Teradata geçişleri için tasarım ve performans
Bu makale, Teradata'dan Azure Synapse Analytics'e geçiş konusunda rehberlik sağlayan yedi bölümden oluşan serinin birinci bölümüdür. Bu makalenin odak noktası tasarım ve performansa yönelik en iyi yöntemlerdir.
Genel Bakış
Teradata veri ambarı sistemlerinin birçok mevcut kullanıcısı, modern bulut ortamları tarafından sağlanan yeniliklerden yararlanmak istiyor. Hizmet olarak altyapı (IaaS) ve hizmet olarak platform (PaaS) bulut ortamları, altyapı bakımı ve platform geliştirme gibi görevleri bulut sağlayıcısına devretmenizi sağlar.
Bahşiş
Bir veritabanından daha fazlası: Azure ortamı kapsamlı bir özellik ve araç kümesi içerir.
Teradata ve Azure Synapse Analytics, olağanüstü büyük veri hacimlerinde yüksek sorgu performansı elde etmek için yüksek düzeyde paralel işleme (MPP) teknikleri kullanan SQL veritabanları olsa da yaklaşımda bazı temel farklılıklar vardır:
Eski Teradata sistemleri genellikle şirket içinde yüklenir ve özel donanım kullanırken, Azure Synapse bulut tabanlıdır ve Azure Depolama ve işlem kaynaklarını kullanır.
Depolama ve işlem kaynakları Azure ortamında ayrı olduğundan ve esnek ölçeklendirme özelliğine sahip olduğundan, bu kaynaklar bağımsız olarak yukarı veya aşağı doğru ölçeklendirilebilir.
Kaynak kullanımını ve maliyetini azaltmak için Azure Synapse'i gerektiği gibi duraklatabilir veya yeniden boyutlandırabilirsiniz.
Teradata yapılandırmasını yükseltmek, fazladan fiziksel donanım ve büyük olasılıkla uzun veritabanı yeniden yapılandırma veya yeniden yükleme içeren önemli bir görevdir.
Microsoft Azure, Azure Synapse'i ve destekleyici araç ve özellikler ekosistemini içeren küresel olarak kullanılabilir, yüksek oranda güvenli, ölçeklenebilir bir bulut ortamıdır. Sonraki diyagramda Azure Synapse ekosistemi özetlemektedir.
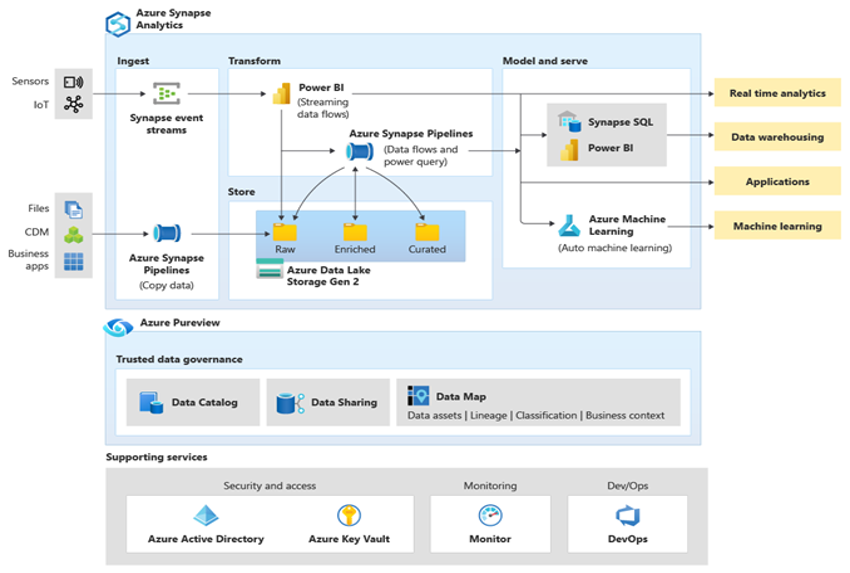
Azure Synapse, sık kullanılan veriler için MPP ve birden çok otomatik önbelleğe alma düzeyi gibi teknikleri kullanarak en iyi tür ilişkisel veritabanı performansı sağlar. Bu tekniklerin sonuçlarını, Azure Synapse'i diğer popüler bulut veri ambarı teklifleriyle karşılaştıran GigaOm'un son çalıştırması gibi bağımsız karşılaştırmalarda görebilirsiniz. Azure Synapse ortamına geçiş yapan müşteriler aşağıdakiler gibi birçok avantaj görür:
Geliştirilmiş performans ve fiyat/performans.
Artan çeviklik ve değere daha kısa süre.
Daha hızlı sunucu dağıtımı ve uygulama geliştirme.
Esnek ölçeklenebilirlik: Yalnızca gerçek kullanım için ödeme.
Geliştirilmiş güvenlik/uyumluluk.
Daha düşük depolama ve olağanüstü durum kurtarma maliyetleri.
Daha düşük genel TCO, daha iyi maliyet denetimi ve kolaylaştırılmış operasyonel harcamalar (OPEX).
Bu avantajları en üst düzeye çıkarmak için yeni veya mevcut verileri ve uygulamaları Azure Synapse platformuna geçirin. Birçok kuruluşta geçiş, mevcut bir veri ambarını Teradata gibi eski bir şirket içi platformdan Azure Synapse'e taşımayı içerir. Geçiş işlemi üst düzeyde şu adımları içerir:
Hazırlık 🡆
Geçirilecek kapsamı tanımlayın.
Geçiş için veri ve işlemlerin envanterini oluşturun.
Veri modeli değişikliklerini tanımlama (varsa).
Kaynak veri ayıklama mekanizmasını tanımlayın.
Kullanılacak uygun Azure ve üçüncü taraf araçlarını ve özelliklerini belirleyin.
Personeli yeni platformda erken eğitin.
Azure hedef platformunu ayarlayın.
Geçiş 🡆
Küçük ve basit bir başlangıç.
Mümkün olan her yerde otomatikleştirin.
Geçiş çalışmalarını azaltmak için Azure'ın yerleşik araç ve özelliklerinden yararlanın.
Tablolar ve görünümler için meta verileri geçirme.
Korunacak geçmiş verileri geçirme.
Saklı yordamları ve iş süreçlerini geçirme veya yeniden düzenleme.
ETL/ELT artımlı yük işlemlerini geçirme veya yeniden düzenleme.
Geçiş sonrası
İşlemin tüm aşamalarını izleyin ve belgeleyin.
Gelecekteki geçişler için bir şablon oluşturmak için kazanılan deneyimi kullanın.
Gerekirse veri modelini yeniden tasarlama (yeni platform performansı ve ölçeklenebilirlik kullanarak).
Uygulamaları ve sorgu araçlarını test edin.
Sorgu performansını karşılaştırma ve iyileştirme.
Bu makalede, mevcut bir Netezza ortamından Azure Synapse'e veri ambarı geçirildiğinde performans iyileştirmeye yönelik genel bilgiler ve yönergeler sağlanmaktadır. Performans iyileştirmesinin amacı, şema geçişi sonrasında Azure Synapse'te aynı veya daha iyi veri ambarı performansına ulaşmaktır.
Tasarımla ilgili dikkat edilecek noktalar
Geçiş kapsamı
Teradata ortamından geçiş yapmaya hazırlanırken aşağıdaki geçiş seçeneklerini göz önünde bulundurun.
İlk geçiş için iş yükünü seçme
Genellikle, eski Teradata ortamları zaman içinde birden çok konu alanını ve karma iş yüklerini kapsayacak şekilde gelişmiştir. Geçiş projesinde nereden başlayacağınıza karar verirken şunları yapabileceğiniz bir alan seçin:
Yeni ortamın avantajlarını hızla sunarak Azure Synapse'e geçişin uygulanabilirliğini kanıtlayın.
Şirket içi teknik personelinizin diğer alanları geçirirken kullanacakları süreçler ve araçlarla ilgili deneyim kazanmalarına izin verin.
Kaynak Teradata ortamına özgü diğer geçişler ve zaten mevcut olan araçlar ve işlemler için bir şablon oluşturun.
Önceki öğeleri Çevre desteği bir Teradata'dan ilk geçiş için iyi bir adaydır ve:
Çevrimiçi işlem işleme (OLTP) iş yükü yerine bi/analytics iş yükü uygular.
En az değişiklikle geçirilebilen yıldız veya kar tanesi şeması gibi bir veri modeline sahiptir.
Bahşiş
Geçirilmesi gereken nesnelerin envanterini oluşturun ve geçiş işlemini belgeleyin.
İlk geçişte geçirilen verilerin hacmi, Azure Synapse ortamının özelliklerini ve avantajlarını gösterecek kadar büyük olmalıdır, ancak değeri hızlı bir şekilde gösteremeyecek kadar büyük olmamalıdır. 1-10 terabayt aralığındaki bir boyut tipiktir.
İlk geçiş projenizde riski, çabayı ve geçiş süresini en aza indirerek Azure bulut ortamının avantajlarını hızla görebilirsiniz ve geçişin kapsamını yalnızca Teradata ambarının OLAP VERITABANı bölümü gibi veri reyonlarıyla sınırlandırın. Hem lift-and-shift hem de aşamalı geçiş yaklaşımları, ilk geçişin kapsamını yalnızca veri reyonlarıyla sınırlar ve ETL geçişi ve geçmiş veri geçişi gibi daha geniş geçiş özelliklerini ele almaz. Ancak, geçirilen veri reyonu katmanı verilerle ve gerekli derleme işlemleriyle doldurulduktan sonra projenin sonraki aşamalarında bu özellikleri ele alabilirsiniz.
Lift and shift geçişi ile Aşamalı yaklaşım karşılaştırması
Genel olarak, planlanan geçişin amacı ve kapsamı ne olursa olsun iki tür geçiş vardır: olduğu gibi lift and shift ve değişiklikleri içeren aşamalı bir yaklaşım.
Lift and shift
Lift and shift geçişinde yıldız şeması gibi mevcut bir veri modeli, yeni Azure Synapse platformuna değiştirilmeden geçirilir. Bu yaklaşım, Azure bulut ortamına geçmenin avantajlarını gerçekleştirmek için gereken çalışmayı azaltarak riski ve geçiş süresini en aza indirir. Lift and shift geçişi bu senaryolar için uygundur:
- Geçiş için tek bir veri reyonu içeren mevcut bir Teradata ortamınız var veya
- Zaten iyi tasarlanmış bir yıldız veya kar tanesi şemasında bulunan verileri içeren mevcut bir Teradata ortamınız var veya
- Modern bir bulut ortamına geçmek için zaman ve maliyet baskısı altındasınız.
Bahşiş
Sonraki aşamalar veri modelinde değişiklik uygulasa bile lift and shift iyi bir başlangıç noktasıdır.
Değişiklikleri içeren aşamalı yaklaşım
Eski bir veri ambarı uzun bir süre içinde geliştiyse, gerekli performans düzeylerini korumak için bunu yeniden tasarlamanız gerekebilir. Nesnelerin İnterneti (IoT) akışları gibi yeni verileri desteklemek için yeniden mühendislik de oluşturmanız gerekebilir. Yeniden mühendislik sürecinin bir parçası olarak, ölçeklenebilir bir bulut ortamının avantajlarından yararlanmak için Azure Synapse'e geçin. Geçiş, inmon modelinden veri kasasına taşıma gibi temel veri modelinde bir değişiklik de içerebilir.
Microsoft, mevcut veri modelinizi olduğu gibi Azure'a taşımanızı (isteğe bağlı olarak Azure'da bir VM Teradata örneği kullanarak) ve yeniden mühendislik değişikliklerini uygulamak için Azure ortamının performansını ve esnekliğini kullanmanızı önerir. Bu şekilde, mevcut kaynak sistemi etkilemeden değişiklikleri yapmak için Azure'ın özelliklerini kullanabilirsiniz.
Geçişin bir parçası olarak Azure VM Teradata örneği kullanma
Şirket içi Teradata ortamından geçiş yaparken, VM içinde bir Teradata örneği oluşturmak için Azure'da bulut depolama ve esnek ölçeklenebilirlikten yararlanabilirsiniz. Bu yaklaşım, Teradata örneğini hedef Azure Synapse ortamıyla birleştirir. Geçirilmekte olan Teradata tablolarının alt kümesini VM örneğine verimli bir şekilde taşımak için Teradata Paralel Veri Taşıyıcı gibi standart Teradata yardımcı programlarını kullanabilirsiniz. Daha sonra, diğer tüm geçiş görevleri Azure ortamında gerçekleşebilir. Bu yaklaşımın çeşitli avantajları vardır:
Verilerin ilk çoğaltıldıktan sonra, kaynak sistem geçiş görevlerinden etkilenmez.
Tanıdık Teradata arabirimleri, araçları ve yardımcı programları Azure ortamında kullanılabilir.
Azure ortamı, şirket içi kaynak sistemi ile bulut hedef sistemi arasındaki ağ bant genişliği kullanılabilirliğiyle ilgili olası sorunları önler.
Azure Data Factory gibi araçlar, verileri verimli ve hızlı bir şekilde geçirmek için Teradata Parallel Transporter gibi yardımcı programları çağırabilir.
Geçiş işlemini tamamen Azure ortamında düzenleyebilir ve denetleyebilirsiniz.
Bahşiş
Geçişi hızlandırmak ve kaynak sistem üzerindeki etkiyi en aza indirmek için geçici bir Teradata örneği oluşturmak için Azure VM'lerini kullanın.
Meta veri temelli geçiş uygulamak için Azure Data Factory'yi kullanma
Azure ortamının özelliklerini kullanarak geçiş işlemini otomatikleştirebilir ve düzenleyebilirsiniz. Bu yaklaşım, mevcut Netezza ortamındaki performans isabetini en aza indirir ve zaten kapasiteye yakın çalışıyor olabilir.
Azure Data Factory , bulutta veri taşımayı ve veri dönüştürmeyi düzenleyen ve otomatik hale getiren veri odaklı iş akışları oluşturmayı destekleyen bulut tabanlı bir veri tümleştirme hizmetidir. Data Factory'yi kullanarak farklı veri depolarından veri alabilen veri temelli iş akışları (işlem hatları) oluşturabilir ve zamanlayabilirsiniz. Data Factory, Azure HDInsight Hadoop, Spark, Azure Data Lake Analytics ve Azure Machine Learning gibi işlem hizmetlerini kullanarak verileri işleyebilir ve dönüştürebilir.
Geçiş işlemini yönetmek için Data Factory olanaklarını kullanmayı planlarken, geçirilecek tüm veri tablolarını ve konumlarını listeleyen meta veriler oluşturun.
Teradata ile Azure Synapse arasındaki tasarım farklılıkları
Daha önce de belirtildiği gibi, Teradata ile Azure Synapse Analytics veritabanları arasındaki yaklaşımda bazı temel farklılıklar vardır ve bu farklılıklar daha sonra ele alınıyor.
Birden çok veritabanı ve tek bir veritabanı ve şemalar karşılaştırması
Teradata ortamı genellikle birden çok ayrı veritabanı içerir. Örneğin, veri alımı ve hazırlama tabloları, çekirdek ambar tabloları ve veri reyonları (bazen anlam katmanı olarak da adlandırılır) için ayrı veritabanları olabilir. ETL veya ELT işlem hattı işlemleri veritabanları arası birleşimler uygulayabilir ve verileri ayrı veritabanları arasında taşıyabilir.
Buna karşılık, Azure Synapse ortamı tek bir veritabanı içerir ve tabloları mantıksal olarak ayrı gruplara ayırmak için şemaları kullanır. Teradata ortamından geçirilen ayrı veritabanlarını taklit etmek için hedef Azure Synapse veritabanında bir dizi şema kullanmanızı öneririz. Teradata ortamı şemaları zaten kullanıyorsa, mevcut Teradata tablolarını ve görünümlerini yeni ortama taşırken yeni bir adlandırma kuralı kullanmanız gerekebilir. Örneğin, mevcut Teradata şemasını ve tablo adlarını yeni Azure Synapse tablo adıyla birleştirir ve özgün ayrı veritabanı adlarını korumak için yeni ortamda şema adlarını kullanabilirsiniz. Şema birleştirme adlandırmasında noktalar varsa Azure Synapse Spark'ta sorunlar olabilir. Mantıksal yapıları korumak için temel tabloların üzerinde SQL görünümlerini kullanabilirsiniz ancak bu yaklaşımın olası dezavantajları vardır:
Azure Synapse'teki görünümler salt okunur olduğundan, verilerde yapılan tüm güncelleştirmelerin temel alınan temel tablolarda gerçekleşmesi gerekir.
Zaten bir veya daha fazla görünüm katmanı olabilir ve iç içe görünümlerin sorunlarını gidermek zor olduğundan ek görünüm katmanı eklemek performansı ve desteklenebilirliği etkileyebilir.
Bahşiş
Azure Synapse'de birden çok veritabanını tek bir veritabanında birleştirin ve tabloları mantıksal olarak ayırmak için şema adlarını kullanın.
Tabloyla ilgili dikkat edilmesi gerekenler
Tabloları farklı ortamlar arasında geçirirken, genellikle yalnızca ham veriler ve bunu açıklayan meta veriler fiziksel olarak geçirildiğinde. Kaynak sistemdeki dizinler gibi diğer veritabanı öğeleri, yeni ortamda gereksiz veya farklı şekilde uygulandığından genellikle geçirilmez. Dizinler gibi kaynak ortamdaki performans iyileştirmeleri, yeni ortamda performans iyileştirmesini nereye ekleyebileceğinizi gösterir. Örneğin, kaynak Teradata ortamındaki bir tablonun benzersiz olmayan bir ikincil dizini (NUSI) varsa, bu, Azure Synapse içinde kümelenmemiş bir dizin oluşturulması gerektiğini önerir. Tablo çoğaltma gibi diğer yerel performans iyileştirme teknikleri, benzer dizin oluşturma gibi düzlerden daha uygulanabilir olabilir.
