Örnek olay incelemesi: Hadoop dağıtılmış dosya sistemi (HDFS)
MapReduce programlama modeli, hesaplama işlerinin iki işlev doğrultusunda yapılandırılmasını sağlar: eşleme ve azaltma. Giriş, MapReduce'a anahtar-değer çifti olarak iletilir ve ardından bir eşleme işlevi aracılığıyla işlenip bir azaltma işlevine geçirilir. Azaltma işlemi de yine anahtar-değer çifti biçiminde bir sonuç üretir. MapReduce, çok sayıda eşleme ve azaltma işlemi örneğini büyük bir hesaplama kümesi genelinde paralel bir şekilde yürütecek şekilde tasarlanmıştır. MapReduce programlama modeli, daha sonraki bir modülde ayrıntılı bir şekilde ele alınmıştır.
MapReduce programlama modeli, tek bir ad alanı içindeki kümenin tüm düğümlerinde kullanılabilir durumda olan bir dağıtılmış dosya sistemi olduğunu kabul eder ve dağıtılmış dosya sistemi (DFS) de bu noktaya devreye girer. DFS, MapReduce kümesinin düğümleriyle aynı konumda bulunur. DFS, MapReduce ile birlikte çalışacak şekilde tasarlanmıştır ve MapReduce kümesinin tamamı için tek bir ad alanı tutar.
MapReduce hizmetinin açık kaynak sürümü olan Apache Hadoop2, büyük veri ortamlarında çok popülerdir. HDFS, açık kaynak bir DFS örneğidir. HDFS, MapReduce programlama modelinin gereksinimlerini karşılamaya yönelik dağıtılmış, ölçeklenebilir ve hataya dayanıklı bir dosya sistemi olarak tasarlanmıştır. Video 4.12'de HDFS hakkında bilgilere yer verilmiştir.
HDFS'nin POSIX uyumlu olmadığını ve tek başına bağlanabilen bir dosya sistemi olarak kabul edilmediğini lütfen unutmayın. HDFS'ye genellikle HDFS istemcileri aracılığıyla veya Hadoop kitaplıklarından uygulama programı arabirimi (API) çağrıları kullanılarak erişim sağlanır. Ancak HDFS için Kullanıcı Alanında Dosya Sistemi (FUSE) sürücüsünün geliştirilmesiyle UNIX benzeri işletim sistemlerine sanal cihaz olarak bağlanması mümkün hale gelmiştir.
HDFS mimarisi
Daha önce de belirtildiği gibi HDFS, düğüm kümesi üzerinde çalışacak şekilde tasarlanmış olan bir DFS sistemidir ve şu tasarım hedeflerine sahiptir:
- Tek, ortak, küme genelinde ad alanı
- Büyük dosyaları depolama imkanı (terabayt veya petabayt boyutunda)
- MapReduce programlama modeli desteği
- Bir kez yazılan, çok kez okunan veri erişim desenleri için akış veri erişimi
- Ticari donanımlarla sunulan yüksek kullanılabilirlik
Aşağıdaki şekilde bir HDFS kümesi gösterilmektedir:
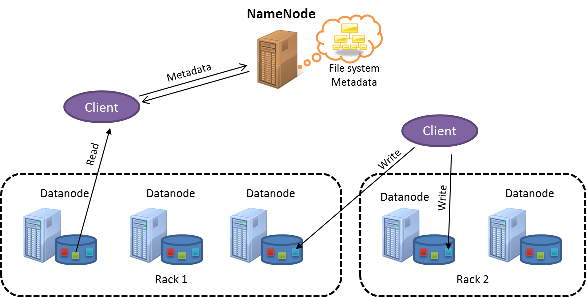
Şekil 1: HDFS mimarisi
HDFS, ana-alt öğe tasarımına sahiptir. Ana düğüm, NameNode olarak adlandırılır. NameNode, kümenin tamamına ait meta verileri yönetir ve HDFS üzerinde depolanan tüm dosyalar için tek bir ad alanı tutar. Alt düğümler, DataNode düğümleri olarak bilinir. DataNode düğümleri, yerel dosya sistemindeki düğümlerin içinde gerçek veri bloklarını depolar.
HDFS'deki dosyalar bloklara ayrılır (öbek olarak da adlandırılır) ve her biri varsayılan olarak 128 MB büyüklüğündedir. Diğer taraftan yerel dosya sistemleri genellikle 4 KB boyutunda bloklara sahiptir. HDFS, çok büyük dosyaları MapReduce işleriyle birlikte verimli bir şekilde işlenebilecek şekilde depolamak için tasarlandığından büyük blok boyutları kullanır.
MapReduce'taki tek bir eşleme görevi, varsayılan olarak tek bir HDFS bloğu üzerinde çalışacak şekilde yapılandırılmıştır ve bu sayede birden fazla eşleme görevi, aynı anda birden fazla HDFS bloğunu işleyebilir. Blok boyutunun çok küçük olması halinde çok sayıda eşleme görevinin kümenin düğümlerine dağıtılması gerekeceğinden işlem performansı olumsuz etkilenebilir. Diğer taraftan bloğun çok büyük olması, dosyayı paralel olarak işleyebilecek eşleme görevlerinin sayısının azalmasına ve aynı anda yürütülebilecek işlem sayısının düşmesine neden olur. HDFS'de blok boyutları dosya düzeyinde belirtilebilir ve bu sayede kullanıcılar, blok boyutlarını ayarlayarak ihtiyaç duydukları paralel işlem sayısına erişebilir. MapReduce ile HDFS arasındaki etkileşim ilerleyen modüllerde ayrıntılı bir şekilde anlatılmaktadır.
Ayrıca HDFS, ayrı düğümlerin hatalarına dayanıklı olarak tasarlandığından veri blokları düğümler arasında çoğaltılarak veri yedekliliği sağlanır. Bu işlem sonraki bölümlerde ayrıntılı bir şekilde anlatılmaktadır.
HDFS'de küme topolojisi
Hadoop kümeleri genellikle önceki modüllerde bahsedilen kalın ağaç topolojisi kullanılarak bağlanmış olan birden fazla sunucu rafından oluşan bir veri merkezine dağıtılır. HDFS bu nedenle küme topolojisi farkındalığına sahip olacak şekilde tasarlanmıştır ve bu durum, blok yerleşimi kararlarının performans ve hataya dayanıklılık etmenleri dikkate alınarak verilmesine yardımcı olur. Hadoop kümeleri genellikle raf başına 30-40 sunucuya, rafa özgü gigabit anahtara ve çekirdek anahtara veya yönlendiriciye giden yukarı bağlantıya sahiptir. Bant genişliği, veri merkezindeki raflar arasında paylaşılır. Bu durum aşağıdaki şekilde gösterilmiştir:
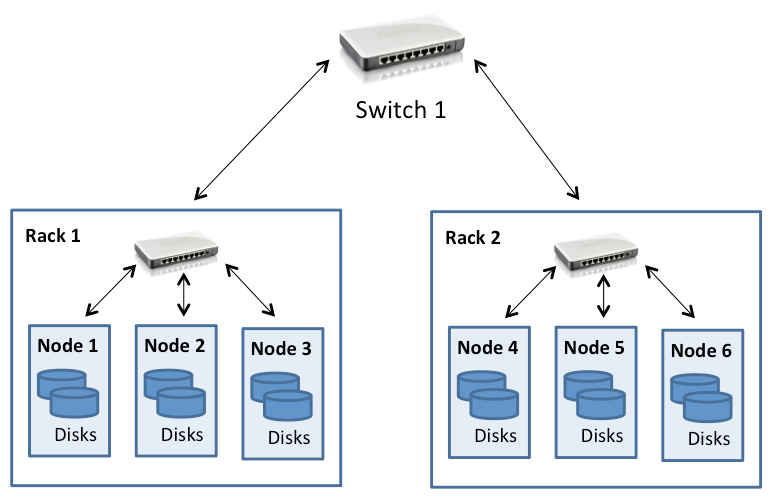
Şekil 2: HDFS kümesi topolojisi
Burada dikkat edilmesi gereken nokta, Hadoop'un bir rafta bulunan düğümlere ait toplam bant genişliğinin farklı raflarda bulunan düğümlere ait toplam bant genişliğinden daha yüksek olduğunu kabul etmesidir. Bu durum, Hadoop tasarımının veri erişimi ve çoğaltma yerleşimi (ilerleyen bölümlerde ele alınacaktır) özelliklerinde dikkate alınmıştır.
HDFS bir kümeye dağıtıldığında sistem yöneticileri her düğümü kümedeki belirli bir raf ile eşleyen bir topoloji açıklamasıyla yapılandırabilir. Ağ uzaklığı atlama cinsinden ölçülür ve her atlama, topolojideki bir bağlantıyı temsil eder. Hadoop, ağaç stilinde topoloji kullanıldığını ve iki düğüm arasındaki mesafenin en yakın ortak üst öğelerine olan mesafenin toplamı olduğunu kabul eder.
Şekil 2'de verilen örnekte Düğüm 1'in kendisi ile arasındaki mesafe sıfır atlamadır (iki işlemler aynı düğüm üzerinden iletişim kurmaktadır). Düğüm 1 ile Düğüm 2 arasındaki mesafe iki atlama, Düğüm 3 ile Düğüm 4 arasındaki mesafe ise dört atlamadır.
Aşağıdaki videoda HDFS'deki dosya okuma ve yazma işlemleri anlatılmaktadır.
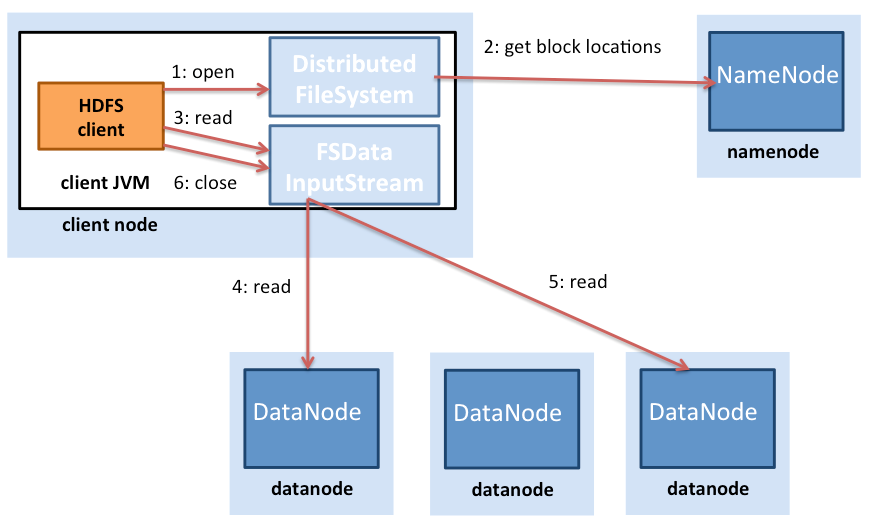
Şekil 3: HDFS'de dosya okumaları
Şekil 3'te HDFS'deki dosya okuma işlemleri gösterilmektedir. HDFS istemcisi (bir dosyaya erişmek isteyen varlık), bir dosya okumak için açıldığında öncelikle NameNode ile iletişime geçer. Daha sonra NameNode, istemciye dosyanın bloklarını bulunduğu konumların listesini sağlar. Hadoop ayrıca blokların farklı düğümlerde çoğaltıldığını kabul eder. Bu nedenle NameNode, belirli bir bloğun konumunu sağlarken istemciye en yakın olan bloğu bulur. Yer belirlenirken şu sıralama kullanılır (azalan düzende): istemciyle aynı düğümdeki bloklar, istemciyle aynı raftaki bloklar, istemciden farklı bir rafta bulunan bloklar.
