İleti kuyrukları: Örnek olay incelemesi
Daha önce, ileti kuyruğu sistemlerini genel olarak ele aldık. İşlemler arası iletişim için genel amaçlı ileti kuyruğu sistemlerinin bir süredir mevcut olduğunu ve istemci-sunucu sistemleri veya web hizmeti mimarileri için daha özelleştirilmiş ileti kuyruklarının ortaya çıktığını gördük. Benzersiz tasarımlara ve özelliklere sahip birkaç farklı sistem olsa da, ölçeklenebilirlik ve esneklik için sıfırdan oluşturulmuş bir sisteme göz atacağız: Apache Kafka.
Apache Kafka
Kafka, bir dizi programdan (üretici olarak bilinir) gelen iletilerin işlenmesinden ve bunların, iletiler ilgisini çekebilecek bir dizi makineye (tüketici olarak bilinir) gönderilmesinden sorumludur. İletiler, üreticiler tarafından bir Kafka konusuna yayımlanır. Tüketiciler, belirli bir konuya abone olarak o konuyu dinleyebilir ve Kafka tarafından tüketicilere iletiler teslim edilir. Dolayısıyla Apache Kafka, açık kaynak dağıtılmış bir yayımlama-abone olma mesajlaşma sistemi olarak açıklanabilir.
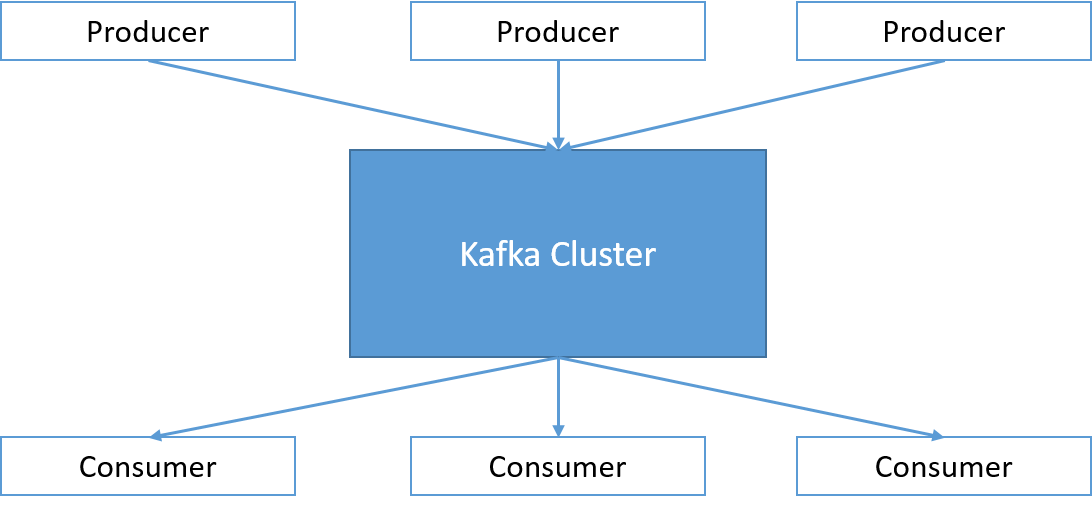
Şekil 3: Kafka kümesi
Konular, iletilerin yayımlanacağı, kullanıcı tanımlı bir kategoriyi temsil eder. Bir reklam şirketinde bulunabilecek örnek bir konu, AdClickEvents olabilir. Tüm veri tüketicileri, bir veya daha fazla konudan okuma işlemi yapabilir. Dahili olarak her konu, Şekil 4’te gösterildiği gibi bölümlenmiş işleme günlüğü olarak tutulur. Bir konunun birden çok bölümden oluşabileceği ve bir Kafka kümesinin birden çok konuyu işleyebileceği unutulmamalıdır.
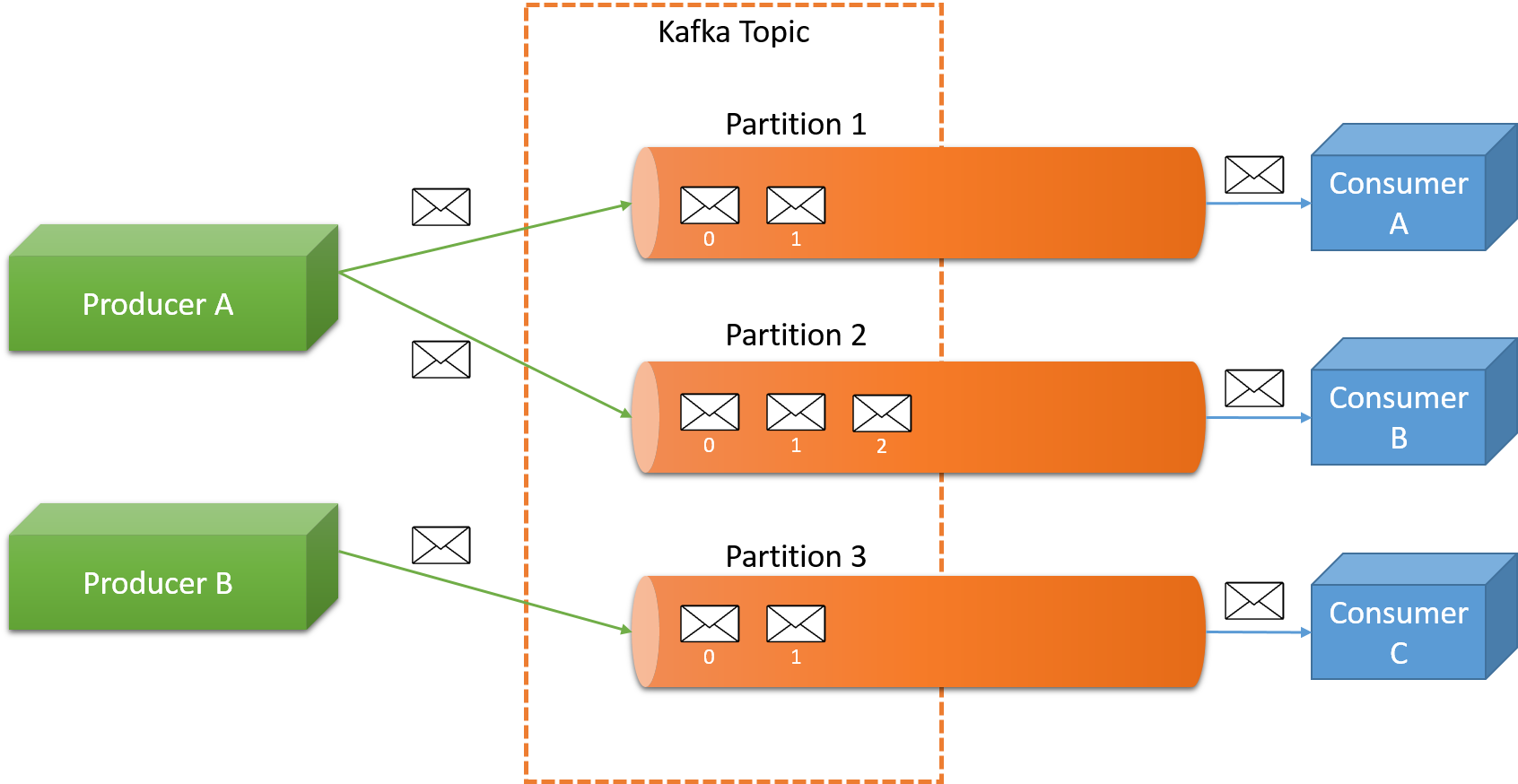
Şekil 4: Kafka'da ileti kuyruğa alma
Resmi olarak her bir bölüm, bir işleme günlüğüne sürekli olarak eklenen, sıralı ve sabit bir ileti dizisidir. Bölümlerdeki iletilerin her birine, ofset adlı bir sıralı kimlik numarası atanır. Bu, bölüm içindeki her bir iletiyi benzersiz şekilde tanımlar ve bölümler arasındaki bir konuda iletileri sıralamak için kullanılamaz.
Günlükteki bölümler birkaç amaca hizmet eder. Birincisi, günlüğün tek bir sunucuya sığacak bir boyutun ötesine ölçeklenebilmesini sağlar. Her bir bölümün, kendisini barındıran sunuculara sığması gerekir, ancak bir konunun rastgele miktarda veriyi işleyebilmesi için birçok bölümü olabilir. İkincisi, paralellik birimi olarak hareket ederek günlüğün tek tek bölümlerinin birden çok makine arasında dağıtılmasını sağlar. Üreticiler, hem bir ileti konusu üzerinde denetime sahip olup hem de gerekirse bir semantik bölümleme işlevi (MapReduce’ta kullanılan bölümleme işlevlerine benzer şekilde) kullanarak bir iletinin gönderildiği bölümü açıkça denetleyebilir. Varsayılan olarak belirli bir konudaki iletiler, o konunun bölümleri arasında hepsi bir kez denenecek şekilde dağıtılır.
Kafka kümesi, yayımlanmış tüm iletileri, kullanılmış olup olmadığına bakılmaksızın, yapılandırılabilir bir süre boyunca (varsayılan 7 gündür) saklar. Bu saklama süresini aşan iletiler, yeni iletilere yer açmak amacıyla Kafka tarafından otomatik olarak temizlenir.
Kafka ayrıca her bir tüketicinin, belirli bir konuya yönelik günlük dosyasının iletilerinin okunmasındaki ilerleme durumunu da (tüketici için ofset olarak bilinir) izler. Çoğu tüketici, iletilerini kullandıkça bu ofset değerini doğrusal olarak ilerletir. Tüketiciler bu ofset değişkeni üzerinde denetim elde eder ve gerekirse daha eski veya daha yeni iletileri okumak için ileri ya da geri hareket edebilir.
Bu özellik kombinasyonu, Kafka tüketicilerinin çok düşük maliyetli olduğu anlamına gelir. Küme veya diğer tüketiciler üzerinde olumsuz etki yaratmadan gidip gelebilirler.
Apache Kafka tarafından sağlanan garantiler
Kafka, uygulama geliştiricilerinin güvenebileceği bir dizi üst düzey garanti sağlar:
- Bir üretici tarafından belirli bir konu bölümüne gönderilen iletiler, gönderildikleri sıraya göre eklenir. Başka bir deyişle M1 iletisi, aynı üretici tarafından M2 iletisi olarak gönderilir ve ilk olarak M1 gönderilirse, M1, M2 iletisinden daha düşük bir ofsete sahip olur ve günlükte daha önce görüntülenir.
- Tüketici örneği, iletileri günlükte depolandığı sırayla görür.
- $N$ çoğaltma katsayısına sahip bir konu için, günlüğe işlenen hiçbir iletiyi kaybetmeden en fazla $N - 1$ sunucu hatasını tolere ederiz.
Teslim garantileri çok katı değildir. Tüketiciler nadir durumlarda aynı iletiyi iki defa alabilir.
Apache Kafka mimarisi
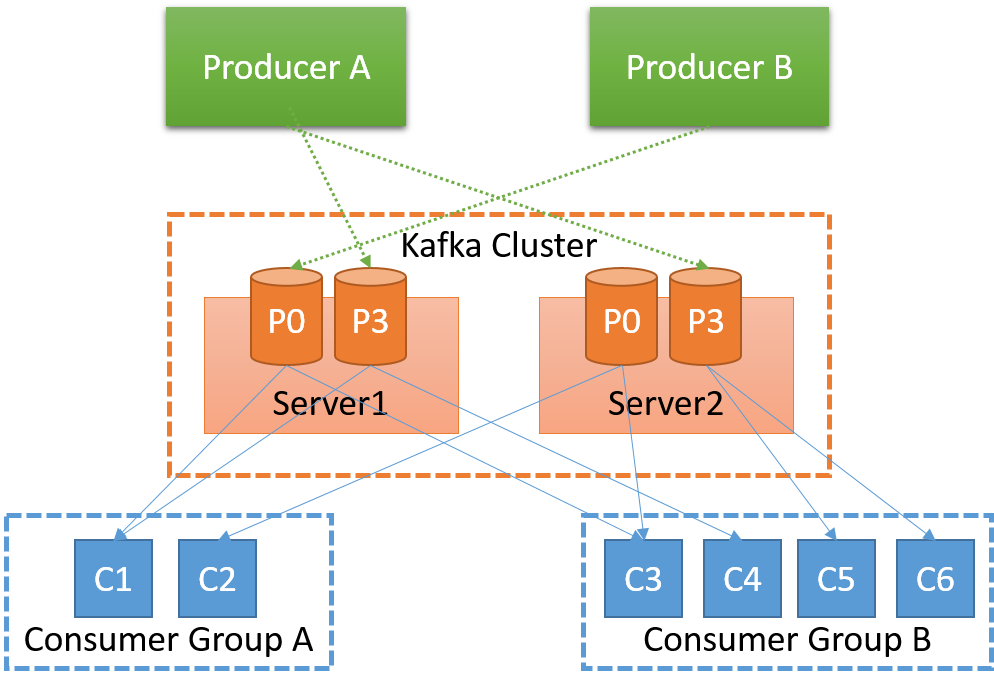
Şekil 5: Kafka mimarisi
Yayımcılardan (üreticiler) abonelere (tüketiciler) iletileri aktaran sunucular, Kafka aracıları olarak bilinir. Kafka aracıları, ileti kalıcılığı ve çoğaltmasından sorumludur. Her bir konunun bölümleri, aracılar arasında dağıtılır ve her bir aracı bir veya daha fazla bölüm depolar.
Sabit bir ana aracı olmadığından aracılar, merkezi olmayacak şekilde düzenlenir. Aracıların sistem durumu hakkında fikir birliğine varması için Apache ZooKeeper devreye alınır. ZooKeeper, API gibi bir dosya sistemi biçiminde yüksek düzeyde kullanılabilir bir çekirdek fikir birliği hizmeti sağlar. ZooKeeper, Kafka’da aşağıdaki görevler için kullanılır:
- Sistemde aracıların ve tüketicilerin eklenmesini ve kaldırılmasını algılama
- Aracı veya tüketici sayısı değiştiğinde bölümlerin yeniden dengelenmesini tetikleme
- Her bir bölüm için tüketilen ofsetleri takip etme ve tüketim ilişkisini koruma
Daha önce belirtildiği gibi, Kafka’daki en küçük paralellik birimi, bir konudaki bölümdür. Başka bir deyişle, bir bölümün tüm iletileri aynı anda tek bir tüketici tarafından kullanılır. Böylece Kafka’nın, bölümler arasında sıralama garantisi olsaydı yüksek maliyete yol açacak şekilde birden çok aracı arasında koordinasyon yapması zorunluluğu ortadan kalkmış olur.
Bölümler hataya dayanıklılık için birden çok aracı arasında çoğaltılır. Aracılardan biri, belirli bir bölüm için lider olarak atanır ve o bölüme ait tüm okuma ve yazmalar varsayılan olarak ana çoğaltmaya gider. Bir ileti yalnızca tüm çoğaltmalar tarafından günlüğe işlendiğinde işlenmiş olarak değerlendirilir. Yalnızca işlenmiş iletiler tüketicilere iletilir. Üreticiler, bir ileti Kafka tarafından işleninceye kadar engellemeyi seçebileceği gibi, engelleyici olmayacak şekilde sürekli olarak iletilerin akışını sağlamayı da seçebilir. Günlük çoğaltma işlemini hızlandırmak için Kafka tarafından devreye alınan birkaç teknik vardır. Ayrıntılar için Apache Kafka belgelerine bakın.
Kafka aracılarının büyük miktarda iletiyi işlemesi beklendiğinden, Kafka’nın kümedeki her düğüm için izlediği iki “canlılık” özelliği vardır:
- Her düğüm, bir sinyal mekanizması aracılığıyla ZooKeeper ile bir oturumu korur.
- Her bağımlı düğüm, ana düğümün güncelleştirmelerini çoğaltmalı ve “çok geride” kalmamalıdır. Çoğaltma gecikmesi, Kafka kümesinde yapılandırılabilir bir özelliktir.
Üretici etkileşimi
Üreticiler, Kafka API’sini kullanarak bir Kafka kümesine ileti gönderebilir. Üreticiler, yapılandırılan konular ve bölümlerden haberdar olur. Kafka ve bir üretici genellikle iletileri, iletinin belirli bölümünün işlenmesinden sorumlu olan uygun aracıya yönlendirir. API, meta veri isteklerinde bulunulmasına da olanak sağlar. Böylece, üreticilerin bir konu ve bölüm için uygun aracıyı sorgulamasına ve bulmasına imkan tanınır. Daha önce belirtildiği gibi, bir konunun bölümlemesi yapılandırılabilir ve bir konunun rastgele yük dengelemesi veya içeriğe duyarlı semantik bölümlemesi devreye alınabilir.
Ayrıca, bir Kafka aracısıyla etkileşim kuran üreticilerin, iletileri toplayıp toplu olarak gönderen istek toplu işleminin yanı sıra zaman uyumsuz ileti iletişimi seçeneği de vardır. Bunlar, toplu iş uygulanacak ileti sayısı veya sabit gecikme süresi sınırı açısından yapılandırılabilir ve böylece uygulamanın aktarım hızı ile gecikme süresi arasında dengeleme yapmasına olanak sağlar.
Tüketici etkileşimi
Kafka tüketicileri, kullanılması gereken tek tek bölümler için aracılardan getirme istekleri yayınlar. Tüketici, her bir istek ile Kafka günlüğünde bir ofset belirtebilir ve sonra o konumdan başlayan bir ileti öbeği alabilir. Tüketiciler, iletilerin Kafka kümesi için saklama zaman penceresi içinde olması şartıyla, tüm ofset ve istek iletilerine geri dönebilir.
Kafka kullanım örnekleri
Mesajlaşma kuyruğu: Kafka, ActiveMQ veya RabbitMQ gibi geleneksel mesajlaşma kuyruklarının yerini alabilir. Kafka özellikle de yapılandırılabilir gecikme süresi ve aktarım hızı gereksinimleriyle yüksek kullanılabilirlik ve ölçeklenebilir ileti teslimi için sıfırdan tasarlandığından daha da önem kazanır.
Web sitesi etkinlik izleme: Kafka başlangıçta LinkedIn tarafından bir kullanıcı etkinliği işlem hattı oluşturmak ve LinkedIn kullanıcıları için içerik ve reklam yerleşimi için gerçek zamanlı kararlar almak üzere oluşturulmuştu. Bu senaryoda, kullanıcı etkileşimi türü tarafından konular oluşturulabilir (örn. sayfa görüntüleme ve kaydırma bilgileri için bir konu, arama terimleri için başka bir konu ve kullanıcı tıklamaları için başka bir konu). Kullanıcı etkinliğinin gerçek zamanlı olarak işlenmesi ve izlenmesi gibi çeşitli arka uç hizmetleri, ilgili konulara abone olabilir ve akışları geldikçe işleyebilir.
Günlük toplama: Kafka, birden çok hizmetten günlükleri toplamak ve işlenmek üzere merkezi bir konumda kullanılabilir hale getirmek için kullanılabilir. Scribe veya Flume gibi günlük odaklı sistemlere kıyasla Kafka, eşit derecede iyi performans, çoğaltma sayesinde daha güçlü dayanıklılık garantileri ve çok daha düşük uçtan uca gecikme süresi sunar.