Akış işleme sistemleri
Şu ana kadar incelediğimiz çerçeveler (MapReduce, Spark, GraphLab) öncelikli olarak toplu iş hesaplamaları gerçekleştirmek için tasarlanmıştır. Bunların girişleri genellikle büyük ve kullanışlı bir çıkış üretmek için birkaç saat boyunca işlenen büyük dağıtılmış veri kümeleridir. Bu çerçevelerin kullanımı başlangıçta veri bilimcileri ve programcıları ile kısıtlı olup bu yüksek gecikme süresinin tolere edilebildiği belirli büyük sorgular için olurdu. Ancak kuruluşlar içinde büyük veri kullanımı yaygınlaştıkça, saatlik değil dakikalık gecikme süresi beklentisiyle geçici veri sorgulamasına geçiş olmuştur. Pig, Hive, Shark ve Spark SQL gibi araçlar, birçok işletmenin yüksek eğitimli programcılardan oluşan büyük bir havuzu kullanmadan verileriyle ilgili karmaşık sorular sormasına olanak sağlamıştır. Bulut bu benimsemeyi daha da ileri götürüp geçici bir sorgu süresince işlem kaynaklarının esnek şekilde sağlanmasına imkan tanımıştır.
Kısa zamanda daha da düşük gecikme süresi beklentileri ortaya çıkmıştır. Gerçek zamanlı olarak büyük veri alınmaya başlamış ve çoğu zaman bu veriler yalnızca kısa bir süreliğine değer kazanmıştır. Örneğin, arama motorları, her bir sorgu için milisaniyeler içinde en iyi reklam kombinasyonunun sunulmasını gerektirmiş; sosyal medya web siteleri, trendleri, öne çıkan konuları ve diyez etiketlerini algılamış ve sistem izleme araçları da birçok büyük altyapı bileşeni arasında karmaşık desenleri algılamıştır. Bu kadar düşük gecikme süreleri sağlayabilmek için yeni bir akış işleme çerçevesi sınıfı şekillenmeye başlamıştır. Bunlar, geçmişteki toplu iş ve etkileşimli işleme sistemlerinden farklı gereksinimlere ve kısıtlamalara sahip olmuştur.
Bu da akış işleme sistemlerinin ortaya çıkmasına neden olmuştur.
Akış işleme
Akış işleme paradigması, son derece uzun bir giriş veri kaynağı tarafından yayınlanan her bir veri öğesine bir dizi işlem uygular. İşlem serisi genellikle işlem hattı haline getirilir ve bu da işlemler arasında bağımlılıklar oluşturur. İşlem uygulaması içinde durum bilgileri genellikle küçük ve hızlı bir veri kaynağından okunur ve bu veri kaynaklarına yazılır. Akış işlemlerinin işlem hattının çıkışı da bir veri akışıdır. Bu, diğer uygulamaları tetiklemek için kullanılabilir veya arabelleğe alınabilir ve depolama alanında depolanabilir. Aşağıda, böyle bir sistemin temel kavramsal mimarisi gösterilmektedir.
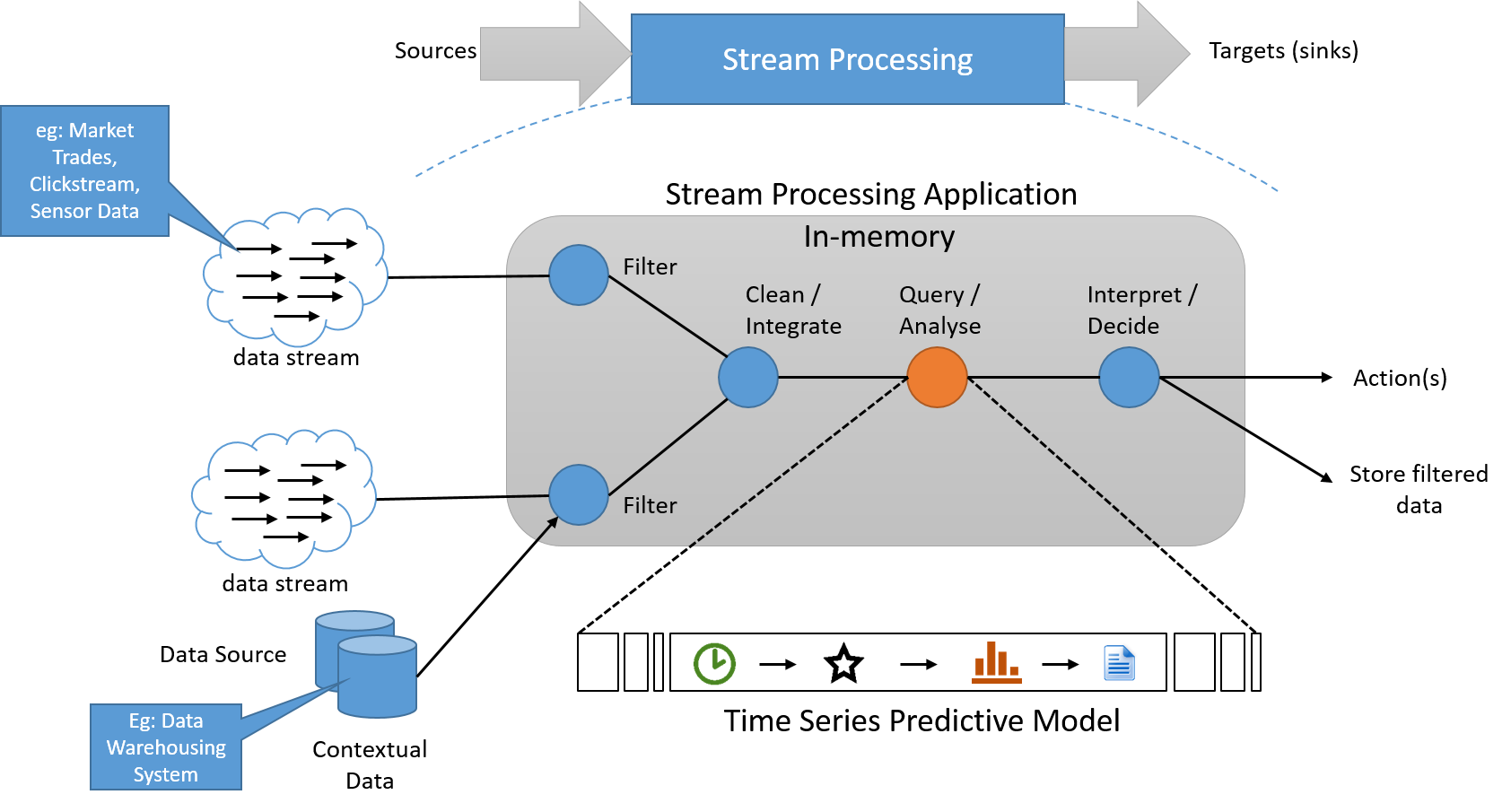
Şekil 6: Bir akış işleme sistemi, gerekirse "kritik yolda" yer vermeyen ayrı bir depolama işlem hattı ile akış içi verileri işlemelidir
Akış işlemenin sekiz kuralı
Stonebraker et. al. akış işleme sistemlerinin sekiz temel kuralını açıklamıştır.
Kural 1: Verilerin hareket halinde kalmasını sağlayın
Gerçek zamanlı bir akış işleme çerçevesi, kritik yol üzerine kabul edilemez gecikme süresi ekleyecek şekilde “akış içi” iletileri diskte depolamak zorunda kalmadan işleyebilmelidir. Ayrıca bu sistemler edilgen (uygulamaların ilgi çekici koşulları algılamak için sonuçları yoklaması gerekecek şekilde) değil, etkin (olay odaklı) olmalıdır.
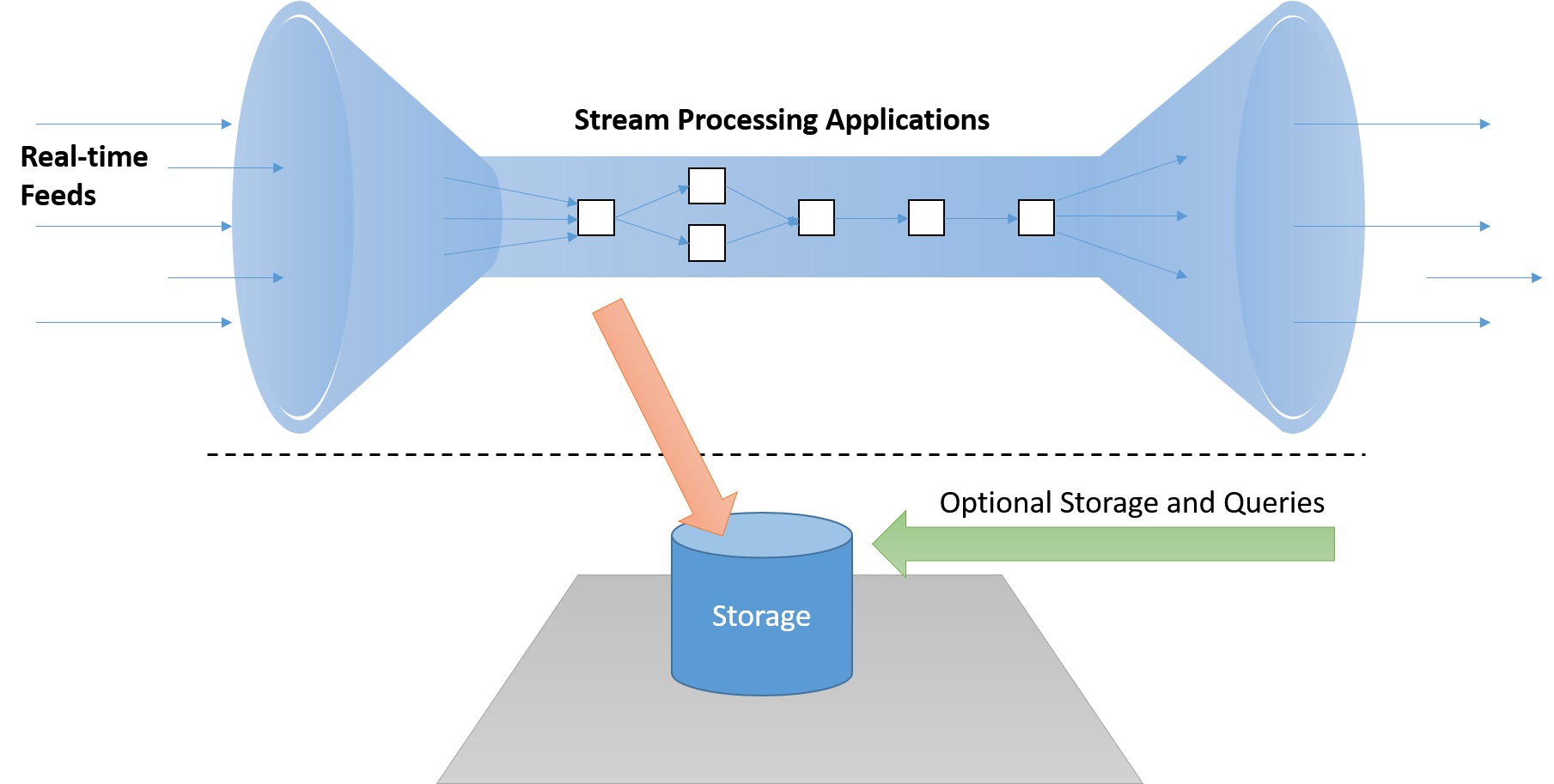
Şekil 7: Bir akış işleme sistemi, gerekirse "kritik yolda" yer almayan ayrı bir depolama işlem hattı ile akış içi verileri işlemelidir
Kural 2: Akışlar SQL kullanarak sorgulamayı desteklemelidir
SQL, verileri sorgulamak için yaygın olarak kullanılan ve bilindik bir standart olarak ortaya çıkmıştır. Ancak geleneksel SQL, sabit miktarda veri üzerinde çalışır ve böylece tablonun sonuna ulaşıldığında sorguya tamamlandığı bildirilir. Akış senaryolarında veriler sürekli olarak artar. Stonebraker et. al. bir sorgunun kapsamını tanımlayan, değişken uzunlukta zamana bağlı kayan pencerelerle StreamSQL diline olan ihtiyacı algılamıştır. Saat, ileti sayısı veya herhangi bir rastgele parametreler kullanılarak pencereler tanımlanabilir. Birden çok akıştaki iletileri birleştirmek için ek işleçler gerekebilir.
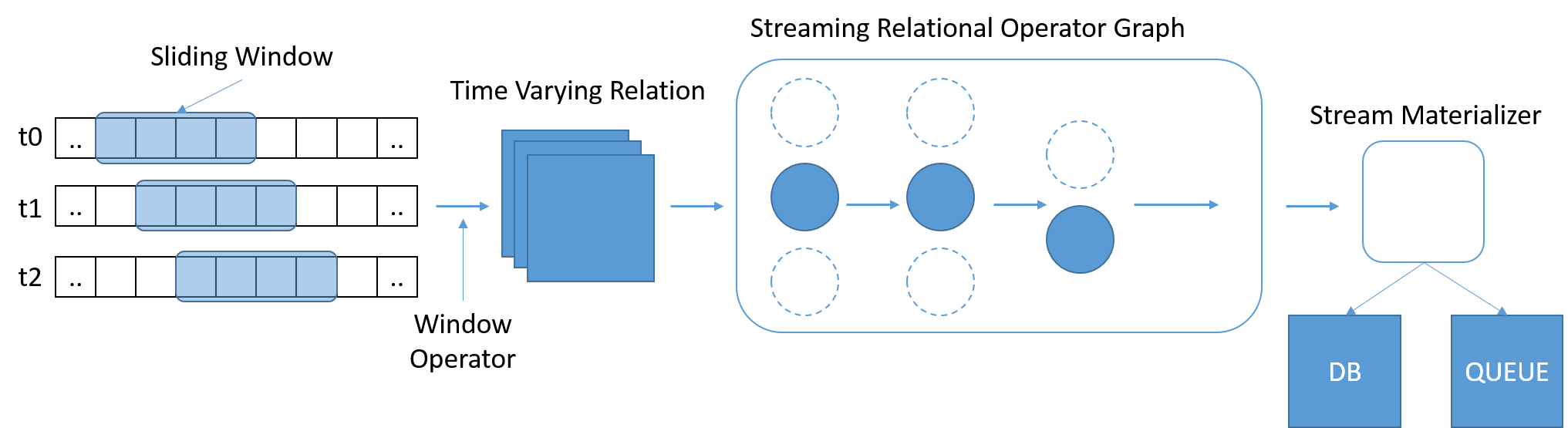
Şekil 8: StreamSQL verilerin alt kümelerini işlemeli ve ilişkilerin pencereler arasında ifade edilmesine izin vermelidir
Kural 3: Akış kusurlarını işleme
Gerçek zamanlı sistemlerde veriler kaybolabilir, geç gelebilir veya yanlış sırayla gelebilir. Akış işleme sistemi, verileri süresiz olarak bekleyemez, ancak herhangi bir veriyi yoksayma ya da kaçırma esnekliğine de sahip olmayabilir. Bu tür sistemler, geç ulaşmanın kabul edilebilir olabileceği yapılandırılabilir zaman aşımları ve “boşta zamanlar” gibi mekanizmalarla akış kusurlarına karşı dayanıklı olmalıdır.
