使用圖格
您可以使用並排將應用程式的加速最大化。 並排會將執行緒分割成相等的矩形子集或 磚 。 如果您使用適當的磚大小和並排演算法,您可以從 C++ AMP 程式碼取得更多加速。 並排的基本元件包括:
tile_static變數。 並排的主要優點是存取的tile_static效能提升。 記憶體中的資料tile_static存取速度比存取全域空間中的資料(array或array_view物件)快得多。 系統會為每個磚建立變數的tile_static實例,而磚中的所有線程都可以存取變數。 在典型的並排演算法中,資料會從全域記憶體複製到tile_static記憶體一次,然後從tile_static記憶體存取多次。tile_barrier::wait 方法 。 呼叫
tile_barrier::wait會暫停目前線程的執行,直到相同磚中的所有線程都到達 對tile_barrier::wait的呼叫為止。 您無法保證執行緒將執行的順序,只有磚中沒有任何執行緒會執行到 呼叫tile_barrier::wait,直到所有線程都到達呼叫為止。 這表示,藉由使用tile_barrier::wait方法,您可以逐磚執行工作,而不是逐一線程執行工作。 典型的並排演算法有程式碼可初始化tile_static整個圖格的記憶體,後面接著呼叫tile_barrier::wait。 下列程式tile_barrier::wait代碼包含需要存取所有tile_static值的計算。本機和全域索引。 您可以存取相對於整個
array_view或array物件的執行緒索引,以及相對於磚的索引。 使用本機索引可讓您的程式碼更容易讀取和偵錯。 一般而言,您會使用本機索引來存取tile_static變數,並使用全域索引來存取array和array_view變數。tiled_extent 類別 和 tiled_index 類別 。
tiled_extent您可以使用 物件,extent而不是呼叫中的parallel_for_each物件。tiled_index您可以使用 物件,index而不是呼叫中的parallel_for_each物件。
若要利用並排,您的演算法必須將計算網域分割成磚,然後將磚資料 tile_static 複製到變數,以加快存取速度。
全域、磚和區域索引的範例
注意
從 Visual Studio 2022 17.0 版開始,C++ AMP 標頭已被取代。
包含任何 AMP 標頭將會產生建置錯誤。 先定義 _SILENCE_AMP_DEPRECATION_WARNINGS ,再包含任何 AMP 標頭以讓警告無聲。
下圖代表以 2x3 磚排列的 8x9 資料矩陣。
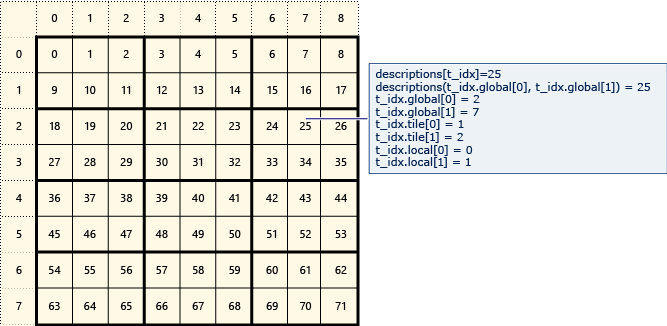
下列範例會顯示此磚矩陣的全域、磚和區域索引。 物件 array_view 是使用 類型的 Description 專案所建立。 會 Description 保存矩陣中元素的全域、磚和區域索引。 呼叫中的程式碼,可 parallel_for_each 設定每個元素之全域、磚和區域索引的值。 輸出會顯示 結構中的 Description 值。
#include <iostream>
#include <iomanip>
#include <Windows.h>
#include <amp.h>
using namespace concurrency;
const int ROWS = 8;
const int COLS = 9;
// tileRow and tileColumn specify the tile that each thread is in.
// globalRow and globalColumn specify the location of the thread in the array_view.
// localRow and localColumn specify the location of the thread relative to the tile.
struct Description {
int value;
int tileRow;
int tileColumn;
int globalRow;
int globalColumn;
int localRow;
int localColumn;
};
// A helper function for formatting the output.
void SetConsoleColor(int color) {
int colorValue = (color == 0) 4 : 2;
SetConsoleTextAttribute(GetStdHandle(STD_OUTPUT_HANDLE), colorValue);
}
// A helper function for formatting the output.
void SetConsoleSize(int height, int width) {
COORD coord;
coord.X = width;
coord.Y = height;
SetConsoleScreenBufferSize(GetStdHandle(STD_OUTPUT_HANDLE), coord);
SMALL_RECT* rect = new SMALL_RECT();
rect->Left = 0;
rect->Top = 0;
rect->Right = width;
rect->Bottom = height;
SetConsoleWindowInfo(GetStdHandle(STD_OUTPUT_HANDLE), true, rect);
}
// This method creates an 8x9 matrix of Description structures.
// In the call to parallel_for_each, the structure is updated
// with tile, global, and local indices.
void TilingDescription() {
// Create 72 (8x9) Description structures.
std::vector<Description> descs;
for (int i = 0; i < ROWS * COLS; i++) {
Description d = {i, 0, 0, 0, 0, 0, 0};
descs.push_back(d);
}
// Create an array_view from the Description structures.
extent<2> matrix(ROWS, COLS);
array_view<Description, 2> descriptions(matrix, descs);
// Update each Description with the tile, global, and local indices.
parallel_for_each(descriptions.extent.tile< 2, 3>(),
[=] (tiled_index< 2, 3> t_idx) restrict(amp)
{
descriptions[t_idx].globalRow = t_idx.global[0];
descriptions[t_idx].globalColumn = t_idx.global[1];
descriptions[t_idx].tileRow = t_idx.tile[0];
descriptions[t_idx].tileColumn = t_idx.tile[1];
descriptions[t_idx].localRow = t_idx.local[0];
descriptions[t_idx].localColumn= t_idx.local[1];
});
// Print out the Description structure for each element in the matrix.
// Tiles are displayed in red and green to distinguish them from each other.
SetConsoleSize(100, 150);
for (int row = 0; row < ROWS; row++) {
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Value: " << std::setw(2) << descriptions(row, column).value << " ";
}
std::cout << "\n";
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Tile: " << "(" << descriptions(row, column).tileRow << "," << descriptions(row, column).tileColumn << ") ";
}
std::cout << "\n";
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Global: " << "(" << descriptions(row, column).globalRow << "," << descriptions(row, column).globalColumn << ") ";
}
std::cout << "\n";
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Local: " << "(" << descriptions(row, column).localRow << "," << descriptions(row, column).localColumn << ") ";
}
std::cout << "\n";
std::cout << "\n";
}
}
int main() {
TilingDescription();
char wait;
std::cin >> wait;
}
此範例的主要工作是在 物件的定義 array_view 中,以及對 parallel_for_each 的呼叫。
結構的向量
Description會複製到 8x9array_view物件中。使用
parallel_for_each物件做為計算網域來呼叫tiled_extent方法。 物件tiled_extent是藉由呼叫extent::tile()變數的descriptions方法所建立。 呼叫extent::tile()的型別參數,<2,3>指定建立 2x3 磚。 因此,8x9 矩陣會並排成 12 個磚、四個數據列和三個數據行。方法
