Azure AI Search'te daha iyi performans için İpuçları
Bu makale, sorgu ve dizin performansını artırmaya yönelik ipuçlarından ve en iyi uygulamalardan oluşan bir koleksiyondur. Arama performansını etkileme olasılığı en yüksek olan faktörleri bilmek, verimsizlikleri önlemenize ve arama hizmetinizden en iyi şekilde yararlanabilmenize yardımcı olabilir. Bazı önemli faktörler şunlardır:
- Dizin oluşturma (şema ve boyut)
- Sorgu tasarımı
- Hizmet kapasitesi (katman ve çoğaltma ve bölüm sayısı)
Not
Yüksek hacimli dizin oluşturma stratejileri mi arıyorsunuz? Bkz. Azure AI Search'te büyük veri kümelerini dizine ekleme.
Dizin boyutu ve şema
Sorgular daha küçük dizinlerde daha hızlı çalışır. Bu, kısmen taranacak daha az alana sahip olmanın bir işlevidir, ancak bunun nedeni sistemin gelecekteki sorgular için içeriği önbelleğe alma şeklidir. İlk sorgudan sonra, bazı içerikler daha verimli bir şekilde arandığı bellekte kalır. Dizin boyutu zaman içinde büyüme eğiliminde olduğundan en iyi yöntemlerden biri, içerik azaltma fırsatlarını aramak için hem şema hem de belgeler olmak üzere dizin bileşimini düzenli aralıklarla yeniden ziyaret etmektir. Ancak, dizin doğru boyuttaysa, yapabileceğiniz diğer tek ayar kapasiteyi artırmaktır: çoğaltma ekleyerek veya hizmet katmanını yükselterek. "İpucu: Standart S2 katmanına yükseltme" bölümünde ölçeği artırma ve ölçeği genişletme kararı ele alınmaktadır.
Şema karmaşıklığı dizin oluşturmayı ve sorgu performansını da olumsuz etkileyebilir. Aşırı alan ilişkilendirmesi, sınırlamalar ve işleme gereksinimlerinde oluşturulur. Karmaşık türlerin dizine alınması ve sorguya alınması daha uzun sürer. Sonraki birkaç bölümde her koşul incelenmektedir.
İpucu: Alan ilişkilendirmesinde seçmeli olun
Yöneticilerin ve geliştiricilerin arama dizini oluştururken yaptığı yaygın bir hata, yalnızca gerekli özellikleri seçmek yerine alanlar için tüm kullanılabilir özellikleri seçmektir. Örneğin, bir alanın aranabilir tam metin olması gerekmiyorsa, aranabilir özniteliği ayarlarken bu alanı atlayın.
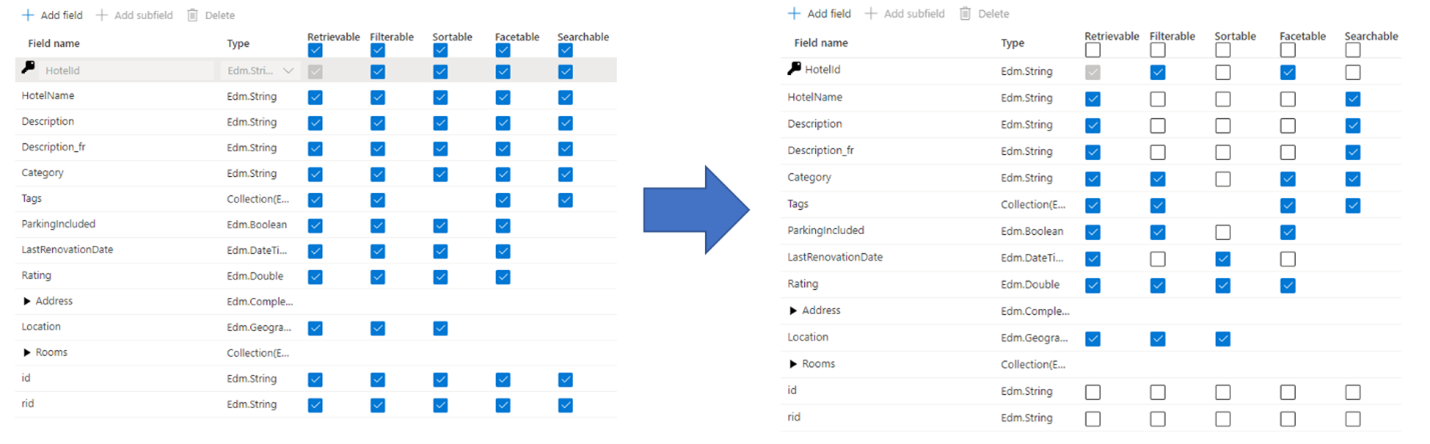
Filtreler, modeller ve sıralama desteği depolama gereksinimlerini dört katına çıkarır. Öneride bulunursanız depolama gereksinimleri daha da artar. Özniteliklerin depolama üzerindeki etkisine ilişkin bir çizim için bkz . Öznitelikler ve dizin boyutu.
Özetle, aşırı ilişkilendirmenin sonuçları şunlardır:
Alandaki içeriği işlemek ve ardından arama ters dizininde depolamak için gereken ek çalışma nedeniyle dizin oluşturma performansının düşmesi (yalnızca aranabilir içerik içeren alanlarda "aranabilir" özniteliğini ayarlayın).
Her sorguyu kapsaması gereken daha büyük bir yüzey oluşturur. Aranabilir olarak işaretlenen tüm alanlar tam metin aramasında taranır.
Ek depolama nedeniyle operasyonel maliyetleri artırır. Filtreleme ve sıralama, özgün (çözümlenmemiş) dizeleri depolamak için ek alan gerektirir. Gerekli olmayan alanlarda filtrelenebilir veya sıralanabilir ayarlamaktan kaçının.
Çoğu durumda, fazla ilişkilendirme alanın özelliklerini sınırlar. Örneğin, bir alan modellenebilir, filtrelenebilir ve aranabilirse, bir alan içinde yalnızca 16 KB metin depolayabilirsiniz, ancak aranabilir bir alan 16 MB'a kadar metin barındırabilir.
Not
Yalnızca gereksiz atıflardan kaçınılmalıdır. Filtreler ve modeller genellikle arama deneyimi için önemlidir ve filtrelerin kullanıldığı durumlarda, sonuçları sıralayabilmek için sık sık sıralama yapmanız gerekir (filtreler tek başına sıralanmamış bir kümede döner).
İpucu: Karmaşık türlerin alternatiflerini göz önünde bulundurun
Karmaşık veri türleri, JSON belgelerinde bulunan üst-alt öğeler gibi karmaşık bir iç içe yapıya sahip olduğunda yararlıdır. Karmaşık türlerin dezavantajı, karmaşık olmayan veri türlerine kıyasla içeriğin dizinini oluşturmak için gereken ek depolama gereksinimleri ve ek kaynaklardır.
Bazı durumlarda karmaşık bir veri yapısını Koleksiyon gibi daha basit bir alan türüne eşleyerek bu dengeleri ortadan kaldırabilirsiniz. Alternatif olarak, bir alan hiyerarşisini tek tek kök düzeyi alanlara düzleştirmeyi tercih edebilirsiniz.

Sorgu tasarımı
Sorgu oluşturma ve karmaşıklık, performans için en önemli faktörlerden biridir ve sorgu iyileştirme performansı önemli ölçüde iyileştirebilir. Sorguları tasarlarken aşağıdaki noktaları düşünün:
Aranabilir alan sayısı. Her ek aranabilir alan, arama hizmeti için daha fazla çalışmayla sonuçlanabilir. "searchFields" parametresini kullanarak sorgu zamanında aranmakta olan alanları sınırlayabilirsiniz. Performansı artırmak için yalnızca önemsediğiniz alanları belirtmek en iyisidir.
Döndürülen veri miktarı. Büyük miktarda içerik almak sorguları yavaşlatabilir. Sorguyu yapılandırırken, yalnızca sonuçlar sayfasını işlemek için ihtiyacınız olan alanları döndürün; kalan alanları, kullanıcı eşleşen bir değer seçtiğinde Arama API'sini kullanarak alın.
Kısmi terim aramalarının kullanımı.Ön ek araması, benzer arama ve normal ifade araması gibi kısmi terim aramaları, sonuç üretmek için tam dizin taramaları gerektirdiğinden, tipik anahtar sözcük aramalarından daha hesaplama açısından daha pahalıdır.
Model sayısı. Sorgulara model eklemek, her sorgu için toplama alınmasını gerektirir. Model için daha yüksek bir "adet" istemek de hizmetin fazladan çalışmasını gerektirir. Genel olarak, yalnızca uygulamanızda işlemeyi planladığınız modelleri ekleyin ve gerekmedikçe modeller için yüksek adet istemekten kaçının.
Yüksek atlama değerleri. Altyapı her istek için daha büyük hacimde belgeyi alıp sıraladığı için
$skipparametresini yüksek bir değere (örneğin binlere) ayarlamak arama gecikme süresini uzatır. Performans nedenleriyle, yüksek$skipdeğerlerinden kaçınmak ve bunun yerine çok sayıda belge almak için filtreleme gibi başka teknikler kullanmak en iyisidir.Yüksek kardinalite alanlarını sınırlayın. Yüksek kardinalite alanı , önemli sayıda benzersiz değere sahip olan ve sonuç olarak sonuçları hesaplarken önemli kaynaklar kullanan, değiştirilebilir veya filtrelenebilir bir alana başvurur. Örneğin, bir Ürün Kimliği veya Açıklama alanını modellenebilir ve filtrelenebilir olarak ayarlamak, belgeden belgeye değerlerin çoğu benzersiz olduğundan yüksek kardinalite olarak sayılır.
İpucu: Filtre ölçütlerini aşırı yükleme yerine arama işlevlerini kullanma
Sorgu giderek daha karmaşık olan filtre ölçütlerini kullandığından, arama sorgusunun performansı düşer. Sonuçları kullanıcı kimliğine göre kırpmak için filtrelerin kullanımını gösteren aşağıdaki örneği göz önünde bulundurun:
$filter= userid eq 123 or userid eq 234 or userid eq 345 or userid eq 456 or userid eq 567
Bu durumda, filtre ifadeleri her belgedeki tek bir alanın bir kullanıcı kimliğinin birçok olası değerinden birine eşit olup olmadığını denetlemek için kullanılır. Bu deseni büyük olasılıkla güvenlik kırpması uygulayan uygulamalarda bulabilirsiniz (sorguyu veren kullanıcıyı temsil eden asıl kimlikler listesinde bir veya daha fazla asıl kimlik içeren bir alanı denetleme).
Bu örnekte gösterildiği gibi çok sayıda değer içeren filtreleri yürütmenin daha verimli bir yolu işlevi kullanmaktırsearch.in:
search.in(userid, '123,234,345,456,567', ',')
İpucu: Yavaş tek sorgular için bölümler ekleme
Sorgu performansı genel olarak yavaşladığında, sık sık daha fazla çoğaltma eklemek sorunu çözer. Peki ya sorun tamamlanması çok uzun süren tek bir sorguysa? Bu senaryoda çoğaltmaların eklenmesi yardımcı olmaz, ancak daha fazla bölüm yardımcı olabilir. Bölüm, verileri ek bilgi işlem kaynaklarına böler. İki bölüm verileri ikiye böler, üçüncü bölüm üçüncü bölümlere böler ve bu şekilde devam eder.
Bölüm eklemenin olumlu bir yan etkisi, paralel bilgi işlem nedeniyle yavaş sorguların bazen daha hızlı performans göstermesini sağlar. Çok sayıda belgeyle eşleşen sorgular veya çok sayıda belge üzerinde sayı sağlayan modeller gibi düşük seçicilik sorgularında paralelleştirmeye dikkat ettik. Belgelerin ilgililiğini puanlama veya belge sayısını saymak için önemli bir hesaplama gerektiğinden, ek bölümler eklemek sorguların daha hızlı tamamlanmasına yardımcı olur.
Bölüm eklemek için Azure portalını, PowerShell'i, Azure CLI'yı veya bir yönetim SDK'sını kullanın.
Hizmet kapasitesi
Sorgular çok uzun sürse veya hizmet istekleri bırakmaya başladığında bir hizmet fazla yükleniyor. Böyle bir durumda, hizmeti yükselterek veya kapasite ekleyerek sorunu çözebilirsiniz.
Arama hizmetinizin katmanı ve çoğaltma/bölüm sayısı da performans üzerinde büyük bir etkiye sahiptir. Her aşamalı olarak daha yüksek katman, daha hızlı CPU'lar ve daha fazla bellek sağlar ve her ikisi de performans üzerinde olumlu bir etkiye sahiptir.
İpucu: Yeni bir yüksek kapasiteli arama hizmeti oluşturma
Oluşturulan temel ve standart hizmetler [desteklenen bölgelerde](3 Nisan 2024'ten sonra desteklenen bölgeler , bölüm başına eski hizmetlere göre daha fazla depolama alanına sahiptir. Daha yüksek bir katmana ve daha yüksek faturalanabilir bir hıza yükseltmeden önce, daha yeni bir hizmette aynı katmanın size gerekli depolama alanını verip vermediğini görmek için katman hizmet sınırlarını yeniden ziyaret edin.
İpucu: Standart S2 katmanına yükseltme
Standart S1 arama katmanı genellikle müşterilerin başladığı yerdir. S1 hizmetleri için yaygın bir desen, dizinlerin zaman içinde büyümesidir ve bu da daha fazla bölüm gerektirir. Daha fazla bölüm daha yavaş yanıt sürelerine yol açar, bu nedenle sorgu yükünü işlemek için daha fazla çoğaltma eklenir. Tahmin edebileceğiniz gibi, S1 hizmetini çalıştırmanın maliyeti artık ilk yapılandırmanın ötesindeki düzeylere kadar ilerlemiştir.
Bu noktada sormanız gereken önemli bir soru, geçerli hizmetin bölüm veya çoğaltma sayısını aşamalı olarak artırmak yerine daha yüksek bir katmana geçmenin yararlı olup olmayacağıdır.
Aşağıdaki topolojiyi, artan kapasite düzeylerini alan bir hizmet örneği olarak düşünün:
- Standart S1 katmanı
- Dizin Boyutu: 190 GB
- Bölüm Sayısı: 8 (S1'de bölüm boyutu bölüm başına 25 GB'tır)
- Çoğaltma Sayısı: 2
- Toplam Arama Birimi: 16 (8 bölüm x 2 çoğaltma)
- Varsayımsal Perakende Fiyatı: ~$4.000 USD / ay (250 ABD doları x 16 arama birimi varsay)
Hizmet yöneticisinin hala daha yüksek gecikme süresi oranları gördüğünü ve başka bir çoğaltma eklemeyi düşündiğini düşünün. Bu işlem çoğaltma sayısını 2'den 3'e değiştirir ve sonuç olarak Arama Birimi sayısı 24'e ve sonuçta aylık 6.000 ABD doları olur.
Ancak yönetici Standart S2 katmanına geçmeyi seçerse topoloji şöyle görünür:
- Standart S2 katmanı
- Dizin Boyutu: 190 GB
- Bölüm Sayısı: 2 (S2'de bölüm boyutu bölüm başına 100 GB'tır)
- Çoğaltma Sayısı: 2
- Toplam Arama Birimi: 4 (2 bölüm x 2 çoğaltma)
- Varsayımsal Perakende Fiyatı: ~$4.000 USD / ay (1.000 ABD Doları x 4 arama birimi)
Bu varsayımsal senaryonun da belirttiği gibi, daha düşük katmanlarda yapılandırmalarınız olabilir ve bu da ilk etapta daha yüksek bir katmanı tercih etmiş gibi benzer maliyetlerle sonuçlanabilir. Ancak, daha yüksek katmanlar premium depolama ile gelir ve bu da dizin oluşturmayı hızlandırır. Daha yüksek katmanların çok daha fazla işlem gücü ve ek belleğe de sahiptir. Aynı maliyetler için aynı dizini daha güçlü bir altyapıyla destekleyebilirsiniz.
Eklenen belleğin önemli avantajlarından biri, dizinin daha fazlasının önbelleğe alınabilmesi ve bunun sonucunda daha düşük arama gecikme süresi ve saniyede daha fazla sayıda sorgu olmasıdır. Bu ek güçle, yöneticinin çoğaltma sayısını artırması bile gerekmeyebilir ve S1 hizmetinde kalarak daha az ödeme yapabilir.
İpucu: Normal ifade sorgularının alternatiflerini göz önünde bulundurun
Normal ifade sorguları veya regex özellikle pahalı olabilir. Bunlar gelişmiş aramalar için çok yararlı olsa da, özellikle normal ifade karmaşıksa veya büyük miktarda veri arıyorsanız yürütme çok fazla işlem gücü gerektirebilir. Bu faktörlerin tümü yüksek arama gecikme süresine katkıda bulunur. Bir azaltma olarak, normal ifadeyi basitleştirmeye veya karmaşık sorguyu daha küçük, daha yönetilebilir sorgulara bölmeye çalışın.
Sonraki adımlar
Hizmet performansıyla ilgili diğer makaleleri gözden geçirin: