此參考架構示範如何使用 Azure Databricks 定型建議模型,然後使用 Azure Cosmos DB、Azure 機器學習 和 Azure Kubernetes Service (AKS) 將模型部署為 API。 如需此架構的參考實作,請參閱 在 GitHub 上建置即時建議 API 。
架構
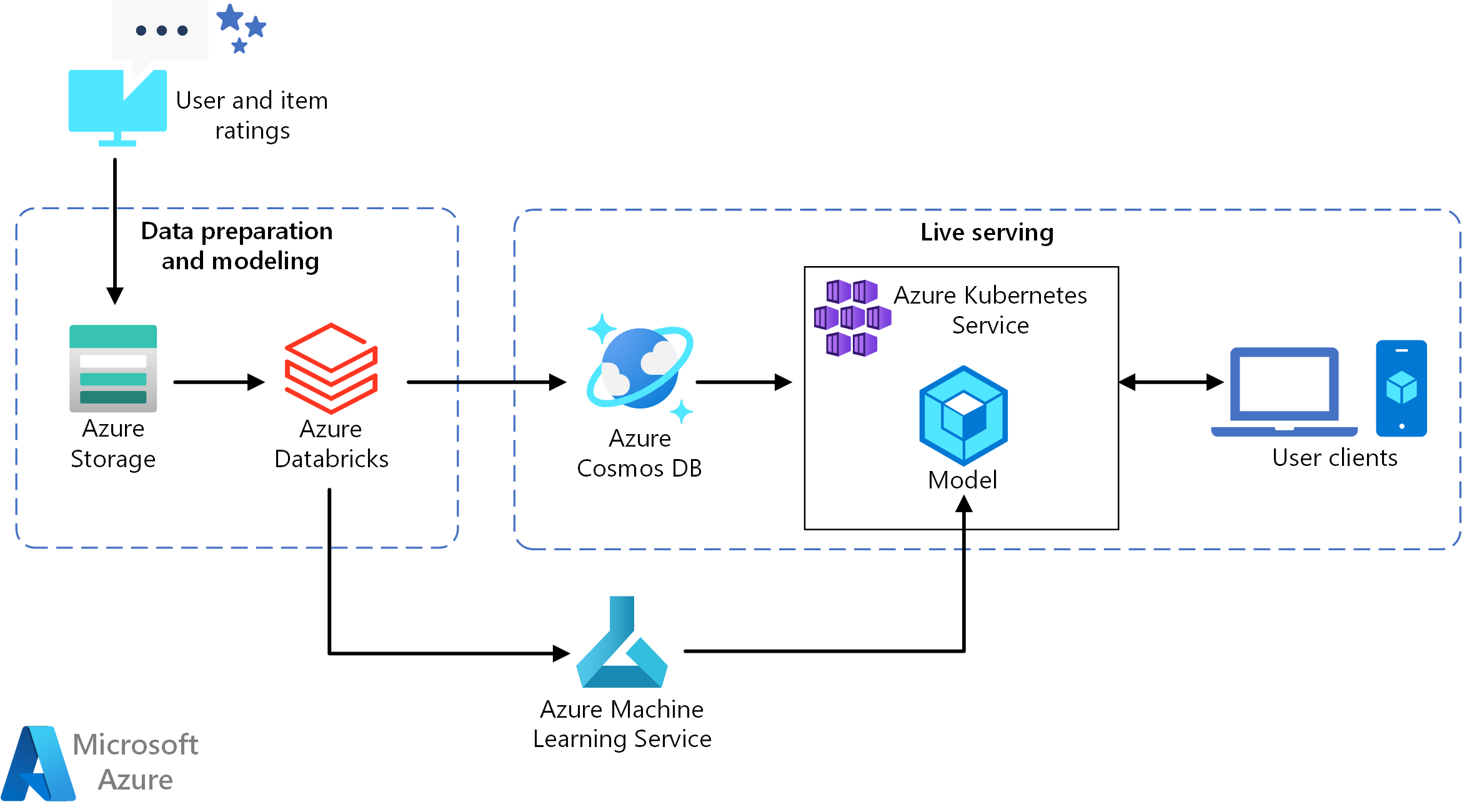
此參考架構適用於訓練和部署實時推薦服務 API,可為使用者提供前 10 名影片建議。
資料流程
- 追蹤用戶行為。 例如,當用戶評分電影或單擊產品或新聞文章時,後端服務可能會記錄。
- 從可用的 數據源將數據載入 Azure Databricks。
- 準備數據,並將其分割成定型和測試集,以定型模型。 (本指南 說明分割數據的選項。
- 將 Spark 共同作業篩選模型放入數據。
- 使用評等和排名計量來評估模型的品質。 (本指南 提供可用來評估推薦的計量詳細數據。
- 預先計算每個使用者的前 10 項建議,並將它儲存為 Azure Cosmos DB 中的快取。
- 使用 機器學習 API 將 API 服務部署至 AKS,以容器化和部署 API。
- 當後端服務從使用者取得要求時,呼叫 AKS 中裝載的建議 API 以取得前 10 項建議,並向使用者顯示建議。
元件
- Azure Databricks。 Databricks 是開發環境,可用來準備輸入數據,並在Spark叢集上定型推薦模型。 Azure Databricks 也提供互動式工作區,以在任何數據處理或機器學習工作的筆記本上執行和共同作業。
- Azure Kubernetes Service (AKS)。 AKS 可用來在 Kubernetes 叢集上部署和運作機器學習模型服務 API。 AKS 裝載容器化模型,提供符合輸送量需求的延展性、身分識別和存取管理,以及記錄和健康情況監視。
- Azure Cosmos DB。 Azure Cosmos DB 是全域散發的資料庫服務,可用來儲存每個使用者的前 10 部建議影片。 Azure Cosmos DB 非常適合此案例,因為它提供低延遲(第 99 個百分位數為 10 毫秒)來讀取指定使用者的熱門建議專案。
- 「機器學習」。 此服務可用來追蹤和管理機器學習模型,然後將這些模型封裝並部署至可調整的 AKS 環境。
- Microsoft 建議工具。 此開放原始碼存放庫包含公用程式代碼和範例,可協助用戶開始建置、評估及運作推薦系統。
案例詳細資料
此架構可針對大部分的建議引擎案例進行一般化,包括產品、電影和新聞的建議。
潛在的使用案例
案例:媒體組織想要為其使用者提供電影或視訊建議。 藉由提供個人化的建議,組織可達成數個商務目標,包括增加點擊率、提高其網站上的參與度,以及更高的用戶滿意度。
此解決方案已針對零售產業和媒體和娛樂產業進行優化。
考量
這些考慮會實作 Azure Well-Architected Framework 的支柱,這是一組指導原則,可用來改善工作負載的品質。 如需詳細資訊,請參閱 Microsoft Azure Well-Architected Framework。
