Tasarım dizinleri
SQL Server,farklı iş yüklerini desteklemek için çeşitli dizin türlerine sahiptir. Yüksek düzeyde, bir dizin, SQL Server'ın tüm tabloyu taramaya kıyasla dizin anahtarıyla (tablo veya görünümdeki bir veya daha fazla sütundan oluşan) ilişkili satırı veya satırları daha kolay bulmasını sağlayan bir tablo veya görünümle ilişkilendirilmiş bir disk içi yapı olarak düşünülebilir.
Kümelenmiş
Yaygın bir DBA iş görüşmesi sorusu, dizinler SQL Server'daki temel bir veri depolama teknolojisi olduğundan, adaya kümelenmiş ve kümelenmemiş dizin arasındaki farkı sormaktır. Kümelenmiş dizin, anahtar değerine göre sıralanmış düzende depolanan temel tablodur. Satırlar tek bir sırada depolanabildiği için, belirli bir tabloda yalnızca bir kümelenmiş dizin olabilir. Kümelenmiş dizini olmayan bir tablo yığın olarak adlandırılır ve yığınlar genellikle yalnızca hazırlama tabloları olarak kullanılır. Önemli bir performans tasarım ilkesi, kümelenmiş dizin anahtarınızı mümkün olduğunca dar tutmaktır. Kümelenmiş dizininizin anahtar sütunlarını göz önünde bulundurarak benzersiz veya çok sayıda farklı değer içeren sütunları dikkate almanız gerekir. İyi bir kümelenmiş dizin anahtarının bir diğer özelliği de sırayla erişilen ve tablodan alınan verileri sıralamak için sık kullanılan kayıtlardır. Kümelenmiş dizinin sıralama için kullanılan sütunda olması, veriler istenen düzende zaten depolanacağından, sorgu her yürütülürken sıralama maliyetini engelleyebilir.
Not
Tablonun belirli bir sırada 'depolandığını' söylediğimizde, fiziksel, disk içi sırasına değil mantıksal düzene başvuruyoruz. Dizinler sayfalar arasında işaretçilere sahiptir ve işaretçiler mantıksal düzenin oluşturulmasına yardımcı olur. 'Sıralı' bir dizini tararken, SQL Server işaretçileri sayfadan sayfaya izler. Dizin oluşturulduktan hemen sonra, büyük olasılıkla diskte fiziksel sırada depolanır, ancak verilerde değişiklik yapmaya başladıktan ve dizine yeni sayfaların eklenmesi gerektiğinde işaretçiler bize doğru mantıksal sırayı verir, ancak yeni sayfalar fiziksel disk sırasına uygun olmayacaktır.
Kümelenmemiş dizinler
Kümelenmemiş dizinler veri satırlarından ayrı bir yapıdır. Kümelenmemiş dizin, dizin için tanımlanan anahtar değerlerini ve anahtar değerini içeren veri satırının işaretçisini içerir. SQL Server'da eklenen sütunlar özelliğini kullanarak daha fazla sütunu kapsayacak şekilde, kümelenmemiş dizinin yaprak düzeyine başka bir anahtar olmayan sütun ekleyebilirsiniz. Tabloda birden çok kümelenmemiş dizin oluşturabilirsiniz.
Dizin eklemeniz veya var olan bir dizine sütun eklemeniz gerektiğinde aşağıda bir örnek gösterilmiştir:

Sorgu planı, dizin arama kullanılarak alınan her satır için kümelenmiş dizinden (tablonun kendisinden) daha fazla veri alınması gerektiğini belirtir. Kümelenmemiş bir dizin vardır, ancak yalnızca ürün sütununu içerir. Sorgudaki diğer sütunları aşağıda gösterildiği gibi kümelenmemiş bir dizine eklerseniz, anahtar aramasını ortadan kaldırmak için yürütme planı değişikliğini görebilirsiniz.

Yukarıda oluşturulan dizin, anahtar sütununa ek olarak sorguyu kapsayan ve tablonun kendisine erişme gereksinimini ortadan kaldıran ek sütunlar dahil ettiğiniz bir kapsayan dizin örneğidir.
Hem kümelenmemiş hem de kümelenmiş dizinler benzersiz olarak tanımlanabilir; bu da anahtar değerlerinin yinelenmemesi anlamına gelir. Bir tabloda BİrİnCİl ANAHTAR veya BENZERSİz kısıtlaması oluşturduğunuzda benzersiz dizinler otomatik olarak oluşturulur.
Bu bölümün odak noktası SQL Server'daki b ağacı dizinleridir; bunlar satır deposu dizinleri olarak da bilinir. B ağacının genel yapısı aşağıda gösterilmiştir:
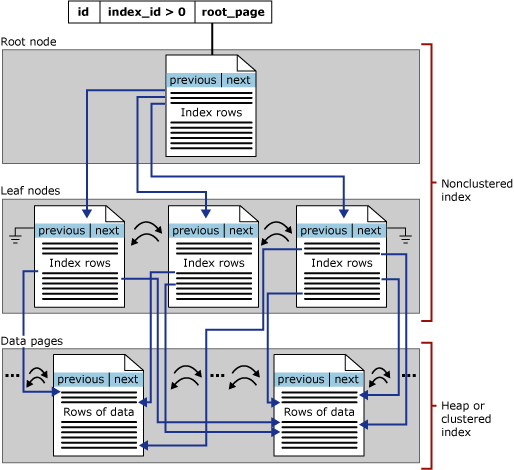
Bir dizin b ağacındaki her sayfa dizin düğümü olarak adlandırılır ve b ağacının üst düğümü kök düğüm olarak adlandırılır. Bir dizindeki alt düğümler yaprak düğümler olarak adlandırılır ve yaprak düğüm koleksiyonu yaprak düzeyidir.
Dizin tasarımı, sanat ve bilimin bir karışımıdır. Anahtarında birkaç sütun bulunan dar bir dizin, güncelleştirilmesi için daha az zaman gerektirir ve daha az bakım yüküne sahiptir; ancak daha fazla sütun içeren daha geniş bir dizin kadar çok sorgu için yararlı olmayabilir. Uygulamanızın sorguları tarafından seçilen sütunlara göre birkaç dizin oluşturma yaklaşımı denemeniz gerekebilir. Sorgu iyileştiricisi genellikle sorgu için mevcut en iyi dizin olarak kabul edeceklerini seçer; ancak bu, oluşturulabilecek daha iyi bir dizin olmadığı anlamına gelmez.
Veritabanını düzgün dizine ekleme karmaşık bir görevdir. Bir tablo için dizinlerinizi planlarken birkaç temel ilkeyi göz önünde bulundurmanız gerekir:
- Sistemin iş yüklerini anlama. Çoğunlukla ekleme işlemleri için kullanılan bir tablo, %90 okuma etkinliği olan veri ambarı işlemleri için kullanılan tablodan çok daha az ek dizinden yararlanır.
- En sık çalıştırılacak sorguları anlayın ve dizinlerinizi bu sorgular etrafında iyileştirin.
- Sorgularınızda kullanılan sütunların veri türlerini anlayın. Dizinler tamsayı veri türleri veya benzersiz veya null olmayan sütunlar için idealdir.
- Koşul ve birleştirme yan tümcelerinde sık kullanılan sütunlarda kümelenmemiş dizinler oluşturun ve ek yükü önlemek için bu dizinleri mümkün olduğunca dar tutun.
- Veri boyutunuzu/hacminizi anlama – Küçük bir tablodaki tablo taraması nispeten ucuz bir işlemdir ve SQL Server, kolayca (önemsiz) olduğundan tablo taraması yapmaya karar verebilir. Büyük bir tabloda tablo taraması pahalıya patlar.
SQL Server'ın sağladığı bir diğer seçenek de filtrelenmiş dizinlerin oluşturulmasıdır. Filtrelenmiş dizinler, satırların büyük bir yüzdesinin bu sütunda aynı değere sahip olduğu büyük tablolardaki sütunlara en uygun olanıdır. Aşağıda gösterildiği gibi, ayrılan veya kullanımdan kaldırılanlar da dahil olmak üzere tüm çalışanların kayıtlarını depolayan bir çalışan tablosu pratik bir örnektir.
CREATE TABLE [HumanResources].[Employee](
[BusinessEntityID] [int] NOT NULL,
[NationalIDNumber] [nvarchar](15) NOT NULL,
[LoginID] [nvarchar](256) NOT NULL,
[OrganizationNode] [hierarchyid] NULL,
[OrganizationLevel] AS ([OrganizationNode].[GetLevel]()),
[JobTitle] [nvarchar](50) NOT NULL,
[BirthDate] [date] NOT NULL,
[MaritalStatus] [nchar](1) NOT NULL,
[Gender] [nchar](1) NOT NULL,
[HireDate] [date] NOT NULL,
[SalariedFlag] [bit] NOT NULL,
[VacationHours] [smallint] NOT NULL,
[SickLeaveHours] [smallint] NOT NULL,
[CurrentFlag] [bit] NOT NULL,
[rowguid] [uniqueidentifier] ROWGUIDCOL NOT NULL,
[ModifiedDate] [datetime] NOT NULL)
Bu tabloda CurrentFlag adlı bir sütun vardır ve bu sütun şu anda bir çalışanın işe alınmış olup olmadığını gösterir. Bu örnekte bit veri türü kullanılır ve bu değerlerden biri şu anda kullanılmakta olan ve sıfır olan yalnızca iki değeri gösterir. CurrentFlag sütunundaki ile filtrelenmiş dizinWHERE CurrentFlag = 1, geçerli çalışanların verimli sorgularını sağlar.
