Team Veri Bilimi Process (TDSP), tahmine dayalı analiz çözümlerini ve yapay zeka uygulamalarını verimli bir şekilde sunmak için kullanabileceğiniz çevik, yinelemeli bir veri bilimi metodolojisidir. TDSP, ekip rollerinin birlikte en iyi şekilde nasıl çalıştığını önererek ekip işbirliğini ve öğrenmeyi geliştirmeye yardımcı olur. TDSP, ekibinizin veri bilimi girişimlerini başarıyla uygulamasına ve analiz programınızın avantajlarını tam olarak hayata geçirmesine yardımcı olmak için Microsoft'un ve diğer sektör liderlerinin en iyi uygulamalarını ve yapılarını içerir.
Bu makalede TDSP'ye ve ana bileşenlerine genel bir bakış sağlanmaktadır. Microsoft araçlarını ve altyapısını kullanarak TDSP'yi uygulama hakkında rehberlik sunar. Makale boyunca daha ayrıntılı kaynaklar bulabilirsiniz.
TDSP'nin önemli bileşenleri
TDSP aşağıdaki temel bileşenlere sahiptir:
- Veri bilimi yaşam döngüsü tanımı
- Standartlaştırılmış proje yapısı
- Veri bilimi projeleri için önerilen altyapı ve kaynaklar
- Proje yürütme için önerilen araçlar ve yardımcı programlar
Veri bilimi yaşam döngüsü
TDSP, veri bilimi projelerinizin geliştirilmesini yapılandırmak için kullanabileceğiniz bir yaşam döngüsü sağlar. Yaşam döngüsü, başarılı projelerin izlediği tüm adımları özetler.
Görev tabanlı TDSP'yi veri madenciliği için endüstriler arası standart süreç (CRISP-DM), veritabanlarında bilgi bulma (KDD) işlemi veya başka bir özel işlem gibi diğer veri bilimi yaşam döngüleriyle birleştirebilirsiniz. Yüksek düzeyde, bu farklı metodolojilerin çok ortak bir yanı vardır.
Akıllı bir uygulamanın parçası olan bir veri bilimi projeniz varsa bu yaşam döngüsünü kullanmanız gerekir. Akıllı uygulamalar, tahmine dayalı analiz için makine öğrenmesi veya yapay zeka modelleri dağıtır. Bu süreci keşif veri bilimi projeleri ve doğaçlama analiz projeleri için de kullanabilirsiniz.
TDSP yaşam döngüsü, ekibinizin yinelemeli olarak gerçekleştirdiği beş ana aşamadan oluşur. Bu aşamalar şunlardır:
TDSP yaşam döngüsünün görsel bir gösterimi aşağıdadır:
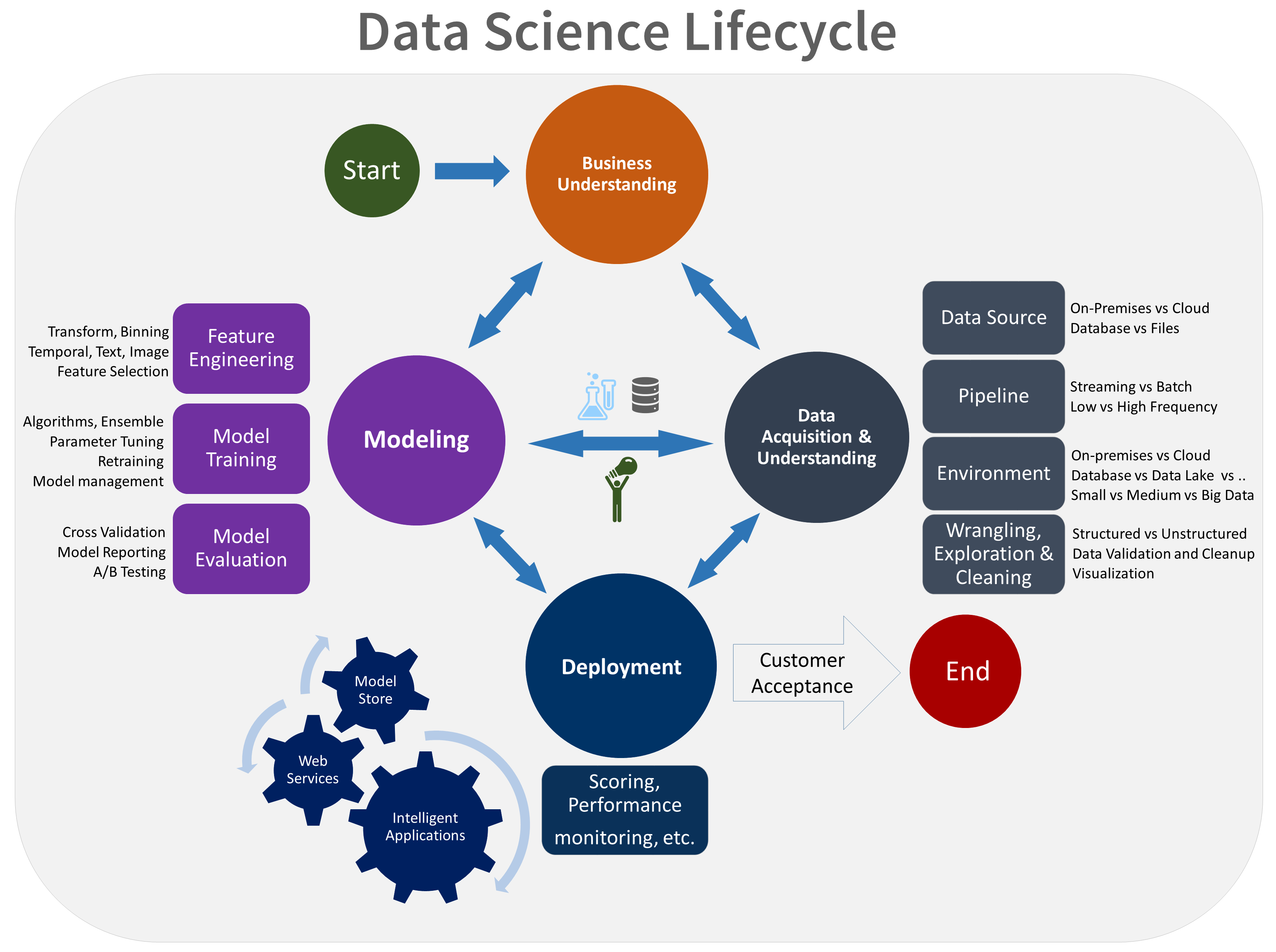
Her aşamanın hedefleri, görevleri ve belge yapıtları hakkında bilgi için bkz. Takım Veri Bilimi Süreci yaşam döngüsü.
Bu görevler ve yapıtlar proje rolleriyle ilişkilendirilir, örneğin:
- Çözüm mimarı.
- Proje yöneticisi.
- Veri mühendisi.
- Veri uzmanı.
- Uygulama geliştirici.
- Proje lideri.
Aşağıdaki diyagramda, bu roller (dikey eksende) için yaşam döngüsünün her aşamasıyla (yatay eksende) ilişkili görevler (mavi) ve yapıtlar (yeşil) gösterilmektedir.

Standartlaştırılmış proje yapısı
Ekibiniz veri bilimi varlıklarınızı düzenlemek için Azure altyapısını kullanabilir.
Azure Machine Learning açık kaynak MLflow'unu destekler. Veri bilimi ve yapay zeka proje yönetimi için MLflow kullanmanızı öneririz. MLflow, makine öğrenmesi yaşam döngüsünün tamamını yönetmek için tasarlanmıştır. Modelleri farklı platformlarda eğitip sunar, böylece denemelerinizin nerede çalıştığına bakılmaksızın tutarlı bir araç kümesi kullanabilirsiniz. MLflow'ı bilgisayarınızda, uzak işlem hedefinde, sanal makinede veya Machine Learning işlem örneğinde yerel olarak kullanabilirsiniz.
MLflow birkaç temel işlevden oluşur:
Denemeleri izleme: MLflow ile parametreler, kod sürümleri, ölçümler ve çıkış dosyaları gibi denemeleri izleyebilirsiniz. Bu özellik farklı çalıştırmaları karşılaştırmanıza ve deneme sürecini verimli bir şekilde yönetmenize yardımcı olur.
Paket kodu: Bağımlılıkları ve yapılandırmaları içeren makine öğrenmesi kodunu paketlemek için standartlaştırılmış bir biçim sunar. Bu paketleme, çalıştırmaları yeniden üretmeyi ve kodu başkalarıyla paylaşmayı kolaylaştırır.
