Microsoft Sentinel'de Kusto Sorgu Dili
Kusto Sorgu Dili, Microsoft Sentinel'de verilerle çalışmak ve verileri işlemek için kullanacağınız dildir. Çalışma alanınıza aktardığınız günlükler, bunları analiz edip tüm bu verilerde gizli olan önemli bilgileri alamazsanız çok değerli değildir. Kusto Sorgu Dili yalnızca bu bilgileri alma gücü ve esnekliğine değil, hızlı bir şekilde başlamanıza yardımcı olacak basitliğe de sahiptir. Betik oluşturma veya veritabanlarıyla çalışma konusunda bir arka planınız varsa, bu makalenin içeriğinin çoğu çok tanıdık gelecek. Aksi takdirde endişelenmeyin çünkü dilin sezgisel yapısı hızla kendi sorgularınızı yazmaya başlamanıza ve kuruluşunuz için değer katmaya başlamanıza olanak tanır.
Bu makalede, her gün yazacağınız sorguların yüzde 75 ile 80'ini ele alması gereken en çok kullanılan işlev ve işleçlerden bazılarını kapsayan Kusto Sorgu Dili temelleri tanıtılır. Daha fazla derinliğe ihtiyacınız olduğunda veya daha gelişmiş sorgular çalıştırmak için yeni Microsoft Sentinel için Gelişmiş KQL çalışma kitabından yararlanabilirsiniz (bu giriş blog gönderisine bakın). Ayrıca resmi Kusto Sorgu Dili belgelerine ve çeşitli çevrimiçi kurslara (Pluralsight gibi) bakın.
Arka plan - Neden Kusto Sorgu Dili?
Microsoft Sentinel, Azure İzleyici hizmetinin üzerine kurulmuştur ve tüm verilerini depolamak için Azure İzleyici'nin Log Analytics çalışma alanlarını kullanır. Bu veriler aşağıdakilerden herhangi birini içerir:
- Microsoft Sentinel veri bağlayıcıları kullanılarak dış kaynaklardan önceden tanımlanmış tablolara alınan veriler.
- özel oluşturulan veri bağlayıcılarının yanı sıra bazı kullanıma açık bağlayıcı türleri kullanılarak dış kaynaklardan kullanıcı tanımlı özel tablolara alınan veriler.
- Microsoft Sentinel tarafından oluşturulan ve oluşturduğu ve gerçekleştirdiği analizlerden (örneğin, uyarılar, olaylar ve UEBA ile ilgili bilgiler) elde edilen veriler.
- tehdit bilgileri akışları ve izleme listeleri gibi algılama ve analize yardımcı olmak için Microsoft Sentinel'e yüklenen veriler.
Kusto Sorgu Dili, Azure Veri Gezgini hizmetinin bir parçası olarak geliştirilmiştir ve bu nedenle bulut ortamındaki büyük veri depolarında arama için iyileştirilmiştir. Ünlü deniz altı gezgini Jacques Cousteau'dan (ve buna göre "koo-STOH" olarak telaffuz edilir) esinlenerek, veri okyanuslarınızın derinliklerine dalmanıza ve gizli hazinelerini keşfetmenize yardımcı olmak için tasarlanmıştır.
Kusto Sorgu Dili, Log Analytics veri depolarındaki verileri almanıza, görselleştirmenize, çözümlemenize ve ayrıştırmanıza olanak tanıyan bazı ek Azure İzleyici özellikleri de dahil olmak üzere Azure İzleyici'de (ve dolayısıyla Microsoft Sentinel'de) de kullanılır. Microsoft Sentinel'de, mevcut kurallarda ve çalışma kitaplarında veya kendi kurallarınızı oluştururken verileri görselleştirip analiz edip tehditlere karşı avlarken Kusto Sorgu Dili dayalı araçlar kullanıyorsunuz.
Kusto Sorgu Dili, Microsoft Sentinel'de yaptığınız neredeyse her şeyin bir parçası olduğundan, nasıl çalıştığını net bir şekilde anlamak, SIEM'inizden çok daha fazlasını almanıza yardımcı olur.
Sorgu nedir?
Kusto Sorgu Dili sorgusu, verileri işlemek ve sonuçları döndürmek için salt okunur bir istektir; veri yazmaz. Sorgular, SQL'e benzer şekilde bir veritabanı, tablo ve sütun hiyerarşisi halinde düzenlenmiş veriler üzerinde çalışır.
İstekler düz dilde belirtilir ve söz diziminin okunmasını, yazmasını ve otomatikleştirilmesini kolaylaştırmak için tasarlanmış bir veri akışı modeli kullanılır. Bunu ayrıntılı olarak göreceğiz.
Kusto Sorgu Dili sorgular noktalı virgülle ayrılmış deyimlerden oluşur. Birçok deyim türü vardır, ancak burada ele alacağımız yalnızca iki yaygın kullanılan tür vardır:
Tablosal ifade deyimleri, sorgulardan bahsederken genellikle neyi ifade ettiğimizdir; bunlar sorgunun gerçek gövdesidir. Tablosal ifade deyimleri hakkında bilinmesi gereken önemli şey, bir tablosal girişi (tablo veya başka bir tablosal ifade) kabul edip bir tablo çıktısı üretmeleridir. Bunlardan en az biri gereklidir. Bu makalenin geri kalanında bu tür bir açıklama ele alınacaktır.
let deyimleri , daha kolay okunabilirlik ve çok yönlülük için sorgu gövdesi dışında değişkenler ve sabitler oluşturmanıza ve tanımlamanıza olanak sağlar. Bunlar isteğe bağlıdır ve özel gereksinimlerinize bağlıdır. Makalenin sonunda bu tür bir ifadeyi ele alacağız.
Tanıtım ortamı
Azure portalındaki Log Analytics tanıtım ortamında bu makaledeki deyimler de dahil olmak üzere Kusto Sorgu Dili deyimleri uygulayabilirsiniz. Bu uygulama ortamını kullanmak için ücret alınmaz, ancak bu ortama erişmek için bir Azure hesabına ihtiyacınız vardır.
Tanıtım ortamını keşfedin. Üretim ortamınızdaki Log Analytics gibi, bu da çeşitli yollarla kullanılabilir:
Sorgu oluşturmak için bir tablo seçin. Varsayılan Tablolar sekmesinden (sol üstteki kırmızı dikdörtgende gösterilir), konulara göre gruplandırılmış tablolar listesinden bir tablo seçin (sol altta gösterilir). Tabloları tek tek görmek için konuları genişletin ve tüm alanlarını (sütunlarını) görmek için her tabloyu daha da genişletebilirsiniz. Tabloya veya alan adına çift tıklanması, tabloyu sorgu penceresinde imlecin noktasına yerleştirir. Sorgunuzun kalan kısmını aşağıda gösterildiği gibi tablo adını izleyerek yazın.
Çalışmak veya değiştirmek için var olan bir sorguyu bulun. Kullanıma hazır sorguların listesini görmek için Sorgular sekmesini (sol üstteki kırmızı dikdörtgende gösterilir) seçin. Ya da sağ üstteki düğme çubuğundan Sorgular'ı seçin. Microsoft Sentinel ile birlikte gelen sorguları kullanıma açık olarak inceleyebilirsiniz. Bir sorguya çift tıklanması, sorgu penceresinin tamamını imlecin noktasına yerleştirir.