Kural 4: Tahmin edilebilir sonuçlar oluşturma
Herhangi bir akış işleme sisteminin sonucu, akış yeniden oynatılarak yinelenebilir ve belirlenimci olmalıdır. Bu özellikle de sistem birden çok eşzamanlı akış üzerinde çalışırken veya iletiler yanlış sırayla ulaştığında zor olur. İletiler, ulaşma zamanından bağımsız olarak saate göre artan düzende üretilmelidir. Bu özellik, işlem başarısız olduğunda akışların yeniden oynatılmasını makul hale getirerek hataya dayanıklılık sağlar.
Kural 5: Saklı durumu tümleştirme
Akış işleme uygulamaları genellikle geçmiş ile şu anı birleştirir. Örneğin, bir arama motoru kullanıcıya reklam önerirken, arama terimi ve reklam pazarının geçerli durumu ile ilgili geçerli bilgileri, kullanıcının tıklama alışkanlıklarıyla ilgili geçmiş bilgileri birleştirmelidir. Depolanan durum ve akış verilerinin tümleştirilmesi aynı zamanda, bir algoritmanın geçmiş veriler üzerinde test edilebildiği ve daha sonra tatmin edici şekilde çalıştığında canlı akışa geçirilebildiği sorunsuz geçişe de olanak sağlar. Veriler, depolanan veriler ve akış verileri ile ilgilenen tekdüzen bir dil kullanımına olanak sağlamak için belki de ekli bir veritabanı kullanılarak, uygulamayla aynı sistem adresi alanında depolanmalıdır.
Kural 6: Yüksek kullanılabilirlik garantisi
Akış işleme sistemleri gerçek zamanlı olarak çalışır ve genellikle yeniden başlatma ile kurtarma işlemlerini tolere edemez. Bu tür sistemler bir yedek veya gölge sisteme çalışırken geçişe olanak sağlamalı ve bu yedek ya da gölge sistem de düzenli olarak birincil sistemle eşitlenmelidir. Kural 4 doğrultusunda veri bütünlüğü garantili edilmelidir.
Kural 7: Bölümleme ve otomatik ölçeklendirme desteği
Tüm bu büyük sistemler için standart işlem modeli, dağıtılmış işlemedir. İyi bir akış işleme mimarisi, engelleyici olmamalı ve modern çok iş parçacıklı mimarilerden yararlanmalıdır. Ayrıca, işlem gecikmelerine veya karmaşıklıklarına göre ya da artan veya azalan veri hacimlerine göre makineler ekleyerek ya da kaldırarak sistem ölçeğini kendisi genişletebilmeli veya daraltabilmelidir. Ayrıca, kullanılabilir makineler üzerinden otomatik ve şeffaf şekilde yük dengeleme de gerçekleştirmelidir. Son kullanıcının tüm bu karmaşıklıklarla uğraşmak zorunda kalmaması gerekir.
8. Kural: Ayak uydurabıladığından emin olun
Tüm sistem bileşenleri, çekirdek dışında minimum sayıda işlem gerçekleşecek şekilde yüksek performans için tasarlanmış olmalıdır. Sistemin, hedef iş yüküne göre test edilip karşılaştırılması ve aktarım hızı ve gecikme süresi hedeflerinin doğrulanması gerekir.
Akış işleme altyapılarının evrimi
Aurora (2002), MIT ve Brown Üniversitesi’nde Stonebraker ve diğerleri tarafından geliştirilen ilk akış işleme sistemlerinden biriydi. Aurora, akış işleme sorununu, döngüsel olmayan yönlü graf (DAG) olarak değerlendirdi.
Akış girişi, zaman içinde yukarı akıştan (başlangıç) aşağı akışa (çıkış) ilerleyen bir sınırsız tanımlama grubu dizisidir (a1, a2, ..., an). Farklı işleme kutuları kombinasyonları eklenip bunlar arasında bağlantılar çizilerek bir uygulamanın tamamı oluşturulabilir. Aurora, bir akış işleme altyapısının ölçeklenebilirlik gereksinimlerinin çoğunu içermeyen tek düğümlü bir sistemdi. Bir ağ üzerinden birçok Aurora düğümlerini birleştirmek için Aurora* (2003) adlı yeni bir Aurora sürümü oluşturuldu. Böylece farklı fiziksel düğümler üzerinden akış işleme işinin farklı aşamaları bölümlenerek ölçeklenebilirlik elde edildi. Son olarak Medusa projesi (2003), Aurora’ya federasyon desteği ekleyerek birden çok kullanıcının işbirliğine ve paylaşımına olanak sağladı.
Aurora projesinin sonraki uzantısı da, etkin çoğaltma kullanarak yüksek kullanılabilirlik desteği ekleyen Borealis (2005) idi. Çoğaltmalar, veri tutarlılığı sağlamak için dikkatle eşitlendi.
Apache Storm (2011), Twitter tarafından geliştirilen bir akış işleme altyapısıydı. Burada işlem düğümleri (Bolt’lar), farklı kaynaklardan (Spout’lar) akışlara abone olarak basit bir abone hesaplama modeline olanak sağlayabilir. Storm, düğüm hatalarına bakılmaksızın garantili ileti işleme sağlar ve verilerin eksik veya fazla sayılmamasından emin olmak için kesinlikle bir kere semantiğini etkinleştirir. Apache S4 (2011), Yahoo!’da geliştirilen benzer bir abonelik sistemiydi. Ölçeklenebilir hale getirme açısından, tüm düğümlerin eşit olması ve merkezi denetim olmaması bakımından simetriktir. S4, çalışan bir kümeye dinamik olarak düğüm eklenmesini veya çalışan bir kümeden dinamik olarak düğüm kaldırılmasını desteklemez. Apache Samza (2013) da başka bir çoklu abone sistemi olup daha ayrıntılı şekilde ele alınacaktır.
Storm, Samza ve S4, aynı anda yalnızca bir kayıt işleme olarak bilinen geleneksel akış modelini izler. Bu modelde, durum bilgisi olan işleçler, dahili durum bilgilerini değiştirmek ve yeni kayıtlar yayınlamak için yeni verileri kullanarak ulaşan kayıtları işler. Hataya dayanıklılık ve kurtarma, işleme öğelerinin birden çok kopyası oluşturulup veya iletilerin yukarı akışının yedekleri depolanıp hata olması durumunda bunlar aşağı akışa yeniden gönderilerek çoğaltma yoluyla gerçekleştirilir. Ayrıca döngüsel olmayan yönlü graf düzeni daha da karmaşık hale geldikçe, farklı yollar arasında tutarlılık sağlanması zor olur. Son olarak bu çerçevelerin toplu iş sistemleriyle birleştirilmesi basit bir işlem değildir ve çoğu zaman Lambda mimarisi (daha sonra ele alınacaktır) kullanılarak gerçekleştirilir.
Akış işleme sistemleri tasarlamaya yönelik bir diğer yaklaşım da "mikro toplu işlem" sağlayan Spark Streaming (2012) tarafından sağlanır. Mikro toplu işlem, yüzlerce milisaniyeden birkaç saniyeye kadar gecikme süresiyle akış hesaplamalarını son derece hızlı hesaplamalar kümesine dönüştürür. Gecikme süresinin artması karşılığında, her bir mikro toplu iş sonucunda kesinlikle bir kere semantiği ve hataya dayanıklılık sağlanması kolaylaşır.
Bir görev için kullanılacak doğru çerçevenin seçilmesi, beklenen gecikme süresi, hataya dayanıklılık ve ileti teslimi garantilerinde ve kullanıcıların beceri kümelerinin ve istenen geliştirme maliyetlerinin elde edilmesinde önemli bir faktördür. Sonraki ünitede, Apache Samza üzerinde çalışarak bu çerçevelerin iç yüzünü daha ayrıntılı şekilde keşfedeceğiz.