Azure Synapse Analytics'te dosya bağlama/kaldırma API'lerine giriş
Azure Synapse Studio ekibi, Microsoft Spark Yardımcı Programları (mssparkutils) paketinde iki yeni bağlama/çıkarma API'sini oluşturmştu. Bu API'leri, tüm çalışan düğümlere (sürücü düğümü ve çalışan düğümleri) uzak depolama (Azure Blob Depolama veya Azure Data Lake Storage 2. Nesil) eklemek için kullanabilirsiniz. Depolama gerçekleştikten sonra yerel dosya API'sini kullanarak verilere yerel dosya sisteminde depolanmış gibi erişebilirsiniz. Daha fazla bilgi için bkz . Microsoft Spark Yardımcı Programlarına Giriş.
Makale, çalışma alanınızda bağlama/çıkarma API'lerini nasıl kullanacağınızı gösterir. Şunları öğreneceksiniz:
- Data Lake Storage 2. Nesil veya Blob Depolama bağlama.
- Yerel dosya sistemi API'sini kullanarak bağlama noktası altındaki dosyalara erişme.
- API kullanarak bağlama noktası altındaki dosyalara
mssparktuils fserişme. - Spark okuma API'sini kullanarak bağlama noktası altındaki dosyalara erişme.
- Bağlama noktasını çıkarma.
Uyarı
Azure dosya paylaşımı bağlaması geçici olarak devre dışı bırakıldı. Sonraki bölümde açıklandığı gibi bunun yerine Data Lake Storage 2. Nesil veya Azure Blob Depolama bağlamayı kullanabilirsiniz.
Azure Data Lake Storage 1. Nesil depolama desteklenmez. Bağlama API'lerini kullanmadan önce Azure Data Lake Storage 1. Nesil 2. Nesil geçiş kılavuzunu izleyerek Data Lake Storage 2. Nesil geçirebilirsiniz.
Depolamayı bağlama
Bu bölümde örnek olarak adım adım Data Lake Storage 2. Nesil bağlama işlemi gösterilmektedir. Blob Depolama bağlama işlemi benzer şekilde çalışır.
Örnekte adlı storegen2bir Data Lake Storage 2. Nesil hesabınız olduğu varsayılır. Hesabın Spark havuzunuzda bağlamak /test istediğiniz adlı mycontainer bir kapsayıcısı vardır.

adlı mycontainermssparkutils kapsayıcıyı bağlamak için öncelikle kapsayıcıya erişim izniniz olup olmadığını denetlemeniz gerekir. Şu anda Azure Synapse Analytics tetikleyici bağlama işlemi için üç kimlik doğrulama yöntemini destekler: LinkedService, accountKeyve sastoken.
Bağlı hizmet kullanarak bağlama (önerilir)
Bağlı hizmet aracılığıyla bir tetikleyici bağlaması öneririz. Gizli dizi veya kimlik doğrulama değerlerinin kendisini depolamadığından bu mssparkutils yöntem güvenlik sızıntılarını önler. Bunun yerine, mssparkutils uzak depolamadan blob verileri istemek için her zaman bağlı hizmetten kimlik doğrulama değerlerini getirir.
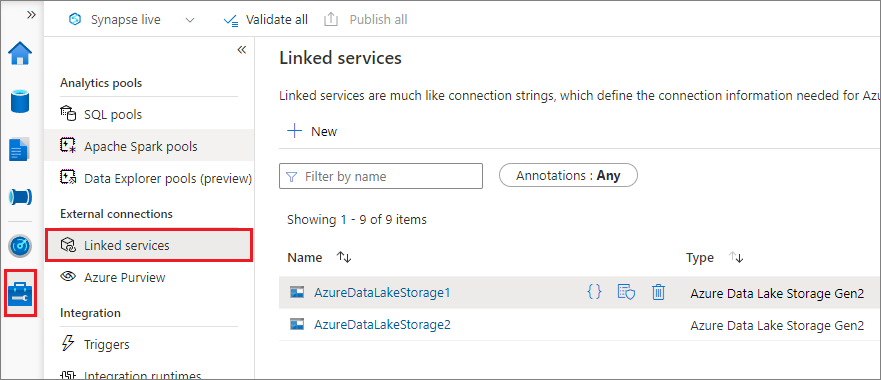
Data Lake Storage 2. Nesil veya Blob Depolama için bağlı bir hizmet oluşturabilirsiniz. Azure Synapse Analytics şu anda bağlı bir hizmet oluşturduğunuzda iki kimlik doğrulama yöntemini destekler:
Hesap anahtarı kullanarak bağlı hizmet oluşturma
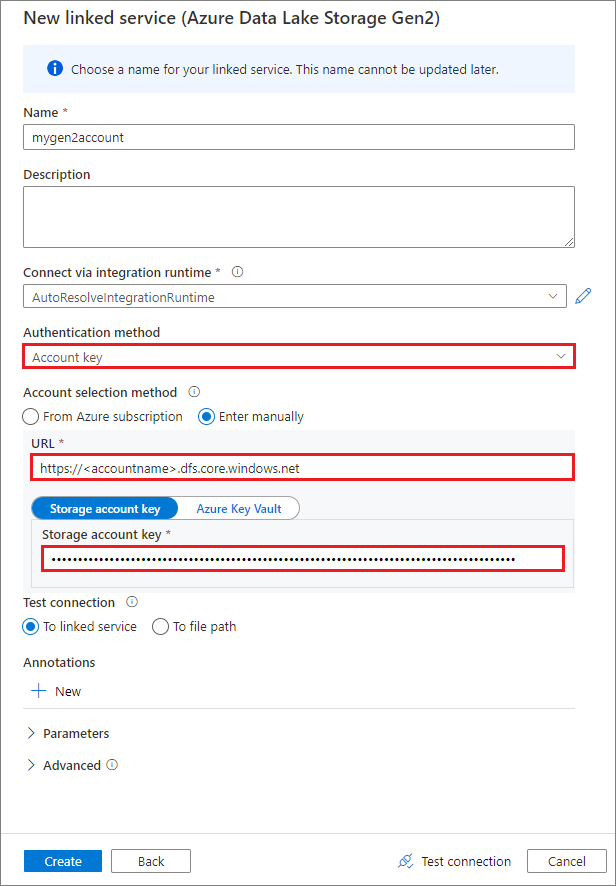
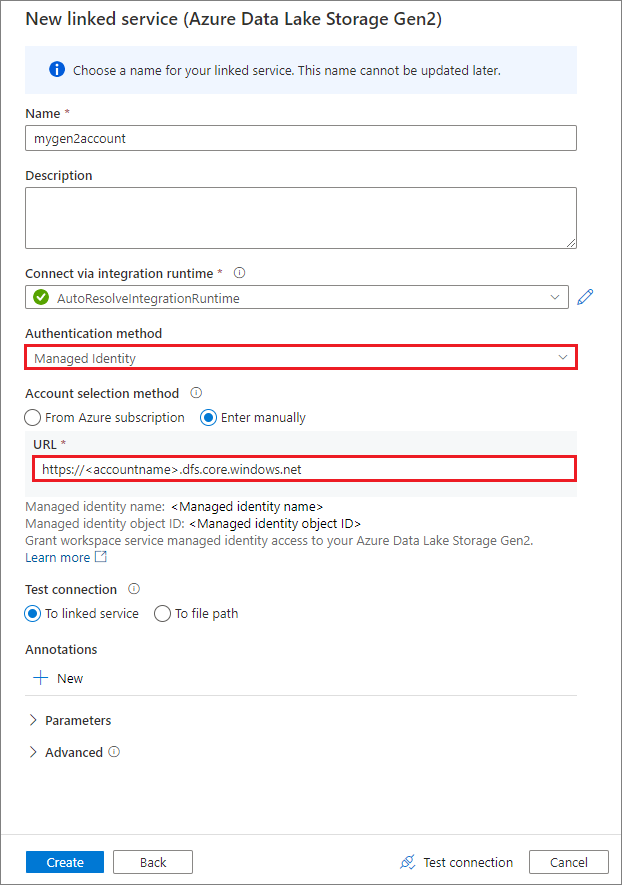
Yönetilen kimlik kullanarak bağlı hizmet oluşturma
Önemli
- Azure Data Lake Storage 2. Nesil için yukarıda oluşturulan Bağlı Hizmet yönetilen özel uç nokta (dfs URI ile) kullanıyorsa, iç fsspec/adlfs kodunu Azure Blob Depolama nBlobServiceClient arabirimi.
- İkincil yönetilen özel uç noktanın doğru yapılandırılmaması durumunda ServiceRequestError: [storageaccountname].blob.core.windows.net:443 ssl:True [Ad veya hizmet bilinmiyor] konağına bağlanılamıyor gibi bir hata iletisi görürsünüz
Dekont
Kimlik doğrulama yöntemi olarak yönetilen kimlik kullanarak bağlı bir hizmet oluşturursanız, çalışma alanı MSI dosyasının bağlı kapsayıcının Depolama Blob Verileri Katkıda Bulunanı rolüne sahip olduğundan emin olun.
Bağlı hizmeti başarıyla oluşturduktan sonra aşağıdaki Python kodunu kullanarak kapsayıcıyı Spark havuzunuza kolayca bağlayabilirsiniz:
mssparkutils.fs.mount(
"abfss://mycontainer@<accountname>.dfs.core.windows.net",
"/test",
{"LinkedService":"mygen2account"}
)
Dekont
Kullanılamıyorsa içeri aktarmanız mssparkutils gerekebilir:
from notebookutils import mssparkutils
Bağlama parametreleri:
- fileCacheTimeout: Bloblar varsayılan olarak 120 saniye boyunca yerel geçici klasörde önbelleğe alınır. Bu süre boyunca blobfuse dosyanın güncel olup olmadığını denetlemez. parametresi varsayılan zaman aşımı süresini değiştirecek şekilde ayarlanabilir. Birden çok istemci dosyaları aynı anda değiştirdiğinde, yerel ve uzak dosyalar arasındaki tutarsızlıkları önlemek için önbellek süresini kısaltmanızı, hatta 0 olarak değiştirmenizi ve her zaman sunucudan en son dosyaları almanızı öneririz.
- zaman aşımı: Bağlama işlemi zaman aşımı varsayılan olarak 120 saniyedir. parametresi varsayılan zaman aşımı süresini değiştirecek şekilde ayarlanabilir. Çok fazla yürütücü olduğunda veya bağlama zaman aşımına uğradıysa değeri artırmanızı öneririz.
- scope: Kapsam parametresi bağlamanın kapsamını belirtmek için kullanılır. Varsayılan değer "job" değeridir. Kapsam "iş" olarak ayarlanırsa bağlama yalnızca geçerli kümede görünür. Kapsam "çalışma alanı" olarak ayarlanırsa, bağlama geçerli çalışma alanında tüm not defterleri tarafından görülebilir ve bağlama noktası yoksa otomatik olarak oluşturulur. Bağlama noktasını sökmek için aynı parametreleri çıkarma API'sine ekleyin. Çalışma alanı düzeyi bağlama yalnızca bağlı hizmet kimlik doğrulaması için desteklenir.
Aşağıdaki gibi parametreleri kullanabilirsiniz:
mssparkutils.fs.mount(
"abfss://mycontainer@<accountname>.dfs.core.windows.net",
"/test",
{"linkedService":"mygen2account", "fileCacheTimeout": 120, "timeout": 120}
)
Hangi kimlik doğrulama yöntemini kullanırsanız kullanın kök klasör bağlamanızı önermeyiz.
Paylaşılan erişim imzası belirteci veya hesap anahtarı aracılığıyla bağlama
Bağlı hizmet aracılığıyla bağlamaya ek olarak, mssparkutils bir hesap anahtarının veya paylaşılan erişim imzası (SAS) belirtecinin hedefi bağlamak için parametre olarak açıkça geçirilmesini destekler.
Güvenlik nedeniyle, hesap anahtarlarını veya SAS belirteçlerini Azure Key Vault'ta depolamanızı öneririz (aşağıdaki örnek ekran görüntüsünde gösterildiği gibi). Daha sonra API'yi mssparkutil.credentials.getSecret kullanarak bunları alabilirsiniz. Daha fazla bilgi için bkz . Key Vault ve Azure CLI (eski) ile depolama hesabı anahtarlarını yönetme.
Örnek kod şu şekildedir:
from notebookutils import mssparkutils
accountKey = mssparkutils.credentials.getSecret("MountKV","mySecret")
mssparkutils.fs.mount(
"abfss://mycontainer@<accountname>.dfs.core.windows.net",
"/test",
{"accountKey":accountKey}
)
Dekont
Güvenlik nedeniyle kimlik bilgilerini kodda depolamayın.
mssparkutils fs API'sini kullanarak bağlama noktası altındaki dosyalara erişme
Bağlama işleminin temel amacı, müşterilerin yerel bir dosya sistemi API'sini kullanarak uzak depolama hesabında depolanan verilere erişmesine izin vermektir. Ayrıca API'yi bağlı bir yol ile parametre olarak kullanarak mssparkutils fs da verilere erişebilirsiniz. Burada kullanılan yol biçimi biraz farklıdır.
bağlama API'sini kullanarak Data Lake Storage 2. Nesil kapsayıcısını mycontainer bağladığınız /test varsayılır. Yerel dosya sistemi API'sini kullanarak verilere eriştiğiniz zaman yol biçimi şöyledir:
/synfs/{jobId}/test/{filename}
Doğru yolu elde etmek için bir mssparkutils.fs.getMountPath() kullanmanızı öneririz:
path = mssparkutils.fs.getMountPath("/test") # equals to /synfs/{jobId}/test
API'yi kullanarak mssparkutils fs verilere erişmek istediğinizde yol biçimi şöyledir:
synfs:/{jobId}/test/{filename}
Bu durumda, bağlı yolun bir parçası yerine şema olarak kullanıldığını görebilirsiniz synfs .