Bahşiş
Mevcut dizinler geçirilen ambarda dizin oluşturma adaylarını gösterir.
Veritabanı için yüksek kullanılabilirlik
Teradata, belirli bir düğümde fiziksel olarak bulunan tablo satırlarını sistemdeki başka bir düğüme çoğaltan seçeneği aracılığıyla FALLBACK düğümler arasında veri çoğaltmayı destekler. Bu yaklaşım, düğüm hatası olduğunda verilerin kaybolmayacağını garanti eder ve yük devretme senaryolarına temel sağlar.
Azure Synapse Analytics'te yüksek kullanılabilirlik mimarisinin amacı, bakım işlemlerinin ve kesintilerin etkisi konusunda endişelenmeden veritabanınızın %99,9 oranında çalışır durumda olmasını sağlamaktır. SLA hakkında daha fazla bilgi için bkz . Azure Synapse Analytics için SLA. Azure, düzeltme eki uygulama, yedeklemeler, Windows ve SQL yükseltmeleri gibi kritik hizmet görevlerini otomatik olarak işler. Azure ayrıca temel alınan donanım, yazılım veya ağdaki hatalar gibi planlanmamış olayları da otomatik olarak işler.
Azure Synapse'te veri depolama otomatik olarak anlık görüntülerle yedekleniyor . Bu anlık görüntüler, hizmetin geri yükleme noktaları oluşturan yerleşik bir özelliğidir. Bu özelliği etkinleştirmeniz gerekmez. Kullanıcılar şu anda hizmetin kurtarma için hizmet düzeyi sözleşmelerini (SLA) korumak için kullandığı otomatik geri yükleme noktalarını silemez.
Azure Synapse Ayrılmış SQL havuzu, yedi gün boyunca kullanılabilen geri yükleme noktaları oluşturmak için gün boyunca veri ambarının anlık görüntülerini alır. Bu saklama süresi değiştirilemez. Azure Synapse sekiz saatlik kurtarma noktası hedeflerini (RPO) destekler. Birincil bölgedeki veri ambarınızı son yedi gün içinde alınan anlık görüntülerden herhangi birinden geri yükleyebilirsiniz. Daha ayrıntılı yedeklemeler gerekiyorsa, başka bir kullanıcı tanımlı seçenek kullanabilirsiniz.
Desteklenmeyen Teradata tablo türleri
Teradata, zaman serisi ve zamansal veriler için özel tablo türlerini destekler. Bu tablo türlerinin söz dizimi ve bazı işlevleri Azure Synapse'te doğrudan desteklenmez. Ancak, uygun veri türlerine eşleyerek ve tarih/saat sütununu dizine ekleyerek veya bölümleyerek verileri Azure Synapse'te standart bir tabloya geçirebilirsiniz.
Bahşiş
Azure Synapse'teki standart tablolar geçirilen Teradata zaman serisini ve zamansal verileri destekleyebilir.
Teradata, geçerli tarih aralığını sınırlamak üzere bir zamana bağlı sorguya ek filtreler eklemek için sorgu yeniden yazma özelliğini kullanarak zamansal sorgu işlevselliğini uygular. Bu işlevi kaynak Teradata ortamından geçirmeyi planlıyorsanız ek filtrelemeyi ilgili zamana bağlı sorgulara ekleyin.
Azure Çevre desteği zaman serisi verileri üzerinde büyük ölçekte karmaşık analizler için zaman serisi içgörüleri sunar. Bu işlev IoT veri analizi uygulamalarını hedefler.
SQL DML söz dizimi farklılıkları
Teradata SQL ile Azure Synapse T-SQL arasında SQL Veri İşleme Dili (DML) söz dizimi farklılıkları vardır:
QUALIFY: Teradata işleciniQUALIFYdestekler. Örneğin:SELECT col1 FROM tab1 WHERE col1='XYZ' QUALIFY ROW_NUMBER () OVER (PARTITION by col1 ORDER BY col1) = 1;Eşdeğer Azure Synapse söz dizimi:
SELECT * FROM ( SELECT col1, ROW_NUMBER () OVER (PARTITION by col1 ORDER BY col1) rn FROM tab1 WHERE col1='XYZ' ) WHERE rn = 1;Tarih aritmetiği: Azure Synapse,veya
DATETIMEalanlarında kullanılabilenDATEveDATEDIFFgibiDATEADDişleçlere sahiptir. Teradata, gibi tarihlerde doğrudan çıkarmayı desteklerSELECT DATE1 - DATE2 FROM...GROUP BYGROUP BY: sıra için açıkça bir T-SQL sütun adı belirtin.LIKE ANY: Teradata aşağıdaki gibi söz dizimlerini desteklerLIKE ANY:SELECT * FROM CUSTOMER WHERE POSTCODE LIKE ANY ('CV1%', 'CV2%', 'CV3%');Azure Synapse söz dizimindeki eşdeğeri:
SELECT * FROM CUSTOMER WHERE (POSTCODE LIKE 'CV1%') OR (POSTCODE LIKE 'CV2%') OR (POSTCODE LIKE 'CV3%');Sistem ayarlarına bağlı olarak, Teradata'daki karakter karşılaştırmaları varsayılan olarak büyük/küçük harfe duyarsız olabilir. Azure Synapse'te karakter karşılaştırmaları her zaman büyük/küçük harfe duyarlıdır.
İşlevler, saklı yordamlar, tetikleyiciler ve diziler
Teradata gibi olgun bir ortamdan veri ambarı geçirirken, büyük olasılıkla basit tablolar ve görünümler dışındaki öğeleri geçirmeniz gerekir. İşlevler, saklı yordamlar, tetikleyiciler ve diziler bunlara örnek olarak verilebilir. Yerleşik Azure araçlarını kullanmak, Azure Synapse için bu öğeleri yeniden kodlamaktan daha verimli olduğundan, Azure ortamındaki araçların işlevlerin, saklı yordamların ve dizilerin işlevlerini değiştirip değiştiremeyeceğini denetleyin.
Hazırlık aşamanızın bir parçası olarak geçirilmesi gereken nesnelerin envanterini oluşturun, bunları işlemek için bir yöntem tanımlayın ve geçiş planınızda uygun kaynakları ayırın.
Veri tümleştirme iş ortakları işlevlerin, saklı yordamların ve dizilerin geçişini otomatikleştirebilen araçlar ve hizmetler sunar.
Aşağıdaki bölümlerde işlevlerin, saklı yordamların ve dizilerin geçişi ele alınmaktadır.
İşlevler
Çoğu veritabanı ürününde olduğu gibi, Teradata bir SQL uygulaması içindeki sistem ve kullanıcı tanımlı işlevleri destekler. Eski bir veritabanı platformunu Azure Synapse'e geçirdiğinizde, genel sistem işlevleri genellikle değişiklik olmadan geçirilebilir. Bazı sistem işlevlerinin söz dizimi biraz farklı olabilir, ancak gerekli değişiklikler otomatikleştirilebilir.
Azure Synapse'te eşdeğeri olmayan Teradata sistem işlevleri veya rastgele kullanıcı tanımlı işlevler için bu işlevleri bir hedef ortam dili kullanarak yeniden kodlayın. Azure Synapse, kullanıcı tanımlı işlevleri uygulamak için Transact-SQL dilini kullanır.
Saklı yordamlar
Çoğu modern veritabanı ürünü, yordamların veritabanında depolanmasını destekler. Teradata bu amaçla SPL dilini sağlar. Saklı yordam genellikle hem SQL deyimlerini hem de yordam mantığını içerir ve veri veya durum döndürür.
Azure Synapse, T-SQL kullanarak saklı yordamları destekler, bu nedenle geçirilen saklı yordamları bu dilde yeniden kodlamanız gerekir.
Tetikleyiciler
Azure Synapse tetikleyici oluşturmayı desteklemez, ancak Azure Data Factory kullanılarak tetikleyici oluşturma uygulanabilir.
Sıralamalar
Azure Synapse dizileri Teradata'ya benzer bir şekilde işler ve bir seride sonraki sıra numarasını oluşturan IDENTITY sütunlarını veya SQL kodunu kullanarak dizileri uygulayabilirsiniz. Sıra, birincil anahtarlar için vekil anahtar değerleri olarak kullanabileceğiniz benzersiz sayısal değerler sağlar.
Teradata ortamından meta verileri ve verileri ayıklama
Veri Tanımı Dili (DDL) oluşturma
ANSI SQL standardı, Veri Tanımı Dili (DDL) komutlarının temel söz dizimini tanımlar. ve CREATE VIEWgibi CREATE TABLE bazı DDL komutları hem Teradata hem de Azure Synapse için ortaktır, ancak dizin oluşturma, tablo dağıtımı ve bölümleme seçenekleri gibi uygulamaya özgü özellikler de sağlar.
Azure Synapse'te eşdeğer tanımlar elde etmek için mevcut Teradata CREATE TABLE ve CREATE VIEW betikleri düzenleyebilirsiniz. Bunu yapmak için değiştirilmiş veri türlerini kullanmanız ve gibi FALLBACKTeradata'ya özgü yan tümceleri kaldırmanız veya değiştirmeniz gerekebilir.
Ancak, mevcut Teradata ortamındaki tabloların ve görünümlerin geçerli tanımlarını belirten tüm bilgiler sistem kataloğu tablolarında tutulur. Bu tablolar, güncel ve eksiksiz olması garanti edilen bu bilgilerin en iyi kaynağıdır. Kullanıcı tarafından korunan belgeler geçerli tablo tanımlarıyla eşitlenmemiş olabilir.
Teradata ortamında sistem kataloğu tabloları geçerli tabloyu ve görünüm tanımını belirtir. Kullanıcı tarafından korunan belgelerden farklı olarak, sistem kataloğu bilgileri her zaman eksiksizdir ve geçerli tablo tanımlarıyla eşitlenir. gibi DBC.ColumnsVkatalog görünümlerini kullanarak sistem kataloğu bilgilerine erişerek Azure Synapse'te eşdeğer tablolar oluşturan DDL deyimleri oluşturabilirsiniz CREATE TABLE .
Bahşiş
Azure Synapse için ve CREATE VIEW DDL oluşturma CREATE TABLE işlemini otomatikleştirmek için mevcut Teradata meta verilerini kullanın.
Benzer sonuçlar elde etmek için sistem kataloğu bilgilerini işleyen üçüncü taraf geçiş ve ETL araçlarını da kullanabilirsiniz.
Teradata'dan veri ayıklama
Temel Teradata Sorgusu (BTEQ), Teradata FastExport veya Teradata Parallel Transporter (TPT) gibi standart Teradata yardımcı programlarını kullanarak Teradata tablolarındaki ham tablo verilerini CSV dosyaları gibi düz sınırlandırılmış dosyalara ayıklayabilirsiniz. Tablo verilerini mümkün olduğunca verimli bir şekilde ayıklamak için TPT kullanın. TPT, en yüksek aktarım hızına ulaşmak için birden çok paralel FastExport akışı kullanır.
Bahşiş
En verimli veri ayıklaması için Teradata Paralel Taşıyıcı'yı kullanın.
TPT'ye doğrudan Azure Data Factory'den çağrı yapma. Bu, Azure ortamındaki bir VM içinde çalışan Teradata şirket içi örneklerinin ve Teradata örneklerinin veri geçişi için önerilen yaklaşımdır.
Ayıklanan veri dosyaları CSV, İyileştirilmiş Satır Sütunlu (ORC) veya Parquet biçiminde sınırlandırılmış metin içermelidir.
Teradata ortamından verileri ve ETL'yi geçirme hakkında daha fazla bilgi için bkz . Teradata geçişleri için veri geçişi, ETL ve yükleme.
Teradata geçişleri için performans önerileri
Performans iyileştirme hedefi, Azure Synapse'e geçiş sonrasında aynı veya daha iyi veri ambarı performansıdır.
Bahşiş
Geçişin başlangıcında Azure Synapse'teki ayarlama seçenekleri hakkında bilgi sahibi olun.
Performans ayarlama yaklaşımındaki farklılıklar
Bu bölümde, Teradata ile Azure Synapse arasındaki düşük düzey performans ayarlama uygulaması farkları vurgulanmaktadır.
Veri dağıtım seçenekleri
Performans için Azure Synapse, çok düğümlü mimariyle tasarlanmıştır ve paralel işleme kullanır. Azure Synapse'te tek tek tablo performansını iyileştirmek için deyimini DISTRIBUTION kullanarak deyimlerde CREATE TABLE bir veri dağıtım seçeneği tanımlayabilirsiniz. Örneğin, belirleyici bir karma işlevi kullanarak tablo satırlarını işlem düğümleri arasında dağıtan karma dağıtılmış bir tablo belirtebilirsiniz. Amaç, sorgu yürütülürken düğümler arasında taşınan veri miktarını azaltmaktır.
Büyük tablodan büyük tabloya birleşimler için karma bir veya ideal olarak her iki tabloyu birleştirme sütunlarından birinde dağıtın. Bu, eşit bir dağıtım sağlamaya yardımcı olmak için çok çeşitli değerlere sahiptir. Birleştirilecek veri satırları aynı işleme düğümünde birlikte bulunduğundan birleştirme işlemini yerel olarak gerçekleştirin.
Azure Synapse, küçük tablo çoğaltması aracılığıyla küçük bir tablo ile büyük bir tablo arasında yerel birleştirmeleri de destekler. Örneğin, yıldız şema modeli içinde küçük bir boyut tablosu ve büyük bir olgu tablosu düşünün. Azure Synapse, büyük tablonun herhangi bir birleştirme anahtarının değerinin eşleşen, yerel olarak kullanılabilir bir boyut satırına sahip olduğundan emin olmak için küçük boyut tablosunu tüm düğümler arasında çoğaltabilir. Boyut tablosu çoğaltmasının yükü, küçük bir boyut tablosu için nispeten düşüktür. Büyük boyut tabloları için karma dağıtım yaklaşımı daha uygundur. Veri dağıtım seçenekleri hakkında daha fazla bilgi için bkz. Çoğaltılmış tabloları kullanmaya yönelik tasarım kılavuzu ve Dağıtılmış tablolar tasarlama kılavuzu.
Veri dizini oluşturma
Azure Synapse, Teradata'da uygulanan dizin oluşturma seçeneklerinden farklı, kullanıcı tanımlı birkaç dizin oluşturma seçeneğini destekler. Azure Synapse'teki farklı dizin oluşturma seçenekleri hakkında daha fazla bilgi için bkz . Ayrılmış SQL havuzu tablolarındaki dizinler.
Kaynak Teradata ortamındaki mevcut dizinler, Azure Synapse ortamında dizin oluşturmak için veri kullanımına ve aday sütunlara ilişkin yararlı bir gösterge sağlar.
Veri bölümleme
Kurumsal veri ambarında olgu tabloları milyarlarca satır içerebilir. Bölümleme, işlenen veri miktarını azaltmak için bu tabloları ayrı bölümlere ayırarak bakım ve sorgu performansını iyileştirir. Azure Synapse'te deyimi, CREATE TABLE bir tablonun bölümleme belirtimini tanımlar. Yalnızca çok büyük tabloları bölümleyip her bölümün en az 60 milyon satır içerdiğini doğrulayın.
Bölümleme için tablo başına yalnızca bir alan kullanabilirsiniz. Birçok sorgu tarihe veya tarih aralığına göre filtrelendiğinden bu alan genellikle bir tarih alanıdır. Tabloyu yeni bir dağıtımla yeniden oluşturmak için (CTAS) deyimini kullanarak ilk yüklemeden CREATE TABLE AS sonra bir tablonun bölümlemini değiştirmek mümkündür. Azure Synapse'te bölümleme hakkında ayrıntılı bilgi için bkz . Ayrılmış SQL havuzunda tabloları bölümleme.
Veri tablosu istatistikleri
ETL/ELT işlerine yönelik bir istatistik adımı oluşturarak veri tablolarındaki istatistiklerin güncel olduğundan emin olmanız gerekir.
Veri yükleme için PolyBase veya COPY INTO
PolyBase , paralel yükleme akışları kullanarak büyük miktarlardaki verilerin bir veri ambarı için verimli bir şekilde yüklenmesini destekler. Daha fazla bilgi için bkz . PolyBase veri yükleme stratejisi.
COPY INTO ayrıca yüksek aktarım hızına sahip veri alımını destekler ve:
Klasör ve alt klasörlerdeki tüm dosyalardan veri alma.
Aynı depolama hesabındaki birden çok konumdan veri alma. Virgülle ayrılmış yollar kullanarak birden çok konum belirtebilirsiniz.
Azure Data Lake Depolama (ADLS) ve Azure Blob Depolama.
CSV, PARQUET ve ORC dosya biçimleri.
İş yükü yönetimi
Karışık iş yüklerinin çalıştırılması, meşgul sistemlerde kaynak zorluklarına neden olabilir. Başarılı bir iş yükü yönetim şeması kaynakları etkili bir şekilde yönetir, yüksek verimli kaynak kullanımı sağlar ve yatırım getirisini (ROI) en üst düzeye çıkarır. İş yükü sınıflandırması, iş yükü önemi ve iş yükü yalıtımı , iş yükünün sistem kaynaklarını nasıl kullandığı üzerinde daha fazla denetim sağlar.
İş yükü yönetimi kılavuzunda iş yükünü analiz etme, iş yükü önemini yönetme ve izleme teknikleri ve bir kaynak sınıfını iş yükü grubuna dönüştürme adımları açıklanmaktadır. geçerli kaynakların verimli bir şekilde kullanıldığından emin olmak için iş yükünü izlemek için DMV'lerdeki Azure portalını ve T-SQL sorgularını kullanın.
Sonraki adımlar
Teradata geçişi için ETL ve yükleme hakkında bilgi edinmek için bu serinin sonraki makalesine bakın: Veri geçişi, ETL ve Teradata geçişleri için yükleme.