你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn 。
自动缩放联机终结点
本文内容
适用范围:Azure CLI ml 扩展 v2(最新版) Python SDK azure-ai-ml v2(最新版)
自动缩放会自动运行适量的资源来处理应用程序的负载。 联机终结点 支持通过与 Azure Monitor 自动缩放功能的集成进行自动缩放。
Azure Monitor 自动缩放支持一组丰富的规则。 可以配置基于指标的缩放(例如,CPU 利用率 >70%)、基于计划的缩放(例如,针对业务高峰期的缩放规则)或两者的组合。 有关详细信息,请参阅 Microsoft Azure 中的自动缩放概述 。
目前,可以使用 Azure CLI、REST、ARM 或基于浏览器的 Azure 门户来管理自动缩放。 今后也会添加对其他 Azure 机器学习 SDK(例如 Python SDK)的支持。
先决条件
定义自动缩放配置文件
若要为终结点启用自动缩放,首先要定义自动缩放配置文件。 此配置文件定义默认、最小和最大规模集容量。 以下示例将默认容量和最小容量设置为两个 VM 实例,将最大容量设置为五个 VM 实例:
适用于:Azure CLI ml 扩展 v2(当前版)
以下代码片段设置终结点和部署名称:
# set your existing endpoint name
ENDPOINT_NAME=your-endpoint-name
DEPLOYMENT_NAME=blue
接下来,获取部署和终结点的 Azure 资源管理器 ID:
# ARM id of the deployment
DEPLOYMENT_RESOURCE_ID=$(az ml online-deployment show -e $ENDPOINT_NAME -n $DEPLOYMENT_NAME -o tsv --query "id")
# ARM id of the deployment. todo: change to --query "id"
ENDPOINT_RESOURCE_ID=$(az ml online-endpoint show -n $ENDPOINT_NAME -o tsv --query "properties.\"azureml.onlineendpointid\"")
# set a unique name for autoscale settings for this deployment. The below will append a random number to make the name unique.
AUTOSCALE_SETTINGS_NAME=autoscale-$ENDPOINT_NAME-$DEPLOYMENT_NAME-`echo $RANDOM`
以下代码片段创建自动缩放配置文件:
az monitor autoscale create \
--name $AUTOSCALE_SETTINGS_NAME \
--resource $DEPLOYMENT_RESOURCE_ID \
--min-count 2 --max-count 5 --count 2
适用于:Python SDK azure-ai-ml v2(当前版本)
导入模块:
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
from azure.mgmt.monitor import MonitorManagementClient
from azure.mgmt.monitor.models import AutoscaleProfile, ScaleRule, MetricTrigger, ScaleAction, Recurrence, RecurrentSchedule
import random
import datetime
为工作区、终结点和部署定义变量:
subscription_id = "<YOUR-SUBSCRIPTION-ID>"
resource_group = "<YOUR-RESOURCE-GROUP>"
workspace = "<YOUR-WORKSPACE>"
endpoint_name = "<YOUR-ENDPOINT-NAME>"
deployment_name = "blue"
获取 Azure 机器学习和 Azure Monitor 客户端:
credential = DefaultAzureCredential()
ml_client = MLClient(
credential, subscription_id, resource_group, workspace
)
mon_client = MonitorManagementClient(
credential, subscription_id
)
获取终结点和部署对象:
deployment = ml_client.online_deployments.get(
deployment_name, endpoint_name
)
endpoint = ml_client.online_endpoints.get(
endpoint_name
)
创建自动缩放配置文件:
# Set a unique name for autoscale settings for this deployment. The below will append a random number to make the name unique.
autoscale_settings_name = f"autoscale-{endpoint_name}-{deployment_name}-{random.randint(0,1000)}"
mon_client.autoscale_settings.create_or_update(
resource_group,
autoscale_settings_name,
parameters = {
"location" : endpoint.location,
"target_resource_uri" : deployment.id,
"profiles" : [
AutoscaleProfile(
name="my-scale-settings",
capacity={
"minimum" : 2,
"maximum" : 5,
"default" : 2
},
rules = []
)
]
}
)
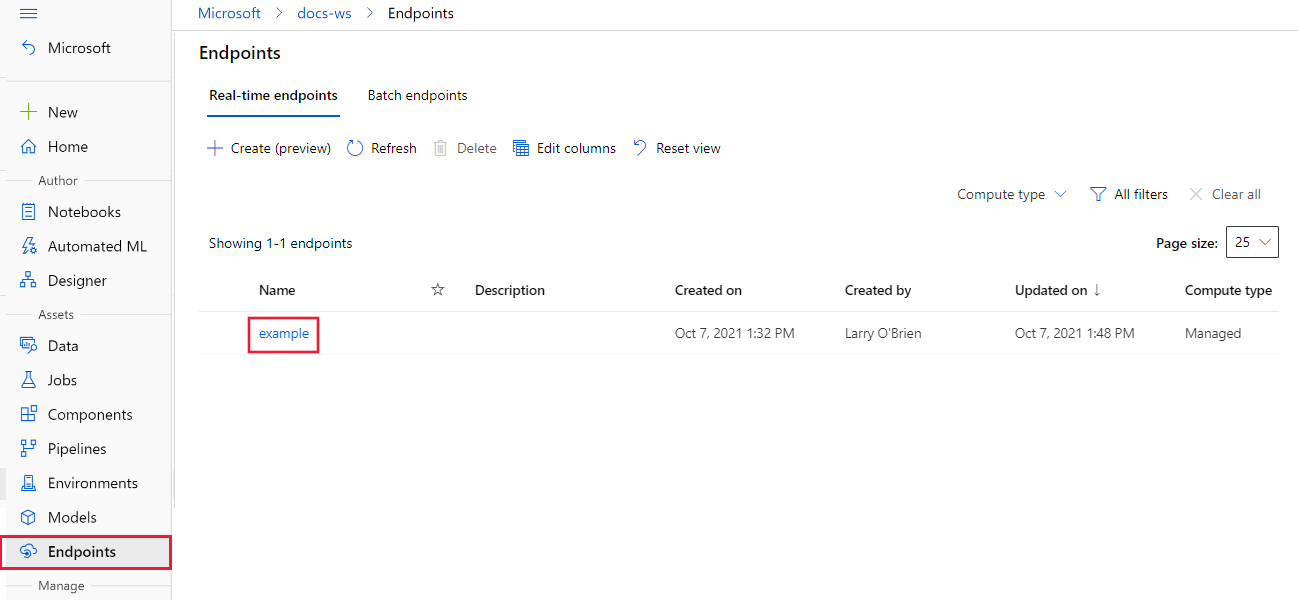
在 Azure 机器学习工作室 中选择你的工作区,然后在页面左侧选择“终结点”。 列出终结点后,选择要配置的终结点。
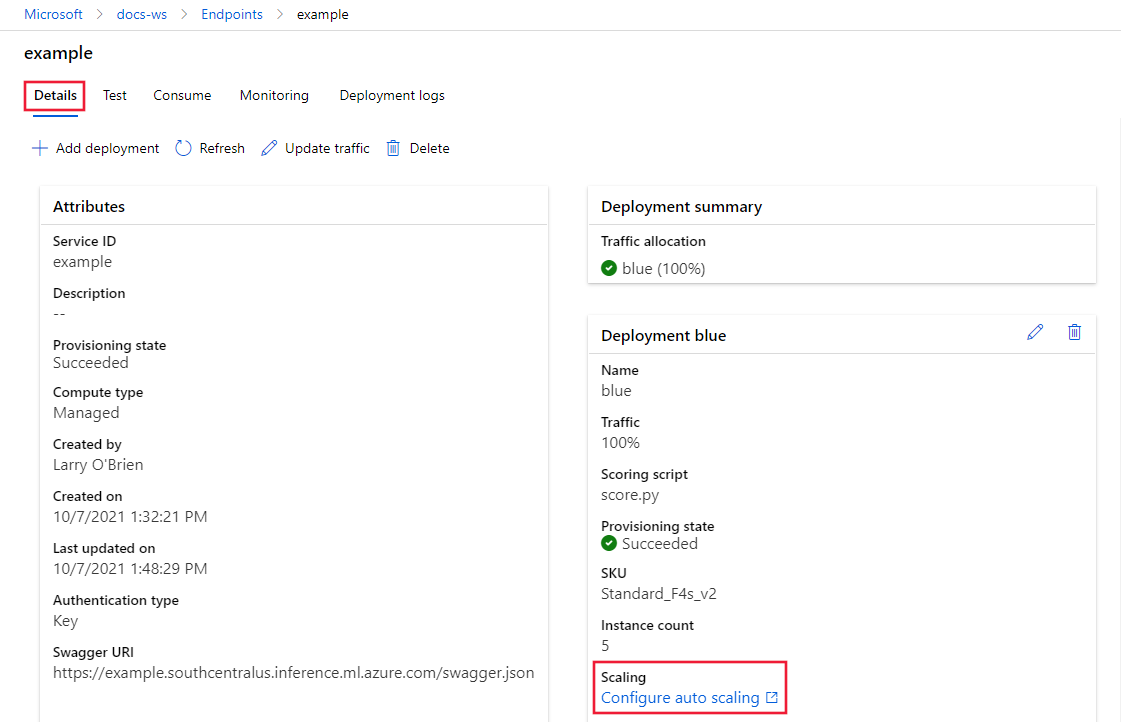
在终结点的“详细信息”选项卡中,选择“配置自动缩放” 。
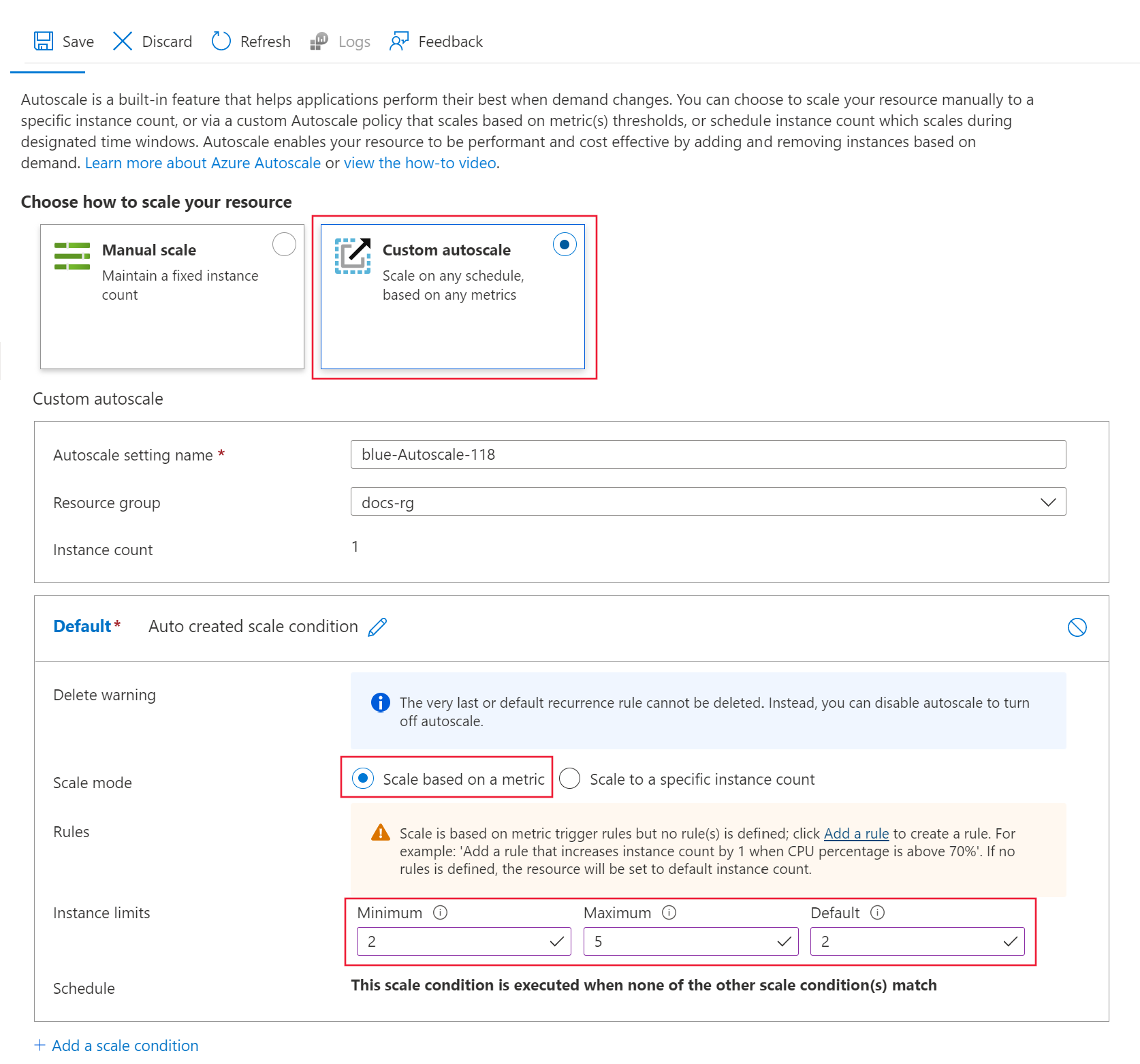
在“选择如何缩放资源”下,选择“自定义自动缩放”开始进行配置 。 对于默认缩放条件,请使用以下值:
将“缩放模式”设置为“基于指标缩放” 。
将“最小值”设置为“2” 。
将“最大值”设置为“5” 。
将“默认值”设置为“2” 。
使用指标创建横向扩展规则
常用的横向扩展规则是在平均 CPU 负载较高时增加 VM 实例数目。 如果 CPU 平均负载持续 5 分钟大于 70%,则以下示例将再分配两个节点(不超过最大数量):
适用于:Azure CLI ml 扩展 v2(当前版)
az monitor autoscale rule create \
--autoscale-name $AUTOSCALE_SETTINGS_NAME \
--condition "CpuUtilizationPercentage > 70 avg 5m" \
--scale out 2
该规则是 my-scale-settings 配置文件的一部分(autoscale-name 与配置文件的 name 匹配)。 condition 参数的值表示当“VM 实例中的平均 CPU 使用率在 5 分钟内超过 70%”时,规则应触发。满足该条件时,将分配两个以上的 VM 实例。
适用于:Python SDK azure-ai-ml v2(当前版本)
创建规则定义:
rule_scale_out = ScaleRule(
metric_trigger = MetricTrigger(
metric_name="CpuUtilizationPercentage",
metric_resource_uri = deployment.id,
time_grain = datetime.timedelta(minutes = 1),
statistic = "Average",
operator = "GreaterThan",
time_aggregation = "Last",
time_window = datetime.timedelta(minutes = 5),
threshold = 70
),
scale_action = ScaleAction(
direction = "Increase",
type = "ChangeCount",
value = 2,
cooldown = datetime.timedelta(hours = 1)
)
)
此规则针对的是 metric_name、time_window、 和 time_aggregation 中的 CPUUtilizationpercentage 最后 5 分钟的平均值。 当该指标的值大于 70 的 threshold 时,系统会再分配两个 VM 实例。
更新 my-scale-settings 配置文件以包含此规则:
mon_client.autoscale_settings.create_or_update(
resource_group,
autoscale_settings_name,
parameters = {
"location" : endpoint.location,
"target_resource_uri" : deployment.id,
"profiles" : [
AutoscaleProfile(
name="my-scale-settings",
capacity={
"minimum" : 2,
"maximum" : 5,
"default" : 2
},
rules = [
rule_scale_out
]
)
]
}
)
在“规则”部分,单击“添加规则” 。 此时会显示“缩放规则”页。 使用以下信息填充此页上的字段:
将“指标名称”设置为“CPU 利用率百分比” 。
将“运算符”设置为“大于”,将“指标阈值”设置为“70” 。
将“持续时间(分钟)”设置为“5”。 将“时间粒度统计”保留为“平均” 。
将“操作”设置为“将计数增加”,将“实例计数”设置为“2” 。
最后,选择“添加”按钮创建规则。
使用指标创建横向缩减规则
当负载较轻时,横向缩减规则可以减少 VM 实例数目。 如果 CPU 负载持续 5 分钟小于 30%,则以下示例将释放单个节点,但至少保留 2 个:
适用于:Azure CLI ml 扩展 v2(当前版本)
az monitor autoscale rule create \
--autoscale-name $AUTOSCALE_SETTINGS_NAME \
--condition "CpuUtilizationPercentage < 25 avg 5m" \
--scale in 1
适用于:Python SDK azure-ai-ml v2(当前版本)
创建规则定义:
rule_scale_in = ScaleRule(
metric_trigger = MetricTrigger(
metric_name="CpuUtilizationPercentage",
metric_resource_uri = deployment.id,
time_grain = datetime.timedelta(minutes = 1),
statistic = "Average",
operator = "LessThan",
time_aggregation = "Last",
time_window = datetime.timedelta(minutes = 5),
threshold = 30
),
scale_action = ScaleAction(
direction = "Increase",
type = "ChangeCount",
value = 1,
cooldown = datetime.timedelta(hours = 1)
)
)
更新 my-scale-settings 配置文件以包含此规则:
mon_client.autoscale_settings.create_or_update(
resource_group,
autoscale_settings_name,
parameters = {
"location" : endpoint.location,
"target_resource_uri" : deployment.id,
"profiles" : [
AutoscaleProfile(
name="my-scale-settings",
capacity={
"minimum" : 2,
"maximum" : 5,
"default" : 2
},
rules = [
rule_scale_out,
rule_scale_in
]
)
]
}
)
在“规则”部分,单击“添加规则” 。 此时会显示“缩放规则”页。 使用以下信息填充此页上的字段:
将“指标名称”设置为“CPU 利用率百分比” 。
将“运算符”设置为“小于”,将“指标阈值”设置为“30” 。
将“持续时间(分钟)”设置为“5” 。
将“操作”设置为“将计数减少”,将“实例计数”设置为“1” 。
最后,选择“添加”按钮创建规则。
如果你同时使用横向扩展和横向缩减规则,则规则将类似于以下屏幕截图。 你已指定,如果平均 CPU 负载持续 5 分钟超过 70%,则应再分配 2 个节点,但不超过 5 个的限制。 如果 CPU 负载持续 5 分钟小于 30%,则应释放单个节点,但至少保留 2 个。
基于终结点指标创建缩放规则
上述规则将应用于部署。 现在,请添加应用于终结点的规则。 在此示例中,如果请求延迟持续 5 分钟大于 70 毫秒的平均值,则分配另一个节点。
适用于:Azure CLI ml 扩展 v2(当前版本)
az monitor autoscale rule create \
--autoscale-name $AUTOSCALE_SETTINGS_NAME \
--condition "RequestLatency > 70 avg 5m" \
--scale out 1 \
--resource $ENDPOINT_RESOURCE_ID
适用于:Python SDK azure-ai-ml v2(当前版本)
创建规则定义:
rule_scale_out_endpoint = ScaleRule(
metric_trigger = MetricTrigger(
metric_name="RequestLatency",
metric_resource_uri = endpoint.id,
time_grain = datetime.timedelta(minutes = 1),
statistic = "Average",
operator = "GreaterThan",
time_aggregation = "Last",
time_window = datetime.timedelta(minutes = 5),
threshold = 70
),
scale_action = ScaleAction(
direction = "Increase",
type = "ChangeCount",
value = 1,
cooldown = datetime.timedelta(hours = 1)
)
)
该规则的 metric_resource_uri 字段现在指向的是终结点,而不是部署。
更新 my-scale-settings 配置文件以包含此规则:
mon_client.autoscale_settings.create_or_update(
resource_group,
autoscale_settings_name,
parameters = {
"location" : endpoint.location,
"target_resource_uri" : deployment.id,
"profiles" : [
AutoscaleProfile(
name="my-scale-settings",
capacity={
"minimum" : 2,
"maximum" : 5,
"default" : 2
},
rules = [
rule_scale_out,
rule_scale_in,
rule_scale_out_endpoint
]
)
]
}
)
在页面底部,选择“+ 添加缩放条件”。
依次选择“基于指标缩放”、“添加规则” 。 此时会显示“缩放规则”页。 使用以下信息填充此页上的字段:
将“指标源”设置为“其他资源” 。
将“资源类型”设置为“机器学习联机终结点” 。
将“资源”设置为你的终结点。
将“指标名称”设置为“请求延迟” 。
将“运算符”设置为“大于”,将“指标阈值”设置为“70” 。
将“持续时间(分钟)”设置为“5” 。
将“操作”设置为“将计数增加”,将“实例计数”设置为“1”
基于计划创建缩放规则
还可以创建仅在特定日期或特定时间应用的规则。 此示例将周末的节点计数设置为 2。
适用于:Azure CLI ml 扩展 v2(当前版本)
az monitor autoscale profile create \
--name weekend-profile \
--autoscale-name $AUTOSCALE_SETTINGS_NAME \
--min-count 2 --count 2 --max-count 2 \
--recurrence week sat sun --timezone "Pacific Standard Time"
适用于:Python SDK azure-ai-ml v2(当前版本)
mon_client.autoscale_settings.create_or_update(
resource_group,
autoscale_settings_name,
parameters = {
"location" : endpoint.location,
"target_resource_uri" : deployment.id,
"profiles" : [
AutoscaleProfile(
name="Default",
capacity={
"minimum" : 2,
"maximum" : 2,
"default" : 2
},
recurrence = Recurrence(
frequency = "Week",
schedule = RecurrentSchedule(
time_zone = "Pacific Standard Time",
days = ["Saturday", "Sunday"],
hours = [],
minutes = []
)
)
)
]
}
)
在页面底部,选择“+ 添加缩放条件”。 在新的缩放条件下,使用以下信息填充字段:
选择“缩放到特定实例计数”。
将“实例计数”设置为“2” 。
将“计划”设置为“在特定的日期重复” 。
将计划设置为“在每个星期六和星期日重复”。
删除资源
如果你不打算使用自己的部署,请将其删除:
适用于:Azure CLI ml 扩展 v2(当前版本)
# delete the autoscaling profile
az monitor autoscale delete -n "$AUTOSCALE_SETTINGS_NAME"
# delete the endpoint
az ml online-endpoint delete --name $ENDPOINT_NAME --yes --no-wait
适用于:Python SDK azure-ai-ml v2(当前版本)
mon_client.autoscale_settings.delete(
resource_group,
autoscale_settings_name
)
ml_client.online_endpoints.begin_delete(endpoint_name)
后续步骤
若要详细了解如何使用 Azure Monitor 进行自动缩放,请参阅以下文章:
 Azure CLI ml 扩展 v2(最新版)
Azure CLI ml 扩展 v2(最新版)