summarize 運算子
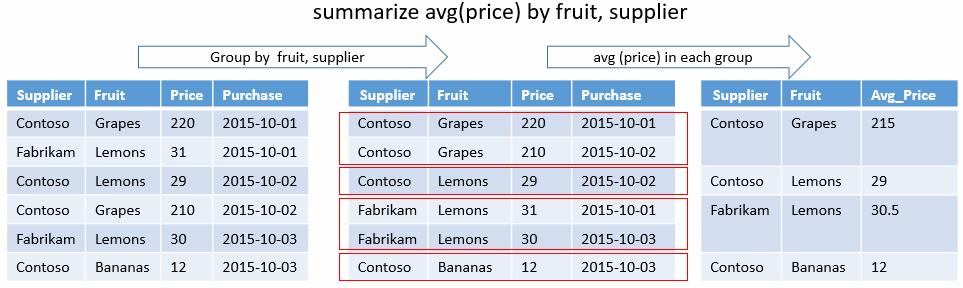
產生資料表來彙總輸入資料表的內容。
Syntax
T| summarize [ SummarizeParameters ] [[Column=] Aggregation [, ...]] [by [Column=] GroupExpression [, ...]]
深入瞭解 語法慣例。
參數
| 名稱 | 類型 | 必要 | Description |
|---|---|---|---|
| 資料行 | string |
結果數據行的名稱。 預設值為衍生自運算式的名稱。 | |
| 彙總 | string |
✔️ | 呼叫 聚合函數 ,例如 count() 或 avg(),其數據行名稱為自變數。 |
| GroupExpression | 純量 (scalar) | ✔️ | 可參考輸入數據的純量表達式。 輸出中的記錄會與所有群組運算式的相異值一樣多。 |
| SummarizeParameters | string |
名稱值形式的=零個或多個空格分隔參數,可控制行為。 請參閱 支持的參數。 |
注意
當輸入資料表是空的時,輸出取決於是否使用 GroupExpression:
- 如果未提供 GroupExpression,輸出將會是單一 (空白) 資料列。
- 如果提供 GroupExpression,輸出就不會有任何資料列。
支援的參數
| 名稱 | 描述 |
|---|---|
hint.num_partitions |
指定用來共用叢集節點上查詢負載的數據分割數目。 請參閱隨機查詢 |
hint.shufflekey=<key> |
此 shufflekey 查詢會使用索引鍵來分割資料,以共用叢集節點上的查詢負載。 請參閱隨機查詢 |
hint.strategy=shuffle |
shuffle 策略查詢會共用叢集節點上的查詢負載,其中每個節點都會處理資料的一個資料分割。 請參閱隨機查詢 |
傳回
輸入資料列會各自分組到具有相同 by 運算式值的群組。 然後指定的彙總函式會針對每個群組進行計算,以便為每個群組產生資料列。 結果會包含 by 資料行,而且每個經過計算的彙總至少會佔有一個資料行。 (某些彙總函式會傳回多個資料行)。
by 值 (可以是零) 有多少個不同組合,結果就會有多少個資料列。 如果未提供任何群組索引鍵,則結果會有一筆記錄。
若要要彙總數值範圍,請使用 bin() 來將範圍減少為離散值。
注意
- 雖然您可以為彙總與群組運算式提供任意運算式,但更有效率的方法是使用簡單的資料行名稱,或對數值資料行套用
bin()。 - 日期時間資料行的自動每小時間隔功能已不再受到支援。 請改用明確的間隔。 例如:
summarize by bin(timestamp, 1h)。
匯總的預設值
下表是彙總預設值的摘要:
| 運算子 | 預設值 |
|---|---|
count(), countif(), dcount(), dcountif(), count_distinct(), sum(), sumif(), variance(), varianceif(), stdev(), stdevif() |
0 |
make_bag(), make_bag_if(), make_list(), make_list_if(), make_set(), make_set_if() |
空的動態陣列 ([]) |
| All others | null |
注意
將這些匯總套用至包含 Null 值的實體時,會忽略 Null 值,且不會納入計算中。 如需範例,請參閱 匯總預設值。
範例
唯一組合
下列查詢會決定 造成直接傷害之暴風雨的唯一組合State。EventType 沒有彙總函式,只有 group-by 索引鍵。 輸出只會顯示這些結果的數據行。
StormEvents
| where InjuriesDirect > 0
| summarize by State, EventType
輸出
下表只顯示前 5 個資料列。 若要查看完整的輸出,請執行查詢。
| 州 | EventType |
|---|---|
| 德克薩斯州 | Thunderstorm Wind |
| 德克薩斯州 | Flash Flood |
| 德克薩斯州 | 冬季天氣 |
| 德克薩斯州 | 強風 |
| 德克薩斯州 | Flood |
| ... | ... |
時間戳下限和最大值
尋找美國群島的最小和最大暴雨雨。 沒有 group-by 子句,因此輸出中只有一個數據列。
StormEvents
| where State == "HAWAII" and EventType == "Heavy Rain"
| project Duration = EndTime - StartTime
| summarize Min = min(Duration), Max = max(Duration)
輸出
| 最小值 | 最大值 |
|---|---|
| 01:08:00 | 11:55:00 |
相異計數
為每個洲建立一個資料列,以顯示發生活動的城市計數。 由於「洲」的值不多,因此 'by' 子句中不需要有群組函式:
StormEvents
| summarize TypesOfStorms=dcount(EventType) by State
| sort by TypesOfStorms
輸出
下表只顯示前 5 個資料列。 若要查看完整的輸出,請執行查詢。
| 狀態 | TypesOfStorms |
|---|---|
| 德克薩斯州 | 27 |
| 加利福尼亞州 | 26 |
| 賓夕法尼亞 | 25 |
| 喬治亞州 | 24 |
| 伊利諾州 | 23 |
| ... | ... |
長條圖
下列範例會計算直方圖 storm 事件類型,此類型具有超過 1 天的暴風雨。 因為 Duration 有許多值,所以使用 bin() 將其值分組為 1 天間隔。
StormEvents
| project EventType, Duration = EndTime - StartTime
| where Duration > 1d
| summarize EventCount=count() by EventType, Length=bin(Duration, 1d)
| sort by Length
輸出
| EventType | 長度 | EventCount |
|---|---|---|
| 乾旱 | 30.00:00:00 | 1646 |
| 野火 | 30.00:00:00 | 11 |
| Heat | 30.00:00:00 | 14 |
| Flood | 30.00:00:00 | 20 |
| 暴雨 | 29.00:00:00 | 42 |
| ... | ... | ... |
彙總預設值
當運算子的 summarize 輸入至少有一個空的分組索引鍵時,其結果也會是空的。
當運算子的 summarize 輸入沒有空的分組索引鍵時,結果就是 [ summarize 如需詳細資訊] 中使用的匯總預設值,請參閱 匯總的預設值。
datatable(x:long)[]
| summarize any_x=take_any(x), arg_max_x=arg_max(x, *), arg_min_x=arg_min(x, *), avg(x), buildschema(todynamic(tostring(x))), max(x), min(x), percentile(x, 55), hll(x) ,stdev(x), sum(x), sumif(x, x > 0), tdigest(x), variance(x)
輸出
| any_x | arg_max_x | arg_min_x | avg_x | schema_x | max_x | min_x | percentile_x_55 | hll_x | stdev_x | sum_x | sumif_x | tdigest_x | variance_x |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| NaN | 0 | 0 | 0 | 0 |
的結果 avg_x(x) 是 NaN 除以 0。
datatable(x:long)[]
| summarize count(x), countif(x > 0) , dcount(x), dcountif(x, x > 0)
輸出
| count_x | countif_ | dcount_x | dcountif_x |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
datatable(x:long)[]
| summarize make_set(x), make_list(x)
輸出
| set_x | list_x |
|---|---|
| [] | [] |
匯總平均會加總所有非 Null,而且只會計算參與計算 (的計算不會將 null 納入考慮) 。
range x from 1 to 4 step 1
| extend y = iff(x == 1, real(null), real(5))
| summarize sum(y), avg(y)
輸出
| sum_y | avg_y |
|---|---|
| 15 | 5 |
一般計數會計算 Null:
range x from 1 to 2 step 1
| extend y = iff(x == 1, real(null), real(5))
| summarize count(y)
輸出
| count_y |
|---|
| 2 |
range x from 1 to 2 step 1
| extend y = iff(x == 1, real(null), real(5))
| summarize make_set(y), make_set(y)
輸出
| set_y | set_y1 |
|---|---|
| [5.0] | [5.0] |
意見反應
即將登場:在 2024 年,我們將逐步淘汰 GitHub 問題作為內容的意見反應機制,並將它取代為新的意見反應系統。 如需詳細資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交並檢視相關的意見反應