AutoML ve Python ile regresyon modeli eğitme (SDK v1)
ŞUNUN IÇIN GEÇERLIDIR: Python SDK azureml v1
Python SDK azureml v1
Bu makalede, Azure Machine Learning otomatik ML kullanarak Azure Machine Learning Python SDK'sı ile regresyon modelini eğitmeyi öğreneceksiniz. Bu regresyon modeli NYC taksi ücretlerini tahmin eder.
Bu işlem eğitim verilerini ve yapılandırma ayarlarını kabul eder ve en iyi modele ulaşmak için farklı özellik normalleştirme/standartlaştırma yöntemlerinin, modellerinin ve hiper parametre ayarlarının birleşimleri aracılığıyla otomatik olarak yinelenir.
Bu makaledeki Python SDK'sını kullanarak kod yazarsınız. Aşağıdaki görevleri öğrenirsiniz:
- Azure Açık Veri Kümelerini kullanarak verileri indirme, dönüştürme ve temizleme
- Otomatik makine öğrenmesi regresyon modelini eğitme
- Model doğruluğunu hesaplama
Kod içermeyen AutoML için aşağıdaki öğreticileri deneyin:
Önkoşullar
Azure aboneliğiniz yoksa başlamadan önce ücretsiz bir hesap oluşturun. Azure Machine Learning'in ücretsiz veya ücretli sürümünü bugün deneyin.
- Hızlı Başlangıcı tamamlayın: Azure Machine Learning çalışma alanınız veya işlem örneğiniz yoksa Azure Machine Learning'i kullanmaya başlayın.
- Hızlı başlangıcı tamamladıktan sonra:
- Stüdyoda Not Defterleri'ni seçin.
- Örnekler sekmesini seçin.
- SDK v1/tutorials/regression-automl-nyc-taxi-data/regression-automated-ml.ipynb not defterini açın.
- Öğreticideki her hücreyi çalıştırmak için Bu not defterini kopyala'yı seçin
Bu makaleyi kendi yerel ortamınızda çalıştırmak istiyorsanız GitHub'da da bulabilirsiniz. Gerekli paketleri almak için
- tam
automlistemcisini yükleyin. - Gerekli paketleri almak için komutunu çalıştırın
pip install azureml-opendatasets azureml-widgets.
Verileri indirme ve hazırlama
Gerekli paketleri içeri aktarın. Açık Veri Kümeleri paketi, indirmeden önce tarih parametrelerini kolayca filtrelemek için her veri kaynağını (NycTlcGreen örneğin) temsil eden bir sınıf içerir.
from azureml.opendatasets import NycTlcGreen
import pandas as pd
from datetime import datetime
from dateutil.relativedelta import relativedelta
Taksi verilerini tutmak için bir veri çerçevesi oluşturarak başlayın. Spark olmayan bir ortamda çalışırken, Açık Veri Kümeleri büyük veri kümeleriyle karşılaşmamak MemoryError için belirli sınıflarla aynı anda yalnızca bir aylık verilerin indirilmesine izin verir.
Taksi verilerini indirmek için, yinelemeli olarak her seferinde bir ay getirin ve veri çerçevesini şişirmekten kaçınmak için green_taxi_df her aydaki 2.000 kaydı rastgele örneklemeye eklemeden önce. Ardından verilerin önizlemesini yapın.
green_taxi_df = pd.DataFrame([])
start = datetime.strptime("1/1/2015","%m/%d/%Y")
end = datetime.strptime("1/31/2015","%m/%d/%Y")
for sample_month in range(12):
temp_df_green = NycTlcGreen(start + relativedelta(months=sample_month), end + relativedelta(months=sample_month)) \
.to_pandas_dataframe()
green_taxi_df = green_taxi_df.append(temp_df_green.sample(2000))
green_taxi_df.head(10)
| Vendorıd | lpepPickupDatetime | lpepDropoffDatetime | passengerCount | tripDistance | puLocationId | doLocationId | pickupLongitude | pickupLatitude | dropoffLongitude | ... | paymentType | fareAmount | Ekstra | mtaTax | improvementSurcharge | tipAmount | tollsAmount | ehailFee | totalAmount | tripType |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 131969 | 2 | 2015-01-11 05:34:44 | 2015-01-11 05:45:03 | 3 | 4,84 | Hiçbiri | Hiçbiri | -73.88 | 40.84 | -73.94 | ... | 2 | 15.00 | 0.50 | 0.50 | 0.3 | 0,00 | 0,00 | Nan | 16.30 |
| 1129817 | 2 | 2015-01-20 16:26:29 | 2015-01-20 16:30:26 | 1 | 0.69 | Hiçbiri | Hiçbiri | -73.96 | 40.81 | -73.96 | ... | 2 | 4,50 | 1.00 | 0,50 | 0.3 | 0,00 | 0,00 | Nan | 6.30 |
| 1278620 | 2 | 2015-01-01 05:58:10 | 2015-01-01 06:00:55 | 1 | 0,45 | Hiçbiri | Hiçbiri | -73.92 | 40.76 | -73.91 | ... | 2 | 4,00 | Kategori 0.00 | 0,50 | 0.3 | 0,00 | 0,00 | Nan | 4.80 |
| 348430 | 2 | 2015-01-17 02:20:50 | 2015-01-17 02:41:38 | 1 | Kategori 0.00 | Hiçbiri | Hiçbiri | -73.81 | 40.70 | -73.82 | ... | 2 | 12.50 | 0.50 | 0.50 | 0.3 | 0,00 | 0,00 | Nan | 13.80 |
| 1269627 | 1 | 2015-01-01 05:04:10 | 2015-01-01 05:06:23 | 1 | 0,50 | Hiçbiri | Hiçbiri | -73.92 | 40.76 | -73.92 | ... | 2 | 4,00 | 0.50 | 0.50 | 0 | 0,00 | 0,00 | Nan | 5.00 |
| 811755 | 1 | 2015-01-04 19:57:51 | 2015-01-04 20:05:45 | 2 | 1.10 | Hiçbiri | Hiçbiri | -73.96 | 40.72 | -73.95 | ... | 2 | 6.50 | 0.50 | 0.50 | 0.3 | 0,00 | 0,00 | Nan | 7.80 |
| 737281 | 1 | 2015-01-03 12:27:31 | 2015-01-03 12:33:52 | 1 | 0.90 | Hiçbiri | Hiçbiri | -73.88 | 40.76 | -73.87 | ... | 2 | 6,00 | 0,00 | 0,50 | 0.3 | 0,00 | 0,00 | Nan | 6.80 |
| 113951 | 1 | 2015-01-09 23:25:51 | 2015-01-09 23:39:52 | 1 | 3.30 | Hiçbiri | Hiçbiri | -73.96 | 40.72 | -73.91 | ... | 2 | 12.50 | 0.50 | 0.50 | 0.3 | 0,00 | 0,00 | Nan | 13.80 |
| 150436 | 2 | 2015-01-11 17:15:14 | 2015-01-11 17:22:57 | 1 | 1.19 | Hiçbiri | Hiçbiri | -73.94 | 40.71 | -73.95 | ... | 1 | 7.00 | 0,00 | 0,50 | 0.3 | 1,75 | Kategori 0.00 | Nan | 9.55 |
| 432136 | 2 | 2015-01-22 23:16:33 2015-01-22 23:20:13 1 0.65 | Hiçbiri | Hiçbiri | -73.94 | 40.71 | -73.94 | ... | 2 | 5.00 | 0.50 | 0.50 | 0.3 | 0,00 | 0,00 | Nan | 6.30 |
Eğitim veya diğer özellik oluşturma için ihtiyacınız olmayan bazı sütunları kaldırın. Makine öğrenmesini otomatikleştirme, lpepPickupDatetime gibi zamana bağlı özellikleri otomatik olarak işler.
columns_to_remove = ["lpepDropoffDatetime", "puLocationId", "doLocationId", "extra", "mtaTax",
"improvementSurcharge", "tollsAmount", "ehailFee", "tripType", "rateCodeID",
"storeAndFwdFlag", "paymentType", "fareAmount", "tipAmount"
]
for col in columns_to_remove:
green_taxi_df.pop(col)
green_taxi_df.head(5)
Verileri temizleme
describe() Her alanın özet istatistiklerini görmek için işlevi yeni veri çerçevesinde çalıştırın.
green_taxi_df.describe()
| Vendorıd | passengerCount | tripDistance | pickupLongitude | pickupLatitude | dropoffLongitude | dropoffLatitude | totalAmount | month_num day_of_month | day_of_week | hour_of_day |
|---|---|---|---|---|---|---|---|---|---|---|
| count | 48000.00 | 48000.00 | 48000.00 | 48000.00 | 48000.00 | 48000.00 | 48000.00 | 48000.00 | 48000.00 | 48000.00 |
| mean | 1.78 | 1.37 | 2.87 | -73.83 | 40.69 | -73.84 | 40.70 | 14.75 | 6.50 | 15.13 |
| std | 0.41 | 1.04 | 2.93 | 2.76 | 1.52 | 2.61 | 1.44 | 12.08 | 3.45 | 8.45 |
| min | 1,00 | 0,00 | 0,00 | -74.66 | Kategori 0.00 | -74.66 | Kategori 0.00 | -300,00 | 1,00 | 1,00 |
| %25 | 2.00 | 1.00 | 1.06 | -73.96 | 40.70 | -73.97 | 40.70 | 7.80 | 3.75 | 8,00 |
| %50 | 2.00 | 1.00 | 1.90 | -73.94 | 40.75 | -73.94 | 40.75 | 11.30 | 6.50 | 15.00 |
| %75 | 2.00 | 1.00 | 3.60 | -73.92 | 40.80 | -73.91 | 40.79 | 17.80 | 9.25 | 22,00 |
| max | 2.00 | 9,00 | 97.57 | Kategori 0.00 | 41.93 | Kategori 0.00 | 41.94 | 450.00 | 12,00 | 30.00 |
Özet istatistiklerinde, model doğruluğunu azaltan aykırı değerler veya değerler içeren birkaç alan olduğunu görürsünüz. Önce lat/long alanlarını Manhattan bölgesinin sınırları içinde olacak şekilde filtreleyin. Bu, diğer özelliklerle ilişkileri bakımından aykırı olan daha uzun taksi yolculuklarını veya seyahatlerini filtreler.
Ayrıca, alanı sıfırdan büyük ama 31 milden küçük olacak şekilde filtreleyin tripDistance (iki lat/uzun çift arasındaki haversine uzaklığı). Bu, tutarsız seyahat maliyeti olan uzun aykırı yolculukları ortadan kaldırır.
Son olarak, totalAmount alanın taksi ücretleri için negatif değerleri vardır ve bu değerler modelimiz bağlamında anlamlı değildir ve passengerCount alan en düşük değerleri sıfır olan hatalı verilere sahiptir.
Sorgu işlevlerini kullanarak bu anomalileri filtreleyin ve ardından eğitim için gerekli olmayan son birkaç sütunu kaldırın.
final_df = green_taxi_df.query("pickupLatitude>=40.53 and pickupLatitude<=40.88")
final_df = final_df.query("pickupLongitude>=-74.09 and pickupLongitude<=-73.72")
final_df = final_df.query("tripDistance>=0.25 and tripDistance<31")
final_df = final_df.query("passengerCount>0 and totalAmount>0")
columns_to_remove_for_training = ["pickupLongitude", "pickupLatitude", "dropoffLongitude", "dropoffLatitude"]
for col in columns_to_remove_for_training:
final_df.pop(col)
Temizlemenin beklendiği gibi çalıştığından emin olmak için verileri yeniden arayın describe() . Artık makine öğrenmesi modeli eğitimi için kullanılacak hazır ve temizlenmiş bir taksi, tatil ve hava durumu veri kümeniz var.
final_df.describe()
Çalışma alanını yapılandırma
Mevcut çalışma alanından bir çalışma alanı nesnesi oluşturun. Çalışma Alanı, Azure aboneliğinizi ve kaynak bilgilerinizi kabul eden bir sınıftır. Ayrıca model çalıştırmalarınızı izlemek ve izlemek için bir bulut kaynağı oluşturur. Workspace.from_config()config.json dosyasını okur ve kimlik doğrulama ayrıntılarını adlı wsbir nesneye yükler. ws bu makaledeki kodun geri kalanı boyunca kullanılır.
from azureml.core.workspace import Workspace
ws = Workspace.from_config()
Verileri eğitim ve test kümelerine bölme
Kitaplıktaki işlevini scikit-learn kullanarak train_test_split verileri eğitim ve test kümelerine bölün. Bu işlev, verileri model eğitimi için x (özellikler) veri kümesine ve test için y (tahmin edilmesi gereken değerler) veri kümesine ayırır.
parametresi, test_size teste ayrılacak verilerin yüzdesini belirler. random_state parametresi rastgele oluşturucuya bir tohum ayarlar, böylece eğitim testi bölmeleriniz belirleyici olur.
from sklearn.model_selection import train_test_split
x_train, x_test = train_test_split(final_df, test_size=0.2, random_state=223)
Bu adımın amacı, gerçek doğruluğu ölçmek için modeli eğitmek için kullanılmayan tamamlanmış modeli test etmek için veri noktalarına sahip olmaktır.
Başka bir deyişle, iyi eğitilmiş bir modelin daha önce görmediği verilerden doğru tahminler yapabilmesi gerekir. Artık bir makine öğrenmesi modelini otomatik olarak eğitmak için hazırlanmış verileriniz var.
Modeli otomatik olarak eğit
Modeli otomatik olarak eğitmek için aşağıdaki adımları izleyin:
- Deneme çalıştırması için ayarları tanımlayın. Eğitim verilerinizi yapılandırmaya ekleyin ve eğitim sürecini denetleyen ayarları değiştirin.
- Modeli ayarlamak için denemeyi gönderin. Denemeyi gönderdikten sonra süreç, tanımlanan kısıtlamalarınıza bağlı olarak farklı makine öğrenmesi algoritmaları ve hiper parametre ayarları aracılığıyla yinelenir. Doğruluk ölçümünü iyileştirerek en uygun modeli seçer.
Eğitim ayarlarını tanımlama
Eğitim için deneme parametresini ve model ayarlarını tanımlayın. Ayarların tam listesini görüntüleyin. Denemenin bu varsayılan ayarlarla gönderilmesi yaklaşık 5-20 dakika sürer, ancak daha kısa bir çalışma süresi istiyorsanız parametresini experiment_timeout_hours azaltın.
| Özellik | Bu makaledeki değer | Açıklama |
|---|---|---|
| iteration_timeout_minutes | 10 | Her yineleme için dakika cinsinden süre sınırı. Her yineleme için daha fazla zamana ihtiyaç duyan daha büyük veri kümeleri için bu değeri artırın. |
| experiment_timeout_hours | 0.3 | Deneme sonlandırilmeden önce tüm yinelemelerin birleştirildiği saat cinsinden maksimum süre. |
| enable_early_stopping | True | Puan kısa vadede iyileşmiyorsa erken sonlandırmayı etkinleştirmek için bayrak ekleyin. |
| primary_metric | spearman_correlation | İyileştirmek istediğiniz ölçüm. En uygun model bu ölçüme göre seçilir. |
| özellik kazandırma | auto | Deneme, otomatik kullanarak giriş verilerini önceden işleyebilir (eksik verileri işleme, metni sayısala dönüştürme vb.) |
| Ayrıntı | logging.INFO | Günlük düzeyini denetler. |
| n_cross_validations | 5 | Doğrulama verileri belirtilmediğinde gerçekleştirilecek çapraz doğrulama bölmelerinin sayısı. |
import logging
automl_settings = {
"iteration_timeout_minutes": 10,
"experiment_timeout_hours": 0.3,
"enable_early_stopping": True,
"primary_metric": 'spearman_correlation',
"featurization": 'auto',
"verbosity": logging.INFO,
"n_cross_validations": 5
}
Tanımlı eğitim ayarlarınızı bir **kwargsAutoMLConfig nesneye parametre olarak kullanın. Buna ek olarak, eğitim verilerinizi ve bu örnekteki regression modelin türünü belirtin.
from azureml.train.automl import AutoMLConfig
automl_config = AutoMLConfig(task='regression',
debug_log='automated_ml_errors.log',
training_data=x_train,
label_column_name="totalAmount",
**automl_settings)
Not
Otomatik makine öğrenmesi ön işleme adımları (özellik normalleştirme, eksik verileri işleme, metni sayısala dönüştürme vb.) temel alınan modelin bir parçası haline gelir. Modeli tahminler için kullanırken, eğitim sırasında uygulanan ön işleme adımları giriş verilerinize otomatik olarak uygulanır.
Otomatik regresyon modelini eğitme
Çalışma alanınızda bir deneme nesnesi oluşturun. Deneme, tek tek işleriniz için kapsayıcı görevi görür. Tanımlanan automl_config nesneyi denemeye geçirin ve iş sırasında ilerleme durumunu görüntülemek için True çıkışı olarak ayarlayın.
Denemeyi başlattıktan sonra, deneme çalıştırılırken gösterilen çıkış canlı olarak güncelleştirilir. Her yineleme için model türünü, çalıştırma süresini ve eğitim doğruluğunu görürsünüz. Alan BEST , ölçüm türünüz temelinde en iyi çalışan eğitim puanını izler.
from azureml.core.experiment import Experiment
experiment = Experiment(ws, "Tutorial-NYCTaxi")
local_run = experiment.submit(automl_config, show_output=True)
Running on local machine
Parent Run ID: AutoML_1766cdf7-56cf-4b28-a340-c4aeee15b12b
Current status: DatasetFeaturization. Beginning to featurize the dataset.
Current status: DatasetEvaluation. Gathering dataset statistics.
Current status: FeaturesGeneration. Generating features for the dataset.
Current status: DatasetFeaturizationCompleted. Completed featurizing the dataset.
Current status: DatasetCrossValidationSplit. Generating individually featurized CV splits.
Current status: ModelSelection. Beginning model selection.
****************************************************************************************************
ITERATION: The iteration being evaluated.
PIPELINE: A summary description of the pipeline being evaluated.
DURATION: Time taken for the current iteration.
METRIC: The result of computing score on the fitted pipeline.
BEST: The best observed score thus far.
****************************************************************************************************
ITERATION PIPELINE DURATION METRIC BEST
0 StandardScalerWrapper RandomForest 0:00:16 0.8746 0.8746
1 MinMaxScaler RandomForest 0:00:15 0.9468 0.9468
2 StandardScalerWrapper ExtremeRandomTrees 0:00:09 0.9303 0.9468
3 StandardScalerWrapper LightGBM 0:00:10 0.9424 0.9468
4 RobustScaler DecisionTree 0:00:09 0.9449 0.9468
5 StandardScalerWrapper LassoLars 0:00:09 0.9440 0.9468
6 StandardScalerWrapper LightGBM 0:00:10 0.9282 0.9468
7 StandardScalerWrapper RandomForest 0:00:12 0.8946 0.9468
8 StandardScalerWrapper LassoLars 0:00:16 0.9439 0.9468
9 MinMaxScaler ExtremeRandomTrees 0:00:35 0.9199 0.9468
10 RobustScaler ExtremeRandomTrees 0:00:19 0.9411 0.9468
11 StandardScalerWrapper ExtremeRandomTrees 0:00:13 0.9077 0.9468
12 StandardScalerWrapper LassoLars 0:00:15 0.9433 0.9468
13 MinMaxScaler ExtremeRandomTrees 0:00:14 0.9186 0.9468
14 RobustScaler RandomForest 0:00:10 0.8810 0.9468
15 StandardScalerWrapper LassoLars 0:00:55 0.9433 0.9468
16 StandardScalerWrapper ExtremeRandomTrees 0:00:13 0.9026 0.9468
17 StandardScalerWrapper RandomForest 0:00:13 0.9140 0.9468
18 VotingEnsemble 0:00:23 0.9471 0.9471
19 StackEnsemble 0:00:27 0.9463 0.9471
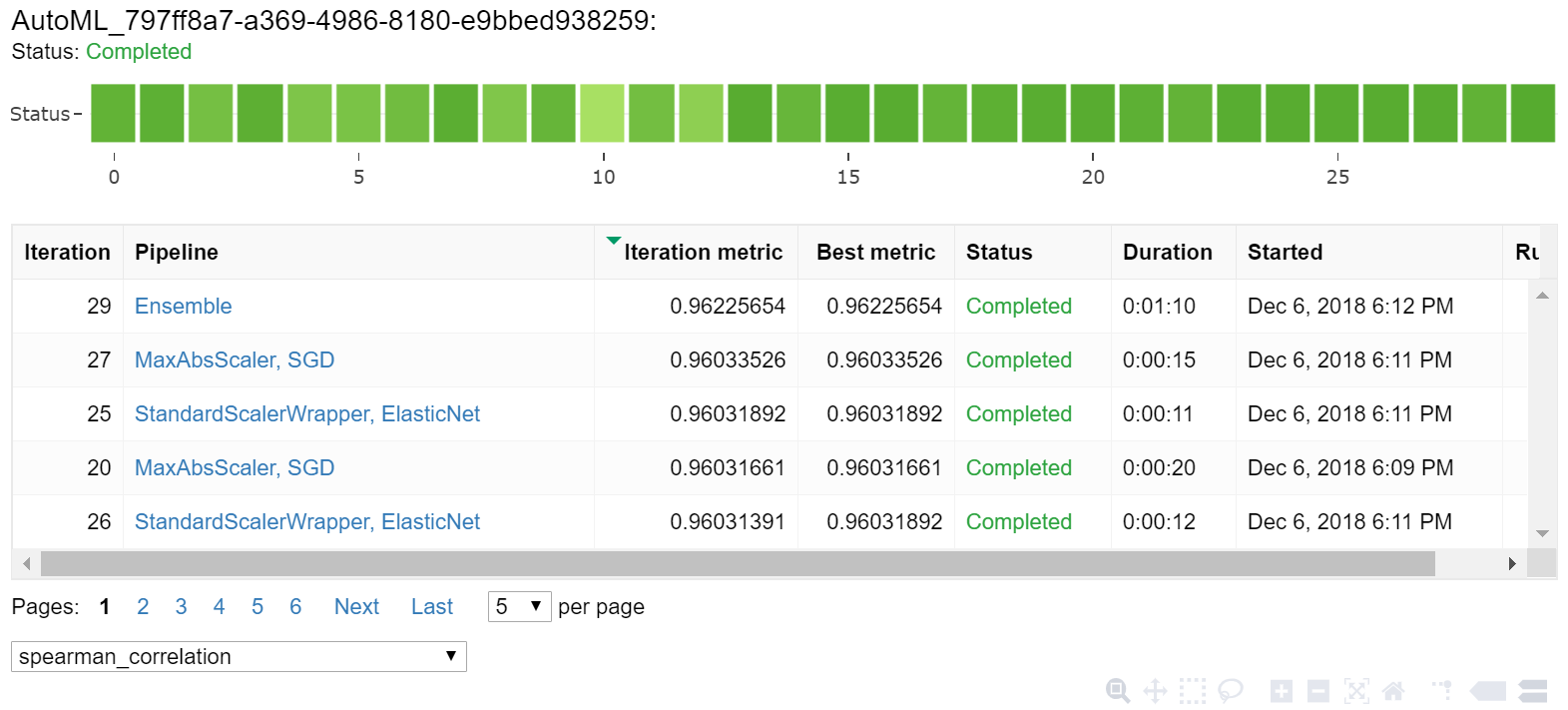
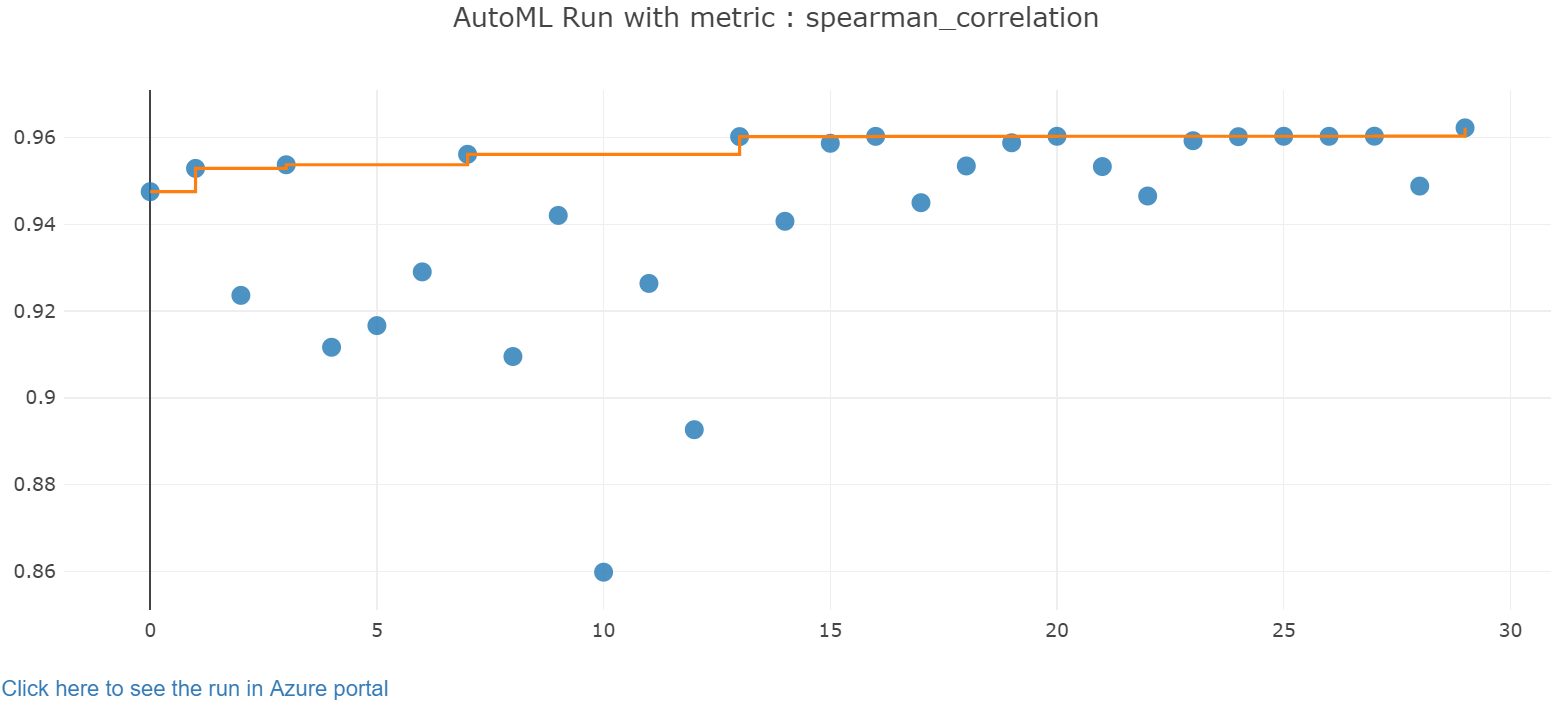
Sonuçları inceleme
Jupyter pencere öğesiyle otomatik eğitimin sonuçlarını keşfedin. Pencere öğesi, eğitim doğruluğu ölçümleri ve meta verilerinin yanı sıra tek tek tüm iş yinelemelerinin grafiğini ve tablosunu görmenize olanak tanır. Ayrıca, açılan menü seçici ile birincil ölçümden farklı doğruluk ölçümlerini filtreleyebilirsiniz.
from azureml.widgets import RunDetails
RunDetails(local_run).show()
En iyi modeli alma
Yinelemeleriniz için en iyi modeli seçin. işlevi, get_output son fit çağrısı için en iyi çalıştırmayı ve uygun modeli döndürür. üzerindeki get_outputaşırı yüklemeleri kullanarak, günlüğe kaydedilen herhangi bir ölçüm veya belirli bir yineleme için en iyi çalıştırma ve uygun modeli alabilirsiniz.
best_run, fitted_model = local_run.get_output()
print(best_run)
print(fitted_model)
En iyi model doğruluğunu test etme
Taksi ücretlerini tahmin etmek için test veri kümesinde tahmin çalıştırmak için en iyi modeli kullanın. işlevi predict en iyi modeli kullanır ve veri kümesinden x_test y(seyahat maliyeti) değerlerini tahmin eder. 'den y_predicttahmin edilen ilk 10 maliyet değerini yazdırın.
y_test = x_test.pop("totalAmount")
y_predict = fitted_model.predict(x_test)
print(y_predict[:10])
Sonuçların root mean squared error değerini hesaplayın. Tahmin edilen y_test değerlerle karşılaştırmak için veri çerçevesini listeye dönüştürün. işlevi mean_squared_error iki değer dizisi alır ve aralarındaki ortalama hata karesini hesaplar. Sonucun karekökünün alınması, y değişkeniyle (maliyet) aynı birimlerde hata verir. Taksi ücreti tahminlerinin gerçek ücretlerden ne kadar uzak olduğunu kabaca gösterir.
from sklearn.metrics import mean_squared_error
from math import sqrt
y_actual = y_test.values.flatten().tolist()
rmse = sqrt(mean_squared_error(y_actual, y_predict))
rmse
Tam y_actual ve y_predict veri kümelerini kullanarak ortalama mutlak yüzde hatasını (MAPE) hesaplamak için aşağıdaki kodu çalıştırın. Bu ölçüm, tahmin edilen ve gerçek değer arasındaki mutlak farkı hesaplar ve tüm farkları toplar. Ardından bu toplamı, gerçek değerlerin toplamının yüzdesi olarak ifade eder.
sum_actuals = sum_errors = 0
for actual_val, predict_val in zip(y_actual, y_predict):
abs_error = actual_val - predict_val
if abs_error < 0:
abs_error = abs_error * -1
sum_errors = sum_errors + abs_error
sum_actuals = sum_actuals + actual_val
mean_abs_percent_error = sum_errors / sum_actuals
print("Model MAPE:")
print(mean_abs_percent_error)
print()
print("Model Accuracy:")
print(1 - mean_abs_percent_error)
Model MAPE:
0.14353867606052823
Model Accuracy:
0.8564613239394718
İki tahmin doğruluğu ölçümünden, modelin genellikle +- 4,00 ABD doları ve yaklaşık %15 hata içinde veri kümesinin özelliklerinden taksi ücretlerini tahmin etme konusunda oldukça iyi olduğunu görürsünüz.
Geleneksel makine öğrenmesi modeli geliştirme süreci oldukça yoğun kaynak kullanır ve onlarca modelin sonuçlarını çalıştırmak ve karşılaştırmak için önemli düzeyde etki alanı bilgisi ve zaman yatırımı gerektirir. Otomatik makine öğrenmesini kullanmak, senaryonuz için birçok farklı modeli hızla test etmenin harika bir yoludur.
Kaynakları temizleme
Diğer Azure Machine Learning öğreticilerini çalıştırmayı planlıyorsanız bu bölümü tamamlamayın.
İşlem örneğini durdurma
İşlem örneği kullandıysanız, maliyeti azaltmak için vm'yi kullanmadığınızda durdurun.
Çalışma alanınızda İşlem'i seçin.
Listeden işlem örneğinin adını seçin.
Durdur'u seçin.
Sunucuyu yeniden kullanmaya hazır olduğunuzda Başlat'ı seçin.
Her şeyi sil
Oluşturduğunuz kaynakları kullanmayı planlamıyorsanız, ücret ödememek için bunları silin.
- Azure portalının en sol tarafındaki Kaynak gruplarını seçin.
- Listeden oluşturduğunuz kaynak grubunu seçin.
- Kaynak grubunu sil'i seçin.
- Kaynak grubu adını girin. Ardından Sil'i seçin.
Ayrıca kaynak grubunu koruyabilir, ancak tek bir çalışma alanını silebilirsiniz. Çalışma alanı özelliklerini görüntüleyin ve Sil'i seçin.
Sonraki adımlar
Bu otomatik makine öğrenmesi makalesinde aşağıdaki görevleri yerine getirin:
- Bir çalışma alanı yapılandırıldı ve deneme için veriler hazırlandı.
- Özel parametrelerle yerel olarak otomatik regresyon modeli kullanılarak eğitilir.
- Eğitim sonuçlarını inceledik ve gözden geçirdim.
Python ile görüntü işleme modellerini eğitmek için AutoML'yi ayarlama (v1)