Normalleştirmeyi açıklama
Veritabanı normalleştirmesi, belirli bir veri kümesini veritabanındaki tablolar ve sütunlar halinde düzenlemek için kullanılan bir tasarım işlemidir. Her tabloda belirli bir 'şey' ile ilgili veriler bulunmalıdır ve tabloya yalnızca aynı 'şeyi' destekleyen veriler eklenmelidir. Bu işlemin amacı, veritabanı eklemelerinin ve güncelleştirmelerinin performans düşüşünü azaltmak için veritabanınızda bulunan yinelenen verileri azaltmaktır. Örneğin, müşteri adresinin depolandığı tek yer Müşteriler tablosundaysa, müşteri adresi değişikliğinin uygulanması çok daha kolaydır. En yaygın normalleştirme biçimleri birinci, ikinci ve üçüncü normal biçimdir ve aşağıda açıklanmıştır.
İlk normal form
İlk normal formda aşağıdaki belirtimler bulunur:
- İlişkili her veri kümesi için ayrı bir tablo oluşturma
- Tek tek tablolarda yinelenen grupları ortadan kaldırma
- Birincil anahtarla ilgili her veri kümesini tanımlama
Bu modelde, benzer verileri depolamak için tek bir tabloda birden çok sütun kullanmamalısınız. Örneğin, ürün birden çok renkle gelebiliyorsa, farklı renk değerlerini içeren tek bir satırda birden çok sütuna sahip olmamanız gerekir. Aşağıdaki ilk tablo (ProductColors), renk için yinelenen değerler olduğundan ilk normal biçimde değildir. Yalnızca bir rengi olan ürünlerde boş alan vardır. Peki ya bir ürün üçten fazla renkle geldiyse? En fazla renk sayısını ayarlamak zorunda kalmak yerine, ikinci tablo olan ProductColor'da gösterildiği gibi tabloyu yeniden oluşturabiliriz. Ayrıca, değeri satırı benzersiz olarak tanımlayan sütun (veya sütunlar) olan tablo için benzersiz bir anahtar olması için de ilk normal forma yönelik bir gereksinimimiz vardır. İkinci tablodaki sütunların hiçbiri benzersiz değildir, ancak birlikte ProductID ve Color birleşimi benzersizdir. Birden çok sütun gerektiğinde buna bileşik anahtar diyoruz.
| Productıd | Renk1 | Renk2 | Renk3 |
|---|---|---|---|
| 1 | Kırmızı | Yeşil | Sarı |
| 2 | Sarı | ||
| 3 | Mavi | Kırmızı | |
| 4 | Mavi | ||
| 5 | Kırmızı |
| Productıd | Renk |
|---|---|
| 1 | Kırmızı |
| 1 | Yeşil |
| 1 | Sarı |
| 2 | Sarı |
| 3 | Mavi |
| 3 | Kırmızı |
| 4 | Mavi |
| 5 | Kırmızı |
Üçüncü tablo olan ProductInfo, her satır belirli bir ürüne başvurduğundan, yinelenen grup olmadığından ve Birincil Anahtar olarak kullanılacak ProductID sütununa sahip olduğumuzdan ilk normal biçimdedir.
| Productıd | Productname | Price | ProductionCountry | ShortLocation |
|---|---|---|---|---|
| 1 | Arabirim öğesi | 15.95 | ABD | ABD |
| 2 | Foop | 41.95 | Birleşik Krallık | Birleşik Krallık |
| 3 | Glombit | 49.95 | Birleşik Krallık | Birleşik Krallık |
| 4 | Sorfin | 99,99 | Filipinler Cumhuriyeti | RepPhil |
| 5 | Sap Cıvatası | 29.95 | ABD | ABD |
İkinci normal form
İkinci normal form, ilk normal formun gerektirdiği özelliklere ek olarak aşağıdaki belirtime sahiptir:
- Tabloda bileşik anahtar varsa, tüm öznitelikler yalnızca bir parçasına değil tam anahtara bağlı olmalıdır.
İkinci normal form yalnızca yukarıdaki ikinci tablo olan ProductColor tablosundaki gibi bileşik anahtarlara sahip tablolarla ilgilidir. ProductColor tablosunun ürünün fiyatını da içerdiği durumu göz önünde bulundurun. Bu tablonun ProductID ve Color üzerinde bileşik bir anahtarı vardır, çünkü yalnızca her iki sütun değerini kullanarak bir satırı benzersiz olarak tanımlayabiliriz. Bir ürünün fiyatı renkle değişmezse verileri şu tabloda gösterildiği gibi görebiliriz:
| Productıd | Renk | Price |
|---|---|---|
| 1 | Kırmızı | 15.95 |
| 1 | Yeşil | 15.95 |
| 1 | Sarı | 15.95 |
| 2 | Sarı | 41.95 |
| 3 | Mavi | 49.95 |
| 3 | Kırmızı | 49.95 |
| 4 | Mavi | 99,95 |
| 5 | Kırmızı | 29.95 |
Yukarıdaki tablo ikinci normal biçimde değil . Fiyat değeri ProductID'ye bağlıdır ancak Renk'e bağımlı değildir. ProductID 1 için üç satır vardır, bu nedenle bu ürünün fiyatı üç kez tekrarlanır. İkinci normal formu ihlal etmeyle ilgili sorun, fiyatı güncelleştirmemiz gerekirse, her yerde güncelleştirdiğimizden emin olmamızdır. İlk satırdaki fiyatı güncelleştirirsek ancak ikinci veya üçüncü satırda güncelleştirmezsek 'anomaliyi güncelleştir' adlı bir şey elde etmiş olacağız. Güncelleştirmeden sonra ProductID 1 için gerçek fiyatın ne olduğunu söyleyemeyiz. Çözüm, Price sütununu Tek sütun anahtarı olarak ProductID içeren bir tabloya taşımaktır çünkü Bu, Price'ın bağımlı olduğu tek sütundur. Örneğin, Fiyat'ı depolamak için Tablo 3'i kullanabiliriz.
Bir ürünün fiyatı rengine göre farklıysa, dördüncü tablo ikinci normal formda olacaktır, çünkü fiyat anahtarın her iki bölümüne de bağlı olacaktır: ProductID ve Color.
Üçüncü normal form
Üçüncü normal form genellikle ÇOĞU OLTP veritabanının amacıdır. Üçüncü normal form, ikinci normal formun gerektirdiği özelliklere ek olarak aşağıdaki belirtime sahiptir:
- Anahtar olmayan tüm sütunlar, birincil anahtara geçişli olarak bağımlı değil.
Geçişli ilişki, bir tablodaki bir sütunun ikinci sütun aracılığıyla diğer sütunlarla ilişkili olduğunu gösterir. Bağımlılık, bir sütunun bir bağımlılığın sonucu olarak değerini başka bir sütundan türetebileceği anlamına gelir. Örneğin yaşınız doğum tarihinize göre belirlenebilir ve bu da yaşınızı doğum tarihinize bağlı hale getirir. Üçüncü tablo olan ProductInfo'ya geri dönün. Bu tablo ikinci normal biçimdedir, ancak üçüncü formda değildir. ShortLocation sütunu, anahtar olmayan ProductionCountry sütununa bağlıdır. İkinci normal form gibi, üçüncü normal formu ihlal etmek de anomalilerin güncelleştirilmesine neden olabilir. ShortLocation'un bir satırda güncelleştirilmesi ancak konumun oluştuğu tüm satırlarda güncelleştirilmesi durumunda tutarsız veriler ortaya çıkar. Bunu önlemek için ülke/bölge adlarını ve kısaltılmış formlarını depolamak için ayrı bir tablo oluşturabiliriz.
Normal dışıleştirme
Üçüncü normal form teorik olarak arzu edilir olsa da, tüm veriler için her zaman mümkün değildir. Buna ek olarak, normalleştirilmiş bir veritabanı size her zaman en iyi performansı vermez. Normalleştirilmiş veriler genellikle tek bir sorguda döndürülen tüm gerekli verileri almak için birden çok birleştirme işlemi gerektirir. Sorgu sonuçlarını döndürmek için gereken birleştirme sayısının yüksek CPU kullanımına sahip olması ve daha az birleştirme ve daha az CPU gerektiren normalleştirilmiş veriler olması durumunda verileri normalleştirme arasında bir fark vardır, ancak anomalileri güncelleştirme olasılığı açılır.
Not
Normalleştirilmiş veriler normal dışı veriyle aynı değildir. Normalleştirme için, normalleştirilmiş tablolar tasarlayarak başlayacağız. Ardından, gerekli birleştirme sayısını azaltmak için bazı tablolara ek sütunlar ekleyebiliriz, ancak bunu yaptığımızda olası güncelleştirme anomalilerinin farkındayız. Ardından, bir güncelleştirme gerçekleştirdiğimizde tüm yinelenen verilerin de güncelleştirilmesini sağlayacak tetikleyiciler veya başka tür işlemler olduğundan emin olacağız.
Normalleştirilmiş verilerin sorgulanması, özellikle de veri ambarı gibi yoğun okunan iş yükleri için daha verimli olabilir. Bu gibi durumlarda, ek sütunlara sahip olmak daha iyi sorgu desenleri ve/veya daha basit sorgular sunabilir.
Yıldız şeması
Çoğu normalleştirme OLTP iş yüklerini hedeflese de, veri ambarlarının genellikle normalleştirilmiş bir model olan kendi modelleme yapısı vardır. Bu tasarım, satış gibi belirli olaylar için ölçümleri veya ölçümleri kaydeden olgu tablolarını kullanır ve bunları satır sayısı bakımından daha küçük olan ancak olgu verilerini açıklamak için çok sayıda sütuna sahip olabilecek boyut tablolarına birleştirir. Bazı örnek boyutlar stok, zaman ve/veya coğrafyayı içerebilir. Bu tasarım düzeni, veritabanını sorgulamayı kolaylaştırmak ve okuma iş yükleri için performans kazanımları sunmak için kullanılır.
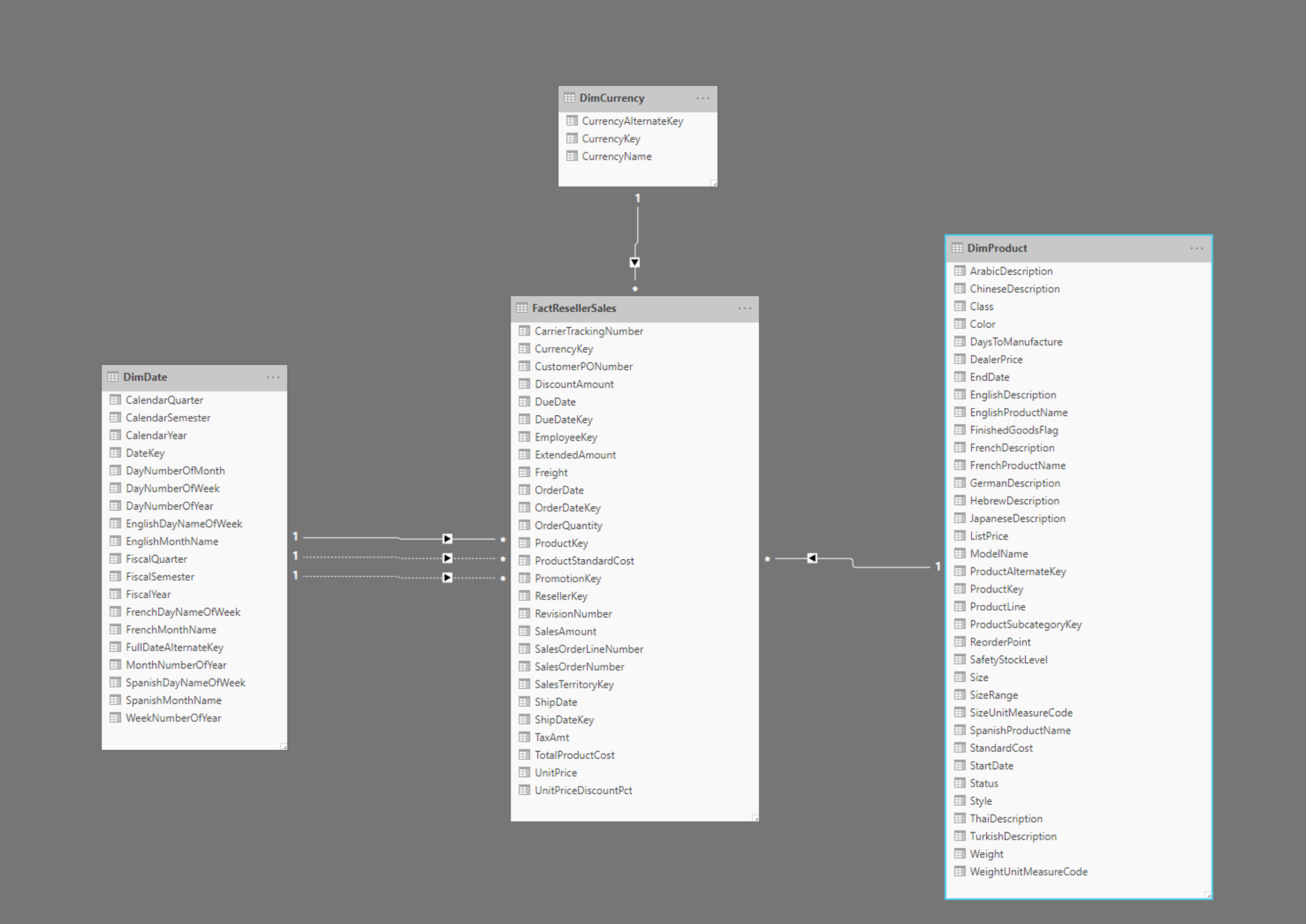
Yukarıdaki görüntüde FactResellerSales olgu tablosu ve tarih, para birimi ve ürünlerin boyutları da dahil olmak üzere bir yıldız şeması örneği gösterilmektedir. Olgu tablosu satış işlemleriyle ilgili verileri içerir ve boyutlar yalnızca satış verilerinin belirli bir öğesiyle ilgili verileri içerir. Örneğin FactResellerSales tablosu yalnızca hangi ürünün satıldığını belirten bir ProductKey içerir. Her ürünle ilgili tüm ayrıntılar DimProduct tablosunda depolanır ve ProductKey sütunuyla olgu tablosuyla ilişkilidir.
Yıldız şeması tasarımıyla ilgili, tek bir iş varlığı için daha normalleştirilmiş bir tablo kümesi kullanan bir kar tanesi şemasıdır. Aşağıdaki görüntüde, kar tanesi şeması için tek bir boyut örneği gösterilmektedir. Ürünler boyutu normalleştirilir ve DimProductCategory, DimProductSubcategory ve DimProduct adlı üç tabloda depolanır.
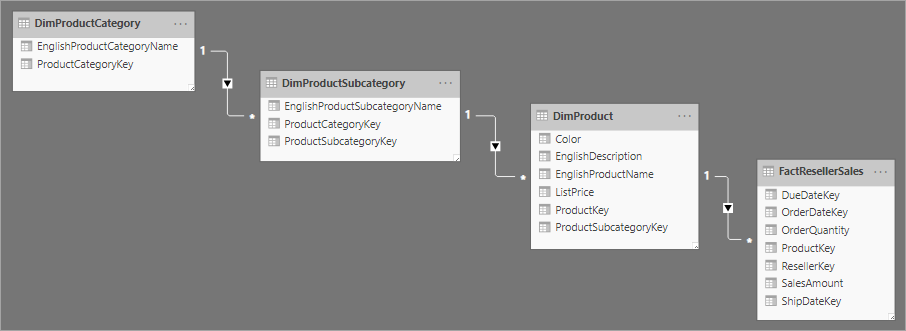
Yıldız ve kar tanesi şemaları arasındaki temel fark, bir kar tanesi şemasındaki boyutların yedekliliği azaltmak için normalleştirilmesidir ve bu da depolama alanından tasarruf sağlar. Bunun dezavantajı, sorgularınızın daha fazla birleşim gerektirmesi ve bu da karmaşıklığınızı artırabilir ve performansı düşürebilir.