逐步解說:偵錯 C++ AMP 應用程式
本文示範如何偵錯使用 C++ 加速大規模平行處理原則 (C++ AMP) 來利用圖形處理單元 (GPU) 的應用程式。 它會使用平行縮減程式來加總大量的整數陣列。 本逐步解說將說明下列工作:
- 啟動 GPU 偵錯工具。
- 在 [GPU 執行緒] 視窗中檢查 GPU 執行緒。
- 使用 [ 平行堆疊 ] 視窗,同時觀察多個 GPU 執行緒的呼叫堆疊。
- 使用 [ 平行監看 式] 視窗,同時檢查跨多個執行緒的單一運算式值。
- 標記、凍結、解除凍結和群組 GPU 執行緒。
- 將磚的所有線程執行到程式碼中的特定位置。
必要條件
開始本逐步解說之前:
注意
從 Visual Studio 2022 17.0 版開始,C++ AMP 標頭已被取代。
包含任何 AMP 標頭將會產生建置錯誤。 先定義 _SILENCE_AMP_DEPRECATION_WARNINGS ,再包含任何 AMP 標頭以讓警告無聲。
- 閱讀 C++ AMP 概觀 。
- 請確定文字編輯器中會顯示行號。 如需詳細資訊,請參閱 如何:在編輯器 中顯示行號。
- 請確定您至少執行 Windows 8 或 Windows Server 2012,以支援軟體模擬器上的偵錯。
注意
在下列指示的某些 Visual Studio 使用者介面項目中,您的電腦可能會顯示不同的名稱或位置: 您所擁有的 Visual Studio 版本以及使用的設定會決定這些項目。 如需詳細資訊,請參閱將 Visual Studio IDE 個人化。
建立範例專案
建立專案的指示會根據您使用的 Visual Studio 版本而有所不同。 請確定您已在此頁面上選取正確的檔版本。
在 Visual Studio 中建立範例專案
在功能表列上,選擇 [檔案]>[新增]>[專案],以開啟 [建立新專案] 對話方塊。
在對話方塊頂端,將 [語言] 設定為 C++,將 [平台] 設定為 Windows,並將 [專案類型] 設定為主控台。
從專案類型的篩選清單中,選擇 [主控台應用程式],然後選擇 [下一步]。 在下一頁中,于 [名稱 ] 方塊中 輸入
AMPMapReduce,以指定專案的名稱,並視需要不同的專案位置指定專案位置。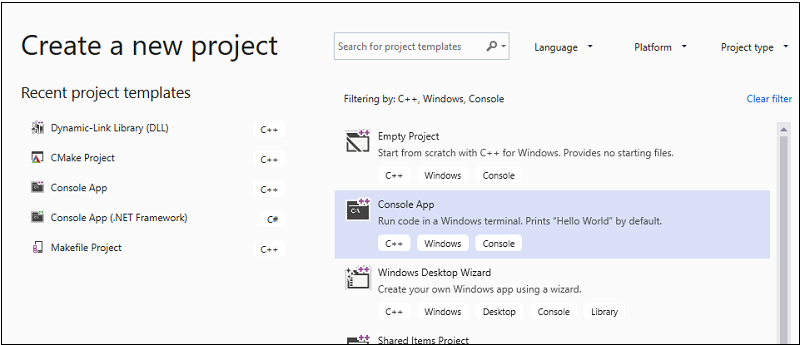
選擇 [建立] 按鈕以建立用戶端專案。
在 Visual Studio 2017 或 Visual Studio 2015 中建立範例專案
啟動 Visual Studio。
在功能表列上,選擇 [檔案]>[新增]>[專案]。
在 [範本] 窗格中的 [已安裝 ] 下,選擇 [Visual C++ ]。
選擇 [Win32 主控台應用程式 ],在 [ 名稱 ] 方塊中輸入
AMPMapReduce,然後選擇 [ 確定] 按鈕。選擇 [下一步] 按鈕。
清除 [ 先行編譯標頭 ] 核取方塊,然後選擇 [ 完成] 按鈕。
在 方案總管 中,從專案刪除 stdafx.h、 targetver.h 和 stdafx.cpp 。
下一步:
開啟 AMPMapReduce.cpp,並將其內容取代為下列程式碼。
// AMPMapReduce.cpp defines the entry point for the program. // The program performs a parallel-sum reduction that computes the sum of an array of integers. #include <stdio.h> #include <tchar.h> #include <amp.h> const int BLOCK_DIM = 32; using namespace concurrency; void sum_kernel_tiled(tiled_index<BLOCK_DIM> t_idx, array<int, 1> &A, int stride_size) restrict(amp) { tile_static int localA[BLOCK_DIM]; index<1> globalIdx = t_idx.global * stride_size; index<1> localIdx = t_idx.local; localA[localIdx[0]] = A[globalIdx]; t_idx.barrier.wait(); // Aggregate all elements in one tile into the first element. for (int i = BLOCK_DIM / 2; i > 0; i /= 2) { if (localIdx[0] < i) { localA[localIdx[0]] += localA[localIdx[0] + i]; } t_idx.barrier.wait(); } if (localIdx[0] == 0) { A[globalIdx] = localA[0]; } } int size_after_padding(int n) { // The extent might have to be slightly bigger than num_stride to // be evenly divisible by BLOCK_DIM. You can do this by padding with zeros. // The calculation to do this is BLOCK_DIM * ceil(n / BLOCK_DIM) return ((n - 1) / BLOCK_DIM + 1) * BLOCK_DIM; } int reduction_sum_gpu_kernel(array<int, 1> input) { int len = input.extent[0]; //Tree-based reduction control that uses the CPU. for (int stride_size = 1; stride_size < len; stride_size *= BLOCK_DIM) { // Number of useful values in the array, given the current // stride size. int num_strides = len / stride_size; extent<1> e(size_after_padding(num_strides)); // The sum kernel that uses the GPU. parallel_for_each(extent<1>(e).tile<BLOCK_DIM>(), [&input, stride_size] (tiled_index<BLOCK_DIM> idx) restrict(amp) { sum_kernel_tiled(idx, input, stride_size); }); } array_view<int, 1> output = input.section(extent<1>(1)); return output[0]; } int cpu_sum(const std::vector<int> &arr) { int sum = 0; for (size_t i = 0; i < arr.size(); i++) { sum += arr[i]; } return sum; } std::vector<int> rand_vector(unsigned int size) { srand(2011); std::vector<int> vec(size); for (size_t i = 0; i < size; i++) { vec[i] = rand(); } return vec; } array<int, 1> vector_to_array(const std::vector<int> &vec) { array<int, 1> arr(vec.size()); copy(vec.begin(), vec.end(), arr); return arr; } int _tmain(int argc, _TCHAR* argv[]) { std::vector<int> vec = rand_vector(10000); array<int, 1> arr = vector_to_array(vec); int expected = cpu_sum(vec); int actual = reduction_sum_gpu_kernel(arr); bool passed = (expected == actual); if (!passed) { printf("Actual (GPU): %d, Expected (CPU): %d", actual, expected); } printf("sum: %s\n", passed ? "Passed!" : "Failed!"); getchar(); return 0; }在功能表列上,依序選擇 [檔案]>[全部儲存]。
在 方案總管 中,開啟 AMPMapReduce 的 快捷方式功能表,然後選擇 [ 屬性 ]。
在 [ 屬性頁] 對話方塊的 [組態屬性 ] 下 ,選擇 [C/C++ > 先行編譯標頭]。
針對 [先行編譯標頭 ] 屬性,選取 [不使用先行編譯標頭 ],然後選擇 [ 確定 ] 按鈕。
在功能表列上選擇 [建置]>[建置解決方案]。
偵錯 CPU 程式碼
在此程式中,您將使用本機 Windows 偵錯工具來確保此應用程式中的 CPU 程式碼正確無誤。 此應用程式中 CPU 程式碼的區段特別有趣,就是 for 函式中的 reduction_sum_gpu_kernel 迴圈。 它會控制在 GPU 上執行的樹狀結構型平行縮減。
偵錯 CPU 程式碼
在 方案總管 中,開啟 AMPMapReduce 的 快捷方式功能表,然後選擇 [ 屬性 ]。
在 [ 屬性頁] 對話方塊的 [組態屬性 ] 底下 ,選擇 [ 偵錯 ]。 確認已在 [偵錯工具] 中 選取 [要啟動 的本機 Windows 偵錯工具 ] 清單。
返回程式 代碼編輯器 。
在下圖所示的程式程式碼上設定中斷點(大約第 67 行 70 行)。

CPU 中斷點在功能表列上,依序選擇 [偵錯]>[開始偵錯]。
在 [ 區域變數 ] 視窗中,觀察 的值
stride_size,直到到達第 70 行的中斷點為止。在功能表列上,依序選擇 [偵錯]>[停止偵錯]。
偵錯 GPU 程式碼
本節說明如何偵錯 GPU 程式碼,這是函式中包含的 sum_kernel_tiled 程式碼。 GPU 程式碼會平行計算每個「區塊」的整數總和。
偵錯 GPU 程式碼
在 方案總管 中,開啟 AMPMapReduce 的 快捷方式功能表,然後選擇 [ 屬性 ]。
在 [ 屬性頁] 對話方塊的 [組態屬性 ] 底下 ,選擇 [ 偵錯 ]。
在 [要啟動的偵錯工具] 清單中,選取 [本機 Windows 偵錯工具]。
在 [ 偵錯工具類型] 清單中,確認已 選取 [自動 ]。
Auto 是預設值。 在 Windows 10 之前的版本中, GPU 僅限 是必要值,而不是 Auto 。
選擇 [確定] 按鈕。
在第 30 行設定中斷點,如下圖所示。

GPU 中斷點在功能表列上,依序選擇 [偵錯]>[開始偵錯]。 CPU 程式碼在第 67 行和 70 行的中斷點不會在 GPU 偵錯期間執行,因為這些程式程式碼會在 CPU 上執行。
使用 [GPU 執行緒] 視窗
若要開啟 [GPU 執行緒] 視窗,請在功能表列上,選擇 [偵 > 錯 Windows > GPU 執行緒]。
您可以在出現的 [GPU 執行緒] 視窗中檢查 GPU 執行緒 的狀態。
將 [GPU 執行緒] 視窗停駐在 Visual Studio 底部。 選擇 [ 展開執行緒切換 ] 按鈕以顯示磚和執行緒文字方塊。 [ GPU 執行緒] 視窗會顯示作用中和封鎖的 GPU 執行緒總數,如下圖所示。

[GPU 執行緒] 視窗313 個磚會配置給此計算。 每個圖格都包含 32 個執行緒。 由於本機 GPU 偵錯發生在軟體模擬器上,因此有四個作用中的 GPU 執行緒。 這四個執行緒會同時執行指令,然後一起移至下一個指令。
在 [ GPU 執行緒] 視窗中,在大約第 21
t_idx.barrier.wait();行定義的 tile_barrier::wait 語句中,有四個 GPU 執行緒作用中 ,28 個 GPU 執行緒遭到封鎖。 所有 32 個 GPU 執行緒都屬於第一個磚tile[0]。 箭號指向包含目前線程的資料列。 若要切換至不同的執行緒,請使用下列其中一種方法:線上程切換至 [GPU 執行緒 ] 視窗中的資料列中,開啟快捷方式功能表,然後選擇 [ 切換至執行緒 ]。 如果資料列代表一個以上的執行緒,您將根據執行緒座標切換至第一個執行緒。
在對應的文字方塊中輸入執行緒的圖格和執行緒值,然後選擇 [ 切換執行緒] 按鈕。
[ 呼叫堆疊 ] 視窗會顯示目前 GPU 執行緒的呼叫堆疊。
使用 [平行堆疊] 視窗
若要開啟 [ 平行堆疊 ] 視窗,請在功能表列上,選擇 [偵 > 錯 Windows > 平行堆疊]。
您可以使用 [ 平行堆疊 ] 視窗,同時檢查多個 GPU 執行緒的堆疊框架。
將 [平行堆疊] 視窗停駐在 Visual Studio 底部。
請確定 已在左上角的清單中選取 [執行緒 ]。 在下圖中,[ 平行堆疊 ] 視窗會顯示您在 [GPU 執行緒] 視窗中看到 之 GPU 執行緒 的呼叫堆疊焦點檢視。

[平行堆疊] 視窗32 個執行緒會從 函式呼叫中的
parallel_for_eachLambda 語句,然後移至_kernel_stubsum_kernel_tiled函式,其中會發生平行縮減。 32 個執行緒中有 28 個已進展至 語句,tile_barrier::wait並在第 22 行保持封鎖,而其他四個執行緒則保留在函式中sum_kernel_tiled,第 30 行。您可以檢查 GPU 執行緒的屬性。 其可在 [平行堆疊 ] 視窗的 豐富資料提示的 [GPU 執行緒 ] 視窗中取得 。 若要查看它們,請將指標暫留在 的
sum_kernel_tiled堆疊框架上。 下圖顯示 DataTip。
GPU 執行緒資料提示如需平行堆疊視窗的詳細資訊 ,請參閱 使用平行堆疊視窗 。
使用 [平行監看式] 視窗
若要開啟 [ 平行監看 式] 視窗,請在功能表列上,選擇 [偵 > 錯 Windows > 平行監看式平行監看 > 式 1]。
您可以使用 [ 平行監看 式] 視窗來檢查跨多個執行緒的運算式值。
將 [平行監看式 1] 視窗停駐在 Visual Studio 底部。 [平行監看 式] 視窗資料表 中有 32 個數據列。 每個都對應至 GPU 執行緒視窗和 平行堆疊 視窗中顯示的 GPU 執行緒。 現在,您可以輸入想要在所有 32 個 GPU 執行緒中檢查其值的運算式。
選取 [ 新增監看 式] 資料行標頭,輸入 ,然後選擇 Enter
localIdx鍵。再次選取 [ 新增監看 式] 資料行標頭,輸入
globalIdx,然後選擇 Enter 鍵。再次選取 [ 新增監看 式] 資料行標頭,輸入
localA[localIdx[0]],然後選擇 Enter 鍵。您可以藉由選取其對應的資料行標頭,依指定的運算式排序。
選取 localA[localIdx[0]] 資料行標頭來排序資料行。 下圖顯示依 localA[localIdx[0]] 排序的結果。

排序結果您可以選擇 [Excel ] 按鈕,然後選擇 [在 Excel 中開啟],將 [平行監看 式] 視窗中的內容 匯出至 Excel 。 如果您已在開發電腦上安裝 Excel,按鈕會開啟包含內容的 Excel 工作表。
在 [平行監看 式] 視窗右上角 ,有一個篩選控制項,您可以使用布林運算式來篩選內容。 在篩選控制項文字方塊中輸入
localA[localIdx[0]] > 20000,然後選擇 Enter 鍵。視窗現在只包含值大於 20000 的
localA[localIdx[0]]執行緒。 內容仍會依localA[localIdx[0]]資料行排序,也就是您稍早選擇的排序動作。
標記 GPU 執行緒
您可以在 [GPU 執行緒] 視窗、[ 平行監看 式] 視窗或 [平行堆疊 ] 視窗中的 [資料提示 ] 視窗中標記特定 GPU 執行緒 。 如果 [GPU 執行緒] 視窗中的資料列包含一個以上的執行緒,則標示該資料列會標幟資料列中包含的所有線程。
為 GPU 執行緒加上旗標
在 [平行監看式 1 ] 視窗中選取 [執行緒] 資料行標頭 ,依磚索引和執行緒索引排序。
在功能表列上,選擇 > [偵錯繼續 ],這會導致作用中的四個執行緒進入下一個屏障(定義于 AMPMapReduce.cpp 的第 32 行)。
選擇資料列左側的旗標符號,其中包含目前作用中的四個執行緒。
下圖顯示 [GPU 執行緒] 視窗中的四個作用中 標幟執行緒 。

