Veri alımı işlem hattı için DevOps
Çoğu senaryoda, veri alımı çözümü betiklerin, hizmet çağrılarının ve tüm etkinlikleri düzenleyen bir işlem hattının bileşimidir. Bu makalede, makine öğrenmesi modeli eğitimi için veri hazırlayan ortak bir veri alımı işlem hattının geliştirme yaşam döngüsüne DevOps uygulamalarını uygulamayı öğreneceksiniz. İşlem hattı aşağıdaki Azure hizmetleri kullanılarak oluşturulur:
- Azure Data Factory: Ham verileri okur ve veri hazırlamayı düzenler.
- Azure Databricks: Verileri dönüştüren bir Python not defteri çalıştırır.
- Azure Pipelines: Sürekli tümleştirme ve geliştirme sürecini otomatikleştirir.
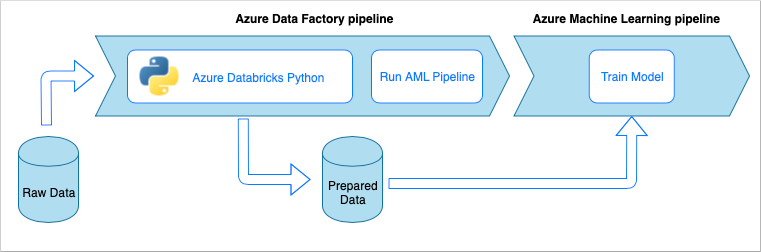
Veri alımı işlem hattı iş akışı
Veri alımı işlem hattı aşağıdaki iş akışını uygular:
- Ham veriler bir Azure Data Factory (ADF) işlem hattında okunur.
- ADF işlem hattı, verileri dönüştürmek için python not defteri çalıştıran bir Azure Databricks kümesine gönderir.
- Veriler, Azure Machine Learning tarafından modeli eğitmek için kullanılabilecek bir blob kapsayıcısına depolanır.
Sürekli tümleştirme ve teslime genel bakış
Birçok yazılım çözümünde olduğu gibi, üzerinde çalışan bir ekip (örneğin, Veri Mühendisi) vardır. Azure Data Factory, Azure Databricks ve Azure Depolama hesapları gibi aynı Azure kaynaklarını birlikte kullanır ve paylaşırlar. Bu kaynakların toplanması bir Geliştirme ortamıdır. Veri mühendisleri aynı kaynak kod tabanına katkıda bulunur.
Sürekli tümleştirme ve teslim sistemi çözümü oluşturma, test etme ve teslim etme (dağıtma) sürecini otomatikleştirir. Sürekli Tümleştirme (CI) işlemi aşağıdaki görevleri gerçekleştirir:
- Kodu bir araya getirme
- Kod kalitesi testleriyle denetler
- Birim testleri çalıştırır
- Test edilmiş kod ve Azure Resource Manager şablonları gibi yapıtlar üretir
Sürekli Teslim (CD) işlemi yapıtları aşağı akış ortamlarına dağıtır.
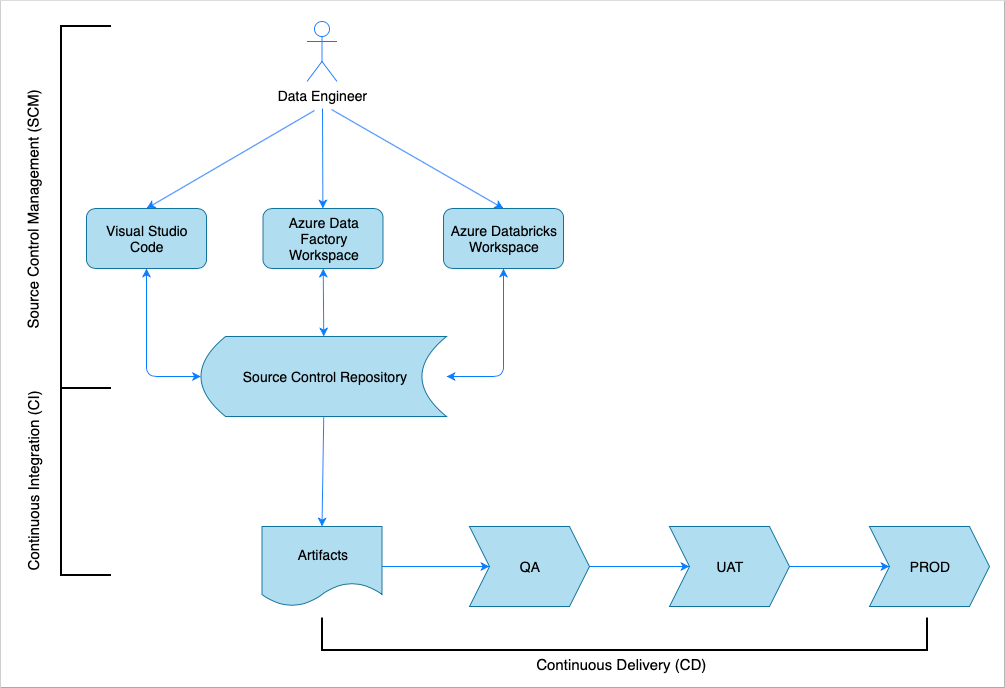
Bu makalede, Azure Pipelines ile CI ve CD işlemlerini otomatikleştirme işlemi gösterilmektedir.
Kaynak denetimi yönetimi
Değişiklikleri izlemek ve ekip üyeleri arasında işbirliğini etkinleştirmek için kaynak denetimi yönetimi gereklidir. Örneğin, kod bir Azure DevOps, GitHub veya GitLab deposunda depolanabilir. İşbirliği iş akışı bir dallanma modelini temel alır.
Python Not Defteri Kaynak Kodu
Veri mühendisleri Python not defteri kaynak koduyla yerel olarak bir IDE'de (örneğin, Visual Studio Code) veya doğrudan Databricks çalışma alanında çalışır. Kod değişiklikleri tamamlandıktan sonra, dallanma ilkesinden sonra depoyla birleştirilir.
İpucu
Kodu .py Jupyter Notebook biçiminde değil dosyalarda .ipynb depolamanızı öneririz. Kod okunabilirliğini artırır ve CI işleminde otomatik kod kalitesi denetimlerini etkinleştirir.
Azure Data Factory Kaynak Kodu
Azure Data Factory işlem hatlarının kaynak kodu, Azure Data Factory çalışma alanı tarafından oluşturulan JSON dosyalarının bir koleksiyonudur. Normalde veri mühendisleri, doğrudan kaynak kod dosyaları yerine Azure Data Factory çalışma alanında bir görsel tasarımcıyla çalışır.
Çalışma alanını kaynak denetimi deposu kullanacak şekilde yapılandırmak için bkz . Azure Repos Git tümleştirmesi ile yazma.
Sürekli tümleştirme (CI)
Sürekli Tümleştirme sürecinin nihai hedefi, ortak ekip çalışmalarını kaynak koddan toplamak ve aşağı akış ortamlarına dağıtım için hazırlamaktır. Kaynak kodu yönetiminde olduğu gibi bu işlem Python not defterleri ve Azure Data Factory işlem hatları için farklıdır.
Python Not Defteri CI
Python Not Defterleri için CI işlemi, kodu işbirliği dalından alır (örneğin, ana dal veya geliştirme) ve aşağıdaki etkinlikleri gerçekleştirir:
- Kod lint
- Birim testi
- Kodu yapıt olarak kaydetme
Aşağıdaki kod parçacığı, bir Azure DevOps yaml işlem hattında bu adımların uygulanmasını gösterir:
steps:
- script: |
flake8 --output-file=$(Build.BinariesDirectory)/lint-testresults.xml --format junit-xml
workingDirectory: '$(Build.SourcesDirectory)'
displayName: 'Run flake8 (code style analysis)'
- script: |
python -m pytest --junitxml=$(Build.BinariesDirectory)/unit-testresults.xml $(Build.SourcesDirectory)
displayName: 'Run unit tests'
- task: PublishTestResults@2
condition: succeededOrFailed()
inputs:
testResultsFiles: '$(Build.BinariesDirectory)/*-testresults.xml'
testRunTitle: 'Linting & Unit tests'
failTaskOnFailedTests: true
displayName: 'Publish linting and unit test results'
- publish: $(Build.SourcesDirectory)
artifact: di-notebooks
İşlem hattı, Python kod lintini yapmak için flake8 kullanır. Kaynak kodda tanımlanan birim testlerini çalıştırır ve azure pipelines yürütme ekranında kullanılabilir olmaları için lint ve test sonuçlarını yayımlar.