Ayrıca, görünümler toplamalar ve/veya tablo birleştirmeleri gibi sorgu öğeleri içerdiğinde önemli performans kazanımları sağlayabilecek görünümlerde dizinler oluşturabilirsiniz.
Columnstore dizinleri
Columnstore, büyük toplama iş yükleri çalıştıran sorgular için geliştirilmiş performans sunar. Bu tür dizinler başlangıçta veri ambarlarını hedeflemiştir, ancak zaman içinde columnstore dizinleri büyük tablolardaki sorgu performansı sorunlarını çözmeye yardımcı olmak için diğer birçok iş yükünde kullanılmıştır. SQL Server 2014 itibarıyla hem kümelenmemiş hem de kümelenmiş columnstore dizinleri vardır. B ağacı dizinleri gibi kümelenmiş columnstore dizini de tablonun kendisi özel bir şekilde depolanır ve kümelenmemiş columnstore dizinleri tablodan bağımsız olarak depolanır. Kümelenmiş columnstore dizinleri doğal olarak belirli bir tablodaki tüm sütunları içerir. Ancak, rowstore kümelenmiş dizinlerinden farklı olarak, kümelenmiş columnstore dizinleri sıralanmaz.
Kümelenmemiş columnstore dizinleri genellikle iki senaryoda kullanılır; birincisi tablodaki bir sütunun columnstore dizininde desteklenmeyen bir veri türüne sahip olmasıdır. Çoğu veri türü desteklenir ancak XML, CLR, sql_variant, ntext, metin ve görüntü columnstore dizininde desteklenmez. Kümelenmiş columnstore her zaman tablonun tüm sütunlarını içerdiğinden (tablo olduğundan), tek seçenek kümelenmemiş bir sütundur. İkinci senaryo filtrelenmiş bir dizindir; bu senaryo, verilerin temel alınan tabloya yüklendiği ve aynı zamanda raporların tabloda çalıştırıldığı karma işlem analizi işleme (HTAP) adlı bir mimaride kullanılır. Dizin filtrelenerek (genellikle bir tarih alanında), bu tasarım hem iyi ekleme hem de raporlama performansı sağlar.
Columnstore dizinleri, depolama mekanizmalarında benzersizdir ve dizindeki her sütun bağımsız olarak depolanır. İki katlı bir avantaj sunar. Columnstore dizini kullanan bir sorgunun yalnızca sorguyu karşılamak için gereken sütunları taraması gerekir ve gerçekleştirilen toplam GÇ'yi azaltır ve aynı sütundaki veriler büyük olasılıkla benzer olacağından daha fazla sıkıştırmaya olanak tanır.
Columnstore dizinleri, veri ambarı içindeki olgu tabloları gibi büyük miktarda veriyi taraan analiz sorgularında en iyi performansı gösterir. SQL Server 2016'dan başlayarak, bir columnstore dizinini başka bir b ağacı kümelenmemiş dizinle genişletebilirsiniz. Bu, bazı sorgularınızın tek değerlerle arama yapması durumunda yararlı olabilir.
Columnstore dizinleri, bir satır kümesini (genellikle 900 civarında) tek seferde işlemeye ve bu satırları tek tek işleyen veritabanı altyapısına karşılık gelen toplu yürütme modundan da yararlanmaktadır. Sorgu altyapısı, her kaydı bağımsız olarak yükleyip işlemek yerine hesaplamayı 900 kayıtlık bir grupta hesaplar. Bu işleme modeli, CPU yönergelerinin sayısını önemli ölçüde azaltır.
SELECT SUM(Sales) FROM SalesAmount;
Toplu iş modu, geleneksel satır işlemeye göre önemli performans artışı sağlayabilir. SQL Server 2019, satır deposu verileri için toplu iş modunu da içerir. Rowstore için toplu iş modu, columnstore diziniyle aynı okuma performansı düzeyine sahip olmasa da analiz sorguları en fazla 5 kat performans geliştirmesi görebilir.
Veri ambarı iş yüklerine sunulan diğer avantaj columnstore dizinleri, 102.400 veya daha fazla satırlık toplu ekleme işlemleri için iyileştirilmiş bir yük yoludur. 102.400 doğrudan columnstore'a yüklenecek en düşük değer olsa da, satır grubu olarak adlandırılan her satır koleksiyonu yaklaşık 1.024.000 satıra kadar olabilir. Daha az ama daha dolu satır gruplarının olması SELECT sorgularınızı daha verimli hale getirir çünkü istenen kayıtları almak için daha az satır grubunun taranmış olması gerekir. Bu yükler bellekte gerçekleşir ve doğrudan dizine yüklenir. Daha küçük birimler için veriler delta deposu olarak adlandırılan bir b ağacı yapısına yazılır ve zaman uyumsuz olarak dizine yüklenir.
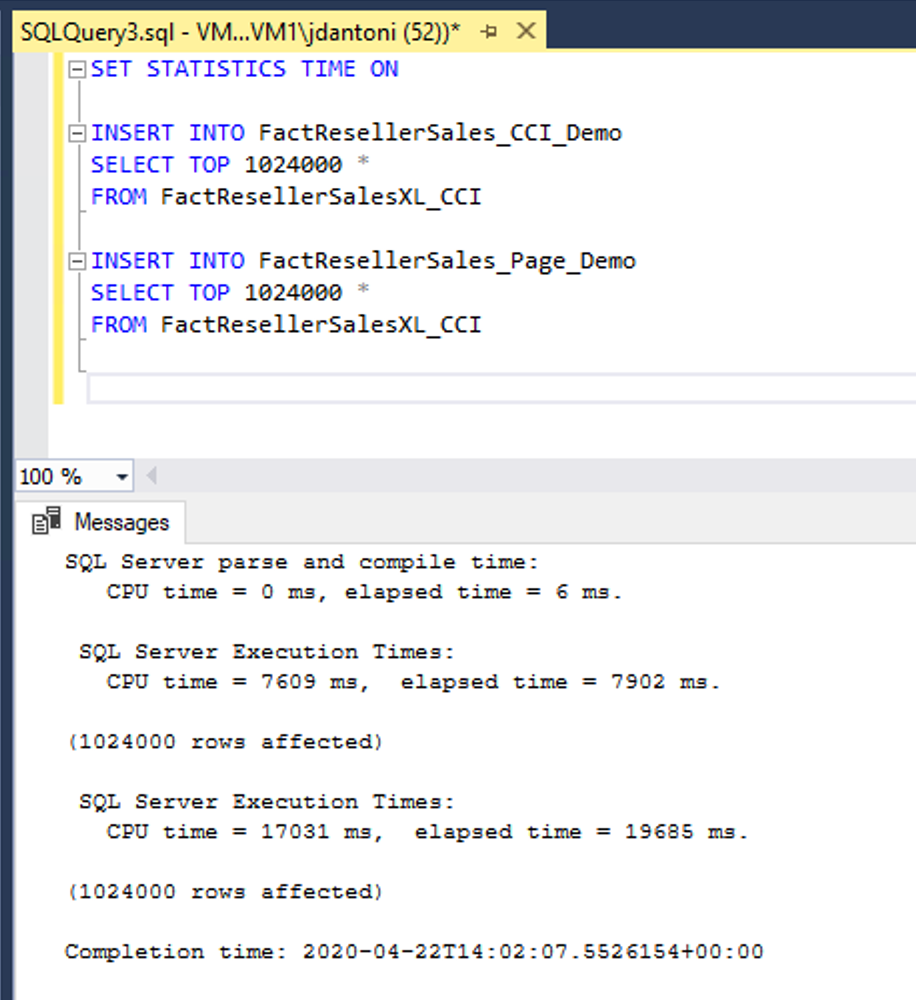
Bu örnekte, aynı veriler FactResellerSales_CCI_Demo ve FactResellerSales_Page_Demo olmak üzere iki tabloya yüklenmektedir. FactResellerSales_CCI_Demo kümelenmiş columnstore dizini vardır ve FactResellerSales_Page_Demo iki sütunlu kümelenmiş bir b ağacı dizini vardır ve sayfa sıkıştırılmıştır. Gördüğünüz gibi her tablo, FactResellerSalesXL_CCI tablosundan 1.024.000 satır yüklüyor. olduğunda SET STATISTICS TIMEON, SQL Server sorgu yürütmenin geçen süresini izler. Verilerin columnstore tablosuna yüklenmesi yaklaşık 8 saniye sürdü ve sayfa sıkıştırılmış tabloya yükleme yaklaşık 20 saniye sürdü. Bu örnekte columnstore dizinine giden tüm satırlar tek bir satır grubuna yüklenir.
Tek bir işlemde columnstore dizinine 102.400'den az veri satırı yüklerseniz, delta deposu olarak bilinen bir b ağacı yapısına yüklenir. Veritabanı altyapısı, tanımlama grubu taşıyıcısı olarak adlandırılan zaman uyumsuz bir işlem kullanarak bu verileri columnstore dizinine taşır. Açık delta depolarının olması sorgularınızın performansını etkileyebilir çünkü bu kayıtları okumak columnstore'dan okumaktan daha az verimlidir. Ayrıca, delta depolarını columnstore dizinlerine eklemeye ve sıkıştırmaya zorlamak için dizini seçeneğiyle COMPRESS_ALL_ROW_GROUPS yeniden düzenleyebilirsiniz.