[GPU 執行緒] 視窗中正在活動的執行緒[ 平行監看 式] 視窗和 [平行堆疊 ] 視窗的 [資料提示] 都表示已標幟的執行緒。
如果您想要將焦點放在標示的四個執行緒上,您可以選擇只顯示已標示的執行緒。 它會限制您在 GPU 執行緒 、平行監看 式和 平行堆疊 視窗中看到 的內容。
選擇任何視窗或 [偵錯位置 ] 工具列上的 [ 僅顯示標幟] 按鈕。 下圖顯示 [偵錯位置 ] 工具列上的 [ 僅顯示標幟] 按鈕。

顯示 [僅標幟] 按鈕現在,GPU 執行緒 、 平行監看 和 平行堆疊 視窗只會顯示標幟的執行緒。
凍結和解除凍結 GPU 執行緒
您可以從 [GPU 執行緒] 視窗或 [平行監看 式] 視窗凍結 (暫停) 和 解除凍結 (繼續) GPU 執行緒 。 您可以凍結和解除凍結 CPU 執行緒的方式相同;如需詳細資訊,請參閱 如何:使用執行緒視窗 。
凍結和解除凍結 GPU 執行緒
選擇 [ 僅顯示標幟] 按鈕以顯示所有線程。
在功能表列上,選擇 [ 偵錯 > 繼續]。
開啟使用中資料列的快捷方式功能表,然後選擇 [ 凍結 ]。
[GPU 執行緒] 視窗的 下圖顯示所有四個執行緒都已凍結。

GPU 執行緒視窗中的 凍結執行緒同樣地,[ 平行監看 式] 視窗會顯示所有四個執行緒都已凍結。
在功能表列上,選擇 > [偵錯繼續 ] 以允許接下來的四個 GPU 執行緒經過第 22 行的屏障,並在第 30 行到達中斷點。 [ GPU 執行緒] 視窗會顯示四個先前凍結的執行緒會維持凍結狀態,且處於作用中狀態。
在功能表列上,選擇 [偵錯 ]、 [ 繼續 ]。
從 [ 平行監看 式] 視窗中,您也可以解除凍結個別或多個 GPU 執行緒。
將 GPU 執行緒分組
在 [GPU 執行緒] 視窗中其中一個執行緒 的快捷方式功能表上,選擇 [分組依據 ]、 [ 位址 ]。
[GPU 執行緒] 視窗中的 執行緒會依位址分組。 位址會對應至反組解碼中每個執行緒群組所在的指令。 24 個執行緒位於執行tile_barrier::wait 方法 的第 22 行。 12 個執行緒位於第 32 行屏障的指示中。 其中四個執行緒會標幟。 八個執行緒位於第 30 行的中斷點。 其中四個執行緒已凍結。 下圖顯示 [GPU 執行緒 ] 視窗中的群組執行緒 。

GPU 執行緒視窗中的群組執行緒您也可以開啟 [平行監看 式] 視窗資料格的快捷方式功能表 ,以執行 [分組依據 ] 作業。 選取 [ 群組依據 ],然後選擇對應至您要如何群組執行緒的功能表項目。
將所有線程執行至程式碼中的特定位置
您可以使用 [執行目前磚至 資料指標],將指定磚中的所有線程執行到包含游標 的行。
若要將所有線程執行至資料指標所標示的位置
在凍結執行緒的快捷方式功能表上,選擇 [解除凍結 ]。
在程式碼編輯器 中 ,將游標放在第 30 行。
在 [程式碼編輯器] 的 快捷方式功能表上,選擇 [ 執行目前磚至游標 ]。
先前在第 21 行的屏障上封鎖的 24 個執行緒已進入第 32 行。 它會顯示在 [GPU 執行緒] 視窗中。
另請參閱
C++ AMP 概觀
偵錯 GPU 程式碼
如何:使用 GPU 執行緒視窗
如何:使用平行監看式視窗
使用並行視覺化檢視分析 C++ AMP 程式碼
意見反映
即將推出:我們會在 2024 年淘汰 GitHub 問題,並以全新的意見反應系統取代並作為內容意見反應的渠道。 如需更多資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交及檢視以下的意見反映: