Çok dilli belgelerde OCR gerçekleştirme
Optik karakter tanıma (OCR), görüntülerden veya ekrandan metin almanızı ve ayıklamanızı sağlar.
Çoğu senaryo belirli bir dilde metni işlemeniz gerekirken ancak kaynakların çok dilli olduğu durumlar vardır.
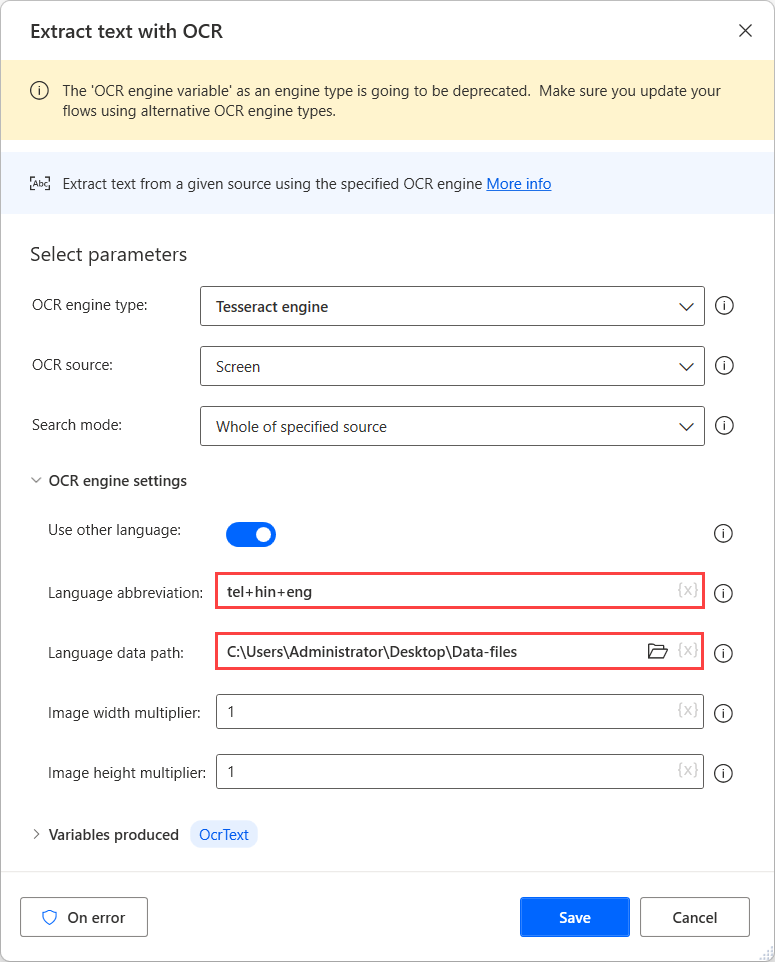
Bu kaynaklarda OCR işlemi yapmak için, ilgili OCR eyleminde bir Tesseract motoru kullanın ve altyapı ayarlarında Diğer dilleri kullan seçeneğini etkinleştirin.
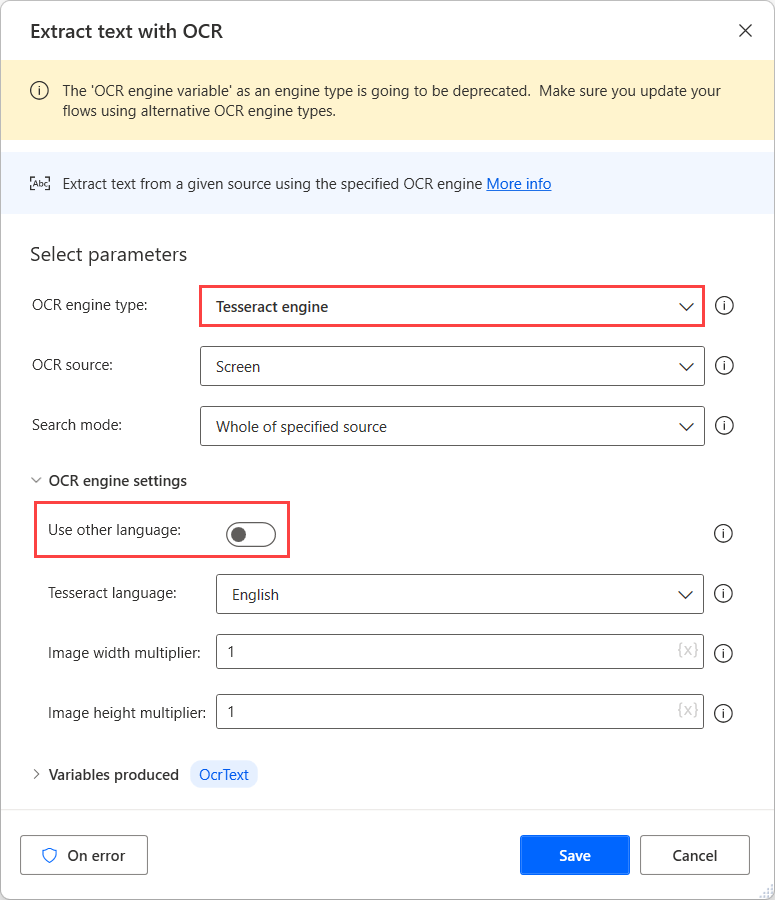
Diğer dilleri kullan seçeneği etkinleştirildiğinde, eylem iki ek ayar görüntüler: Dil kısaltması ve Dil veri yolu alanları.
Dil kısaltması alanı, hangi dilin OCR sırasında aranması gerektiğini altyapıya gösterir. Dil veri yolu alanı, OCR altyapısını eğitmek için kullanılan dil veri dosyalarını (.traineddata) içerir.
Gerekli dillerin veri dosyalarını yükledikten sonra, bunları aynı yol altında kullanabilmek için ortak bir klasöre taşıyın.
Sonra, Dil veri yolu alanında oluşturulan klasörü seçin ve Dil kısaltması alanında karşılık gelen dil kodlarını doldurun. Dil kodlarını ayırmak için artı karakterini (+) kullanın.
Not
Dil veri dosyalarının kaynağı içinde kullanılabilir tüm dil kodlarını bulabilirsiniz. Aşağıdaki örnekte, kullanılan kodlar Telugu, Hintçe ve İngilizce'yi temsil eder.