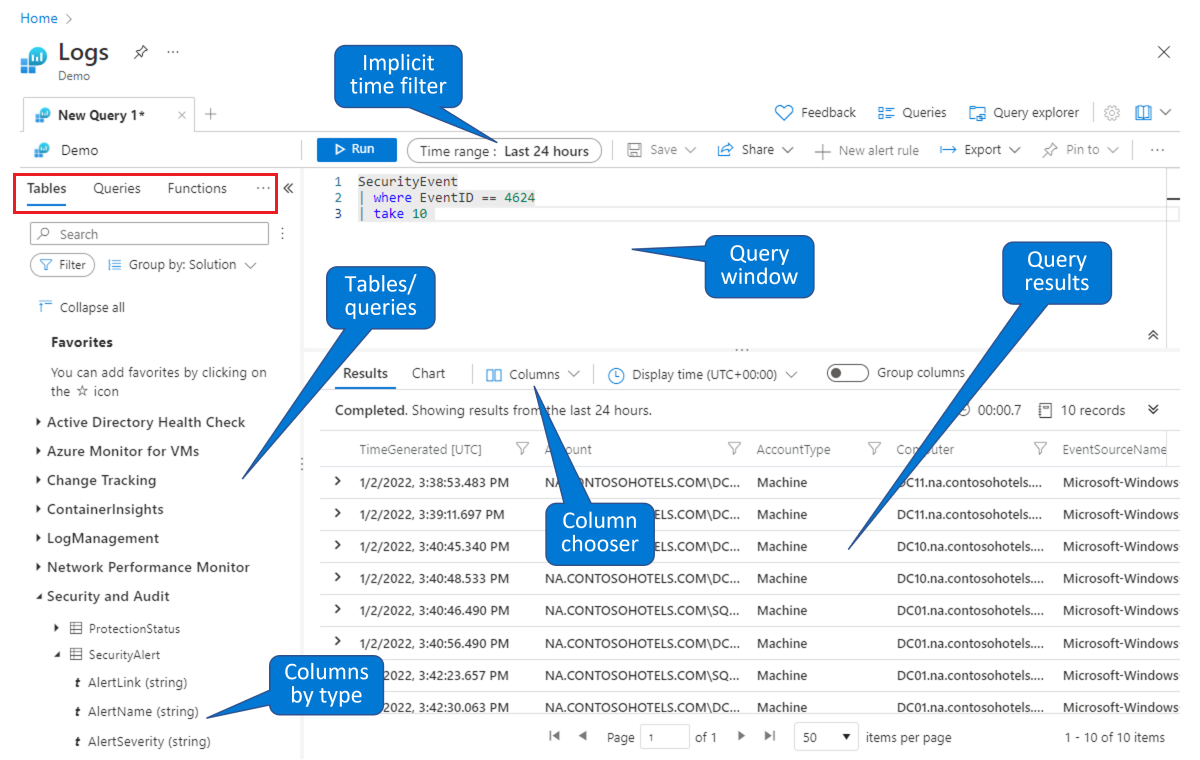
Bu tanıtım ortamında olduğu gibi, Microsoft Sentinel Günlükleri sayfasında da verileri sorgulayabilir ve filtreleyebilirsiniz. Sütunları görmek için bir tablo seçebilir ve detaya gidebilirsiniz. Sütun seçiciyi kullanarak gösterilen varsayılan sütunları değiştirebilir ve sorgular için varsayılan zaman aralığını ayarlayabilirsiniz. Zaman aralığı sorguda açıkça tanımlanmışsa, zaman filtresi kullanılamaz (gri görünür).
Sorgu yapısı
Kusto Sorgu Dili öğrenmeye başlamak için iyi bir yer, genel sorgu yapısını anlamaktır. Kusto sorgusuna baktığınızda ilk olarak boru simgesinin (| ) kullanılması fark edeceksiniz. Kusto sorgusunun yapısı, verilerinizi bir veri kaynağından almak ve ardından verileri bir "işlem hattı" üzerinden geçirmekle başlar ve her adım bir miktar işlem düzeyi sağlar ve ardından verileri bir sonraki adıma geçirir. İşlem hattının sonunda nihai sonucu elde edersiniz. Aslında bu işlem hattımızdır:
Get Data | Filter | Summarize | Sort | Select
İşlem hattından veri geçirme kavramı, her adımda verilerinizin zihinsel bir resmini oluşturmak kolay olduğundan çok sezgisel bir yapı sağlar.
Bunu göstermek için Microsoft Entra oturum açma günlüklerine bakan aşağıdaki sorguya göz atalım. Her satırı okurken, verilere neler olduğunu gösteren anahtar sözcükleri görebilirsiniz. İşlem hattına ilgili aşamayı her satıra açıklama olarak dahil ettik.
Dekont
Bir sorgudaki herhangi bir satıra açıklamaların önüne çift eğik çizgi (// ) ekleyerek açıklama ekleyebilirsiniz.
SigninLogs // Get data
| evaluate bag_unpack(LocationDetails) // Ignore this line for now; we'll come back to it at the end.
| where RiskLevelDuringSignIn == 'none' // Filter
and TimeGenerated >= ago(7d) // Filter
| summarize Count = count() by city // Summarize
| sort by Count desc // Sort
| take 5 // Select
Her adımın çıkışı aşağıdaki adımın girişi olarak görev yaptığı için, adımların sırası sorgunun sonuçlarını belirleyebilir ve performansını etkileyebilir. Adımları sorgudan çıkarmak istediğiniz adımlara göre sıralamanız çok önemlidir.
Bahşiş
- Verilerinizi erken filtrelemek iyi bir kuraldır, bu nedenle yalnızca ilgili verileri işlem hattından geçirirsiniz. Bu, performansı büyük ölçüde artırır ve özetleme adımlarına ilgisiz verileri yanlışlıkla eklemediğinizden emin olur.
- Bu makalede, göz önünde bulundurulması gereken diğer en iyi yöntemlere işaret edecektir. Daha eksiksiz bir liste için bkz . sorgu en iyi yöntemleri.
Umarım artık Kusto Sorgu Dili bir sorgunun genel yapısı için bir takdire sahipsinizdir. Şimdi sorgu oluşturmak için kullanılan gerçek sorgu işleçlerine göz atalım.
Veri türleri
Sorgu işleçlerine girmeden önce veri türlerine hızlıca göz atalım. Çoğu dilde olduğu gibi, veri türü bir değere karşı hangi hesaplamaların ve işlemelerin çalıştırılabileceğini belirler. Örneğin, dize türünde bir değeriniz varsa, buna karşı aritmetik hesaplamalar yapamazsınız.
Kusto Sorgu Dili'da, veri türlerinin çoğu standart kuralları izler ve büyük olasılıkla daha önce gördüğünüz adlara sahiptir. Aşağıdaki tabloda tam liste gösterilmektedir:
Veri türü tablosu
| Tür | Ek adlar | Eşdeğer .NET türü |
|---|---|---|
bool |
Boolean |
System.Boolean |
datetime |
Date |
System.DateTime |
dynamic |
System.Object |
|
guid |
uuid, uniqueid |
System.Guid |
int |
System.Int32 |
|
long |
System.Int64 |
|
real |
Double |
System.Double |
string |
System.String |
|
timespan |
Time |
System.TimeSpan |
decimal |
System.Data.SqlTypes.SqlDecimal |
Veri türlerinin çoğu standart olsa da dinamik, zaman aralığı ve guid gibi türleri daha az tanıyor olabilirsiniz.
Dinamik, JSON'a çok benzer bir yapıya sahiptir, ancak bir önemli fark vardır: İç içe dinamik değer veya zaman aralığı gibi geleneksel JSON'un yapamayacağı Kusto Sorgu Dili özgü veri türlerini depolayabilir. Dinamik tür örneği aşağıda verilmişti:
{
"countryOrRegion":"US",
"geoCoordinates": {
"longitude":-122.12094116210936,
"latitude":47.68050003051758
},
"state":"Washington",
"city":"Redmond"
}
Zaman aralığı saat, gün veya saniye gibi bir zaman ölçüsüne başvuran bir veri türüdür. Zaman aralığını, bir saat ölçüsü değil, gerçek bir tarih ve saat olarak değerlendirilen tarih saat ile karıştırmayın. Aşağıdaki tabloda zaman aralığı sonekleri listesi gösterilmektedir.
Zaman aralığı sonekleri
| İşlev | Tanım |
|---|---|
D |
gün |
H |
saat |
M |
sürdü |
S |
saniye |
Ms |
milisaniye |
Microsecond |
Mikrosaniye |
Tick |
Nanosaniye |
Guid , [8]-[4]-[4]-[4]-[12] standart biçimini izleyen 128 bit, genel olarak benzersiz bir tanımlayıcıyı temsil eden bir veri türüdür; burada her [sayı] karakter sayısını temsil eder ve her karakter 0-9 veya a-f arasında değişebilir.
Dekont
Kusto Sorgu Dili hem tablosal hem de skaler işleçleri vardır. Bu makalenin geri kalanında yalnızca "işleç" sözcüğünü görüyorsanız, aksi belirtilmediği sürece bunun tablosal işleç anlamına geldiğini varsayabilirsiniz.
Verileri alma, sınırlama, sıralama ve filtreleme
görevlerinizin büyük çoğunluğunu gerçekleştirmenizi sağlayacak temel Kusto Sorgu Dili temeli, verilerinizi filtreleme, sıralama ve seçmeye yönelik işleçlerden oluşan bir koleksiyondur. Yapmanız gereken kalan görevler, daha gelişmiş gereksinimlerinizi karşılamak için dil bilginizi genişletmenizi gerektirir. Yukarıdaki örneğimizde kullandığımız bazı komutları biraz genişletelim ve , sortve where'ye take bakalım.
