Veri varlıklarını oluşturma ve yönetme
ŞUNLAR IÇIN GEÇERLIDIR: Azure CLI ml uzantısı v2 (geçerli)Python SDK azure-ai-ml v2 (geçerli)
Azure CLI ml uzantısı v2 (geçerli)Python SDK azure-ai-ml v2 (geçerli)
Bu makalede Azure Machine Learning'de veri varlıklarının nasıl oluşturulacağı ve yönetileceğini gösterilmektedir.
Veri varlıkları şu özelliklere ihtiyacınız olduğunda yardımcı olabilir:
- Sürüm oluşturma: Veri varlıkları, veri sürümü oluşturma işlemini destekler.
- Yeniden üretilebilirlik: Bir veri varlığı sürümü oluşturduktan sonra sabittir. Değiştirilemez veya silinemez. Bu nedenle, veri varlığını kullanan eğitim işleri veya işlem hatları yeniden oluşturulabilir.
- Denetlenebilirlik: Veri varlığı sürümü sabit olduğundan, varlık sürümlerini, sürümü güncelleştirenleri ve sürüm güncelleştirmelerinin ne zaman gerçekleştiğini izleyebilirsiniz.
- Köken: Belirli bir veri varlığı için hangi işlerin veya işlem hatlarının verileri tükettiğine bakabilirsiniz.
- Kullanım kolaylığı: Azure makine öğrenmesi veri varlığı, web tarayıcısı yer işaretlerine (sık kullanılanlar) benzer. Azure Depolama'da sık kullanılan verilerinize başvuran uzun depolama yollarını (URI' ler) hatırlamak yerine, bir veri varlığı sürümü oluşturabilir ve varlığın bu sürümüne kolay bir adla erişebilirsiniz (örneğin:
azureml:<my_data_asset_name>:<version>).
Bahşiş
Etkileşimli bir oturumda (örneğin, bir not defteri) veya bir işte verilerinize erişmek için, önce bir veri varlığı oluşturmanız gerekmez. Verilere erişmek için Datastore URI'lerini kullanabilirsiniz. Veri deposu URI'leri, Azure machine learning'i kullanmaya başlayanlar için verilere erişmek için basit bir yol sunar.
Ön koşullar
Veri varlıkları oluşturmak ve bunlarla çalışmak için şunları yapmanız gerekir:
Azure aboneliği. Aboneliğiniz yoksa başlamadan önce ücretsiz bir hesap oluşturun. Azure Machine Learning'in ücretsiz veya ücretli sürümünü deneyin.
Azure Machine Learning çalışma alanı. Çalışma alanı kaynakları oluşturun.
Veri varlıkları oluşturma
Veri varlığınızı oluştururken veri varlığı türünü ayarlamanız gerekir. Azure Machine Learning üç veri varlığı türünü destekler:
| Tür | API | Kurallı Senaryolar |
|---|---|---|
| Dosya Tek bir dosyaya başvurma |
uri_file |
Azure Depolama'da tek bir dosyayı okuyun (dosya herhangi bir biçime sahip olabilir). |
| Klasör Klasöre başvurma |
uri_folder |
Pandas/Spark'ta parquet/CSV dosyalarının bir klasörünü okuyun. Bir klasörde bulunan yapılandırılmamış verileri (görüntüler, metin, ses vb.) okuyun. |
| Table Veri tablosuna başvurma |
mltable |
Sık yapılan değişikliklere tabi olan karmaşık bir şemanız var veya büyük tablosal verilerin bir alt kümesine ihtiyacınız var. Tablolu AutoML. Birden çok depolama konumuna yayılmış yapılandırılmamış verileri (görüntüler, metin, ses vb.) okuyun. |
Dekont
Verileri MLTable olarak kaydetmediğiniz sürece lütfen csv dosyalarında eklenmiş yeni satırlar kullanmayın. Csv dosyalarına eklenen yeni satırlar, verileri okuduğunuzda yanlış hizalanmış alan değerlerine neden olabilir. MLTable, tırnak içindeki satır sonlarını tek bir kayıt olarak yorumlamak için dönüştürmede read_delimited bu parametreye support_multi_linesahiptir.
Veri varlığını bir Azure Machine Learning işinde kullandığınızda, varlığı işlem düğümlerine bağlayabilir veya indirebilirsiniz . Daha fazla bilgi için lütfen Modlar'ı okuyun.
Ayrıca, veri varlığı konumuna işaret eden bir path parametre belirtmeniz gerekir. Desteklenen yollar şunlardır:
| Konum | Örnekler |
|---|---|
| Yerel bilgisayarınızdaki bir yol | ./home/username/data/my_data |
| Veri deposundaki bir yol | azureml://datastores/<data_store_name>/paths/<path> |
| Ortak http(ler) sunucusundaki yol | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
| Azure Depolama'da yol | (Blob) wasbs://<containername>@<accountname>.blob.core.windows.net/<path_to_data>/(ADLS 2. Nesil) abfss://<file_system>@<account_name>.dfs.core.windows.net/<path> (ADLS 1. nesil) adl://<accountname>.azuredatalakestore.net/<path_to_data>/ |
Dekont
Yerel bir yoldan veri varlığı oluşturduğunuzda, bu varlık otomatik olarak varsayılan Azure Machine Learning bulut veri deposuna yüklenir.
Veri varlığı oluşturma: Dosya türü
Dosya (uri_file) türündeki bir veri varlığı, depolamadaki tek bir dosyayı (örneğin, CSV dosyası) gösterir. Dosya türüne sahip bir veri varlığı oluşturmak için şunu kullanabilirsiniz:
Bir YAML dosyası oluşturun ve aşağıdaki kodu kopyalayıp yapıştırın. Yer tutucuları veri varlığınızın adı, sürüm, açıklama ve desteklenen bir konumdaki tek bir dosyanın yolu ile güncelleştirmeniz <> gerekir.
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
# Supported paths include:
# local: './<path>/<file>' (this will be automatically uploaded to cloud storage)
# blob: 'wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>/<file>'
# ADLS gen2: 'abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>/<file>'
# Datastore: 'azureml://datastores/<data_store_name>/paths/<path>/<file>'
type: uri_file
name: <NAME OF DATA ASSET>
version: <VERSION>
description: <DESCRIPTION>
path: <SUPPORTED PATH>
Ardından, CLI'da aşağıdaki komutu yürütür (yer tutucuyu <filename> YAML dosya adıyla güncelleştirin):
az ml data create -f <filename>.yml



Veri varlığı oluşturma: Klasör türü
Klasör (uri_folder) türünde bir veri varlığı, depolamadaki bir klasörü (örneğin, birkaç resim alt klasörü içeren bir klasör) gösteren varlıktır. Aşağıdakini kullanarak klasör türüne sahip bir veri varlığı oluşturabilirsiniz:
Bir YAML dosyası oluşturun ve aşağıdaki kodu kopyalayıp yapıştırın. Yer tutucuları veri varlığınızın adı, sürümü, açıklaması ve desteklenen bir konumdaki bir klasörün yolu ile güncelleştirmeniz <> gerekir.
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
# Supported paths include:
# local: './<path>/<folder>' (this will be automatically uploaded to cloud storage)
# blob: 'wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>/<folder>'
# ADLS gen2: 'abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>/<folder>'
# Datastore: 'azureml://datastores/<data_store_name>/paths/<path>/<folder>'
type: uri_folder
name: <NAME OF DATA ASSET>
version: <VERSION>
description: <DESCRIPTION>
path: <SUPPORTED PATH>
Ardından, CLI'da aşağıdaki komutu yürütür (yer tutucuyu <filename> dosya adına YAML dosya adıyla güncelleştirin):
az ml data create -f <filename>.yml
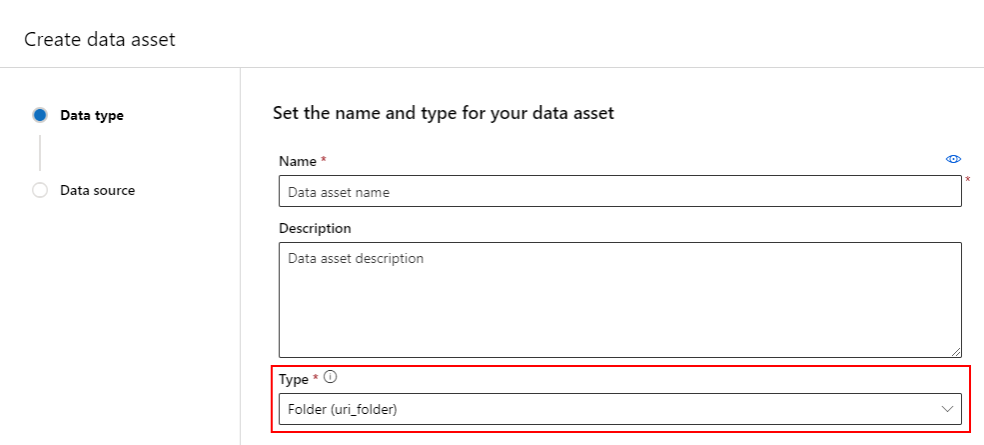
Veri varlığı oluşturma: Tablo türü
Azure Machine Learning Tabloları (MLTable), Azure Machine Learning'de tablolarla çalışma bölümünde daha ayrıntılı olarak ele alınan zengin işlevlere sahiptir. Bu belgeleri burada yinelemek yerine, genel kullanıma açık bir Azure Blob Depolama hesabında bulunan Titanik verilerini kullanarak Tablo türündeki bir veri varlığı oluşturma örneği sunuyoruz.
İlk olarak data adlı yeni bir dizin oluşturun ve MLTable adlı bir dosya oluşturun:
mkdir data
touch MLTable
Ardından, aşağıdaki YAML'yi kopyalayıp önceki adımda oluşturduğunuz MLTable dosyasına yapıştırın:
Dikkat
Dosyayı veya olarak yeniden adlandırmayın.MLTableMLTable.ymlMLTable.yaml Azure machine learning bir MLTable dosya bekler.
paths:
- file: wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv
transformations:
- read_delimited:
delimiter: ','
empty_as_string: false
encoding: utf8
header: all_files_same_headers
include_path_column: false
infer_column_types: true
partition_size: 20971520
path_column: Path
support_multi_line: false
- filter: col('Age') > 0
- drop_columns:
- PassengerId
- convert_column_types:
- column_type:
boolean:
false_values:
- 'False'
- 'false'
- '0'
mismatch_as: error
true_values:
- 'True'
- 'true'
- '1'
columns: Survived
type: mltable
Ardından, CLI'da aşağıdaki komutu yürütür. Yer tutucuları veri varlığı adı ve sürüm değerleriyle güncelleştirdiğinizden <> emin olun.
az ml data create --path ./data --name <DATA ASSET NAME> --version <VERSION> --type mltable
Önemli
geçerli pathMLTable bir dosya içeren bir klasör olmalıdır.
İş çıkışlarından veri varlıkları oluşturma
Çıktıda parametresini ayarlayarak bir Azure Machine Learning işinden name veri varlığı oluşturabilirsiniz. Bu örnekte, bir genel blob deposundaki verileri varsayılan Azure Machine Learning Datastore'nuza kopyalayan ve adlı job_output_titanic_assetbir veri varlığı oluşturan bir iş gönderirsiniz.
İş belirtimi YAML dosyası (<file-name>.yml):
$schema: https://azuremlschemas.azureedge.net/latest/commandJob.schema.json
# path: Set the URI path for the data. Supported paths include
# local: `./<path>
# Blob: wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>
# ADLS: abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# Data Asset: azureml:<my_data>:<version>
# type: What type of data are you pointing to?
# uri_file (a specific file)
# uri_folder (a folder)
# mltable (a table)
# mode: Set INPUT mode:
# ro_mount (read-only mount)
# download (download from storage to node)
# mode: Set the OUTPUT mode
# rw_mount (read-write mount)
# upload (upload data from node to storage)
type: command
command: cp ${{inputs.input_data}} ${{outputs.output_data}}
compute: azureml:cpu-cluster
environment: azureml://registries/azureml/environments/sklearn-1.1/versions/4
inputs:
input_data:
mode: ro_mount
path: azureml:wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv
type: uri_file
outputs:
output_data:
mode: rw_mount
path: azureml://datastores/workspaceblobstore/paths/quickstart-output/titanic.csv
type: uri_file
name: job_output_titanic_asset
Ardından, CLI kullanarak işi gönderin:
az ml job create --file <file-name>.yml
Veri varlıklarını yönetme
Veri varlığını silme
Önemli
Tasarım gereği, veri varlığı silme desteklenmez.
Azure makine öğrenmesi veri varlığının silinmesine izin verirse aşağıdaki olumsuz etkilere neden olabilir:
- Daha sonra silinen veri varlıklarını kullanan üretim işleri başarısız olur.
- Ml denemesini yeniden oluşturmak daha zor olacaktır.
- silinen veri varlığı sürümünü görüntülemek imkansız hale geleceği için iş kökeni bozulacaktı.
- Sürümler eksik olabileceğinden doğru şekilde izleyemez ve denetleyemezsiniz .
Bu nedenle, veri varlıklarının değişmezliği, üretim iş yükleri oluşturan bir ekipte çalışırken bir koruma düzeyi sağlar.
Hatalı bir ad, tür veya yol ile hatalı bir şekilde bir veri varlığı oluşturulduğunda Azure Machine Learning, silme işleminin olumsuz sonuçları olmadan durumu ele almak için çözümler sunar:
| Bu veri varlığını silmek istiyorum çünkü... | Çözüm |
|---|---|
| Ad yanlış | Veri varlığını arşivle |
| Ekip artık veri varlığını kullanmıyor | Veri varlığını arşivle |
| Veri varlığı listesini karışıklığa neden olur | Veri varlığını arşivle |
| Yol yanlış | Doğru yola sahip veri varlığının yeni bir sürümünü (aynı ad) oluşturun. Daha fazla bilgi için Bkz . Veri varlıkları oluşturma. |
| Yanlış bir türe sahip | Şu anda Azure Machine Learning, ilk sürümle karşılaştırıldığında farklı türde yeni bir sürüm oluşturulmasına izin vermiyor. (1) Veri varlığını arşivle (2) Doğru türde farklı bir ad altında yeni bir veri varlığı oluşturun. |
Veri varlığını arşivle
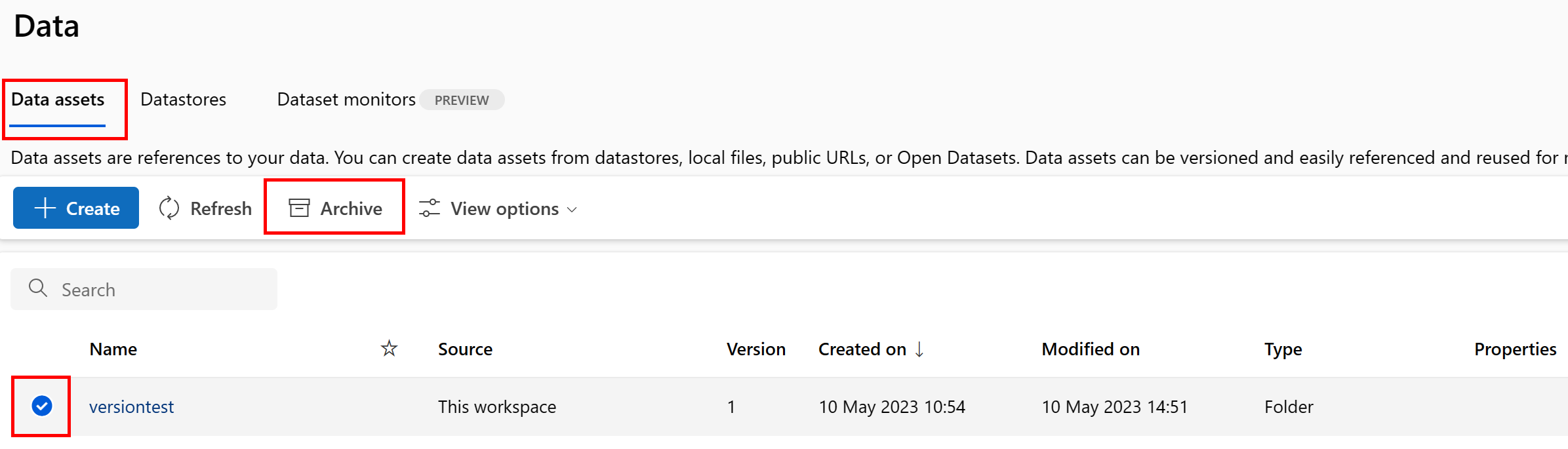
Bir veri varlığını arşivleme, varsayılan olarak hem liste sorgularından (örneğin, CLI'de az ml data list) hem de Studio kullanıcı arabirimindeki veri varlığı listesinde gizler. İş akışlarınızda arşivlenmiş bir veri varlığına başvurmaya ve kullanmaya devam edebilirsiniz. Aşağıdakilerden birini arşivleyebilirsiniz:
- veri varlığının belirli bir ad altındaki tüm sürümleri veya
- belirli bir veri varlığı sürümü
Veri varlığının tüm sürümlerini arşivle
Veri varlığının tüm sürümlerini belirli bir ad altında arşivleyebilmek için şunu kullanın:
Aşağıdaki komutu yürüt (yer tutucuyu <> veri varlığınızın adıyla güncelleştirin):
az ml data archive --name <NAME OF DATA ASSET>
Belirli bir veri varlığı sürümünü arşivle
Belirli bir veri varlığı sürümünü arşiv etmek için şunu kullanın:
Aşağıdaki komutu yürüt (yer tutucuları veri varlığınızın ve sürümünüzün adıyla güncelleştirin <> ):
az ml data archive --name <NAME OF DATA ASSET> --version <VERSION TO ARCHIVE>
Arşivlenmiş veri varlığını geri yükleme
Arşivlenmiş bir veri varlığını geri yükleyebilirsiniz. Veri varlığının tüm sürümleri arşivlenmişse, veri varlığının tek tek sürümlerini geri yükleyemezsiniz. Tüm sürümleri geri yüklemeniz gerekir.
Veri varlığının tüm sürümlerini geri yükleme
Veri varlığının belirli bir ad altındaki tüm sürümlerini geri yüklemek için şunu kullanın:
Aşağıdaki komutu yürüt (yer tutucuyu <> veri varlığınızın adıyla güncelleştirin):
az ml data restore --name <NAME OF DATA ASSET>


Belirli bir veri varlığı sürümünü geri yükleme
Önemli
Tüm veri varlığı sürümleri arşivlendiyse, veri varlığının tek tek sürümlerini geri yükleyemezsiniz. Tüm sürümleri geri yüklemeniz gerekir.
Belirli bir veri varlığı sürümünü geri yüklemek için şunu kullanın:
Aşağıdaki komutu yürüt (yer tutucuları veri varlığınızın ve sürümünüzün adıyla güncelleştirin <> ):
az ml data restore --name <NAME OF DATA ASSET> --version <VERSION TO ARCHIVE>
Veri kökeni
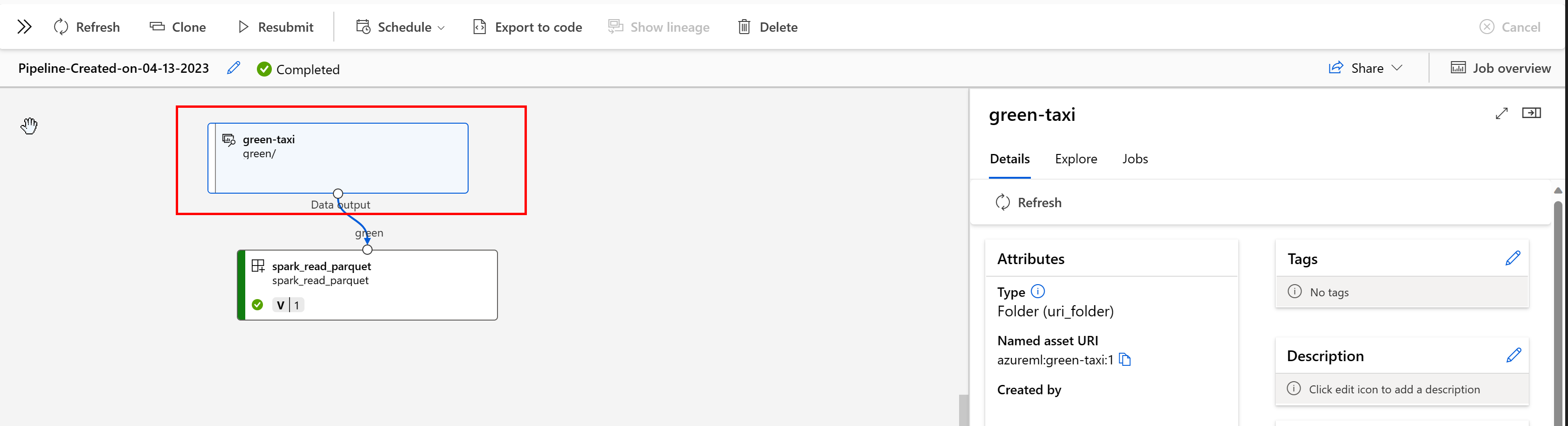
Veri kökeni, verilerin kaynağını kapsayan yaşam döngüsü ve zaman içinde depolama alanı boyunca nereye taşınacağı olarak geniş ölçüde anlaşılır. Farklı türde geriye dönük senaryolar bunu kullanır; örneğin, sorun giderme, ML işlem hatlarında kök nedenleri izleme ve hata ayıklama. Veri kalitesi analizi, uyumluluk ve "durum" senaryolarında da köken kullanılır. Köken, kaynaktan hedefe taşınan verileri göstermek için görsel olarak temsil edilir ve ayrıca veri dönüşümlerini kapsar. Çoğu kurumsal veri ortamlarının karmaşıklığı göz önüne alındığında, bu görünümlerin çevre birimi veri noktalarını birleştirmeden veya maskelemeden anlaşılması zor olabilir.
Azure Machine Learning İşlem Hattı'nda veri varlıklarınız verilerin kaynağını ve verilerin nasıl işlendiğini gösterir, örneğin:
Veri varlığını kullanan işleri Studio kullanıcı arabiriminde görüntüleyebilirsiniz. İlk olarak, sol taraftaki menüden Veri'yi seçin ve ardından veri varlığı adını seçin. Veri varlığını kullanan işleri görebilirsiniz:
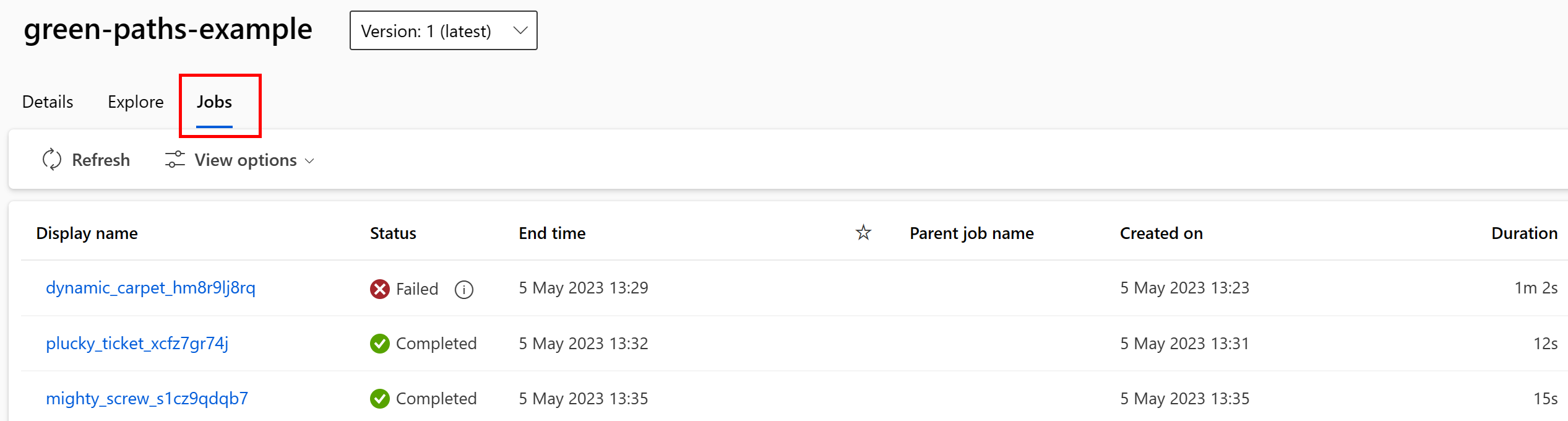
Veri varlıklarındaki işler görünümü, iş hatalarını bulmayı ve ML işlem hatlarınızda ve hata ayıklamanızda yol neden analizi yapmayı kolaylaştırır.
Veri varlığı etiketleme
Veri varlıkları, anahtar-değer çifti biçiminde veri varlığına uygulanan ek meta veriler olan etiketlemeyi destekler. Veri etiketleme birçok avantaj sağlar:
- Veri kalitesi açıklaması. Örneğin, kuruluşunuz bir madalyon göl evi mimarisi kullanıyorsa varlıkları (ham),
medallion:silver(doğrulanmış) vemedallion:gold(zenginleştirilmiş) etiketleyebilirsinizmedallion:bronze. - Verilerin bulunmasına yardımcı olmak için verilerin verimli bir şekilde aranıp filtrelenmesine olanak sağlar.
- Veri erişimini düzgün bir şekilde yönetmek ve yönetmek için hassas kişisel verilerin tanımlanmasına yardımcı olur. Örneğin,
sensitivity:PII/sensitivity:nonPII. - Verilerin sorumlu bir yapay zeka (RAI) denetiminden onaylanıp onaylanmamış olduğunu belirleyin. Örneğin,
RAI_audit:approved/RAI_audit:todo.
Veri varlıklarına oluşturma akışlarının bir parçası olarak etiket ekleyebilir veya mevcut veri varlıklarına etiket ekleyebilirsiniz. Bu bölümde her ikisi de gösterilir.
Veri varlığı oluşturma akışının parçası olarak etiket ekleme
BIR YAML dosyası oluşturun ve aşağıdaki kodu kopyalayıp yapıştırın. Yer tutucuları veri varlığınızın adı, sürümü, açıklaması, etiketleri (anahtar-değer çiftleri) ve desteklenen bir konumdaki tek bir dosyanın yolu ile güncelleştirmeniz <> gerekir.
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
# Supported paths include:
# local: './<path>/<file>' (this will be automatically uploaded to cloud storage)
# blob: 'wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>/<file>'
# ADLS gen2: 'abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>/<file>'
# Datastore: 'azureml://datastores/<data_store_name>/paths/<path>/<file>'
# Data asset types, use one of:
# uri_file, uri_folder, mltable
type: uri_file
name: <NAME OF DATA ASSET>
version: <VERSION>
description: <DESCRIPTION>
tags:
<KEY1>: <VALUE>
<KEY2>: <VALUE>
path: <SUPPORTED PATH>
Ardından, CLI'da aşağıdaki komutu yürütür (yer tutucuyu <filename> YAML dosya adıyla güncelleştirin):
az ml data create -f <filename>.yml
Mevcut bir veri varlığına etiket ekleme
Azure CLI'da aşağıdaki komutu yürüterek yer tutucuları etiketin <> veri varlığı adı, sürümü ve anahtar-değer çiftiyle güncelleştirin.
az ml data update --name <DATA ASSET NAME> --version <VERSION> --set tags.<KEY>=<VALUE>

Sürüm oluşturma en iyi yöntemleri
ETL işlemleriniz genellikle Azure depolamadaki klasör yapınızı zamana göre düzenler, örneğin:
/
└── 📁 mydata
├── 📁 year=2022
│ ├── 📁 month=11
│ │ └── 📄 file1
│ │ └── 📄 file2
│ └── 📁 month=12
│ └── 📄 file1
│ │ └── 📄 file2
└── 📁 year=2023
└── 📁 month=1
└── 📄 file1
│ │ └── 📄 file2
Zaman/sürüm yapılandırılmış klasörleri ve Azure Machine Learning Tablolarının (MLTable) birleşimi, sürümlenmiş veri kümeleri oluşturmanıza olanak tanır. Azure Machine Learning Tabloları ile sürüm verilerine ulaşmayı göstermek için varsayımsal bir örnek kullanırız. Aşağıdaki yapıda kamera görüntülerini her hafta Azure Blob depolamaya yükleyen bir işleminiz olduğunu varsayalım:
/myimages
└── 📁 year=2022
├── 📁 week52
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
└── 📁 year=2023
├── 📁 week1
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
Dekont
Görüntü (jpeg) verilerinin nasıl sürüm oluşturulacağını göstersek de, aynı metodoloji herhangi bir dosya türüne (örneğin, Parquet, CSV) uygulanabilir.
Azure Machine Learning Tabloları ()mltable ile, 2023'te ilk haftanın sonuna kadar verileri içeren bir Yol Tablosu oluşturur ve ardından bir veri varlığı oluşturursunuz:
import mltable
from mltable import MLTableHeaders, MLTableFileEncoding, DataType
from azure.ai.ml import MLClient
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
from azure.identity import DefaultAzureCredential
# The ** in the pattern below will glob all sub-folders (camera1, ..., camera2)
paths = [
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2022/week=52/**/*.jpeg"
},
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2023/week=1/**/*.jpeg"
},
]
tbl = mltable.from_paths(paths)
tbl.save("./myimages")
# Connect to the AzureML workspace
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# Define the Data asset object
my_data = Data(
path=mltable_folder,
type=AssetTypes.MLTABLE,
description="My images. Version includes data through to 2023-Jan-08.",
name="myimages",
version="20230108",
)
# Create the data asset in the workspace
ml_client.data.create_or_update(my_data)
Sonraki haftanın sonunda ETL'niz verileri daha fazla veri içerecek şekilde güncelleştirdi:
/myimages
└── 📁 year=2022
├── 📁 week52
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
└── 📁 year=2023
├── 📁 week1
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
├── 📁 week2
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
İlk sürümünüz (20230108) ve içindeki dosyaları year=2022/week=52year=2023/week=1 bağlamaya/indirmeye devam eder çünkü yollar dosyada MLTable bildirilir. Bu, denemeleriniz için yeniden üretilebilirlik sağlar. veri varlığının içeren year=2023/week2yeni bir sürümünü oluşturmak için şunları kullanabilirsiniz:
import mltable
from mltable import MLTableHeaders, MLTableFileEncoding, DataType
from azure.ai.ml import MLClient
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
from azure.identity import DefaultAzureCredential
# The ** in the pattern below will glob all sub-folders (camera1, ..., camera2)
paths = [
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2022/week=52/**/*.jpeg"
},
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2023/week=1/**/*.jpeg"
},
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2023/week=2/**/*.jpeg"
},
]
# Save to an MLTable file on local storage
tbl = mltable.from_paths(paths)
tbl.save("./myimages")
# Next, you create a data asset - the MLTable file will automatically be uploaded
# Connect to the AzureML workspace
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# Define the Data asset object
my_data = Data(
path=mltable_folder,
type=AssetTypes.MLTABLE,
description="My images. Version includes data through to 2023-Jan-15.",
name="myimages",
version="20230115", # update version to the date
)
# Create the data asset in the workspace
ml_client.data.create_or_update(my_data)
Artık verilerin iki sürümüne sahipsiniz ve burada sürümün adı görüntülerin depolama alanına yüklendiği tarihe karşılık gelir:
- 20230108: 2023-Ocak 08'e kadar olan görüntüler.
- 20230115: 2023-Ocak 15'e kadar olan görüntüler.
Her iki durumda da MLTable, yalnızca bu tarihlere kadar olan görüntüleri içeren bir yol tablosu oluşturur.
Azure Machine Learning işinde, veya modlarını kullanarak eval_download sürüme sahip MLTable'daki bu yolları işlem hedefinize bağlayabilir veya eval_mount indirebilirsiniz:
from azure.ai.ml import MLClient, command, Input
from azure.ai.ml.entities import Environment
from azure.identity import DefaultAzureCredential
from azure.ai.ml.constants import InputOutputModes
# connect to the AzureML workspace
ml_client = MLClient.from_config(
DefaultAzureCredential()
)
# Get the 20230115 version of the data
data_asset = ml_client.data.get(name="myimages", version="20230115")
input = {
"images": Input(type="mltable",
path=data_asset.id,
mode=InputOutputModes.EVAL_MOUNT
)
}
cmd = """
ls ${{inputs.images}}/**
"""
job = command(
command=cmd,
inputs=input,
compute="cpu-cluster",
environment="azureml://registries/azureml/environments/sklearn-1.1/versions/4"
)
ml_client.jobs.create_or_update(job)
Dekont
eval_mount ve eval_download modları MLTable için benzersizdir. Bu durumda, AzureML veri çalışma zamanı özelliği dosyayı değerlendirir MLTable ve yolları işlem hedefinde bağlar.