Azure Machine Learning veri kümelerini sürüm oluşturma ve izleme
ŞUNUN IÇIN GEÇERLIDIR: Python SDK azureml v1
Python SDK azureml v1
Bu makalede, yeniden üretilebilirlik için Azure Machine Learning veri kümelerini sürüm oluşturmayı ve izlemeyi öğreneceksiniz. Veri kümesi sürümü oluşturma, gelecekteki denemeler için veri kümesinin belirli bir sürümünü uygulayabilmeniz için verilerinizin belirli durumlarını yer işaretlerine ekler.
Azure Machine Learning kaynaklarınızı şu tipik senaryolarda sürüm olarak kullanmak isteyebilirsiniz:
- Yeniden eğitme için yeni veriler kullanılabilir olduğunda
- Farklı veri hazırlama veya özellik mühendisliği yaklaşımları uyguladığınızda
Önkoşullar
Python için Azure Machine Learning SDK'sı. Bu SDK, azureml-datasets paketini içerir
Azure Machine Learning çalışma alanı. Yeni bir çalışma alanı oluşturun veya şu kod örneğiyle var olan bir çalışma alanını alın:
import azureml.core from azureml.core import Workspace ws = Workspace.from_config()
Veri kümesi sürümlerini kaydetme ve alma
Kayıtlı bir veri kümesini denemeler arasında ve iş arkadaşlarınızla sürüm oluşturabilir, yeniden kullanabilir ve paylaşabilirsiniz. Aynı ada sahip birden çok veri kümesini kaydedebilir ve ada ve sürüm numarasına göre belirli bir sürümü alabilirsiniz.
Veri kümesi sürümünü kaydetme
Bu kod örneği, veri kümesinin titanic_ds yeni bir sürümünü kaydetmek için veri kümesinin Trueparametresini olarak ayarlarcreate_new_version. Çalışma alanında kayıtlı veri kümesi yoksa titanic_ds , kod adlı titanic_dsyeni bir veri kümesi oluşturur ve sürümünü 1 olarak ayarlar.
titanic_ds = titanic_ds.register(workspace = workspace,
name = 'titanic_ds',
description = 'titanic training data',
create_new_version = True)
Ada göre veri kümesi alma
Varsayılan olarak, Dataset sınıf get_by_name() yöntemi çalışma alanına kayıtlı veri kümesinin en son sürümünü döndürür.
Bu kod veri kümesinin titanic_ds 1. sürümünü döndürür.
from azureml.core import Dataset
# Get a dataset by name and version number
titanic_ds = Dataset.get_by_name(workspace = workspace,
name = 'titanic_ds',
version = 1)
Sürüm oluşturma en iyi uygulaması
Veri kümesi sürümü oluşturduğunuzda, çalışma alanıyla ek bir veri kopyası oluşturmazsınız. Veri kümeleri depolama hizmetinizdeki verilere başvuru olduğundan, depolama hizmetiniz tarafından yönetilen tek bir gerçek kaynağınız vardır.
Önemli
Veri kümeniz tarafından başvuruda bulunan verilerin üzerine yazılır veya silinirse, veri kümesinin belirli bir sürümüne yapılan çağrı değişikliği geri döndürmez.
Bir veri kümesinden veri yüklediğinizde, veri kümesi tarafından başvuruda bulunan geçerli veri içeriği her zaman yüklenir. Her veri kümesi sürümünün yeniden üretilebilir olduğundan emin olmak istiyorsanız, veri kümesi sürümü tarafından başvuruda bulunılan veri içeriğinin değiştirilmesini önlemenizi öneririz. Yeni veriler geldiğinde, yeni veri dosyalarını ayrı bir veri klasörüne kaydedin ve ardından bu yeni klasörden veri eklemek için yeni bir veri kümesi sürümü oluşturun.
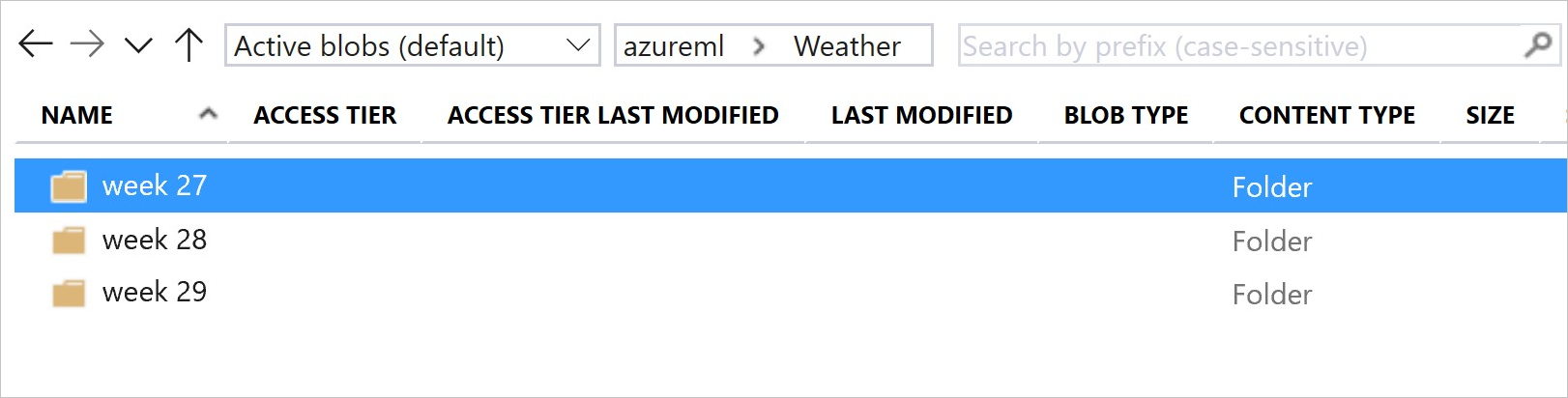
Bu görüntü ve örnek kod, hem veri klasörlerinizi yapılandırmak hem de bu klasörlere başvuran veri kümesi sürümleri oluşturmak için önerilen yolu gösterir:
from azureml.core import Dataset
# get the default datastore of the workspace
datastore = workspace.get_default_datastore()
# create & register weather_ds version 1 pointing to all files in the folder of week 27
datastore_path1 = [(datastore, 'Weather/week 27')]
dataset1 = Dataset.File.from_files(path=datastore_path1)
dataset1.register(workspace = workspace,
name = 'weather_ds',
description = 'weather data in week 27',
create_new_version = True)
# create & register weather_ds version 2 pointing to all files in the folder of week 27 and 28
datastore_path2 = [(datastore, 'Weather/week 27'), (datastore, 'Weather/week 28')]
dataset2 = Dataset.File.from_files(path = datastore_path2)
dataset2.register(workspace = workspace,
name = 'weather_ds',
description = 'weather data in week 27, 28',
create_new_version = True)
ML işlem hattı çıkış veri kümesini sürüm oluşturma
Her ML işlem hattı adımının girişi ve çıkışı olarak bir veri kümesi kullanabilirsiniz. İşlem hatlarını yeniden çalıştırdığınızda, her işlem hattı adımının çıkışı yeni bir veri kümesi sürümü olarak kaydedilir.
Machine Learning işlem hatları, işlem hattı her yeniden çalıştığında her adımın çıkışını yeni bir klasöre doldurur. Ardından sürümlenen çıkış veri kümeleri yeniden üretilebilir hale gelir. Daha fazla bilgi için işlem hatlarındaki veri kümelerini ziyaret edin.
from azureml.core import Dataset
from azureml.pipeline.steps import PythonScriptStep
from azureml.pipeline.core import Pipeline, PipelineData
from azureml.core. runconfig import CondaDependencies, RunConfiguration
# get input dataset
input_ds = Dataset.get_by_name(workspace, 'weather_ds')
# register pipeline output as dataset
output_ds = PipelineData('prepared_weather_ds', datastore=datastore).as_dataset()
output_ds = output_ds.register(name='prepared_weather_ds', create_new_version=True)
conda = CondaDependencies.create(
pip_packages=['azureml-defaults', 'azureml-dataprep[fuse,pandas]'],
pin_sdk_version=False)
run_config = RunConfiguration()
run_config.environment.docker.enabled = True
run_config.environment.python.conda_dependencies = conda
# configure pipeline step to use dataset as the input and output
prep_step = PythonScriptStep(script_name="prepare.py",
inputs=[input_ds.as_named_input('weather_ds')],
outputs=[output_ds],
runconfig=run_config,
compute_target=compute_target,
source_directory=project_folder)
Denemelerinizdeki verileri izleme
Azure Machine Learning, denemeniz boyunca verilerinizi giriş ve çıkış veri kümeleri olarak izler. Bu senaryolarda verileriniz giriş veri kümesi olarak izlenir:
Deneme işini gönderirken nesnenizin
ScriptRunConfigveyaargumentsparametresi aracılığıylainputsnesneDatasetConsumptionConfigolarakBetiğiniz belirli yöntemleri (
get_by_name()örneğin, veyaget_by_id()) çağırdığında. Veri kümesini çalışma alanına kaydettiğiniz sırada veri kümesine atanan ad, görüntülenen addır
Bu senaryolarda verileriniz çıkış veri kümesi olarak izlenir:
Deneme
OutputFileDatasetConfigişi gönderirken bir nesneyi veyaargumentsparametresinden geçirinoutputs.OutputFileDatasetConfignesneleri de işlem hattı adımları arasında veri kalıcı olabilir. Daha fazla bilgi için ML işlem hattı adımları arasında veri taşıma adresini ziyaret edinBetiğinize bir veri kümesi kaydedin. Çalışma alanına kaydettiğinizde veri kümesine atanan ad, görüntülenen addır. Bu kod örneğinde
training_dsgörüntülenen ad:training_ds = unregistered_ds.register(workspace = workspace, name = 'training_ds', description = 'training data' )Betikte kayıtlı olmayan bir veri kümesine sahip bir alt işin gönderilmesi. Bu gönderim anonim kaydedilmiş bir veri kümesine neden olur
Deneme işlerinde veri kümelerini izleme
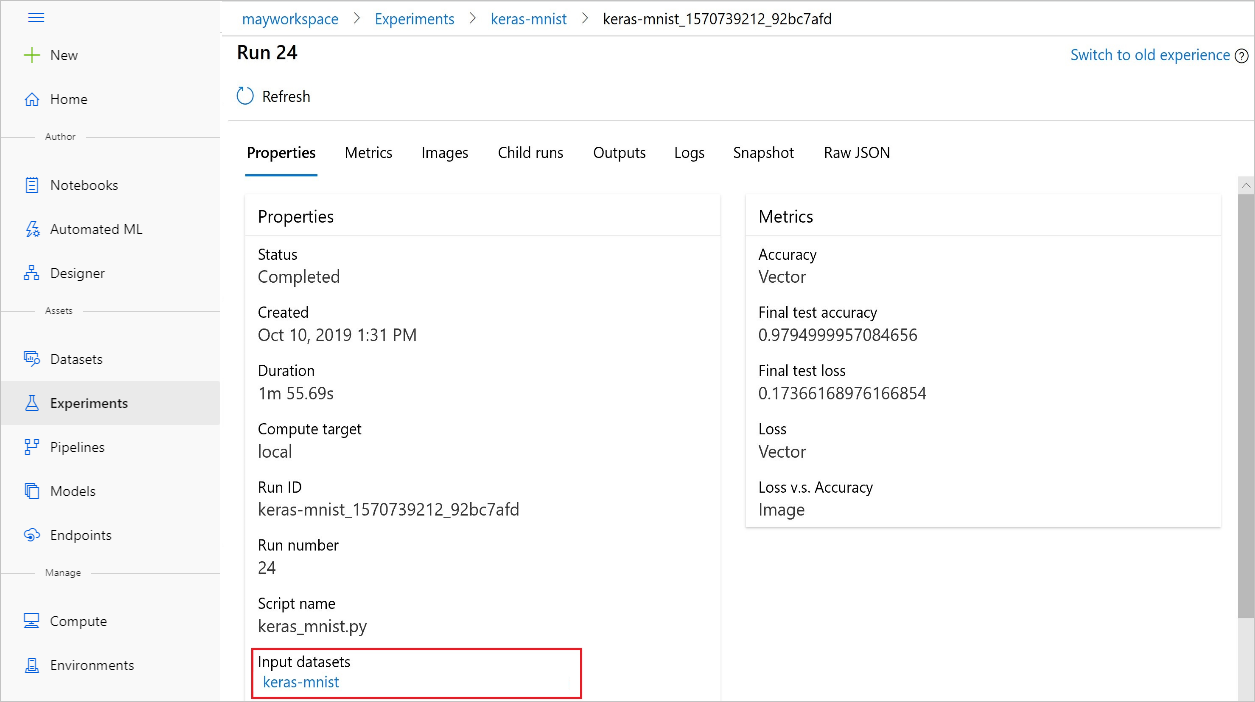
Her Machine Learning denemesi için deneme nesnesi için Job giriş veri kümelerini izleyebilirsiniz. Bu kod örneği, deneme çalıştırmasıyla get_details() kullanılan giriş veri kümelerini izlemek için yöntemini kullanır:
# get input datasets
inputs = run.get_details()['inputDatasets']
input_dataset = inputs[0]['dataset']
# list the files referenced by input_dataset
input_dataset.to_path()
Ayrıca, Azure Machine Learning stüdyosu ile denemelerden öğesini de bulabilirsinizinput_datasets.
Bu ekran görüntüsünde, Azure Machine Learning stüdyosu bir denemenin giriş veri kümesinin nerede bulunacağı gösterilmektedir. Bu örnek için Denemeler bölmenizden başlayın ve denemenizin keras-mnistbelirli bir çalıştırması için Özellikler sekmesini açın.
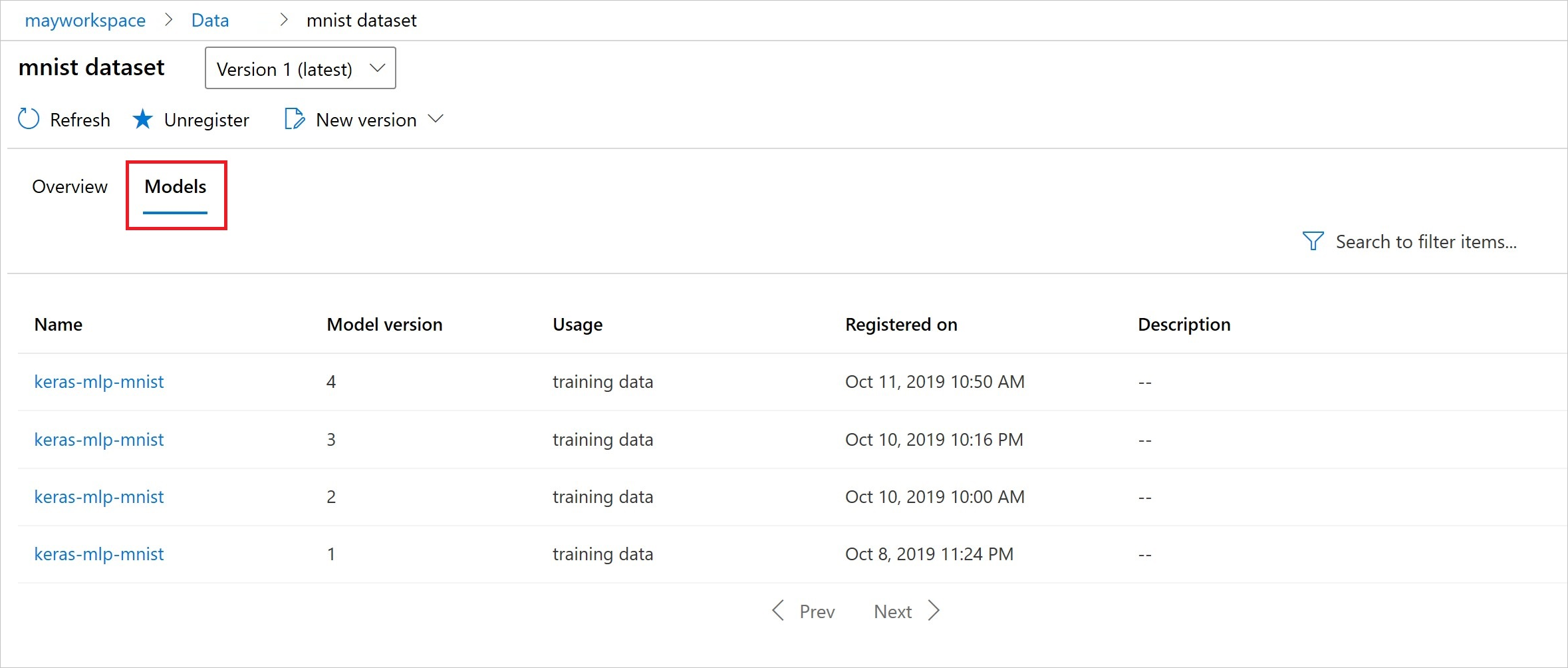
Bu kod modelleri veri kümelerine kaydeder:
model = run.register_model(model_name='keras-mlp-mnist',
model_path=model_path,
datasets =[('training data',train_dataset)])
Kayıt işleminden sonra Python veya stüdyo ile veri kümesine kayıtlı modellerin listesini görebilirsiniz.
Thia ekran görüntüsü, Varlıklar'ın altındaki Veri Kümeleri bölmesinden alınıyor. Veri kümesini seçin ve ardından veri kümesine kayıtlı modellerin listesi için Modeller sekmesini seçin.