Aşağıdaki üç örnek kullanarak mssparkutils fsbağlama noktası yolu olan bir dosyaya nasıl erişeceğini gösterir. Örneklerde, 49 çağrısından mssparkutils.env.getJobId()aldığımız bir Spark iş kimliğidir.
Liste dizinleri:
mssparkutils.fs.ls("synfs:/49/test")Dosya içeriğini okuma:
mssparkutils.fs.head("synfs:/49/test/myFile.txt")Dizin oluşturma:
mssparkutils.fs.mkdirs("synfs:/49/test/newdir")
Spark okuma API'sini kullanarak bağlama noktası altındaki dosyalara erişme
Spark okuma API'sini kullanarak verilere erişmek için bir parametre sağlayabilirsiniz. Buradaki yol biçimi, API'yi mssparkutils fs kullandığınızda aynıdır:
synfs:/{jobId}/test/{filename}
Bağlı bir Data Lake Storage 2. Nesil depolama hesabından dosya okuma
Aşağıdaki örnekte, bir Data Lake Storage 2. Nesil depolama hesabının zaten bağlı olduğu varsayılır ve ardından bağlama yolunu kullanarak dosyayı okursunuz:
%%pyspark
df = spark.read.load("synfs:/49/test/myFile.csv", format='csv')
df.show()
Dekont
Bağlı hizmeti kullanarak depolamayı bağladığınızda, verilere erişmek için synfs şemasını kullanmadan önce spark bağlı hizmet yapılandırmasını her zaman açıkça ayarlamanız gerekir. Ayrıntılar için bağlı hizmetler içeren ADLS 2. Nesil depolamaya bakın.
Bağlı blob Depolama hesabından dosya okuma
Bir Blob Depolama hesabı bağladıysanız ve bu hesaba veya Spark API'sini kullanarak mssparkutils erişmek istiyorsanız, bağlama API'sini kullanarak kapsayıcıyı bağlamayı denemeden önce Spark yapılandırması aracılığıyla SAS belirtecini açıkça yapılandırmanız gerekir:
Tetikleyici bağlama sonrasında veya Spark API'sini kullanarak
mssparkutilsbir Blob Depolama hesabına erişmek için aşağıdaki kod örneğinde gösterildiği gibi Spark yapılandırmasını güncelleştirin. Spark yapılandırmasına yalnızca bağlandıktan sonra yerel dosya API'sini kullanarak erişmek istiyorsanız bu adımı atlayabilirsiniz.blob_sas_token = mssparkutils.credentials.getConnectionStringOrCreds("myblobstorageaccount") spark.conf.set('fs.azure.sas.mycontainer.<blobStorageAccountName>.blob.core.windows.net', blob_sas_token)Bağlı hizmeti oluşturun ve bağlı hizmeti
myblobstorageaccountkullanarak Blob Depolama hesabını bağlayın:%%spark mssparkutils.fs.mount( "wasbs://mycontainer@<blobStorageAccountName>.blob.core.windows.net", "/test", Map("LinkedService" -> "myblobstorageaccount") )Blob Depolama kapsayıcısını bağlayın ve ardından yerel dosya API'sinde bir bağlama yolu kullanarak dosyayı okuyun:
# mount the Blob Storage container, and then read the file by using a mount path with open("/synfs/64/test/myFile.txt") as f: print(f.read())Spark okuma API'sini aracılığıyla bağlı Blob Depolama kapsayıcısından verileri okuyun:
%%spark // mount blob storage container and then read file using mount path val df = spark.read.text("synfs:/49/test/myFile.txt") df.show()
Bağlama noktasını çıkarma
Bağlama noktanızı/test (bu örnekte) sökmek için aşağıdaki kodu kullanın:
mssparkutils.fs.unmount("/test")
Bilinen sınırlamalar
mssparkutils fs helpİşlev henüz bağlama/çıkarma bölümü hakkında açıklama eklemedi.Çıkarma mekanizması otomatik değildir. Uygulama çalıştırması tamamlandığında, disk alanını serbest bırakmak için bağlama noktasını çıkarabilmek için kodunuzda bir çıkarma API'sini açıkça çağırmanız gerekir. Aksi takdirde, uygulama çalıştırması tamamlandıktan sonra bağlama noktası düğümde bulunmaya devam eder.
Data Lake Storage 1. Nesil depolama hesabı bağlama işlemi şimdilik desteklenmiyor.