Modelleri yönetme: MLflow, modelleri yönetmeye ve sürüm oluşturmaya yönelik işlevler sağlar. Modelleri depolayabileceğiniz, sürümleyebileceğiniz ve sunabileceğiniz çeşitli makine öğrenmesi çerçevelerini destekler.
Modelleri sunma ve dağıtma: MLflow, modelleri farklı ortamlarda kolayca dağıtabilmeniz için model sunma ve dağıtım özelliklerini tümleştirir.
Modelleri kaydetme: Sürüm oluşturma, aşama geçişleri ve ek açıklamalar dahil olmak üzere bir modelin yaşam döngüsünü yönetebilirsiniz. MLflow, işbirliğine dayalı bir ortamda merkezi bir model deposu korumak için kullanışlıdır.
API ve kullanıcı arabirimi kullanma: Azure'da MLflow, Makine Öğrenmesi API'sinin 2. sürümünde paketlenmiştir, böylece sistemle program aracılığıyla etkileşim kurabilirsiniz. Bir kullanıcı arabirimiyle etkileşime geçmek için Azure portalını kullanabilirsiniz.
MLflow, denemeden dağıtıma kadar makine öğrenmesi geliştirme sürecini basitleştirmeyi ve standartlaştırmayı amaçlar.
Machine Learning Git depolarıyla tümleştirilip Git ile uyumlu hizmetleri kullanabilirsiniz: GitHub, GitLab, Bitbucket, Azure DevOps veya git uyumlu başka bir hizmet. Ekibiniz Machine Learning'de zaten izlenen varlıklara ek olarak Git uyumlu hizmetlerinde kendi taksonomisini geliştirerek aşağıdakiler gibi diğer proje bilgilerini depolayabilir:
- Belge
- Project, örneğin son proje raporu
- Veri raporu, örneğin veri sözlüğü veya veri kalitesi raporları
- Model, örneğin model raporları
- Kod
- Veri hazırlama
- Model geliştirme
- Güvenlik ve uyumluluk dahil olmak üzere kullanıma hazır hale getirme
Altyapı ve kaynaklar
TDSP, paylaşılan analiz ve depolama altyapısını yönetmek için aşağıdakiler gibi öneriler sağlar:
- Veri kümelerini depolamak için bulut dosya sistemleri
- Veritabanları
- Sql veya Spark gibi büyük veri kümeleri
- Makine öğrenmesi hizmetleri
Ham ve işlenmiş veri kümelerinin depolandığı analiz ve depolama altyapısını buluta veya şirket içine yerleştirebilirsiniz. Bu altyapı, yeniden üretilebilir analize olanak tanır. Ayrıca, tutarsızlıklara ve gereksiz altyapı maliyetlerine yol açabilecek yinelenenleri önler. Altyapı, paylaşılan kaynakları sağlamaya, bunları izlemeye ve her ekip üyesinin bu kaynaklara güvenli bir şekilde bağlanmasına izin veren araçlara sahiptir. Proje üyelerinin tutarlı bir işlem ortamı oluşturması da iyi bir uygulamadır. Daha sonra çeşitli ekip üyeleri denemeleri çoğaltabilir ve doğrulayabilir.
Birden çok proje üzerinde çalışan ve çeşitli bulut analizi altyapısı bileşenlerini paylaşan bir ekip örneği aşağıda verilmiştir:

Araçlar ve Yardımcı Programlar
Çoğu kuruluşta süreçleri tanıtmak zordur. Altyapı, TDSP'yi uygulamaya yönelik araçlar sağlar ve yaşam döngüsü engelleri azaltmaya ve benimseme tutarlılığını artırmaya yardımcı olur.
Machine Learning ile veri bilimcileri, veri bilimi işlem hattının veya iş akışının bir parçası olarak açık kaynak araçları uygulayabilir. Machine Learning'de Microsoft, Microsoft'un Sorumlu Yapay Zeka Standardına ulaşmanıza yardımcı olan sorumlu yapay zeka araçlarını tanıtıyor.
Eşler tarafından gözden geçirilmiş alıntılar
TDSP, Microsoft görevlendirmelerinde kullanılan iyi kurulmuş bir metodolojidir ve bu nedenle hakemli literatürde belgelenmiştir ve incelenmiştir. Bu alıntılar, TDSP özelliklerini ve uygulamalarını araştırma fırsatı sağlar. Alıntıların listesi için yaşam döngüsüne genel bakış sayfasına bakın.