在 HDInsight Spark 叢集上開啟 Jupyter Notebook
建立 HDInsight Spark 叢集之後,您便可以針對 Azure HDInsight 中的 Apache Spark 叢集執行互動式 Spark SQL 查詢或作業。 若要這麼做,您必須先建立筆記本。 筆記本是互動式的編輯器,可讓資料工程師和資料科學家使用各種語言與資料互動。 這包括 Python、SQL、Scala 及其他語言。 HDInsight 支援使用 Jupyter、Zeppelin 及 Livy 來與資料互動。 互動層級會取決於您正在管理的工作負載。
HDInsight 上的 Apache Spark 支援下列工作負載:
互動式資料分析和 BI
您可以使用筆記本來擷取非結構化/半結構化的資料,然後在筆記本內定義結構描述。 您接著可以使用該結構描述來在 Power BI 5 之類的工具中建立模型,這將能讓商務使用者針對該筆記本中的資料執行資料分析
Spark 機器學習服務
您可以使用筆記本來搭配 MLlib (以 Spark 為基礎所建置的機器學習程式庫) 以建立機器學習應用程式
Spark 串流和即時資料分析
HDInsight 上的 Spark 叢集提供豐富的支援,以供您建置即時分析解決方案。 雖然 Spark 已附有從 Kafka、Flume、Twitter、ZeroMQ 或 TCP 通訊端等眾多來源擷取資料的連接器,不過 HDInsight 中的 Spark 仍加入首屈一指的支援,供您從 Azure 事件中樞擷取資料。
建立 Jupyter 筆記本
使用下列步驟在 Azure 入口網站中建立 Jupyter 筆記本。
從入口網站的 [叢集儀表板] 區段,選取 [Jupyter Notebook]。 出現提示時,輸入叢集的叢集登入認證。
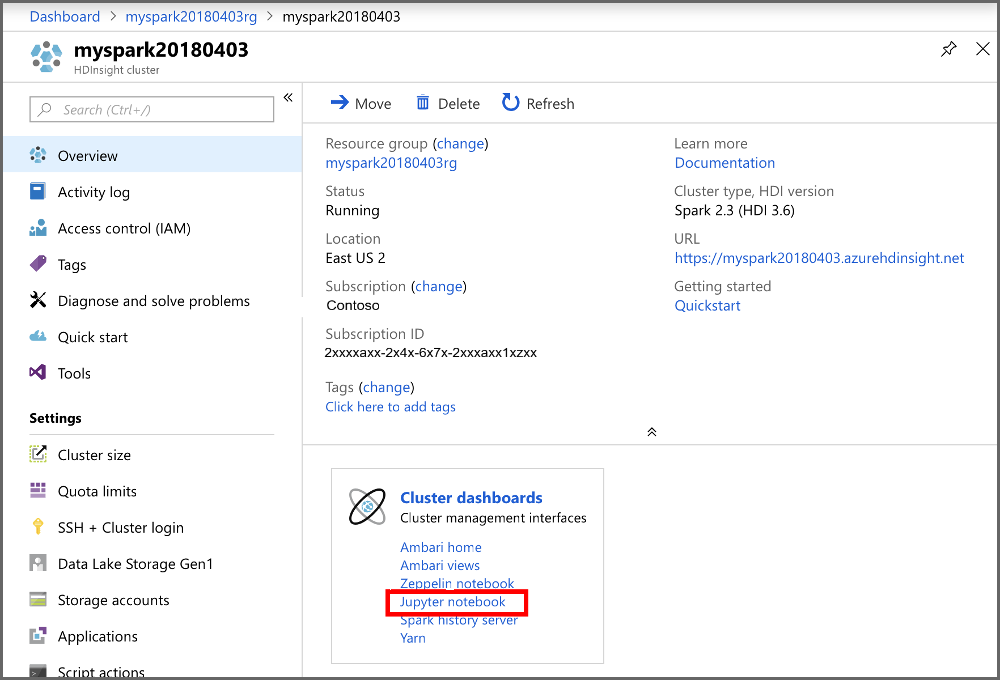
選取 [新增] > [PySpark] 以建立筆記本。
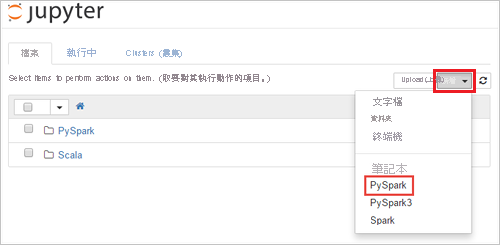
系統會建立並開啟新的筆記本,該筆記本會具有 [Untitled] (Untitled.pynb) 的名稱,且可讓您開始建立作業並執行查詢