Bu işleçlerin her biri için önceki SigninLogs örneğimizde kullanımını inceleyecek ve yararlı bir ipucu veya en iyi uygulama hakkında bilgi edineceğiz.
Veri alma
Herhangi bir temel sorgunun ilk satırı, hangi tabloyla çalışmak istediğinizi belirtir. Microsoft Sentinel söz konusu olduğunda, bu büyük olasılıkla çalışma alanınızdaki SigninLogs, SecurityAlert veya CommonSecurityLog gibi bir günlük türünün adı olacaktır. Örnek:
SigninLogs
Kusto Sorgu Dili günlük adlarının büyük/küçük harfe duyarlı olduğunu ve signinLogs farklı SigninLogs yorumlanacağına dikkat edin. Özel günlükleriniz için adları seçerken dikkatli olun; böylece kolayca tanımlanabilir ve başka bir günlüğe çok benzemeyecekler.
Verileri sınırlama: sınır alma /
Take işleci (ve aynı sınır işleci) yalnızca belirli sayıda satır döndürerek sonuçlarınızı sınırlamak için kullanılır. Ardından döndürülecek satır sayısını belirten bir tamsayı eklenir. Genellikle, sıralama düzeninizi belirledikten sonra sorgunun sonunda kullanılır ve böyle bir durumda sıralanmış düzenin en üstünde verilen satır sayısını döndürür.
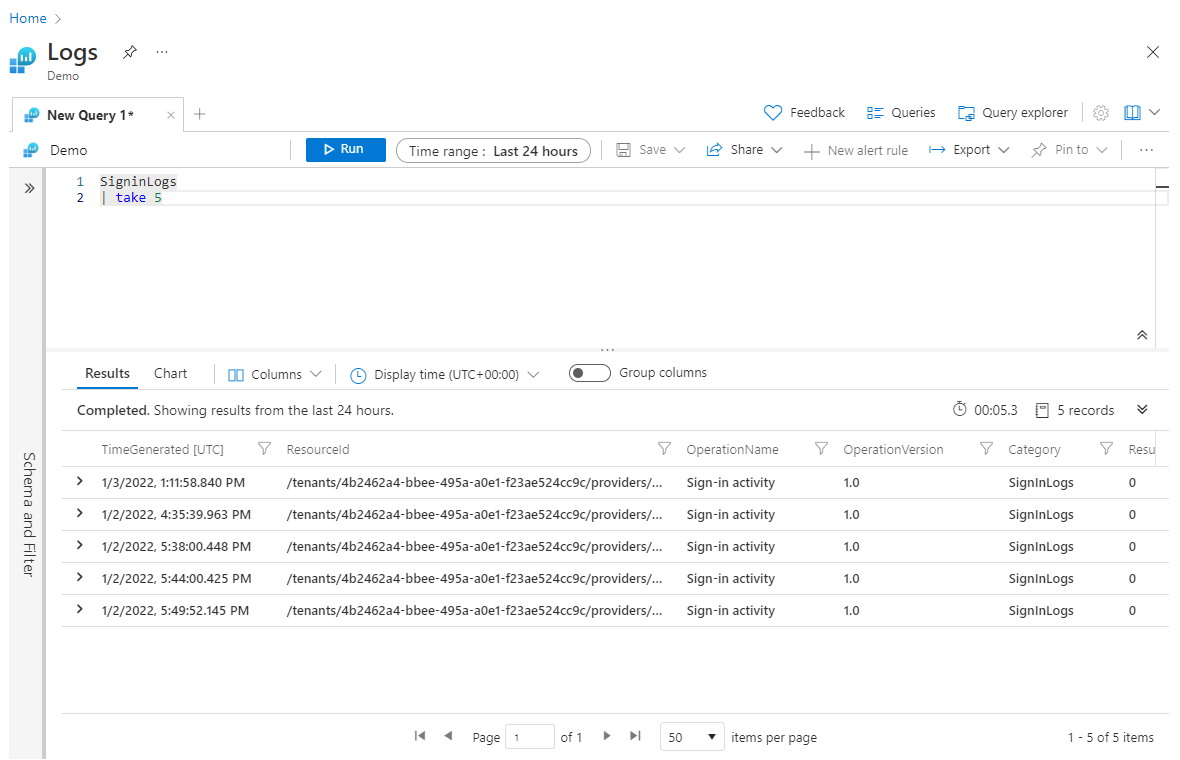
take Büyük veri kümeleri döndürmek istemediğinizde sorgunun önceki bölümlerinde kullanmak sorguyu test etmek için yararlı olabilir. Ancak, işlemi herhangi bir sort işlemden önce yerleştirirseniztake, take rastgele seçilen satırları döndürür ve sorgu her çalıştırıldığında muhtemelen farklı bir satır kümesi döndürür. Aşağıda take kullanımına bir örnek verilmişti:
SigninLogs
| take 5
Bahşiş
Sorgunun nasıl görüneceğini bilmediğiniz yepyeni bir sorgu üzerinde çalışırken, daha hızlı işleme ve deneme için veri kümenizi yapay olarak sınırlamak için en başına bir take deyim eklemek yararlı olabilir. Sorgunun tamamını tamamladıktan sonra ilk take adımı kaldırabilirsiniz.
Verileri sıralama: sıralama / düzeni
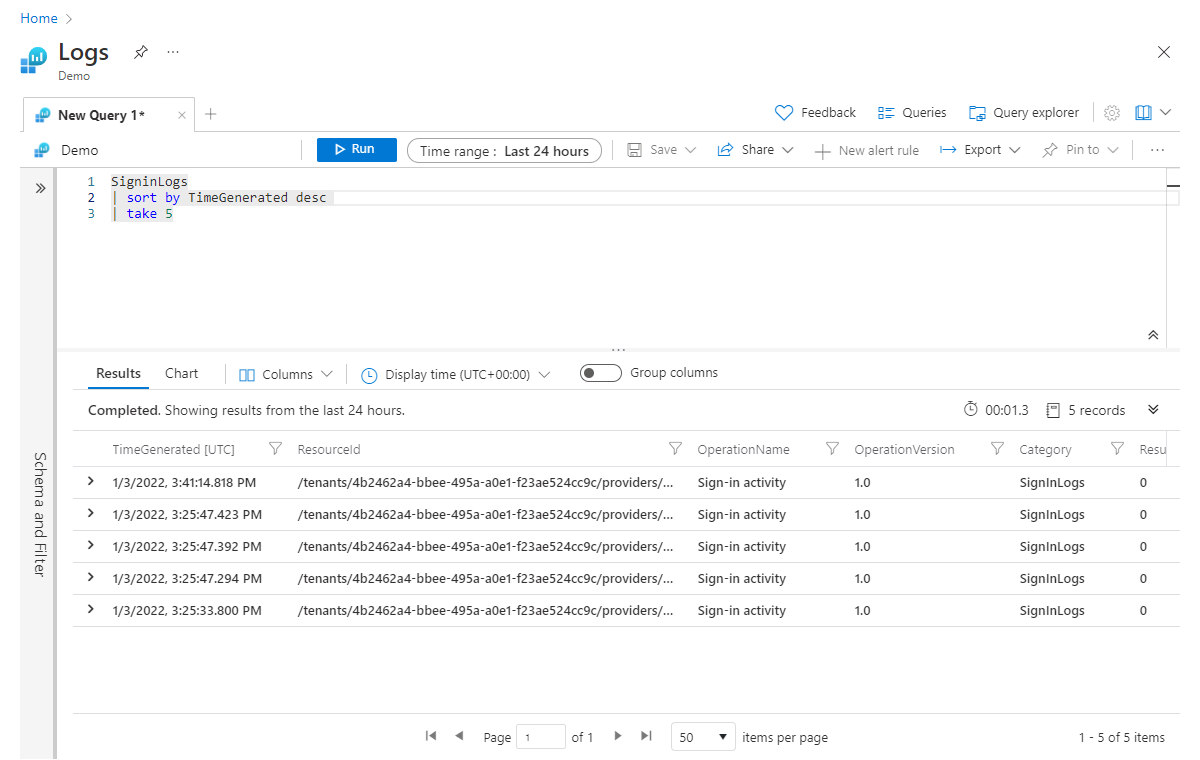
Sıralama işleci (ve aynı düzen işleci), verilerinizi belirtilen bir sütuna göre sıralamak için kullanılır. Aşağıdaki örnekte, sonuçları TimeGenerated tarafından sıraladık ve sıralama yönünü desc parametresiyle azalan olarak ayarladık ve en yüksek değerleri önce yerleştirdik; artan sırada asc kullanacağız.
Dekont
Sıralamalar için varsayılan yön azalandır, bu nedenle teknik olarak yalnızca artan düzende sıralamak isteyip istemediğinizi belirtmeniz gerekir. Ancak her durumda sıralama yönünün belirtilmesi sorgunuzun daha okunabilir olmasını sağlar.
SigninLogs
| sort by TimeGenerated desc
| take 5
Daha önce de belirttiğimiz gibi işlecini işlecin önüne koyduk sorttake . Uygun beş kaydı aldığımızdan emin olmak için önce sıralamamız gerekiyor.
Sayfanın Üstü
Top işleci, ve take işlemlerini tek bir işleçte birleştirmemize sort olanak tanır:
SigninLogs
| top 5 by TimeGenerated desc
İki veya daha fazla kaydın sıralama ölçütü olarak kullandığınız sütunda aynı değere sahip olduğu durumlarda, sıralama ölçütü olarak daha fazla sütun ekleyebilirsiniz. İlk sıralama sütunundan sonra ancak sıralama düzeni anahtar sözcüğünden önce bulunan, virgülle ayrılmış bir listeye ek sıralama sütunları ekleyin. Örnek:
SigninLogs
| sort by TimeGenerated, Identity desc
| take 5
Şimdi TimeGenerated birden çok kayıt arasında aynıysa, Kimlik sütunundaki değere göre sıralamayı dener.
Dekont
ve takene zaman kullanılır sort ve ne zaman kullanılır?top
Yalnızca bir alanda sıralamak istiyorsanız, ve
takebirleşiminden daha iyi performans sağladığındansortkullanıntop.Birden fazla alana göre sıralamanız gerekiyorsa (yukarıdaki son örnekte olduğu gibi),
topbunu yapamazsınız, bu nedenle vetakekullanmanızsortgerekir.
Verileri filtreleme: where
Where işleci muhtemelen en önemli işleçtir çünkü senaryonuzla ilgili verilerin yalnızca alt kümesiyle çalışmanızı sağlamanın anahtarıdır. Bunu yapmak, sonraki adımlarda işlenmesi gereken veri miktarını azaltarak sorgu performansını artıracağından, verilerinizi sorguda mümkün olduğunca erken filtrelemek için elinden geleni yapmalısınız; ayrıca yalnızca istenen veriler üzerinde hesaplamalar gerçekleştirmenizi sağlar. Şu örne bakın:
SigninLogs
| where TimeGenerated >= ago(7d)
| sort by TimeGenerated, Identity desc
| take 5
where işleci bir değişken, karşılaştırma (skaler) işleci ve bir değer belirtir. Bizim örneğimizde, TimeGenerated sütunundaki değerin yedi günden büyük (yani, daha sonra) veya yedi gün öncesine eşit olması gerektiğini belirtirdik>=.
Kusto Sorgu Dili iki tür karşılaştırma işleci vardır: dize ve sayısal. Aşağıdaki tabloda sayısal işleçlerin tam listesi gösterilmektedir:
Sayısal işleçler
| Operator | Tanım |
|---|---|
+ |
Ekleme |
- |
Çıkarma |
* |
Çarpma |
/ |
Bölüm |
% |
Mod |
< |
Küçüktür |
> |
Büyüktür |
== |
Eşittir |
!= |
Eşit değil |
<= |
Küçüktür veya eşittir |
>= |
Büyüktür veya eşittir |
in |
Öğelerden birine eşit |
!in |
Öğelerin hiçbirine eşit değildir |
Dize işleçleri listesi çok daha uzun bir listedir çünkü büyük/küçük harf duyarlılığı, alt dize konumları, ön ekler, sonekler ve çok daha fazlası için permütasyonları vardır. işleci == hem sayısal hem de dize işlecidir, yani hem sayılar hem de metinler için kullanılabilir. Örneğin, aşağıdaki deyimlerin her ikisi de where deyimleri geçerli olacaktır:
| where ResultType == 0| where Category == 'SignInLogs'
Bahşiş
En İyi Yöntem: Çoğu durumda, büyük olasılıkla verilerinizi birden fazla sütuna göre filtrelemek veya aynı sütunu birden çok şekilde filtrelemek istersiniz. Bu örneklerde, aklınızda bulundurmanız gereken iki en iyi yöntem vardır.
ve anahtar sözcüğünü kullanarak birden çok where deyimi tek bir adımda birleştirebilirsiniz. Örnek:
SigninLogs
| where Resource == ResourceGroup
and TimeGenerated >= ago(7d)
Yukarıdaki gibi ve anahtar sözcüğünü kullanarak tek where bir deyime katılmış birden çok filtreniz olduğunda, önce yalnızca tek bir sütuna başvuran filtreler koyarak daha iyi bir performans elde edersiniz. Bu nedenle yukarıdaki sorguyu yazmanın daha iyi bir yolu şu olabilir:
SigninLogs
| where TimeGenerated >= ago(7d)
and Resource == ResourceGroup
Bu örnekte, ilk filtre tek bir sütundan (TimeGenerated) bahsederken, ikinci sütun iki sütuna (Resource ve ResourceGroup) başvurur.
Verileri özetleme
Özetleme, Kusto Sorgu Dili en önemli tablosal işleçlerden biridir, ancak genel olarak dilleri sorgulamaya yeni olup olmadığını öğrenmek için daha karmaşık işleçlerden biridir. görevi summarize , bir veri tablosu almak ve bir veya daha fazla sütun tarafından toplanan yeni bir tablo çıkarmaktır.
Summarize deyiminin yapısı
Bir summarize deyiminin temel yapısı aşağıdaki gibidir:
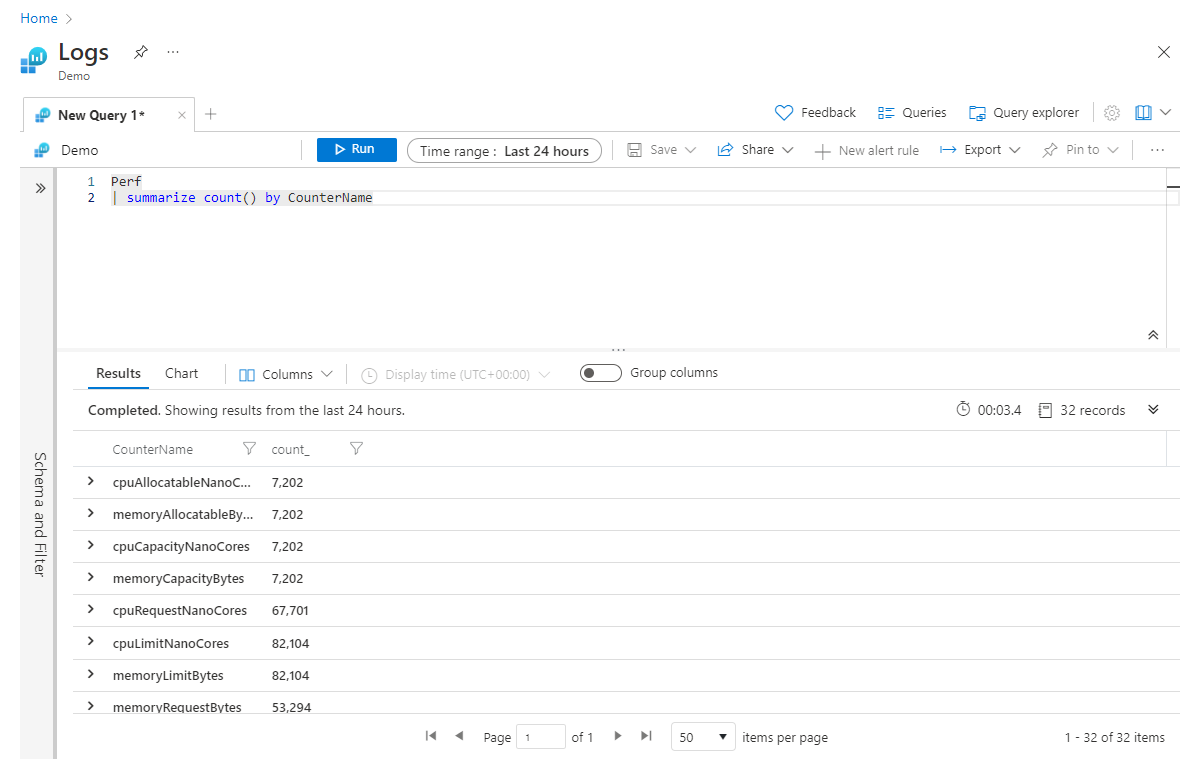
| summarize <aggregation> by <column>
Örneğin, aşağıdakiler Performans tablosundaki her CounterName değeri için kayıt sayısını döndürür:
Perf
| summarize count() by CounterName
çıkışı summarize yeni bir tablo olduğundan, deyiminde summarizeaçıkça belirtilmeyen tüm sütunlar işlem hattına geçirilmez . Bu kavramı göstermek için şu örneği göz önünde bulundurun:
Perf
| project ObjectName, CounterValue, CounterName
| summarize count() by CounterName
| sort by ObjectName asc
İkinci satırda yalnızca ObjectName, CounterValue ve CounterName sütunlarını önemsediğimizi belirtiyoruz. Ardından CounterName değerine göre kayıt sayısını almak için özetledik ve son olarak objectName sütununa göre verileri artan düzende sıralamaya çalışıyoruz. Ne yazık ki, özetlediğimizde, yeni tablomuza yalnızca Count ve CounterName sütunlarını eklediğimiz için bu sorgu bir hatayla başarısız olur (ObjectName'in bilinmediğini gösterir). Bu hatayı önlemek için, adımımızın summarize sonuna ObjectName'i şu şekilde ekleyebiliriz:
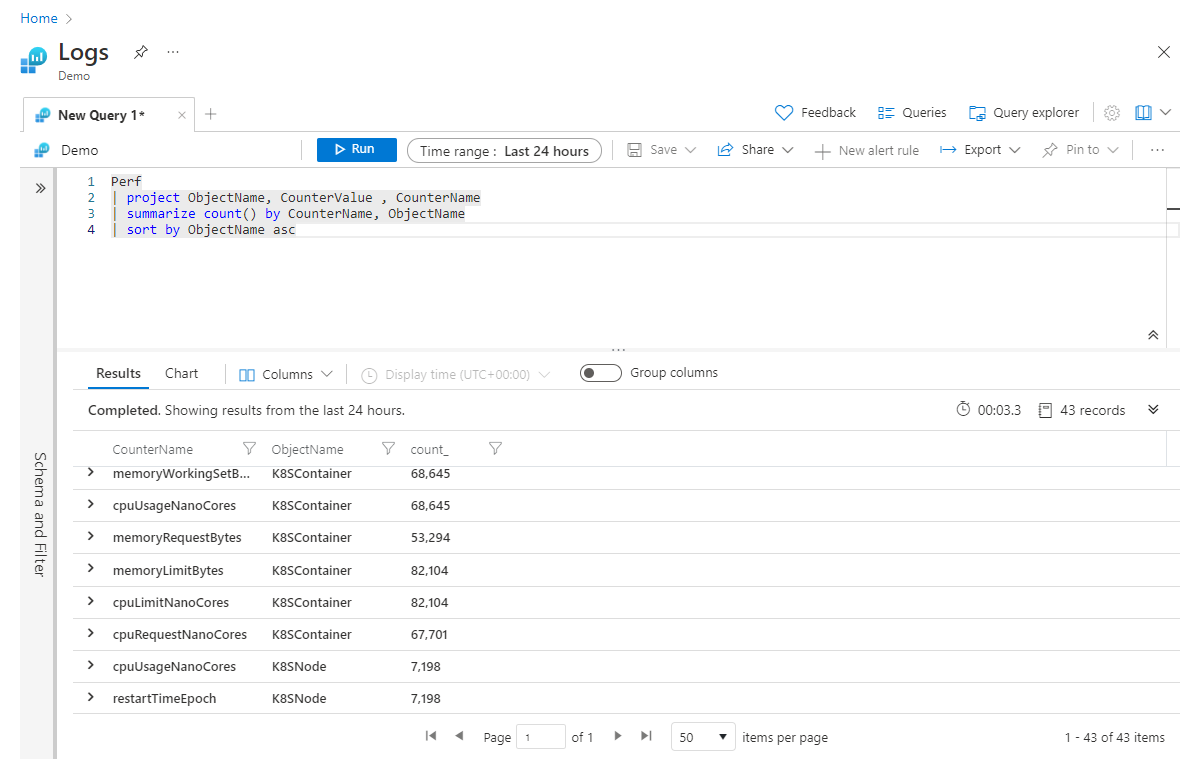
Perf
| project ObjectName, CounterValue , CounterName
| summarize count() by CounterName, ObjectName
| sort by ObjectName asc
Kafanızdaki satırı okumanın summarize yolu şu olabilir: "Kayıtların sayısını CounterName ile özetleyin ve ObjectName'e göre gruplandırın". Deyimin summarize sonuna virgülle ayırarak sütun eklemeye devam edebilirsiniz.
Önceki örnekte, birden çok sütunu aynı anda toplamak istiyorsak, işlecine summarize virgülle ayrılmış toplamalar ekleyerek bunu başarabiliriz. Aşağıdaki örnekte, yalnızca tüm kayıtların sayısını değil, aynı zamanda tüm kayıtlardaki CounterValue sütunundaki değerlerin toplamını da alıyoruz (sorgudaki filtrelerle eşleşen):
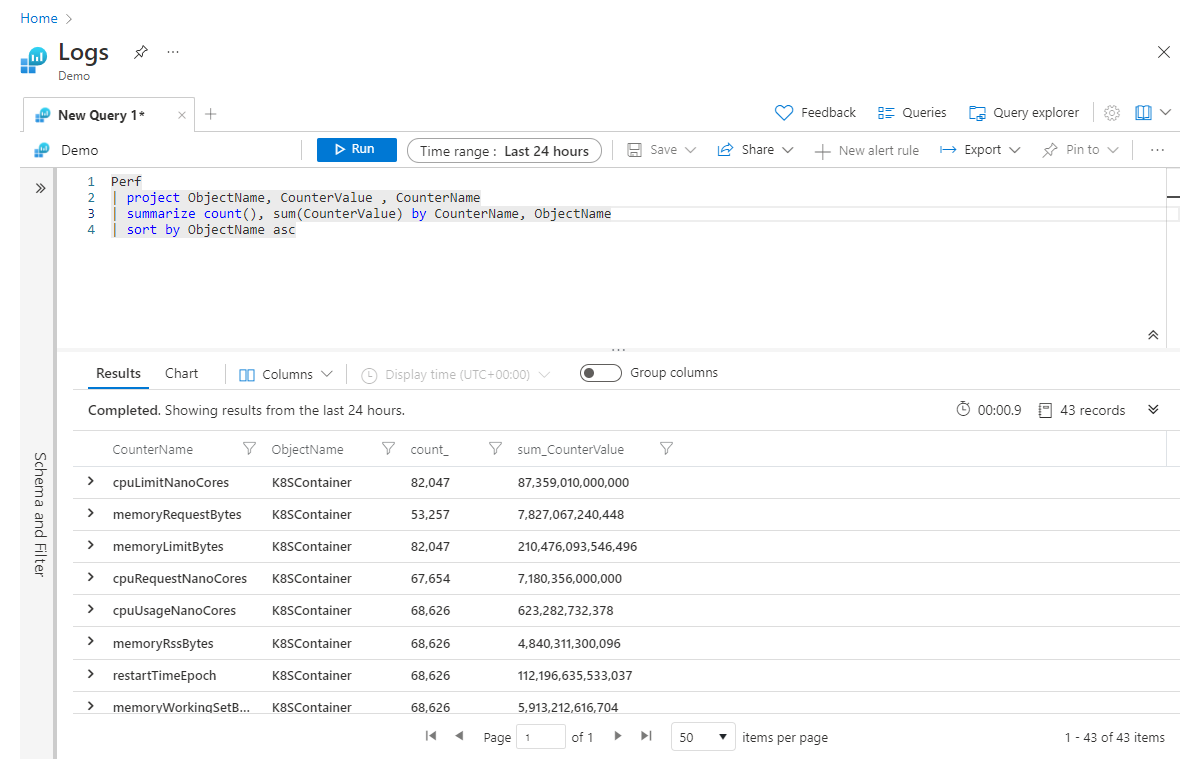
Perf
| project ObjectName, CounterValue , CounterName
| summarize count(), sum(CounterValue) by CounterName, ObjectName
| sort by ObjectName asc
Toplanan sütunları yeniden adlandırma
Bu toplanmış sütunların sütun adları hakkında konuşmak için uygun bir zaman gibi görünüyor. Bu bölümün başında, işlecin bir veri tablosu aldığını ve yeni bir tablo ürettiğini ve yalnızca deyiminde belirttiğiniz sütunların summarize işlem hattında devam edeceklerini söylediksummarize. Bu nedenle, yukarıdaki örneği çalıştırırsanız toplama işlemimizin sonucunda elde edilen sütunlar count_ ve sum_CounterValue olur.
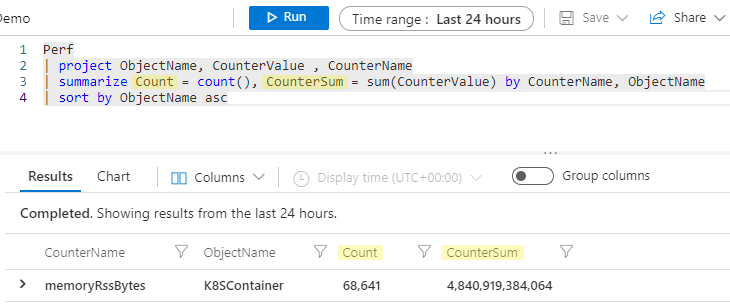
Kusto altyapısı, açık olmamıza gerek kalmadan otomatik olarak bir sütun adı oluşturur, ancak genellikle yeni sütununuzun daha kolay bir ada sahip olmasını tercih edeceğinizi göreceksiniz. Yeni bir ad ve ardından = toplama belirterek deyimindeki summarize sütununuzu kolayca yeniden adlandırabilirsiniz, örneğin:
Perf
| project ObjectName, CounterValue , CounterName
| summarize Count = count(), CounterSum = sum(CounterValue) by CounterName, ObjectName
| sort by ObjectName asc
Şimdi özetlenen sütunlarımız Count ve CounterSum olarak adlandırılacak.
Operatörde summarize burada ele alacağımızdan çok daha fazlası vardır, ancak microsoft Sentinel verileriniz üzerinde gerçekleştirmeyi planladığınız tüm veri çözümlemelerinin önemli bir bileşeni olduğundan öğrenmek için zaman harcamanız gerekir.
Toplama başvurusu
birçok toplama işlevidir, ancak en sık kullanılanlardan bazıları , count()ve avg()'tirsum(). Kısmi liste aşağıdadır (tam listeye bakın):
Toplama işlevleri
| İşlev | Tanım |
|---|---|
arg_max() |
Bağımsız değişken ekranı kapladığında bir veya daha fazla ifade döndürür |
arg_min() |
Bağımsız değişken simge durumuna küçültüldüğünde bir veya daha fazla ifade döndürür |
avg() |
Grup genelinde ortalama değer verir |
buildschema() |
Dinamik girişin tüm değerlerini kabul eden en düşük şemayı döndürür |
count() |
Grubun sayısını verir |
countif() |
Grubun koşulunu içeren sayıyı verir |
dcount() |
Grup öğelerinin yaklaşık ayrı sayısını döndürür |
make_bag() |
Grup içindeki dinamik değerlerden oluşan bir özellik paketi döndürür |
make_list() |
Gruptaki tüm değerlerin listesini döndürür |
make_set() |
Grup içinde bir dizi ayrı değer döndürür |
max() |
Grup genelindeki en büyük değeri verir |
min() |
Grup genelinde en düşük değeri verir |
percentiles() |
Grubun yüzdebirlik değerini verir |
stdev() |
Grup genelinde standart sapması verir |
sum() |
Grup içindeki öğelerin toplamını verir |
take_any() |
Grup için rastgele boş olmayan değer döndürür |
variance() |
Grup genelinde varyansı verir |
Seçme: sütun ekleme ve kaldırma
Sorgularla daha fazla çalışmaya başladığınızda, konularınızla ilgili ihtiyacınız olandan daha fazla bilgiye (tablonuzda çok fazla sütun) sahip olduğunuzu fark edebilirsiniz. Veya sahip olduğunuzdan daha fazla bilgiye ihtiyacınız olabilir (başka bir deyişle, diğer sütunların çözümleme sonuçlarını içerecek yeni bir sütun eklemeniz gerekir). Şimdi sütun işleme için birkaç anahtar işlecine göz atalım.
Proje ve proje dışı
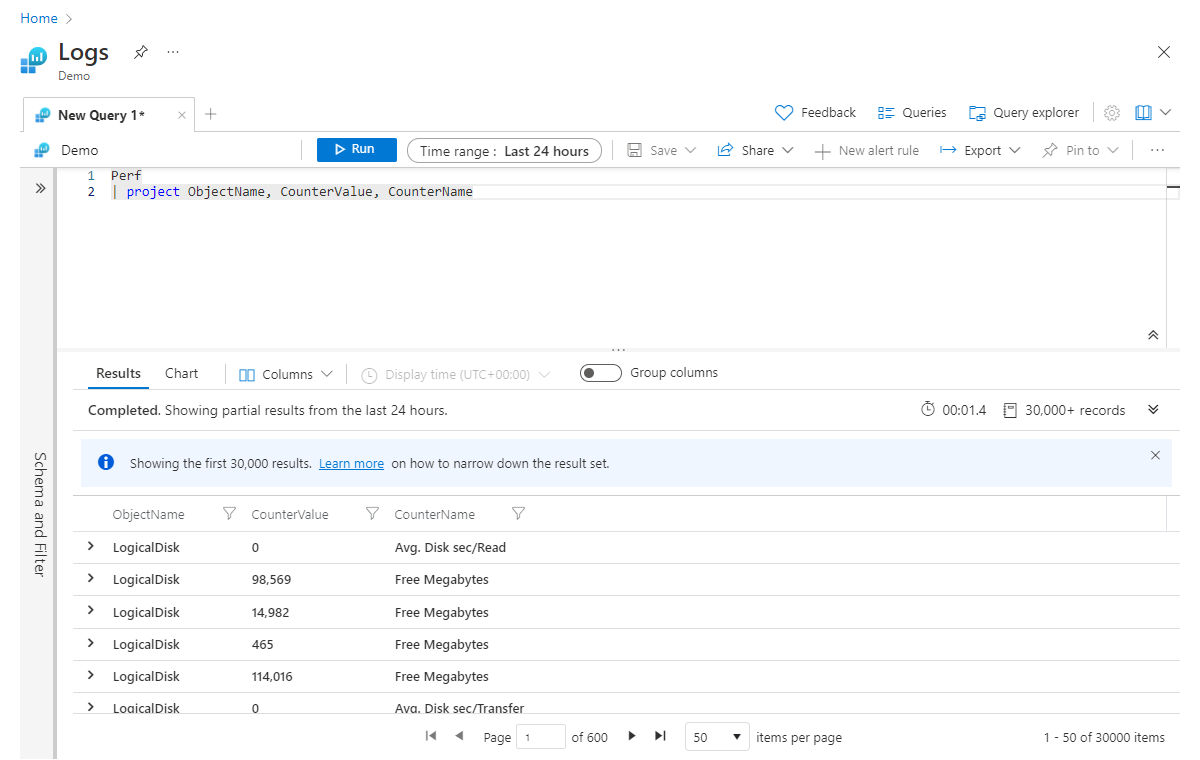
Project kabaca birçok dilin select deyimlerine eşdeğerdir. Hangi sütunların tutulacaklarını seçmenize olanak tanır. Döndürülen sütunların sırası, bu örnekte gösterildiği gibi deyiminizde project listelediğiniz sütunların sırasıyla eşleşecektir:
Perf
| project ObjectName, CounterValue, CounterName
Tahmin edebileceğiniz gibi, çok geniş veri kümeleriyle çalışırken, saklamak istediğiniz çok sayıda sütun olabilir ve bunların tümünü ada göre belirtmek çok fazla yazma gerektirir. Bu gibi durumlarda, hangi sütunların tutulacağını değil, hangi sütunların kaldırılacağını belirtmenizi sağlayan proje dışında seçeneğiniz vardır:
Perf
| project-away MG, _ResourceId, Type
Bahşiş
Sorgularınızın başında ve sonunda olmak üzere iki konumda kullanılması project yararlı olabilir. project Sorgunuzun erken aşamalarında kullanmak, işlem hattını geçirmeniz için gerekmeyen büyük veri öbeklerini kaldırarak performansın geliştirilmesine yardımcı olabilir. Sonunda yeniden kullanmak, önceki adımlarda oluşturulmuş ve son çıkışınızda gerekli olmayan tüm sütunlardan kurtulmanızı sağlar.
Genişlet
Genişlet , yeni bir hesaplanmış sütun oluşturmak için kullanılır. Bu, var olan sütunlarda bir hesaplama yapmak ve her satırın çıkışını görmek istediğinizde yararlı olabilir. Mb değerini (mevcut Quantity sütununda) 1.024 ile çarparak hesaplayabildiğimiz Kbytes adlı yeni bir sütunu hesapladığımız basit bir örneğe göz atalım.
Usage
| where QuantityUnit == 'MBytes'
| extend KBytes = Quantity * 1024
| project ResourceUri, MBytes=Quantity, KBytes
Deyimimizdeki project son satırda Quantity sütununu Mbytes olarak yeniden adlandırdık, böylece her sütun için hangi ölçü biriminin uygun olduğunu kolayca anlayabiliriz.
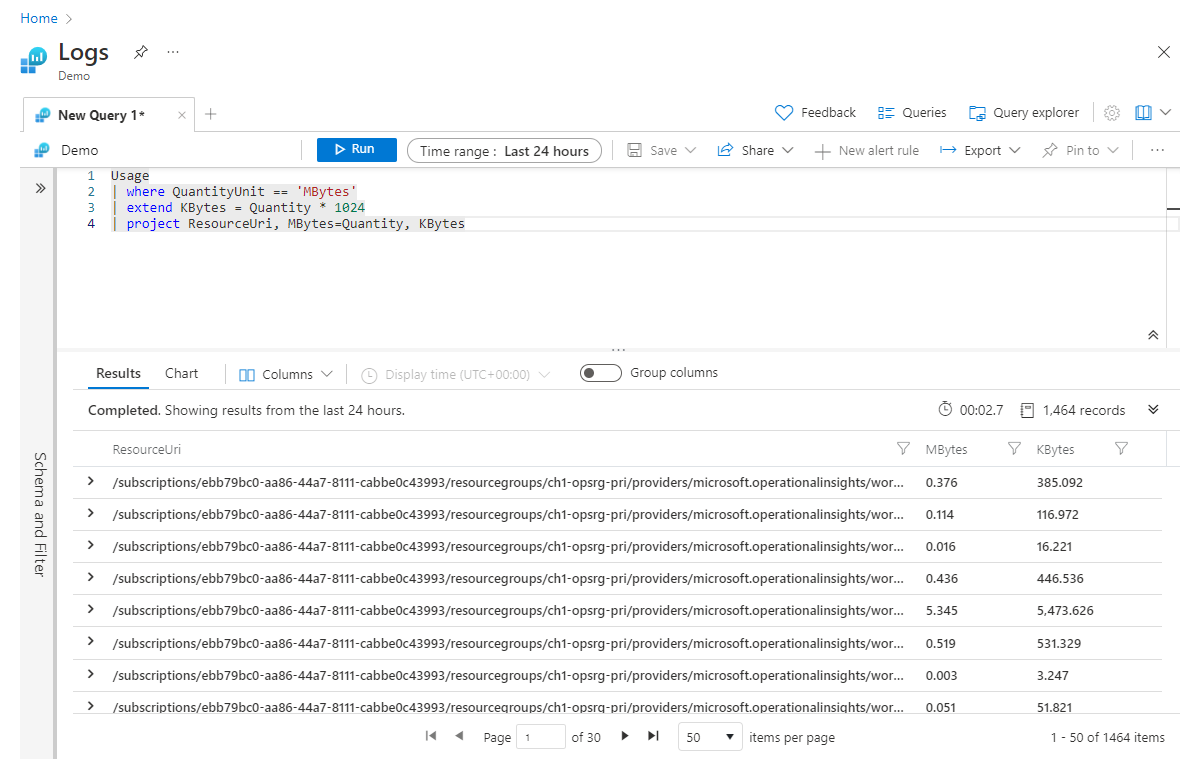
Zaten hesaplanmış sütunlarla da çalıştığını belirtmek extend gerekir. Örneğin, Kbayt cinsinden hesaplanan Baytlar adlı bir sütun daha ekleyebiliriz:
Usage
| where QuantityUnit == 'MBytes'
| extend KBytes = Quantity * 1024
| extend Bytes = KBytes * 1024
| project ResourceUri, MBytes=Quantity, KBytes, Bytes

Tabloları birleştirme
Microsoft Sentinel'deki çalışmalarınızın büyük bölümü tek bir günlük türü kullanılarak gerçekleştirilebilir, ancak bazen verileri ilişkilendirmek veya başka bir veri kümesiyle arama yapmak isteyebilirsiniz. Çoğu sorgu dili gibi Kusto Sorgu Dili de çeşitli birleştirme türlerini gerçekleştirmek için kullanılan birkaç işleç sunar. Bu bölümde, en çok kullanılan işleçlere union ve joinöğesine bakacağız.
Birliği
Birleşim yalnızca iki veya daha fazla tablo alır ve tüm satırları döndürür. Örnek:
OfficeActivity
| union SecurityEvent
Bu, hem OfficeActivity hem de SecurityEvent tablolarındaki tüm satırları döndürür. Union birleşimin nasıl davranacağını ayarlamak için kullanılabilecek birkaç parametre sunar. En kullanışlılarından ikisi withsource ve kind'dır:
OfficeActivity
| union withsource = SourceTable kind = inner SecurityEvent
withsource parametresi, belirli bir satırdaki değeri satırın geldiği tablonun adı olacak yeni bir sütunun adını belirtmenize olanak tanır. Yukarıdaki örnekte sourceTable sütununu adlandırdık ve satıra bağlı olarak değer OfficeActivity veya SecurityEvent olacaktır.
Belirttiğimiz diğer parametre, iki seçeneği olan türdü: iç veya dış. Yukarıdaki örnekte iç öğesini belirttik. Bu, birleşim sırasında tutulacak sütunların her iki tabloda da bulunan sütunlar olduğu anlamına gelir. Alternatif olarak, dış değeri (varsayılan değerdir) belirtmiş olsaydık her iki tablodaki tüm sütunlar döndürülürdü.
Join
Birleştirme, ile benzer şekilde unionçalışır, ancak yeni tablo oluşturmak için tabloları birleştirmek yerine satırları birleştirerek yeni bir tablo oluştururuz. Çoğu veritabanı dilinde olduğu gibi, gerçekleştirebileceğiniz birden çok birleştirme türü vardır. için join genel söz dizimi şöyledir:
T1
| join kind = <join type>
(
T2
) on $left.<T1Column> == $right.<T2Column>
işlecinden join sonra, gerçekleştirmek istediğimiz birleştirme türünü ve ardından açık bir parantez belirtiriz. Parantez içinde, birleştirmek istediğiniz tabloyu ve bu tablodaki eklemek istediğiniz diğer sorgu deyimlerini belirttiğiniz yerdir. Kapanış ayracından sonra on anahtar sözcüğünü ve ardından solumuzu ($left) kullanırız.<columnName> anahtar sözcüğü) ve right ($right.<columnName>) sütunları == işleciyle ayrılmıştır. İç birleşim örneği aşağıda verilmişti:
OfficeActivity
| where TimeGenerated >= ago(1d)
and LogonUserSid != ''
| join kind = inner (
SecurityEvent
| where TimeGenerated >= ago(1d)
and SubjectUserSid != ''
) on $left.LogonUserSid == $right.SubjectUserSid
Dekont
Birleştirme işlemini gerçekleştirdiğiniz sütunlar için her iki tablonun da adı aynıysa, $left ve $right kullanmanız gerekmez; bunun yerine yalnızca sütun adını belirtebilirsiniz. Ancak $left ve $right kullanmak daha açık ve genel olarak iyi bir uygulama olarak kabul edilir.
Başvurunuz için aşağıdaki tabloda kullanılabilir birleştirme türlerinin listesi gösterilmektedir.
Birleştirme Türleri
| Birleştirme Türü | Tanım |
|---|---|
inner |
Her iki tablodan eşleşen satırların her birleşimi için tek bir değer döndürür. |
innerunique |
Sol tablodan, sağ tabloda eşleşmesi olan bağlantılı alanda ayrı değerler içeren satırları döndürür. Bu varsayılan belirtilmeyen birleştirme türüdür. |
leftsemi |
Sol tablodaki, sağ tabloda eşleşmesi olan tüm kayıtları döndürür. Yalnızca sol tablodaki sütunlar döndürülür. |
rightsemi |
Sağ tablodan, sol tabloda eşleşmesi olan tüm kayıtları döndürür. Yalnızca sağ tablodaki sütunlar döndürülür. |
leftanti/leftantisemi |
Sol tablodaki, sağ tabloda eşleşmesi olmayan tüm kayıtları döndürür. Yalnızca sol tablodaki sütunlar döndürülür. |
rightanti/rightantisemi |
Sağ tablodaki, sol tabloda eşleşmesi olmayan tüm kayıtları döndürür. Yalnızca sağ tablodaki sütunlar döndürülür. |
leftouter |
Sol tablodaki tüm kayıtları döndürür. Sağ tabloda eşleşmesi olmayan kayıtlar için hücre değerleri null olur. |
rightouter |
Sağ tablodaki tüm kayıtları döndürür. Sol tabloda eşleşmesi olmayan kayıtlar için hücre değerleri null olur. |
fullouter |
Eşleşen veya olmayan hem sol hem de sağ tablolardaki tüm kayıtları döndürür. Eşleşmeyen değerler null olur. |
Bahşiş
En küçük tablonuzun solda olması en iyi yöntemdir . Bazı durumlarda, bu kuralın izlenmesi, gerçekleştirdiğiniz birleştirme türlerine ve tabloların boyutuna bağlı olarak size büyük performans avantajları sağlayabilir.
Değerlendirin
İlk örnekte, satırlardan birinde evaluate işlecini gördüğümüzi hatırlayabilirsiniz. İşleç evaluate , daha önce dokunduğumuz işleçlerden daha az yaygın olarak kullanılır. Ancak, operatörün evaluate nasıl çalıştığını bilmek zamanınızı almaya değer. Bir kez daha, ikinci satırda göreceğiniz evaluate ilk sorgu aşağıdadır.
SigninLogs
| evaluate bag_unpack(LocationDetails)
| where RiskLevelDuringSignIn == 'none'
and TimeGenerated >= ago(7d)
| summarize Count = count() by city
| sort by Count desc
| take 5
Bu işleç, kullanılabilir eklentileri (temel olarak yerleşik işlevler) çağırmanıza olanak tanır. Bu eklentilerin çoğu, otomatik kümeleme, difpatterns ve sequence_detect gibi veri bilimine odaklanarak gelişmiş analiz gerçekleştirmenize ve istatistiksel anomalileri ve aykırı değerleri keşfetmenize olanak sağlar.
Yukarıdaki örnekte kullanılan eklenti bag_unpack olarak adlandırılıyordu ve dinamik verilerin bir öbeklerini alıp sütunlara dönüştürmeyi çok kolaylaştırır. Dinamik verilerin, bu örnekte gösterildiği gibi JSON'a çok benzeyen bir veri türü olduğunu unutmayın:
{
"countryOrRegion":"US",
"geoCoordinates": {
"longitude":-122.12094116210936,
"latitude":47.68050003051758
},
"state":"Washington",
"city":"Redmond"
}
Bu örnekte verileri şehre göre özetlemek istedik, ancak şehir LocationDetails sütununda bir özellik olarak yer alır. Sorgumuzda şehir özelliğini kullanmak için önce bag_unpack kullanarak bunu bir sütuna dönüştürmemiz gerekiyordu.
Özgün işlem hattı adımlarımıza geri dönerken şunu gördük:
Get Data | Filter | Summarize | Sort | Select
Artık işlecini değerlendirdiğimize evaluate göre işlem hattında yeni bir aşamayı temsil ettiğini görebiliriz ve bu aşama şu şekilde görünür:
Get Data | Parse | Filter | Summarize | Sort | Select
Veri kaynaklarını daha okunabilir ve işlenebilir bir biçimde ayrıştırmak için kullanılabilecek birçok farklı işleç ve işlev örneği vardır. Bunlar ve Kusto Sorgu Dili geri kalanı hakkında bilgi edinmek için tam belgelerde ve çalışma kitabından bilgi edinebilirsiniz.
Let deyimleri
Önemli işleçlerin ve veri türlerinin birçoğunu ele aldığımıza göre, şimdi sorgularınızın okunmasını, düzenlenmesini ve bakımının kolay olmasını sağlamanın harika bir yolu olan let deyimini ele alalım.
Bir değişken oluşturup ayarlamanıza veya bir ifadeye ad atamanıza olanak tanır. Bu ifade tek bir değer olabilir, ancak aynı zamanda tam bir sorgu da olabilir. İşte basit bir örnek:
let aWeekAgo = ago(7d);
SigninLogs
| where TimeGenerated >= aWeekAgo
Burada birWeekAgo adı belirttik ve bunu bir tarih saat değeri döndüren bir zaman aralığı işlevinin çıkışına eşit olacak şekilde ayarladık. Ardından let deyimini noktalı virgülle sonlandırıyoruz. Artık sorgumuzda herhangi bir yerde kullanılabilen aWeekAgo adlı yeni bir değişkenimiz var.
Daha önce de belirttiğimiz gibi, sorgunun tamamını almak ve sonucu bir ad vermek için let deyimini kullanabilirsiniz. Sorgu sonuçları, tablosal ifadeler olduğundan sorguların girişleri olarak kullanılabildiğinden, bu adlandırılmış sonucu üzerinde başka bir sorgu çalıştırmak amacıyla bir tablo olarak değerlendirebilirsiniz. Önceki örnekte küçük bir değişiklik aşağıda verilmiştir:
let aWeekAgo = ago(7d);
let getSignins = SigninLogs
| where TimeGenerated >= aWeekAgo;
getSignins
Bu örnekte ikinci bir let deyimi oluşturduk ve burada sorgumuzun tamamını getSignins adlı yeni bir değişkene sarmaladık. Daha önce olduğu gibi ikinci let deyimini noktalı virgülle sonlandırıyoruz. Ardından sorguyu çalıştıracak son satırda değişkenini çağırırız. İkinci let deyiminde birWeekAgo kullanabildiğimizi fark edin. Bunun nedeni bunu önceki satırda belirtmemizdir; getSignins'in ilk kez gelmesi için let deyimlerini değiştirirsek bir hatayla karşılaşırız.
Artık getSignins'i başka bir sorgunun temeli olarak kullanabiliriz (aynı pencerede):
let aWeekAgo = ago(7d);
let getSignins = SigninLogs
| where TimeGenerated >= aWeekAgo;
getSignins
| where level >= 3
| project IPAddress, UserDisplayName, Level
deyimleri , sorgularınızı düzenlemenize yardımcı olma konusunda size daha fazla güç ve esneklik sağlar. Skaler ve tablosal değerleri tanımlamanın yanı sıra kullanıcı tanımlı işlevler oluşturalım . Birden çok birleştirme yapan daha karmaşık sorgular düzenlerken bunlar gerçekten kullanışlıdır.
Sonraki adımlar
Bu makale yüzeyi neredeyse hiç karalamamış olsa da artık gerekli temele sahipsiniz ve Microsoft Sentinel'de işinizi yapmak için en sık kullandığınız parçaları ele aldık.
Microsoft Sentinel çalışma kitabı için gelişmiş KQL
Microsoft Sentinel için Gelişmiş KQL çalışma kitabı olan Kusto Sorgu Dili çalışma kitabından doğrudan Microsoft Sentinel'in kendisinde yararlanın. Günlük güvenlik operasyonlarınızda karşılaşma olasılığınız olan birçok durum için adım adım yardım ve örnekler sunar ve ayrıca analiz kuralları, çalışma kitapları, tehdit avcılığı kuralları ve Kusto sorgularını kullanan daha birçok hazır, kullanıma hazır öğe örneğine işaret eder. Bu çalışma kitabını Microsoft Sentinel'deki Çalışma Kitapları dikey penceresinden başlatın.
Gelişmiş KQL Framework Çalışma Kitabı - KQL-savvy olmanıza yardımcı olmak, bu çalışma kitabını nasıl kullanacağınızı gösteren mükemmel bir blog gönderisidir.
Diğer kaynaklar
Kusto Sorgu Dili bilgilerinizi genişletmek ve derinleştirmek için bu öğrenme, eğitim ve beceri kaynakları koleksiyonuna bakın.