Azure Databricks 上的 Spark 模型批次評分說明參考架構,該參考架構會使用 Spark 和 Azure Databricks 來執行排程的批次評分程式。 建議您使用此方法來產生新的建議。
效能效益
效能效率是工作負載調整的能力,以符合使用者以有效率的方式滿足其需求。 如需詳細資訊,請參閱 效能效率要素概觀。
效能是實時建議的主要考慮,因為建議通常落在您的網站上使用者要求的重要路徑中。
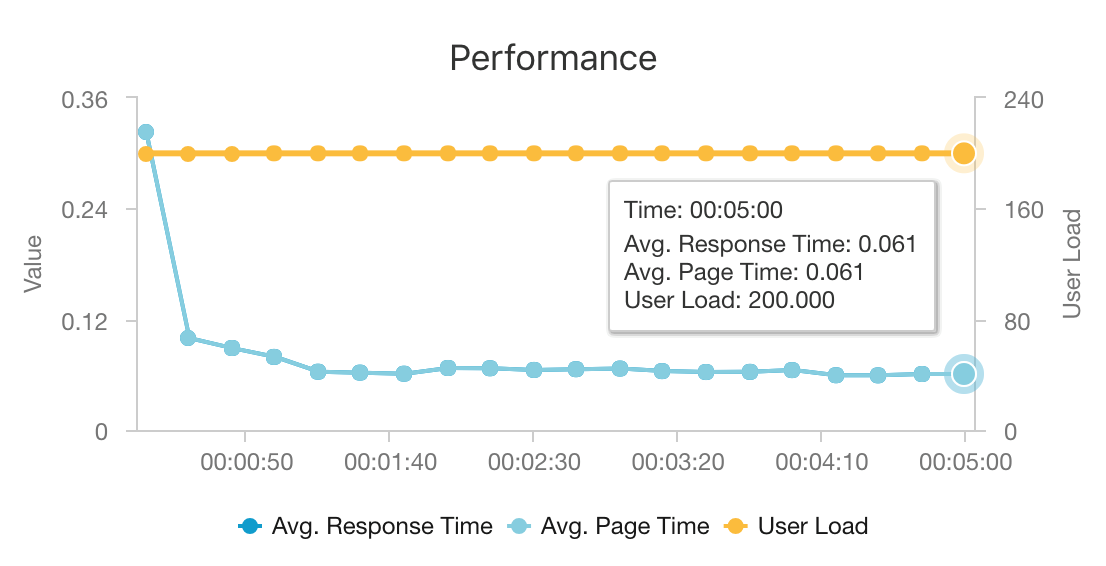
AKS 和 Azure Cosmos DB 的組合可讓此架構提供良好的起點,以提供中等大小的工作負載建議,且額外負荷最少。 在具有 200 位並行使用者的負載測試下,此架構會以大約 60 毫秒的中位數延遲提供建議,並以每秒 180 個要求的輸送量執行。 負載測試是針對為 Azure Cosmos DB 布建的每秒 12 個 vCPU、42 GB 記憶體和每秒 11,000 個要求單位 (RU) 的預設部署組態執行 (3x D3 v2 V2 AKS 叢集)。

建議使用 Azure Cosmos DB,使其周全域散發,並符合應用程式擁有的任何資料庫需求。 若要稍微降低延遲,請考慮使用 Azure Cache for Redis 而不是 Azure Cosmos DB 來提供查閱。 Azure Cache for Redis 可以改善嚴重依賴後端存放區數據的系統效能。
延展性
如果您不打算使用 Spark,或擁有不需要散發的較小工作負載,請考慮使用 資料科學虛擬機器 (DSVM) 而不是 Azure Databricks。 DSVM 是 Azure 虛擬機,具有機器學習和數據科學的深度學習架構和工具。 如同 Azure Databricks,您在 DSVM 中建立的任何模型都可以透過 機器學習,以 AKS 上的服務的形式運作。
在定型期間,在 Azure Databricks 中布建較大的固定大小 Spark 叢集,或設定 自動調整。 啟用自動調整時,Databricks 會監視叢集上的負載,並視需要相應增加和減少。 如果您有大型數據大小,而且想要減少數據準備或模型化工作所需的時間,布建或相應放大較大的叢集。
調整 AKS 叢集以符合您的效能和輸送量需求。 請小心相應增加 Pod 數目以充分利用叢集,並調整叢集的節點以符合您的服務需求。 您也可以在 AKS 叢集上設定自動調整。 如需詳細資訊,請參閱 將模型部署至 Azure Kubernetes Service 叢集。
若要管理 Azure Cosmos DB 效能,請估計每秒所需的讀取次數,並布建每秒所需的 RU 數目(輸送量)。 使用數據分割和水平調整的最佳做法。
成本最佳化
成本優化是考慮如何減少不必要的費用,並提升營運效率。 如需詳細資訊,請參閱 成本優化要素概觀。
此案例的主要成本驅動因素包括:
- 定型所需的 Azure Databricks 叢集大小。
- 符合效能需求所需的 AKS 叢集大小。
- 布建的 Azure Cosmos DB RU 符合您的效能需求。
在不使用時重新定型並關閉 Spark 叢集,以管理 Azure Databricks 成本。 AKS 和 Azure Cosmos DB 成本會系結至您的網站所需的輸送量和效能,並根據月臺的流量相應增加和減少。
部署此案例
若要部署此架構,請遵循安裝檔中的 Azure Databricks 指示。 簡單來說,指示會要求您:
- 建立 Azure Databricks 工作區。
- 在 Azure Databricks 中使用下列組態建立新的叢集:
- 叢集模式:標準
- Databricks 運行時間版本:4.3(包括 Apache Spark 2.3.1、Scala 2.11)
- Python 版本:3
- 驅動程式類型:Standard_DS3_v2
- 背景工作類型:Standard_DS3_v2(視需要最小和最大值)
- 自動終止:(視需要)
- Spark 組態:(視需要)
- 環境變數:(視需要)
- 在 Azure Databricks 工作區內建立個人存取令牌。 如需詳細資訊,請參閱 Azure Databricks 驗證 檔 。
- 將 Microsoft Recommenders 存放庫複製到您可以執行腳本的環境(例如本機電腦)。
- 請遵循快速安裝安裝指示,在 Azure Databricks 上安裝相關的連結庫。
- 請遵循快速安裝安裝指示來準備 Azure Databricks 以進行作業化。
- 將 ALS 電影作業化筆記本 匯入您的工作區。 登入 Azure Databricks 工作區之後,請執行下列動作:
- 按兩下 工作區左側的 [首頁 ]。
- 以滑鼠右鍵按下主目錄中的空格符。 選取匯入。
- 選取 [URL],然後將下列內容貼到文字欄位中:
https://github.com/Microsoft/Recommenders/blob/main/examples/05_operationalize/als_movie_o16n.ipynb - 按一下 [匯入]。
- 在 Azure Databricks 中開啟筆記本,並鏈接已設定的叢集。
- 執行筆記本來建立建立建議 API 所需的 Azure 資源,為指定使用者提供前 10 部影片建議。
參與者
本文由 Microsoft 維護。 原始投稿人如下。
主要作者:
- Miguel Fierro |主體 資料科學家 管理員
- Nikhil Joglekar |產品管理員、Azure 演算法和數據科學
若要查看非公用LinkedIn配置檔,請登入LinkedIn。
下一步
- 建置即時建議 API
- 什麼是 Azure Databricks?(機器翻譯)
- Azure Kubernetes Service
- 歡迎使用 Azure Cosmos DB
- 什麼是 Azure Machine Learning 服務?