Blok konumları belirlendikten sonra istemci her DataNode'a doğrudan bir bağlantı açar ve verileri DataNode'dan istemci işlemine akışla aktararak HDFS istemcisi veri bloğunda okuma işlemini çağırdığında gerçekleştirilir. Bu nedenle istemcinin hesaplama yapmaya başlayabilmesi için bloğun tamamının aktarılmasına gerek yoktur; hesaplama ve iletişim aralıklı olarak gerçekleştirilebilir. İstemci ilk bloğu okumayı tamamladıktan sonra bu işlemleri kalan bloklar için tekrarlar ve bu süreç istemci tüm blokları okuyup dosyayı kapatana kadar devam eder.
İstemcilerin veri almak için doğrudan DataNode ile iletişime geçmesi önemlidir. Bu sayede HDFS, eşzamanlı ve paralel veri okuma işlemleri için çok sayıda istemciyle ölçeklendirilebilir.
HDFS'de dosya yazma işlemleri, dosya okuma işlemlerinden farklıdır (Şekil 4). HDFS'ye dosya yazmak isteyen bir istemci öncelikle NameNode ile iletişime geçer ve ardından dosya oluşturma işlemi bilgilendirme yapar. NameNode, dosyanın var olup olmadığını kontrol eder ve istemcinin dosya oluşturma iznine sahip olduğunu doğrular. Denetimler başarılı olursa NameNode yeni dosya kaydı oluşturur.
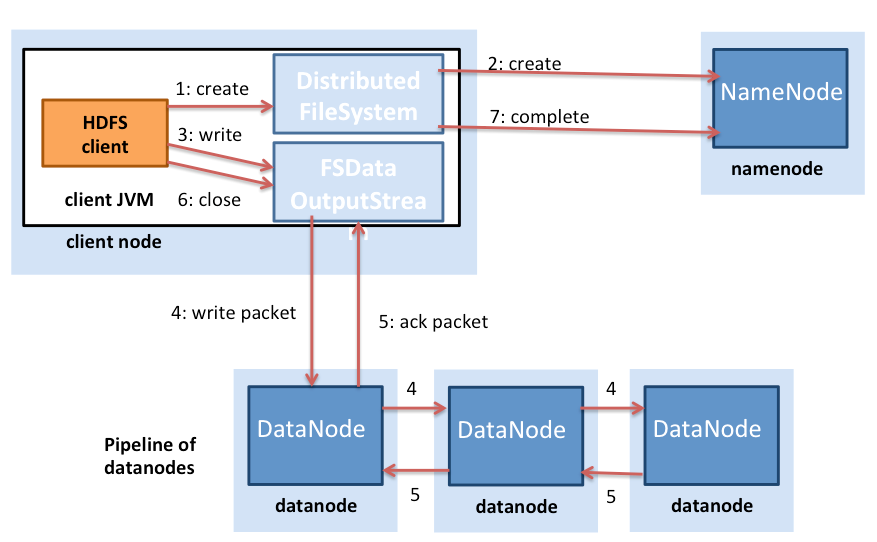
Şekil 4: HDFS'de dosya yazma işlemleri
İstemci daha sonra dosyayı sistem içindeki bir veri kuyruğuna yazar ve NameNode düğümünden kümedeki DataNode düğümleri üzerindeki blok konumlarını ister. Ardından sistem içindeki kuyrukta yer alan bloklar DataNode düğümlerine sırayla aktarılır. Blok ilk DataNode düğümüne yazıldıktan sonra çoğaltma oluşturmak için sırayla diğer DataNode düğümlerine iletilir. Bu sayede yazma işlemi sırasında bloklar çoğaltılmış olur. HDFS'nin tüm dosya çoğaltmaları DataNode düğümleri tarafından yazılana kadar istemciye yazma bildirimi iletmediğine dikkat edin (Şekil 4.28 Adım 5).
Hadoop, çoğaltma yerleşimi sırasında raf konumunu da dikkate alır. Veri blokları HDFS'de varsayılan olarak üç kez çoğaltılır. HDFS, ilk çoğaltmayı bloğu yazan istemciyle aynı düğüme yerleştirmeyi dener. HDFS kümesinde çalışan istemci işlemi olmaması halinde rastgele bir düğüm seçilir. İkinci çoğaltma, ilk çoğaltmadan farklı bir rafta bulunan bir düğüme (farklı rafa) yazılır. Bloğun üçüncü çoğaltması, ikinciyle aynı rafta bulunan başka bir rastgele düğüme yazılır. Kümedeki rastgele düğümlere ek çoğaltmalar yazılır ancak sistem, aynı rafa çok fazla çoğaltma yerleştirmekten kaçınmaya çalışır. Şekil 5'de HDFS'de üç kez çoğaltılan bir bloğun çoğaltmalarının yerleştirildiği yerler gösterilmiştir. HDFS'nin çoğaltma yerleştirme sisteminin altında yatan fikir, düğüm ve raf hatalarına dayanıklılık sağlamaktır. Örneğin elektrik veya ağ sorunları nedeniyle rafın tamamının çevrimdışı olması halinde istenen blok farklı bir rafta bulunabilir.
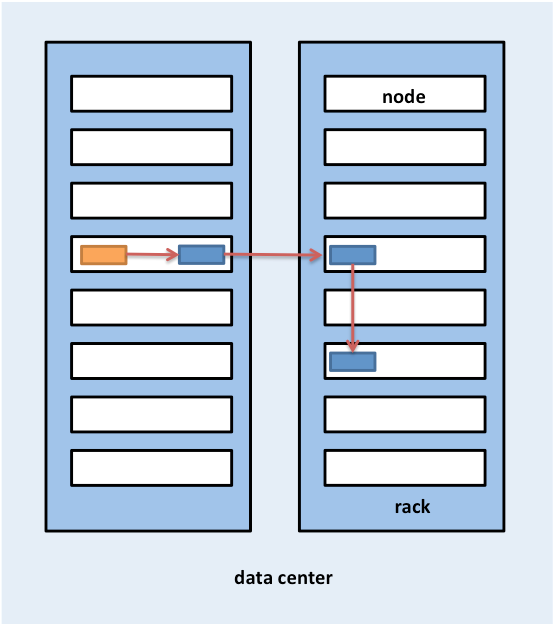
Şekil 5: HDFS'de üç çoğaltılmış blok için çoğaltma yerleşimi
Eşitleme: Semantik
HDFS semantiğinde bazı değişiklikler yapılmıştır. HDFS'nin önceki sürümlerinde katı sabit semantik kullanılmıştır. HDFS'nin önceki sürümlerinde bir dosya yazıldıktan sonra ek yazma işlemleri için yeniden açılması mümkün değildi. Dosyaları silmek mümkündü. Ancak güncel HDFS sürümleri, sınırlı da olsa ekleme işlemlerini desteklemektedir. HDFS'ye yazılmış olan ikili verilerin yerinde değiştirilmesine izin verilmediğinden bu konuda yine sınırlı destek sunulmaktadır.
HDFS'deki bu tasarım tercihinin nedeni, çoğu yaygın MapReduce iş yükünün bir kez yazma, çok kez okuma veri erişim düzenini kullanmasıdır. MapReduce, önceden tanımlanmış aşamalara sahip olan kısıtlı bir hesaplama modelidir ve MapReduce'taki azaltıcıların çıkışları, HDFS'de çıkış olarak bağımsız dosyalar yazmaktadır. HDFS, aynı anda birden fazla istemci için eşzamanlı ve hızlı okuma erişimi sunmayı amaçlamaktadır.
Tutarlılık modeli
HDFS, güçlü tutarlı bir dosya sistemidir. Her veri bloğu birden çok düğümde çoğaltılır ancak yazma işlemleri ancak veriler tüm çoğaltmalara yazıldıktan sonra başarılı olarak kabul edilir. Bu sayede tüm istemciler yazılan dosyayı anında görebilir ve dosya görünümü tüm istemcilerde aynı olur. Bir dosya ömrü boyunca yalnızca bir kez yazılmak üzere açılabileceğinden HDFS'nin sabit semantiği bu işlemi oldukça kolay hale getirir.
HDFS'de hataya dayanıklılık
HDFS'deki birincil hataya dayanıklılık mekanizması çoğaltmadır. Daha önce belirtildiği gibi HDFS'ye yazılan her blok varsayılan olarak üç kez çoğaltılır. İhtiyaç duyulması halinde kullanıcılar bu ayarı dosya düzeyinde değiştirebilir.
NameNode, DataNode düğümlerini sinyal mekanizmasıyla takip eder. Her DataNode, NameNode düğümüne düzenli aralıklarla sinyal iletileri (birkaç saniyede bir) gönderir. DataNode düğümlerinden birinin geçersiz olması halinde NameNode düğümüne sinyal gönderilmez. NameNode, atlanan sinyal iletilerinin sayısı belirli bir eşiğe ulaşırsa bir DataNode'un öldüğünü algılar . NameNode daha sonra ilgili DataNode düğümünü geçersiz olarak işaretler ve o DataNode düğümüne G/Ç isteklerini iletmez. İlgili DataNode üzerinde depolanan bloklar, diğer DataNode düğümlerine çoğaltılmış olmalıdır. Ayrıca NameNode, dosya sisteminde durum denetimi gerçekleştirerek gereğinden az çoğaltılan blokları bulur ve kümeyi yeniden dengeleme işlemi gerçekleştirerek istenen sayıdan daha az çoğaltmaya sahip olan bloklar için çoğaltma işlemi başlatır.
NameNode düğümünde hata olması dosya sisteminin tamamını etkileyeceğinden NameNode, HDFS sisteminin tek hata noktası (SPOF) olarak kabul edilir. NameNode, disk üzerinde dosya sisteminin yapısını depolayan iki veri yapısı tutar: görüntü dosyası ve düzenleme günlüğü. Görüntü dosyası, dosya sistemi meta verilerinin belirli bir zamandaki denetim noktasıdır. Düzenleme günlüğü ise görüntü dosyası oluşturulduktan sonra dosya sistemi meta verilerinde yapılan tüm işlemlerin yer aldığı bir günlüktür. Dosya sistemi meta verilerinde yapılan tüm değişiklikler, düzenleme günlüğüne yazılır. Düzenli aralıklarla düzenleme günlükleri ve görüntü dosyası birleştirilerek yeni bir görüntü dosyası anlık görüntüsü oluşturulur ve düzenleme günlüğü temizlenir. Ancak bir NameNode hatasında meta veriler kullanılamaz duruma gelir ve dosya meta verileri kaybolacağından NameNode'da bir disk hatası yıkıcı olur.
HDFS, NameNode düğümündeki meta verilerin yedeklenmesi için NameNode düğümündeki görüntü dosyalarını belirli aralıklarla kopyalayan ikincil bir NameNode oluşturulmasına imkan tanır. Bu kopyalar NameNode düğümünde veri kaybı yaşanması halinde dosya sisteminin kurtarılmasına yardımcı olur ancak NameNode düğümünün düzenleme günlüğünde yer alan son birkaç değişiklik kaybedilir. Hadoop'un son sürümlerinde NameNode düğümünde hata oluşması halinde otomatik olarak devreye girecek ikincil bir NameNode düğümünün oluşturulmasına yönelik çalışmalar yapılmaktadır.
Pratikte HDFS
HDFS, eşleme ve azaltma işlemleri için bir DFS sunarak Hadoop MapReduce işlerini destekleme amacıyla tasarlanmış olsa da büyük veri araçlarıyla da birçok farklı senaryoda kullanılmaktadır.
HDFS, Pig, Hive, HBase ve Giraph dahil olmak üzere Hadoop çerçevesi üzerinde oluşturulan çeşitli Apache projelerinde kullanılır. HDFS desteği GraphLab gibi diğer projelere de dahildir.
HDFS'nin temel avantajları şunlardır:
- MapReduce iş yükleri için yüksek bant genişliği: Büyük Hadoop kümelerinin (binlerce makine) HDFS kullanarak saniyede 1 terabayta kadar sürekli yazma yaptığı bilinmektedir.
- Yüksek güvenilirlik: Hataya dayanıklılık, HDFS'de birincil tasarım hedefidir. HDFS çoğaltması, özellikle disk ve sunucu hatalarının olasılığının önemli ölçüde arttığı büyük kümelerde yüksek güvenilirlik ve kullanılabilirlik sağlar.
- Bayt başına düşük maliyet: SAN gibi ayrılmış, paylaşılan bir disk çözümüyle karşılaştırıldığında, depolama işlem sunucularıyla birlikte kullanıldığından HDFS gigabayt başına daha az maliyetlidir. SAN seçeneğinde donanım hatalarını yönetmek için disk dizisi ve üst düzey kurumsal diskler gibi yönetilen altyapı için ek maliyetleri karşılamanız gerekir. HDFS, ticari donanımlarla çalışacak şekilde tasarlanmıştır ve hata dayanıklılığı için yedeklilik, yazılım düzeyinde sağlanır.
- Ölçeklenebilirlik: HDFS, DataNodes'un çalışan bir kümeye eklenmesini sağlar ve küme düğümleri eklendiğinde veri bloklarını el ile yeniden dengelemeye yönelik araçlar sunar ve bu araçlar dosya sistemini kapatmadan yapılabilir.
HDFS'nin temel dezavantajları şunlardır:
- Küçük dosya verimsizlikleri: HDFS, büyük blok boyutlarıyla (64 MB ve daha büyük) kullanılacak şekilde tasarlanmıştır. Büyük dosyaları (yüzlerce megabayt, gigabayt veya terabayt) alıp bloklar halinde öbeklemesi amaçlanır ve bu bloklar paralel işleme için MapReduce işlerine beslenebilir. HDFS, küçük boyuttaki dosyalar (birkaç kilobayt) söz konusu olduğunda verimsizdir. Dosya sistemindeki tüm dosyaların meta verilerini tutmak zorunda olan NameNode düğümü, küçük dosyalar söz konusu olduğunda artan yüke maruz kalır. HDFS kullanıcıları genellikle küçük dosyaları dizi dosyaları gibi teknikler kullanarak daha büyük dosyalar haline getirmektedir.
- POSIX uyumsuzluk: HDFS POSIX uyumlu, takılabilir bir dosya sistemi olarak tasarlanmamıştır; uygulamaların sıfırdan yazılması veya HDFS istemcisi kullanmak için değiştirilmesi gerekir. HDFS'nin FUSE sürücüsü kullanılarak bağlanmasını sağlayan geçici çözümler mevcuttur ancak dosya sistemi semantiği kapatılan dosyalara veri yazılmasına izin vermez.
- Bir kez yazma modeli: Bir kez yazma modeli, aynı dosyaya eşzamanlı yazma erişimi gerektiren uygulamalar için olası bir dezavantajdır. Ancak HDFS'nin en son sürümü dosyalara ekleme yapılmasını desteklemektedir.
Özetle HDFS, MapReduce modelini benimseyen veya HDFS'yi kullanacak şekilde yazılmış olan dağıtılmış uygulamalar için iyi bir depolama arka ucu seçeneğidir. HDFS en yüksek verimi çok sayıda küçük dosya yerine az sayıda büyük dosya kullanıldığında sağlar.
Başvurular
- Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung (2003). The Google File Systems 19th ACM Symposium on Operating Systems Principles
- White, Tom (2012). Hadoop: Definitive Guide O'Reilly Media, Yahoo Press