Linting ve birim testi başarılı olursa işlem hattı, kaynak kodu sonraki dağıtım adımları tarafından kullanılacak yapıt deposuna kopyalar.
Azure Data Factory CI
Azure Data Factory işlem hattı için CI işlemi, veri alımı işlem hattında performans sorunudur. Sürekli tümleştirme yoktur. Azure Data Factory için dağıtılabilir yapıt, Azure Resource Manager şablonlarından oluşan bir koleksiyondur. Bu şablonları oluşturmanın tek yolu, Azure Data Factory çalışma alanında yayımla düğmesine tıklamaktır.
- Veri mühendisleri, özellik dallarındaki kaynak kodu ana dal veya geliştirme gibiişbirliği dallarıyla birleştirir.
- İzin verilen biri, işbirliği dalındaki kaynak kodundan Azure Resource Manager şablonları oluşturmak için yayımla düğmesine tıklar.
- Çalışma alanı işlem hatlarını doğrular (bunu lint ve birim testi olarak düşünün), Azure Resource Manager şablonları oluşturur (derleme aşamasında düşünün) ve oluşturulan şablonları aynı kod deposundaki bir teknik dal adf_publish kaydeder (yapıtları yayımlama olarak düşünün). Bu dal, Azure Data Factory çalışma alanı tarafından otomatik olarak oluşturulur.
Bu işlem hakkında daha fazla bilgi için bkz . Azure Data Factory'de sürekli tümleştirme ve teslim.
Oluşturulan Azure Resource Manager şablonlarının ortamdan bağımsız olduğundan emin olmak önemlidir. Bu, ortamlar arasında farklılık gösterebilecek tüm değerlerin parametriz olduğu anlamına gelir. Azure Data Factory, bu tür değerlerin çoğunu parametre olarak kullanıma sunan kadar akıllıdır. Örneğin, aşağıdaki şablonda bir Azure Machine Learning çalışma alanına bağlantı özellikleri parametre olarak gösterilir:
{
"$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentParameters.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"factoryName": {
"value": "devops-ds-adf"
},
"AzureMLService_servicePrincipalKey": {
"value": ""
},
"AzureMLService_properties_typeProperties_subscriptionId": {
"value": "0fe1c235-5cfa-4152-17d7-5dff45a8d4ba"
},
"AzureMLService_properties_typeProperties_resourceGroupName": {
"value": "devops-ds-rg"
},
"AzureMLService_properties_typeProperties_servicePrincipalId": {
"value": "6e35e589-3b22-4edb-89d0-2ab7fc08d488"
},
"AzureMLService_properties_typeProperties_tenant": {
"value": "72f988bf-86f1-41af-912b-2d7cd611db47"
}
}
}
Ancak, Azure Data Factory çalışma alanı tarafından varsayılan olarak işlenmeyen özel özelliklerinizi kullanıma sunmanız gerekebilir. Bu makalenin senaryosunda Azure Data Factory işlem hattı verileri işleyen bir Python not defteri çağırır. Not defteri, giriş veri dosyası adıyla bir parametre kabul eder.
import pandas as pd
import numpy as np
data_file_name = getArgument("data_file_name")
data = pd.read_csv(data_file_name)
labels = np.array(data['target'])
...
Bu ad Geliştirme, Soru-Cevap, UAT ve PROD ortamları için farklıdır. Birden çok etkinliği olan karmaşık bir işlem hattında birkaç özel özellik olabilir. Tüm bu değerleri tek bir yerde toplamak ve bunları işlem hattı değişkenleri olarak tanımlamak iyi bir uygulamadır:
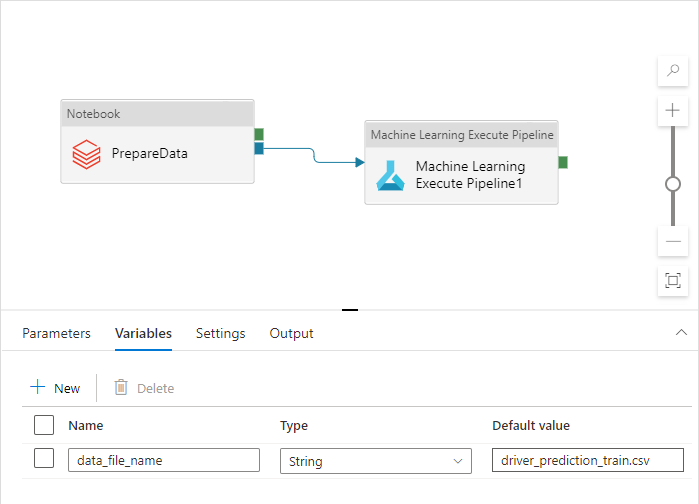
İşlem hattı etkinlikleri, bunları kullanırken işlem hattı değişkenlerine başvurabilir:
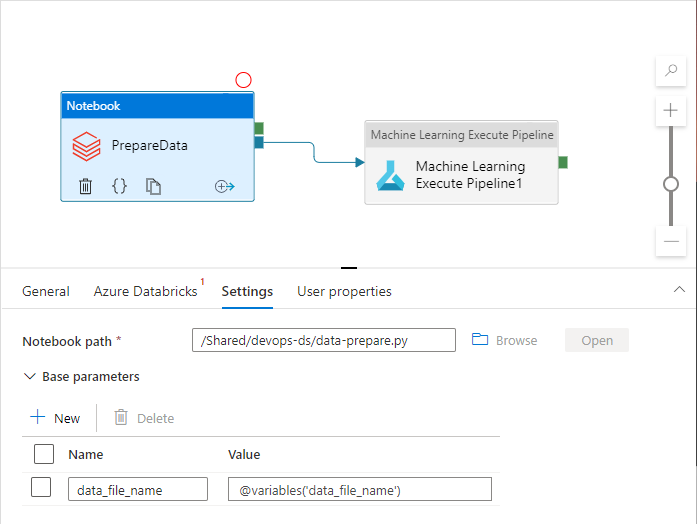
Azure Data Factory çalışma alanı, işlem hattı değişkenlerini varsayılan olarak Azure Resource Manager şablon parametreleri olarak sunmaz. Çalışma alanı, Hangi işlem hattı özelliklerinin Azure Resource Manager şablon parametreleri olarak kullanıma sunılması gerektiğini dikte eden Varsayılan Parametreleştirme Şablonu'nı kullanır. Listeye işlem hattı değişkenleri eklemek için, Varsayılan Parametreleme Şablonu'nun bölümünü aşağıdaki kod parçacığıyla güncelleştirin "Microsoft.DataFactory/factories/pipelines" ve sonuç json dosyasını kaynak klasörün köküne yerleştirin:
"Microsoft.DataFactory/factories/pipelines": {
"properties": {
"variables": {
"*": {
"defaultValue": "="
}
}
}
}
Bunun yapılması, Yayımla düğmesine tıklandığında Azure Data Factory çalışma alanını değişkenleri parametreler listesine eklemeye zorlar:
{
"$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentParameters.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"factoryName": {
"value": "devops-ds-adf"
},
...
"data-ingestion-pipeline_properties_variables_data_file_name_defaultValue": {
"value": "driver_prediction_train.csv"
}
}
}
JSON dosyasındaki değerler, işlem hattı tanımında yapılandırılan varsayılan değerlerdir. Azure Resource Manager şablonu dağıtıldığında hedef ortam değerleriyle geçersiz kılınmaları beklenir.
Sürekli teslim (CD)
Sürekli Teslim işlemi yapıtları alır ve ilk hedef ortama dağıtır. Testleri çalıştırarak çözümün çalıştığından emin olur. Başarılı olursa, sonraki ortama devam eder.
CD Azure Pipelines, ortamları temsil eden birden çok aşamadan oluşur. Her aşama, aşağıdaki adımları gerçekleştiren dağıtımlar ve işler içerir:
- Azure Databricks çalışma alanına Python Not Defteri dağıtma
- Azure Data Factory işlem hattı dağıtma
- İşlem hattını çalıştırma
- Veri alımı sonucunu denetleme
İşlem hattı aşamaları, dağıtım sürecinin ortamlar zinciri aracılığıyla nasıl geliştiği üzerinde ek denetim sağlayan onaylar ve geçitlerle yapılandırılabilir.
Python Not Defteri dağıtma
Aşağıdaki kod parçacığı, Bir Python not defterini Databricks kümesine kopyalayan bir Azure Pipeline dağıtımını tanımlar:
- stage: 'Deploy_to_QA'
displayName: 'Deploy to QA'
variables:
- group: devops-ds-qa-vg
jobs:
- deployment: "Deploy_to_Databricks"
displayName: 'Deploy to Databricks'
timeoutInMinutes: 0
environment: qa
strategy:
runOnce:
deploy:
steps:
- task: UsePythonVersion@0
inputs:
versionSpec: '3.x'
addToPath: true
architecture: 'x64'
displayName: 'Use Python3'
- task: configuredatabricks@0
inputs:
url: '$(DATABRICKS_URL)'
token: '$(DATABRICKS_TOKEN)'
displayName: 'Configure Databricks CLI'
- task: deploynotebooks@0
inputs:
notebooksFolderPath: '$(Pipeline.Workspace)/di-notebooks'
workspaceFolder: '/Shared/devops-ds'
displayName: 'Deploy (copy) data processing notebook to the Databricks cluster'
CI tarafından üretilen yapıtlar dağıtım aracısına otomatik olarak kopyalanır ve klasöründe bulunur $(Pipeline.Workspace) . Bu durumda, dağıtım görevi Python not defterini içeren yapıtı ifade eder di-notebooks . Bu dağıtımda, not defteri dosyalarını Databricks çalışma alanına kopyalamak için Databricks Azure DevOps uzantısı kullanılır.
Aşama, Deploy_to_QA Azure DevOps projesinde tanımlanan değişken grubuna bir başvuru devops-ds-qa-vg içerir. Bu aşamadaki adımlar, bu değişken grubundaki değişkenlere (örneğin ve $(DATABRICKS_URL)$(DATABRICKS_TOKEN)) başvurur. Fikir, sonraki aşamanın (örneğin, Deploy_to_UAT) kendi UAT kapsamlı değişken grubunda tanımlanan değişken adlarıyla çalışmasıdır.
Azure Data Factory işlem hattı dağıtma
Azure Data Factory için dağıtılabilir yapıt bir Azure Resource Manager şablonudur. Aşağıdaki kod parçacığında gösterildiği gibi Azure Kaynak Grubu Dağıtım göreviyle dağıtılacaktır:
- deployment: "Deploy_to_ADF"
displayName: 'Deploy to ADF'
timeoutInMinutes: 0
environment: qa
strategy:
runOnce:
deploy:
steps:
- task: AzureResourceGroupDeployment@2
displayName: 'Deploy ADF resources'
inputs:
azureSubscription: $(AZURE_RM_CONNECTION)
resourceGroupName: $(RESOURCE_GROUP)
location: $(LOCATION)
csmFile: '$(Pipeline.Workspace)/adf-pipelines/ARMTemplateForFactory.json'
csmParametersFile: '$(Pipeline.Workspace)/adf-pipelines/ARMTemplateParametersForFactory.json'
overrideParameters: -data-ingestion-pipeline_properties_variables_data_file_name_defaultValue "$(DATA_FILE_NAME)"
data filename parametresinin değeri, bir QA aşama değişken grubunda tanımlanan değişkenden $(DATA_FILE_NAME) gelir. Benzer şekilde, ARMTemplateForFactory.json dosyasında tanımlanan tüm parametreler geçersiz kılınabilir. Değilse, varsayılan değerler kullanılır.
İşlem hattını çalıştırın ve veri alımı sonucunu denetleyin
Sonraki adım, dağıtılan çözümün çalıştığından emin olmaktır. Aşağıdaki iş tanımı, PowerShell betiğiyle bir Azure Data Factory işlem hattı çalıştırır ve Bir Azure Databricks kümesinde Python not defteri yürütür. Not defteri, verilerin doğru alınıp alınmadığını denetler ve sonuç veri dosyasını adla $(bin_FILE_NAME) doğrular.
- job: "Integration_test_job"
displayName: "Integration test job"
dependsOn: [Deploy_to_Databricks, Deploy_to_ADF]
pool:
vmImage: 'ubuntu-latest'
timeoutInMinutes: 0
steps:
- task: AzurePowerShell@4
displayName: 'Execute ADF Pipeline'
inputs:
azureSubscription: $(AZURE_RM_CONNECTION)
ScriptPath: '$(Build.SourcesDirectory)/adf/utils/Invoke-ADFPipeline.ps1'
ScriptArguments: '-ResourceGroupName $(RESOURCE_GROUP) -DataFactoryName $(DATA_FACTORY_NAME) -PipelineName $(PIPELINE_NAME)'
azurePowerShellVersion: LatestVersion
- task: UsePythonVersion@0
inputs:
versionSpec: '3.x'
addToPath: true
architecture: 'x64'
displayName: 'Use Python3'
- task: configuredatabricks@0
inputs:
url: '$(DATABRICKS_URL)'
token: '$(DATABRICKS_TOKEN)'
displayName: 'Configure Databricks CLI'
- task: executenotebook@0
inputs:
notebookPath: '/Shared/devops-ds/test-data-ingestion'
existingClusterId: '$(DATABRICKS_CLUSTER_ID)'
executionParams: '{"bin_file_name":"$(bin_FILE_NAME)"}'
displayName: 'Test data ingestion'
- task: waitexecution@0
displayName: 'Wait until the testing is done'
İşin son görevi, not defteri yürütmenin sonucunu denetler. Hata döndürürse işlem hattı yürütme durumunu başarısız olarak ayarlar.
Parçaları bir araya getirme
CI/CD Azure Pipeline'ın tamamı aşağıdaki aşamalardan oluşur:
- CI
- Soru-Cevap'a Dağıtma
- Databricks'e dağıtma + ADF'ye dağıtma
- Tümleştirme Testi
Sahip olduğunuz hedef ortam sayısına eşit bir dizi Dağıtım aşaması içerir. Her Dağıtım aşaması, paralel olarak çalışan iki dağıtım ve çözümü ortamda test etmek için dağıtımlardan sonra çalışan bir iş içerir.
İşlem hattının örnek uygulaması aşağıdaki yaml kod parçacığında bir araya getirilir:
variables:
- group: devops-ds-vg
stages:
- stage: 'CI'
displayName: 'CI'
jobs:
- job: "CI_Job"
displayName: "CI Job"
pool:
vmImage: 'ubuntu-latest'
timeoutInMinutes: 0
steps:
- task: UsePythonVersion@0
inputs:
versionSpec: '3.x'
addToPath: true
architecture: 'x64'
displayName: 'Use Python3'
- script: pip install --upgrade flake8 flake8_formatter_junit_xml
displayName: 'Install flake8'
- checkout: self
- script: |
flake8 --output-file=$(Build.BinariesDirectory)/lint-testresults.xml --format junit-xml
workingDirectory: '$(Build.SourcesDirectory)'
displayName: 'Run flake8 (code style analysis)'
- script: |
python -m pytest --junitxml=$(Build.BinariesDirectory)/unit-testresults.xml $(Build.SourcesDirectory)
displayName: 'Run unit tests'
- task: PublishTestResults@2
condition: succeededOrFailed()
inputs:
testResultsFiles: '$(Build.BinariesDirectory)/*-testresults.xml'
testRunTitle: 'Linting & Unit tests'
failTaskOnFailedTests: true
displayName: 'Publish linting and unit test results'
# The CI stage produces two artifacts (notebooks and ADF pipelines).
# The pipelines Azure Resource Manager templates are stored in a technical branch "adf_publish"
- publish: $(Build.SourcesDirectory)/$(Build.Repository.Name)/code/dataingestion
artifact: di-notebooks
- checkout: git://${{variables['System.TeamProject']}}@adf_publish
- publish: $(Build.SourcesDirectory)/$(Build.Repository.Name)/devops-ds-adf
artifact: adf-pipelines
- stage: 'Deploy_to_QA'
displayName: 'Deploy to QA'
variables:
- group: devops-ds-qa-vg
jobs:
- deployment: "Deploy_to_Databricks"
displayName: 'Deploy to Databricks'
timeoutInMinutes: 0
environment: qa
strategy:
runOnce:
deploy:
steps:
- task: UsePythonVersion@0
inputs:
versionSpec: '3.x'
addToPath: true
architecture: 'x64'
displayName: 'Use Python3'
- task: configuredatabricks@0
inputs:
url: '$(DATABRICKS_URL)'
token: '$(DATABRICKS_TOKEN)'
displayName: 'Configure Databricks CLI'
- task: deploynotebooks@0
inputs:
notebooksFolderPath: '$(Pipeline.Workspace)/di-notebooks'
workspaceFolder: '/Shared/devops-ds'
displayName: 'Deploy (copy) data processing notebook to the Databricks cluster'
- deployment: "Deploy_to_ADF"
displayName: 'Deploy to ADF'
timeoutInMinutes: 0
environment: qa
strategy:
runOnce:
deploy:
steps:
- task: AzureResourceGroupDeployment@2
displayName: 'Deploy ADF resources'
inputs:
azureSubscription: $(AZURE_RM_CONNECTION)
resourceGroupName: $(RESOURCE_GROUP)
location: $(LOCATION)
csmFile: '$(Pipeline.Workspace)/adf-pipelines/ARMTemplateForFactory.json'
csmParametersFile: '$(Pipeline.Workspace)/adf-pipelines/ARMTemplateParametersForFactory.json'
overrideParameters: -data-ingestion-pipeline_properties_variables_data_file_name_defaultValue "$(DATA_FILE_NAME)"
- job: "Integration_test_job"
displayName: "Integration test job"
dependsOn: [Deploy_to_Databricks, Deploy_to_ADF]
pool:
vmImage: 'ubuntu-latest'
timeoutInMinutes: 0
steps:
- task: AzurePowerShell@4
displayName: 'Execute ADF Pipeline'
inputs:
azureSubscription: $(AZURE_RM_CONNECTION)
ScriptPath: '$(Build.SourcesDirectory)/adf/utils/Invoke-ADFPipeline.ps1'
ScriptArguments: '-ResourceGroupName $(RESOURCE_GROUP) -DataFactoryName $(DATA_FACTORY_NAME) -PipelineName $(PIPELINE_NAME)'
azurePowerShellVersion: LatestVersion
- task: UsePythonVersion@0
inputs:
versionSpec: '3.x'
addToPath: true
architecture: 'x64'
displayName: 'Use Python3'
- task: configuredatabricks@0
inputs:
url: '$(DATABRICKS_URL)'
token: '$(DATABRICKS_TOKEN)'
displayName: 'Configure Databricks CLI'
- task: executenotebook@0
inputs:
notebookPath: '/Shared/devops-ds/test-data-ingestion'
existingClusterId: '$(DATABRICKS_CLUSTER_ID)'
executionParams: '{"bin_file_name":"$(bin_FILE_NAME)"}'
displayName: 'Test data ingestion'
- task: waitexecution@0
displayName: 'Wait until the testing is done'