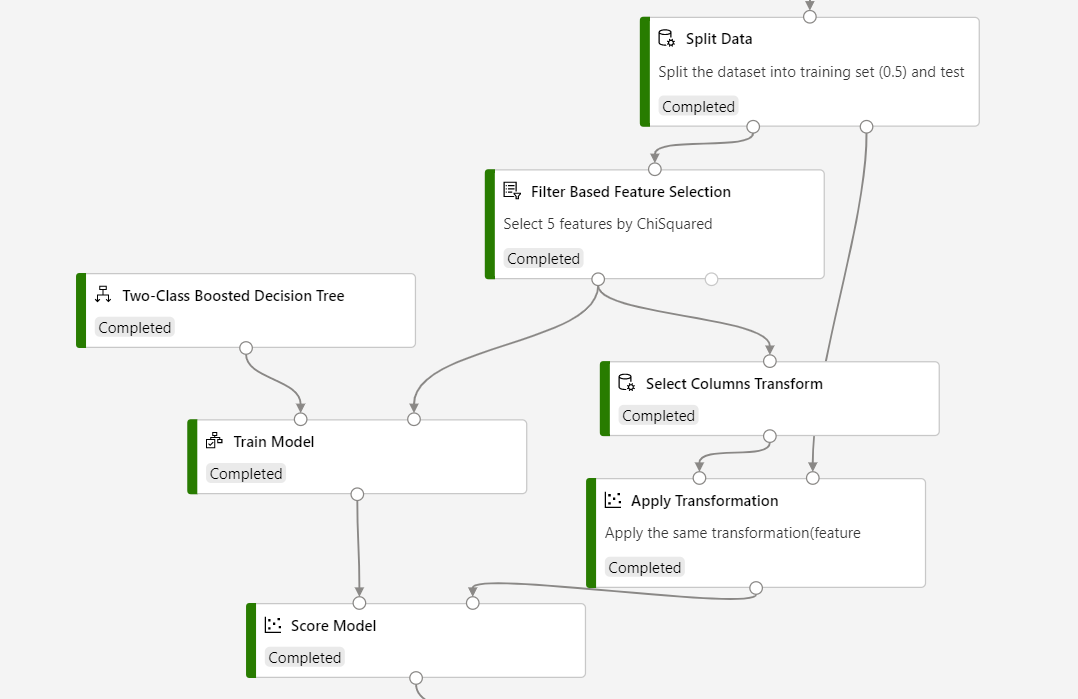
Sonuçlar
İşlem tamamlandıktan sonra:
Analiz edilen özellik sütunlarının ve puanlarının tam listesini görmek için bileşene sağ tıklayın ve Görselleştir'i seçin.
Özellik seçim ölçütlerinize göre veri kümesini görüntülemek için bileşene sağ tıklayın ve Görselleştir'i seçin.
Veri kümesi beklediğinizden daha az sütun içeriyorsa bileşen ayarlarını denetleyin. Giriş olarak sağlanan sütunların veri türlerini de denetleyin. Örneğin, İstenen özellik sayısı ayarını 1 olarak ayarlarsanız, çıkış veri kümesi yalnızca iki sütun içerir: etiket sütunu ve en yüksek dereceli özellik sütunu.
Teknik notlar
Uygulama ayrıntıları
Sayısal bir özellik ve kategorik etiket üzerinde Pearson bağıntısını kullanıyorsanız, özellik puanı aşağıdaki gibi hesaplanır:
Kategorik sütundaki her düzey için sayısal sütunun koşullu ortalamasını hesap edin.
Koşullu ortalamalar sütununu sayısal sütunla ilişkilendirin.
Gereksinimler
Etiket veya Puan sütunu olarak belirlenen hiçbir sütun için özellik seçim puanı oluşturulamaz.
Bir puanlama yöntemini, yöntemin desteklemediği bir veri türü sütunuyla kullanmayı denerseniz, bileşen bir hata oluşturur. Veya sütuna sıfır puan atanır.
Bir sütun mantıksal (true/false) değerler içeriyorsa ve olarak
True = 1False = 0işlenir.Sütun, Etiket veya Puan olarak belirlenmişse özellik olamaz.
Eksik değerler nasıl işlenir?
Tüm eksik değerlerin bulunduğu herhangi bir sütunu hedef (etiket) sütunu olarak belirtemezsiniz.
Bir sütunda eksik değerler varsa, bileşen sütunun puanını hesaplarken bunları yoksayar.
Özellik sütunu olarak belirlenen bir sütunda tüm eksik değerler varsa bileşen sıfır puan atar.
Sonraki adımlar
Bkz. Azure Machine Learning'de kullanılabilen bileşenler kümesi .