parallel_for_each是使用tiled_index<2,3>物件 (t_idx) 做為索引來呼叫。 索引的類型參數 (t_idx) 必須符合計算網域的類型參數 (descriptions.extent.tile< 2, 3>())。執行每個執行緒時,索引
t_idx會傳回執行緒位於哪個磚的資訊(tiled_index::tile屬性)和磚內線程的位置(tiled_index::local屬性)。
磚同步處理 - tile_static 和 tile_barrier::wait
上一個範例說明磚配置和索引,但本身並不十分有用。 當磚是演算法和惡意探索 tile_static 變數不可或缺的一部分時,磚會變得很有用。 因為磚中的所有線程都有變數的存取權 tile_static , tile_barrier::wait 因此呼叫 會用來同步處理變數的 tile_static 存取權。 雖然磚中的所有線程都有變數的存取權 tile_static ,但是磚中沒有線程執行的保證順序。 下列範例示範如何使用 tile_static 變數和 tile_barrier::wait 方法來計算每個磚的平均值。 以下是瞭解範例的索引鍵:
rawData 會儲存在 8x8 矩陣中。
磚大小為 2x2。 這會建立 4x4 的磚格線,而平均值可以使用 物件儲存在 4x4 矩陣
array中。 在 AMP 限制函式中,您只能藉由參考擷取的有限類型。 類別array是其中之一。矩陣大小和範例大小是使用
#define語句來定義,因為 、、extent和tiled_index的類型參數arrayarray_view必須是常數值。 您也可以使用const int static宣告。 作為額外的優點,變更樣本大小以計算超過 4x4 磚的平均大小是微不足道的。tile_static每個磚都會宣告 2x2 浮點數陣列。 雖然宣告位於每個執行緒的程式碼路徑中,但矩陣中的每個磚只會建立一個陣列。有一行程式碼會將每個磚
tile_static中的值複製到陣列。 針對每個執行緒,在值複製到陣列之後,執行緒上的執行會因為呼叫tile_barrier::wait而停止。當磚中的所有線程都達到屏障時,就可以計算平均值。 因為程式碼會針對每個執行緒執行,因此有一個
if語句只會計算一個執行緒上的平均值。 平均值會儲存在 averages 變數中。 屏障基本上是依磚控制計算的建構,就像您可能使用迴圈一for樣。變數中的資料
averages,因為它是array物件,必須複製到主機。 這個範例使用向量轉換運算子。在完整的範例中,您可以將 SAMPLESIZE 變更為 4,而且程式碼會正確執行,而不需要任何其他變更。
#include <iostream>
#include <amp.h>
using namespace concurrency;
#define SAMPLESIZE 2
#define MATRIXSIZE 8
void SamplingExample() {
// Create data and array_view for the matrix.
std::vector<float> rawData;
for (int i = 0; i < MATRIXSIZE * MATRIXSIZE; i++) {
rawData.push_back((float)i);
}
extent<2> dataExtent(MATRIXSIZE, MATRIXSIZE);
array_view<float, 2> matrix(dataExtent, rawData);
// Create the array for the averages.
// There is one element in the output for each tile in the data.
std::vector<float> outputData;
int outputSize = MATRIXSIZE / SAMPLESIZE;
for (int j = 0; j < outputSize * outputSize; j++) {
outputData.push_back((float)0);
}
extent<2> outputExtent(MATRIXSIZE / SAMPLESIZE, MATRIXSIZE / SAMPLESIZE);
array<float, 2> averages(outputExtent, outputData.begin(), outputData.end());
// Use tiles that are SAMPLESIZE x SAMPLESIZE.
// Find the average of the values in each tile.
// The only reference-type variable you can pass into the parallel_for_each call
// is a concurrency::array.
parallel_for_each(matrix.extent.tile<SAMPLESIZE, SAMPLESIZE>(),
[=, &averages] (tiled_index<SAMPLESIZE, SAMPLESIZE> t_idx) restrict(amp)
{
// Copy the values of the tile into a tile-sized array.
tile_static float tileValues[SAMPLESIZE][SAMPLESIZE];
tileValues[t_idx.local[0]][t_idx.local[1]] = matrix[t_idx];
// Wait for the tile-sized array to load before you calculate the average.
t_idx.barrier.wait();
// If you remove the if statement, then the calculation executes for every
// thread in the tile, and makes the same assignment to averages each time.
if (t_idx.local[0] == 0 && t_idx.local[1] == 0) {
for (int trow = 0; trow < SAMPLESIZE; trow++) {
for (int tcol = 0; tcol < SAMPLESIZE; tcol++) {
averages(t_idx.tile[0],t_idx.tile[1]) += tileValues[trow][tcol];
}
}
averages(t_idx.tile[0],t_idx.tile[1]) /= (float) (SAMPLESIZE * SAMPLESIZE);
}
});
// Print out the results.
// You cannot access the values in averages directly. You must copy them
// back to a CPU variable.
outputData = averages;
for (int row = 0; row < outputSize; row++) {
for (int col = 0; col < outputSize; col++) {
std::cout << outputData[row*outputSize + col] << " ";
}
std::cout << "\n";
}
// Output for SAMPLESIZE = 2 is:
// 4.5 6.5 8.5 10.5
// 20.5 22.5 24.5 26.5
// 36.5 38.5 40.5 42.5
// 52.5 54.5 56.5 58.5
// Output for SAMPLESIZE = 4 is:
// 13.5 17.5
// 45.5 49.5
}
int main() {
SamplingExample();
}
追蹤條件
建立名為 total 的變數,並為每個執行緒遞增該變數可能會很誘人 tile_static ,如下所示:
// Do not do this.
tile_static float total;
total += matrix[t_idx];
t_idx.barrier.wait();
averages(t_idx.tile[0],t_idx.tile[1]) /= (float) (SAMPLESIZE* SAMPLESIZE);
此方法的第一個問題是 tile_static 變數不能有初始化運算式。 第二個問題是指派 total 給 有競爭條件,因為磚中的所有線程都無法依特定順序存取變數。 您可以程式設計演算法,只允許一個執行緒存取每個屏障的總計,如下所示。 不過,此解決方案不可延伸。
// Do not do this.
tile_static float total;
if (t_idx.local[0] == 0&& t_idx.local[1] == 0) {
total = matrix[t_idx];
}
t_idx.barrier.wait();
if (t_idx.local[0] == 0&& t_idx.local[1] == 1) {
total += matrix[t_idx];
}
t_idx.barrier.wait();
// etc.
記憶體柵欄
必須同步處理的記憶體存取有兩種:全域記憶體存取和 tile_static 記憶體存取。 concurrency::array物件只會配置全域記憶體。 concurrency::array_view可以參考全域記憶體、 tile_static 記憶體或兩者,視其建構方式而定。 必須同步處理的記憶體有兩種:
全域記憶體
tile_static
記憶體柵欄 可確保記憶體存取可供執行緒磚中的其他執行緒使用,並根據程式循序執行記憶體存取。 為了確保這一點,編譯器和處理器不會在柵欄上重新排序讀取和寫入。 在 C++ AMP 中,記憶體柵欄是由下列其中一種方法的呼叫所建立:
tile_barrier::wait 方法 :建立全域和
tile_static記憶體周圍的柵欄。tile_barrier::wait_with_all_memory_fence 方法 :建立全域和
tile_static記憶體周圍的柵欄。tile_barrier::wait_with_global_memory_fence方法 :只建立全域記憶體周圍的柵欄。
tile_barrier::wait_with_tile_static_memory_fence 方法 :只建立記憶體
tile_static周圍的柵欄。
呼叫您需要的特定柵欄可以改善應用程式的效能。 屏障類型會影響編譯器和硬體重新排序語句的方式。 例如,如果您使用全域記憶體柵欄,它只會套用至全域記憶體存取,因此,編譯器和硬體可能會重新排序對柵欄兩側的變數進行讀取和寫入 tile_static 。
在下一個範例中,屏障會將寫入同步處理至 tileValues 的 tile_static 變數。 在此範例中, tile_barrier::wait_with_tile_static_memory_fence 會呼叫 , tile_barrier::wait 而不是 。
// Using a tile_static memory fence.
parallel_for_each(matrix.extent.tile<SAMPLESIZE, SAMPLESIZE>(),
[=, &averages] (tiled_index<SAMPLESIZE, SAMPLESIZE> t_idx) restrict(amp)
{
// Copy the values of the tile into a tile-sized array.
tile_static float tileValues[SAMPLESIZE][SAMPLESIZE];
tileValues[t_idx.local[0]][t_idx.local[1]] = matrix[t_idx];
// Wait for the tile-sized array to load before calculating the average.
t_idx.barrier.wait_with_tile_static_memory_fence();
// If you remove the if statement, then the calculation executes
// for every thread in the tile, and makes the same assignment to
// averages each time.
if (t_idx.local[0] == 0&& t_idx.local[1] == 0) {
for (int trow = 0; trow <SAMPLESIZE; trow++) {
for (int tcol = 0; tcol <SAMPLESIZE; tcol++) {
averages(t_idx.tile[0],t_idx.tile[1]) += tileValues[trow][tcol];
}
}
averages(t_idx.tile[0],t_idx.tile[1]) /= (float) (SAMPLESIZE* SAMPLESIZE);
}
});
另請參閱
C++ AMP (C++ Accelerated Massive Parallelism)
tile_static 關鍵字
意見反映
即將推出:我們會在 2024 年淘汰 GitHub 問題,並以全新的意見反應系統取代並作為內容意見反應的渠道。 如需更多資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交及檢視以下的意見反映: