Azure Synapse Analytics'te sunucusuz SQL havuzu için maliyet yönetimi
Bu makalede, Azure Synapse Analytics'te sunucusuz SQL havuzu için maliyetleri nasıl tahmin edip yönetebileceğiniz açıklanır:
- Sorguyu oluşturmadan önce işlenen veri miktarını tahmin etme
- Bütçeyi ayarlamak için maliyet denetimi özelliğini kullanma
Azure Synapse Analytics'teki sunucusuz SQL havuzu maliyetlerinin Azure faturanızdaki aylık maliyetlerin yalnızca bir kısmı olduğunu anlayın. Diğer Azure hizmetlerini kullanıyorsanız, üçüncü taraf hizmetler de dahil olmak üzere Azure aboneliğinizde kullanılan tüm Azure hizmetleri ve kaynakları için faturalandırılırsınız. Bu makalede, Azure Synapse Analytics'te sunucusuz SQL havuzu için maliyetleri planlama ve yönetme işlemleri açıklanmaktadır.
İşlenen veriler
İşlenen veriler , sorgu çalıştırılırken sistemin geçici olarak depolandığı veri miktarıdır. İşlenen veriler aşağıdaki miktarlardan oluşur:
- Depolama alanından okunan veri miktarı. Bu tutar şunları içerir:
- Veriler okunurken veriler okunur.
- Meta verileri okurken okunan veriler (Parquet gibi meta veriler içeren dosya biçimleri için).
- Ara sonuçlardaki veri miktarı. Sorgu çalıştırılırken bu veriler düğümler arasında aktarılır. Uç noktanıza veri aktarımını sıkıştırılmamış biçimde içerir.
- Depolama alanına yazılan veri miktarı. Sonuç kümenizi depolama alanına aktarmak için CETAS kullanırsanız, yazılan veri miktarı CETAS'ın SELECT bölümü için işlenen veri miktarına eklenir.
Dosyaları depolama alanından okumak son derece iyileştirilmiştir. İşlemde şu işlemler kullanılır:
- Önceden hazırlama, okunan veri miktarına biraz ek yük getirebilir. Sorgu bir dosyanın tamamını okursa ek yük yoktur. Top N sorgularında olduğu gibi bir dosya kısmen okunursa, önceden hazırlama kullanılarak biraz daha fazla veri okunur.
- İyileştirilmiş virgülle ayrılmış değer (CSV) ayrıştırıcısı. CSV dosyalarını okumak için PARSER_VERSION='2.0' kullanırsanız depolama alanından okunan veri miktarı biraz artar. İyileştirilmiş bir CSV ayrıştırıcısı, dosyaları eşit boyuttaki öbekler halinde paralel olarak okur. Öbeklerin tam satır içermesi gerekmez. Tüm satırların ayrıştırıldığından emin olmak için, iyileştirilmiş CSV ayrıştırıcısı bitişik öbeklerin küçük parçalarını da okur. Bu işlem küçük miktarda ek yük ekler.
İstatistikler
Sunucusuz SQL havuzu sorgu iyileştiricisi, en iyi sorgu yürütme planlarını oluşturmak için istatistiklere dayanır. İstatistikleri el ile oluşturabilirsiniz. Aksi takdirde sunucusuz SQL havuzu bunları otomatik olarak oluşturur. Her iki durumda da istatistikler, sağlanan örnek hızında belirli bir sütunu döndüren ayrı bir sorgu çalıştırılarak oluşturulur. Bu sorguda işlenen ilişkili veri miktarı var.
Oluşturulan istatistiklerden yararlanabilecek aynı sorguyu veya başka bir sorguyu çalıştırırsanız, mümkünse istatistikler yeniden kullanılır. İstatistik oluşturma için işlenen ek veri yoktur.
Parquet sütunu için istatistikler oluşturulduğunda dosyalardan yalnızca ilgili sütun okunur. CSV sütunu için istatistikler oluşturulduğunda, tüm dosyalar okunur ve ayrıştırılır.
Yuvarlama
İşlenen veri miktarı sorgu başına en yakın MB'a yuvarlanır. Her sorguda işlenen en az 10 MB veri vardır.
İşlenen veriler şunları içermez:
- Sunucu düzeyinde meta veriler (oturum açma bilgileri, roller ve sunucu düzeyinde kimlik bilgileri gibi).
- Uç noktanızda oluşturduğunuz veritabanları. Bu veritabanları yalnızca meta verileri (kullanıcılar, roller, şemalar, görünümler, satır içi tablo değerli işlevler [TVF'ler], saklı yordamlar, veritabanı kapsamlı kimlik bilgileri, dış veri kaynakları, dış dosya biçimleri ve dış tablolar gibi) içerir.
- Şema çıkarımı kullanırsanız, sütun adlarını ve veri türlerini çıkarsamak için dosya parçaları okunur ve okunan veri miktarı işlenen veri miktarına eklenir.
- Veri tanımı dili (DDL) deyimleri; create STATISTICS deyimi dışında, belirtilen örnek yüzdesine göre depolama alanından verileri işler.
- Yalnızca meta veri sorguları.
İşlenen veri miktarını azaltma
Verilerinizi bölümleyerek ve Parquet gibi sıkıştırılmış sütun tabanlı bir biçime dönüştürerek işlenen sorgu başına veri miktarınızı iyileştirebilir ve performansı geliştirebilirsiniz.
Örnekler
Üç tablo düşünün.
- population_csv tablosu 5 TB CSV dosyası tarafından desteklenir. Dosyalar beş eşit boyutlu sütun halinde düzenlenmiştir.
- population_parquet tablosu, population_csv tablosuyla aynı verilere sahiptir. 1 TB Parquet dosyasıyla desteklenir. Veriler Parquet biçiminde sıkıştırıldığından bu tablo öncekinden daha küçüktür.
- very_small_csv tablosu 100 KB CSV dosyası tarafından desteklenir.
Sorgu 1: SELECT SUM(population) FROM population_csv
Bu sorgu, popülasyon sütununun değerlerini almak için tüm dosyaları okur ve ayrıştırıyor. Düğümler bu tablonun parçalarını işler ve her parçanın popülasyon toplamı düğümler arasında aktarılır. Son toplam uç noktanıza aktarılır.
Bu sorgu 5 TB verinin yanı sıra parça toplamlarını aktarmak için küçük bir ek yük işler.
Sorgu 2: SELECT SUM(population) FROM population_parquet
Parquet gibi sıkıştırılmış ve sütun tabanlı biçimleri sorguladığınızda, sorgu 1'e göre daha az veri okunur. Sunucusuz SQL havuzu dosyanın tamamı yerine tek bir sıkıştırılmış sütunu okuduğundan bu sonucu görürsünüz. Bu durumda 0,2 TB okunur. (Her birinde eşit boyutta beş sütun 0,2 TB'dir.) Düğümler bu tablonun parçalarını işler ve her parçanın popülasyon toplamı düğümler arasında aktarılır. Son toplam uç noktanıza aktarılır.
Bu sorgu 0,2 TB artı parça toplamlarını aktarmak için küçük miktarda ek yükü işler.
Sorgu 3: SELECT * FROM population_parquet
Bu sorgu tüm sütunları okur ve tüm verileri sıkıştırılmamış biçimde aktarır. Sıkıştırma biçimi 5:1 ise, sorgu 1 TB okuduğu ve 5 TB sıkıştırılmamış verileri aktardığı için 6 TB işler.
Sorgu 4: SELECT COUNT(*) FROM very_small_csv
Bu sorgu tüm dosyaları okur. Bu tablo için depolamadaki dosyaların toplam boyutu 100 KB'tır. Düğümler bu tablonun parçalarını işler ve her parçanın toplamı düğümler arasında aktarılır. Son toplam uç noktanıza aktarılır.
Bu sorgu 100 KB'tan biraz daha fazla veri işler. Bu sorgu için işlenen veri miktarı, bu makalenin Yuvarlama bölümünde belirtildiği gibi 10 MB'a yuvarlandı.
Maliyet denetimi
Sunucusuz SQL havuzundaki maliyet denetimi özelliği işlenen veri miktarı için bütçe ayarlamanıza olanak tanır. Bütçeyi TB cinsinden bir günde, haftada ve ayda işlenen veri miktarı olarak ayarlayabilirsiniz. Aynı zamanda bir veya birden fazla bütçe ayarlayabilirsiniz. Sunucusuz SQL havuzunun maliyet denetimini yapılandırmak için Synapse Studio veya T-SQL kullanabilirsiniz.
Synapse Studio'da sunucusuz SQL havuzu için maliyet denetimini yapılandırma
Synapse Studio'da sunucusuz SQL havuzu için maliyet denetimini yapılandırmak için soldaki menüde Öğeyi yönet'e gidin ve Analiz havuzları'nın altında SQL havuzu öğesini seçin. Sunucusuz SQL havuzunun üzerine geldiğinizde, maliyet denetimi için bir simge göreceksiniz; bu simgeye tıklayın.
Maliyet denetimi simgesine tıkladığınızda yan çubuk görüntülenir:
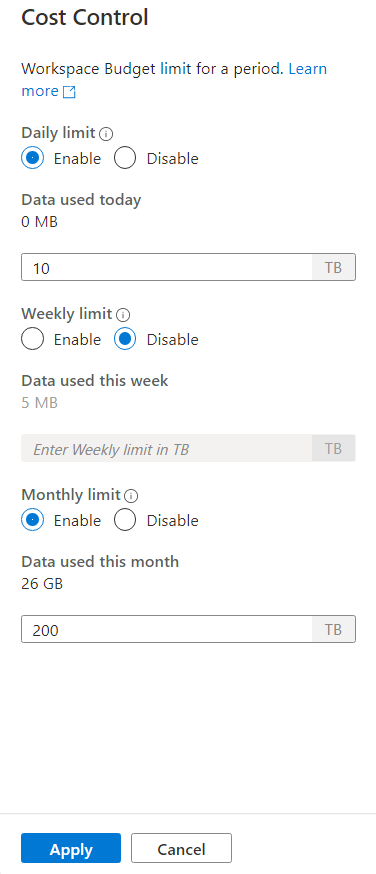
Bir veya daha fazla bütçe ayarlamak için, metin kutusuna tamsayı değerini girmek yerine, ayarlamak istediğiniz bütçe için radyo düğmesini etkinleştir'e tıklayın. Değerin birimi TB'ler'dir. İstediğiniz bütçeleri yapılandırdıktan sonra yan çubuğun altındaki Uygula düğmesine tıklayın. İşte bu kadar, bütçeniz ayarlandı.
T-SQL'de sunucusuz SQL havuzu için maliyet denetimini yapılandırma
T-SQL'de sunucusuz SQL havuzu için maliyet denetimini yapılandırmak için aşağıdaki saklı yordamlardan birini veya daha fazlasını yürütmeniz gerekir.
sp_set_data_processed_limit
@type = N'daily',
@limit_tb = 1
sp_set_data_processed_limit
@type= N'weekly',
@limit_tb = 2
sp_set_data_processed_limit
@type= N'monthly',
@limit_tb = 3334
Geçerli yapılandırmayı görmek için aşağıdaki T-SQL deyimini yürütür:
SELECT * FROM sys.configurations
WHERE name like 'Data processed %';
Geçerli gün, hafta veya ay içinde ne kadar veri işlendiğini görmek için aşağıdaki T-SQL deyimini yürütebilirsiniz:
SELECT * FROM sys.dm_external_data_processed
Maliyet denetiminde tanımlanan sınırları aşma
Sorgu yürütme sırasında herhangi bir sınırın aşılması durumunda sorgu sonlandırılamaz.
Sınır aşıldığında, yeni sorgu, dönemle ilgili ayrıntıları, o döneme ait tanımlı sınırı ve o dönem için işlenen verileri içeren hata iletisiyle reddedilir. Örneğin, haftalık sınırın 1 TB olarak ayarlandığı ve aşıldığı yeni sorgunun yürütülmesi durumunda hata iletisi şu şekilde olur:
Query is rejected because SQL Serverless budget limit for a period is exceeded. (Period = Weekly: Limit = 1 TB, Data processed = 1 TB))
Sonraki adımlar
Sorgularınızı performans açısından iyileştirmeyi öğrenmek için bkz. Sunucusuz SQL havuzu için en iyi yöntemler.