你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
请求冗余反模式
反模式是一种常见的设计缺陷,可能会在压力过大的情况下使软件或应用程序中断,因此不应该被忽视。 在“超量提取反模式”下,检索超出业务运营需要的数据通常会导致不必要的 I/O 开销,并降低响应能力。
超量提取反模式的示例
如果应用程序尝试通过检索所有数据(超过它可能需要的数据量)来尽量减少 I/O 请求数量,则可能会发生这种反模式。 这通常是过度补偿琐碎 I/O 反模式的结果。 例如,应用程序可能会提取数据库中每个产品的详细信息。 但用户可能只需要一部分详细信息(有些信息与客户无关),因此不需要一次性查看所有产品。 即使用户浏览的是整个目录,也应将结果分页,例如,每次显示 20 条结果。
出现此问题的另一个原因是遵循了不合理的编程或设计做法。 例如,以下代码使用实体框架来提取每个产品的完整详细信息。 然后,它会筛选结果以返回一部分字段,并丢弃剩余的字段。 可在此处找到完整示例。
public async Task<IHttpActionResult> GetAllFieldsAsync()
{
using (var context = new AdventureWorksContext())
{
// Execute the query. This happens at the database.
var products = await context.Products.ToListAsync();
// Project fields from the query results. This happens in application memory.
var result = products.Select(p => new ProductInfo { Id = p.ProductId, Name = p.Name });
return Ok(result);
}
}
在以下示例中,应用程序会检索数据来执行聚合(也可以由数据库执行该聚合)。 该应用程序通过获取所有销售订单的每条记录来计算总销售额,然后对这些记录求和。 可在此处找到完整示例。
public async Task<IHttpActionResult> AggregateOnClientAsync()
{
using (var context = new AdventureWorksContext())
{
// Fetch all order totals from the database.
var orderAmounts = await context.SalesOrderHeaders.Select(soh => soh.TotalDue).ToListAsync();
// Sum the order totals in memory.
var total = orderAmounts.Sum();
return Ok(total);
}
}
以下示例演示实体框架对 LINQ to Entities 的使用方式所造成的微妙问题。
var query = from p in context.Products.AsEnumerable()
where p.SellStartDate < DateTime.Now.AddDays(-7) // AddDays cannot be mapped by LINQ to Entities
select ...;
List<Product> products = query.ToList();
该应用程序尝试查找 SellStartDate 超过一周的产品。 在大多数情况下,LINQ to Entities 会将 where 子句转换为可由数据库执行的 SQL 语句。 但是,在这种情况下,LINQ to Entities 无法将 AddDays 方法映射到 SQL。 而是返回 Product 表中的每行,并在内存中筛选结果。
调用 AsEnumerable 暗示着存在一个问题。 此方法将结果转换为 IEnumerable 接口。 尽管 IEnumerable 支持筛选,但筛选是在客户端而不是数据库上执行的。 默认情况下,LINQ to Entities 使用 IQueryable,该接口将筛选责任传递给数据源。
如何修复超量提取反模式
避免提取可能很快就会过时或被丢弃的大量数据,只提取所执行操作需要的数据。
不要从表中获取每个列并对其进行筛选,而是从数据库中选择所需的列。
public async Task<IHttpActionResult> GetRequiredFieldsAsync()
{
using (var context = new AdventureWorksContext())
{
// Project fields as part of the query itself
var result = await context.Products
.Select(p => new ProductInfo {Id = p.ProductId, Name = p.Name})
.ToListAsync();
return Ok(result);
}
}
同样,请在数据库而不是应用程序内存中执行聚合。
public async Task<IHttpActionResult> AggregateOnDatabaseAsync()
{
using (var context = new AdventureWorksContext())
{
// Sum the order totals as part of the database query.
var total = await context.SalesOrderHeaders.SumAsync(soh => soh.TotalDue);
return Ok(total);
}
}
使用实体框架时,请确保使用 IQueryable 接口(而不是 IEnumerable)来解析 LINQ 查询。 可能需要调整查询,以便只使用可映射到数据源的函数。 可以重构前面的示例,以便从查询中删除 AddDays 方法,使筛选由数据库执行。
DateTime dateSince = DateTime.Now.AddDays(-7); // AddDays has been factored out.
var query = from p in context.Products
where p.SellStartDate < dateSince // This criterion can be passed to the database by LINQ to Entities
select ...;
List<Product> products = query.ToList();
注意事项
在某些情况下,可以通过将数据水平分区来提高性能。 如果不同的操作访问不同的数据属性,水平分区可以减少资源争用。 大部分操作往往是针对少部分数据运行的,因此,分散负载可提高性能。 请参阅数据分区。
对于必须支持无界限查询的操作,请实现分页,每次只提取有限数量的实体。 例如,如果客户正在浏览产品目录,则每次可向其显示一页结果。
如果可能,请利用数据存储内置的功能。 例如,SQL 数据库通常提供聚合函数。
如果使用的数据存储不支持某个特定函数(例如聚合),则可将计算结果存储在其他位置,并在添加或更新记录后更新该值。这样,在需要该值时,应用程序就不需要重新计算。
如果发现请求正在检索大量字段,请检查源代码,确定是否需要所有这些字段。 有时,这些请求是设计不佳的
SELECT *查询造成的。同样,检索大量实体的请求可能意味着应用程序未正确筛选数据。 请确认是否需要所有这些实体。 尽量使用数据库端筛选,例如,在 SQL 中使用
WHERE子句。将处理工作量分配到数据库并不总是最佳选择。 仅当数据库在设计上或优化为执行这些处理时,才使用此策略。 大部分数据库系统已针对某些函数进行高度优化,但并不旨在充当通用的应用程序引擎。 有关详细信息,请参阅繁忙数据库反模式。
如何检测超量提取反模式
请求冗余的症状包括高延迟和低吞吐量。 如果数据是从数据存储中检索的,则还可能会加剧资源争用。 最终用户可能会反映响应时间延长,或服务超时导致失败。这些失败可能返回 HTTP 500(内部服务器)错误或 HTTP 503(服务不可用)错误。 检查 Web 服务器的事件日志,其中可能包含有关错误原因和情况的更详细信息。
此反模式的症状和获取的某些遥测数据可能与整体持久性反模式非常类似。
可执行以下步骤来帮助确定原因:
- 执行负载测试、进程监视或其他检测数据捕获方法,识别速度缓慢的工作负荷或事务。
- 观察系统表现的所有行为模式。 在每秒事务数或用户量方面是否存在特定的限制?
- 将慢速工作负荷的实例与行为模式相关联。
- 识别正在使用的数据存储。 对于每个数据源,运行较低级别的遥测来观察操作行为。
- 识别引用这些数据源的所有缓慢运行的查询。
- 针对缓慢运行的查询执行特定于资源的分析,并确定数据的使用和消耗方式。
确定是否存在以下任何症状:
- 频繁地向同一资源或数据存储发出大型 I/O 请求。
- 共享资源或数据存储中发生资源争用。
- 某个操作频繁通过网络接收大量数据。
- 应用程序和服务花费大量时间等待 I/O 完成。
示例诊断
以下部分对前面的示例应用这些步骤。
识别速度缓慢的工作负荷
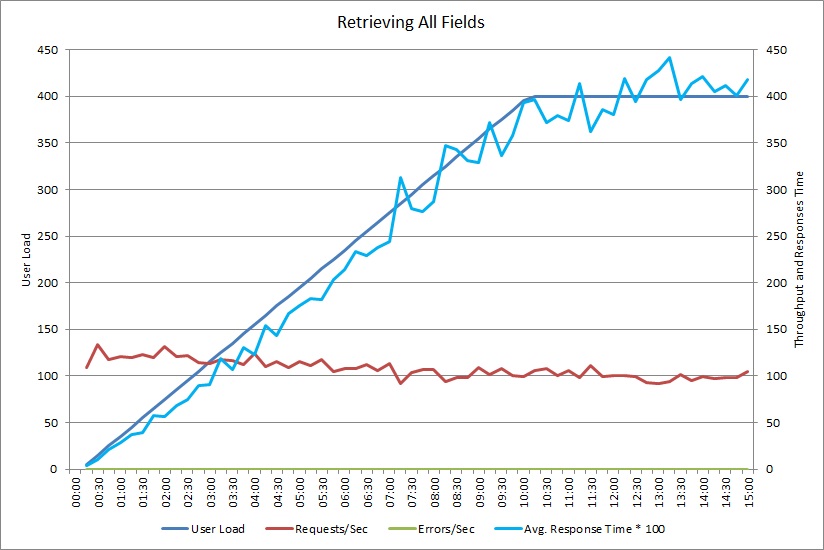
此图显示了某项负载测试的性能结果。该测试模拟多达 400 个运行前面所示 GetAllFieldsAsync 方法的并发用户。 随着负载的增大,吞吐量缓慢下降。 随着工作负荷的增大,平均响应时间不断提高。
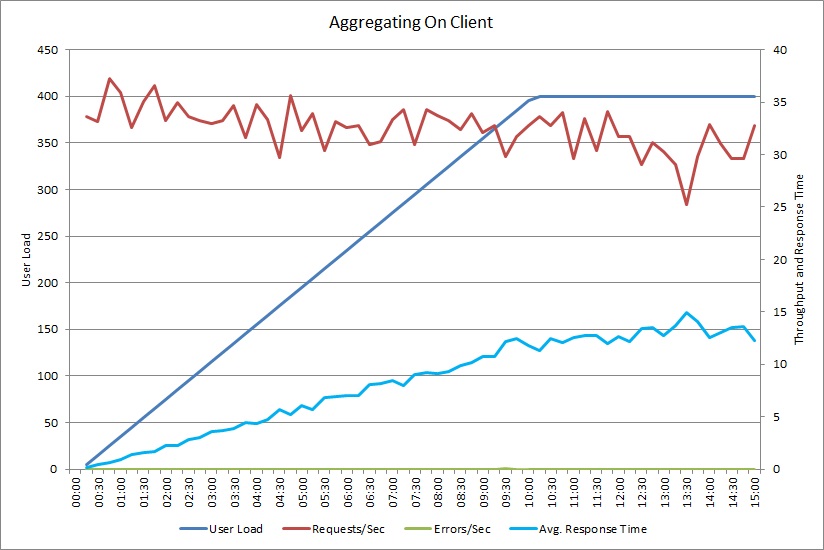
针对 AggregateOnClientAsync 操作执行的负载测试显示了类似的模式。 请求量适度稳定。 平均响应时间随着工作负荷的增大而提高,不过,提高的速度比前一图表中要慢。
将慢速工作负荷与行为模式相关联
定期的高使用率与缓慢性能之间的任何关联可以指明关注区域。 仔细检查怀疑运行速度缓慢的功能的性能配置文件,确定它是否与前面执行的负载测试匹配。
使用基于步骤的用户负载对同一功能进行负载测试,找出性能明显下降或完全失败的位置。 如果该位置在预期的实际使用边界内,请检查该功能的实现方式
如果速度缓慢的操作不是在系统承受压力的情况下执行的、不是时间关键的,且不会对其他重要操作的性能造成负面影响,则该操作就不一定是个问题。 例如,生成每月操作统计信息可能是一个长时间运行的操作,但它可能是以批处理的形式执行的,并以低优先级作业的形式运行。 另一方面,客户查询产品目录是一个关键的业务操作。 专注于这些关键操作生成的遥测数据可以了解重度使用期间的性能变化。
识别慢速工作负荷中的数据源
如果怀疑某个服务由于检索数据的方式原因而性能不佳,请调查应用程序与其使用的存储库之间的交互方式。 监视实时系统,确定在性能不佳期间访问了哪些源。
对于每个数据源,检测系统以捕获以下信息:
- 访问每个数据存储的频率。
- 进入和退出数据存储的数据量。
- 这些操作的计时,尤其是请求延迟。
- 在承受典型负载的情况下访问每个数据存储时发生的所有错误的性质和比率。
将此信息与应用程序返回给客户端的数据量进行比较。 根据返回给客户端的数据量跟踪数据存储返回的数据量比率。 如果有较大的差异,请调查确定应用程序是否在提取不需要的数据。
可以通过观察实时系统并跟踪每个用户请求的生命周期来捕获此数据,或者,可为一系列合成工作负荷建模,并针对测试系统运行这些工作负荷。
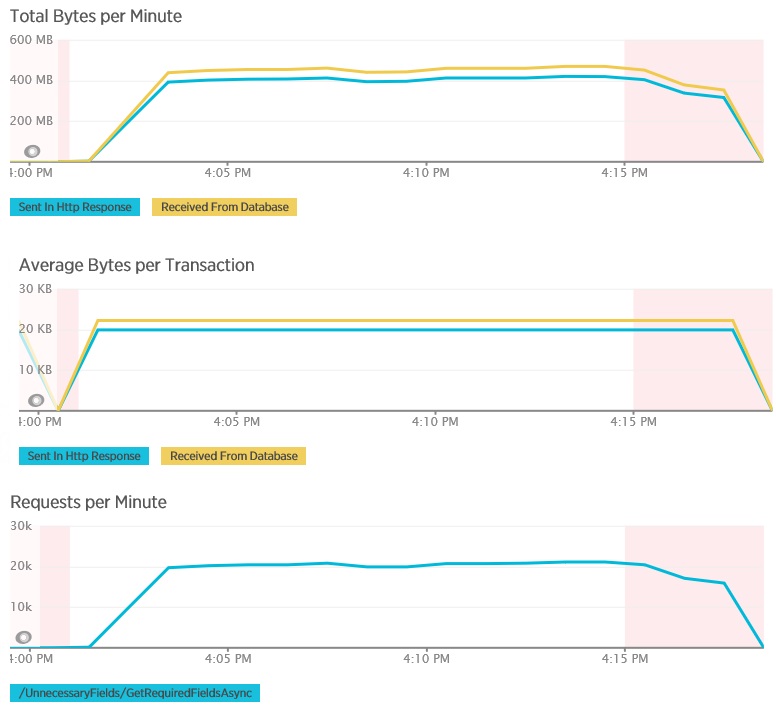
下图显示对 GetAllFieldsAsync 方法执行负载测试期间,使用 New Relic APM 捕获的遥测数据。 请注意从数据库收到的数据量与相应 HTTP 响应之间的差异。
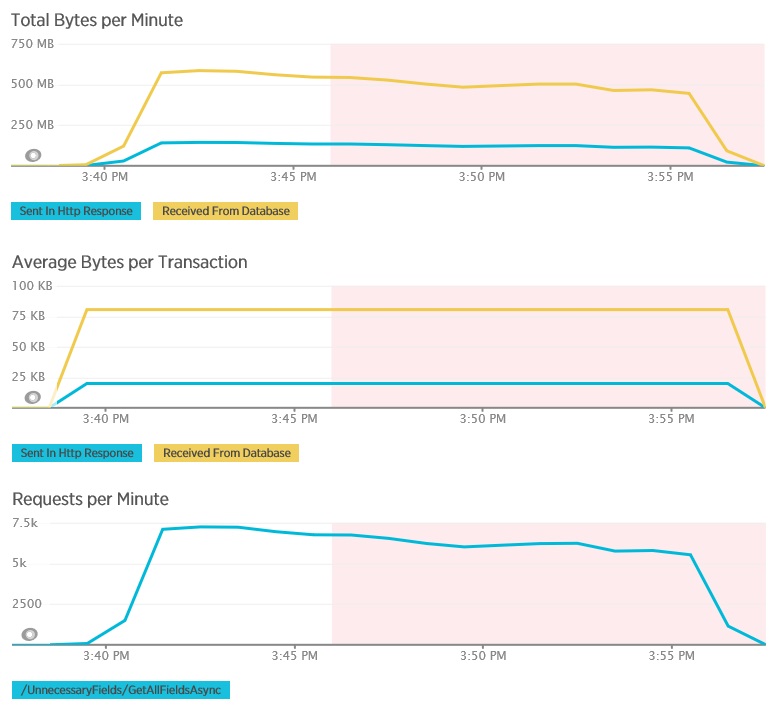
对于每个请求,数据库返回了 80,503 字节,但返回给客户端的响应仅包含 19,855 字节,大约为数据库响应大小的 25%。 返回给客户端的数据大小可能会根据格式的不同而异。 在此负载测试中,客户端请求了 JSON 数据。 使用 XML 执行的单独测试(未显示)返回的响应大小为 35,655 字节,即数据库响应大小的 44%。
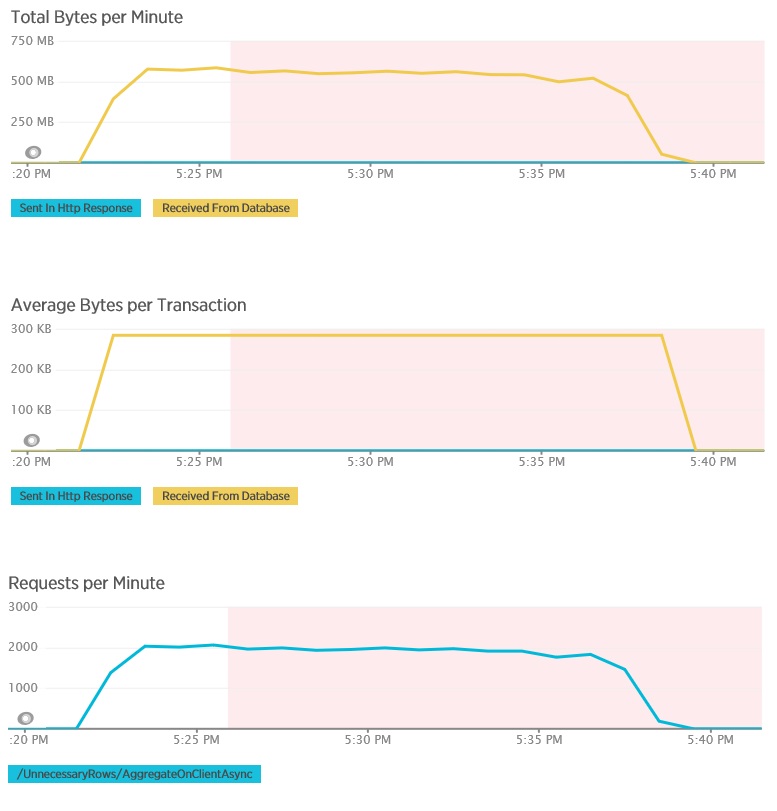
针对 AggregateOnClientAsync 方法的负载测试显示了更极端的结果。 在本例中,每项测试执行了一个从数据库中检索超过 280 Kb 数据的查询,但 JSON 响应只有 14 个字节。 之所以出现这么大的差异,是因为该方法基于大量数据计算了聚合结果。
识别和分析慢速查询
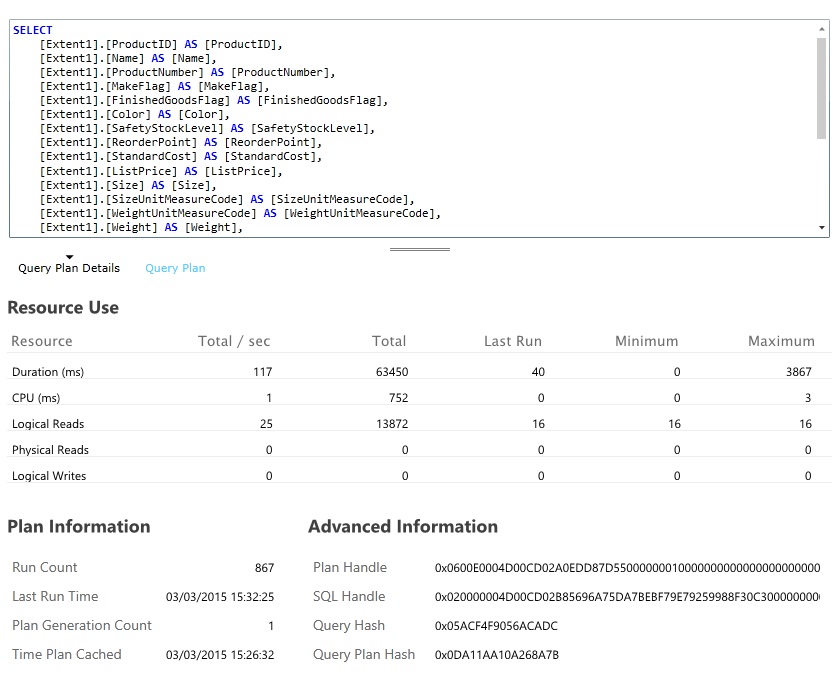
找出消耗最多资源且执行时间最长的数据库查询。 可以添加检测来找到许多数据库操作的开始时间和完成时间。 许多数据存储还提供有关查询执行和优化方式的深入信息。 例如,可以通过 Azure SQL 数据库管理门户中的“查询性能”窗格选择某个查询,并查看详细的运行时性能信息。 下面是 GetAllFieldsAsync 操作生成的查询:
实施解决方案并验证结果
在数据库端将 GetRequiredFieldsAsync 方法更改为使用 SELECT 语句后,负载测试显示了以下结果。
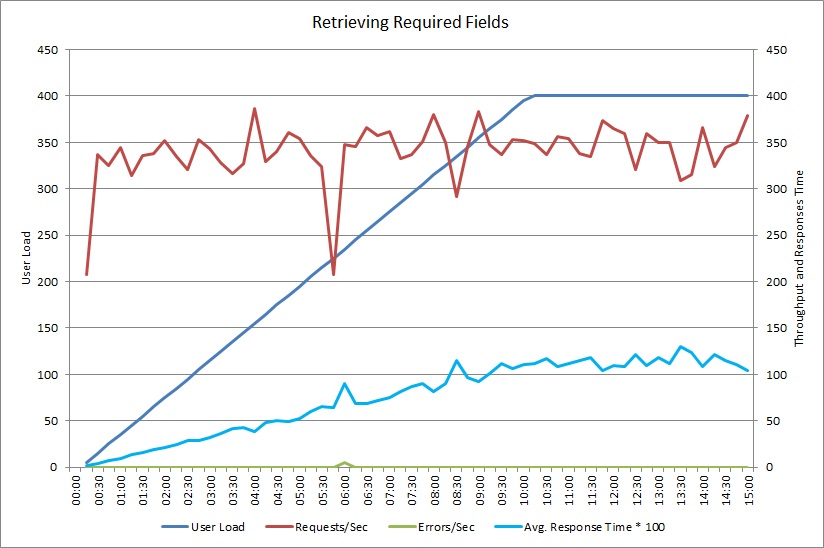
此负载测试使用了与前面相同的部署以及包含 400 个并发用户的模拟工作负荷。 图中显示的延迟要低得多。 随着负载的增大,响应时间提升到大约 1.3 秒,而在前一案例中,响应时间为 4 秒。 吞吐量也已提高,为每秒 350 个请求,而在前一案例中为 100。 从数据库中检索的数据量现在与 HTTP 响应消息的大小非常接近。
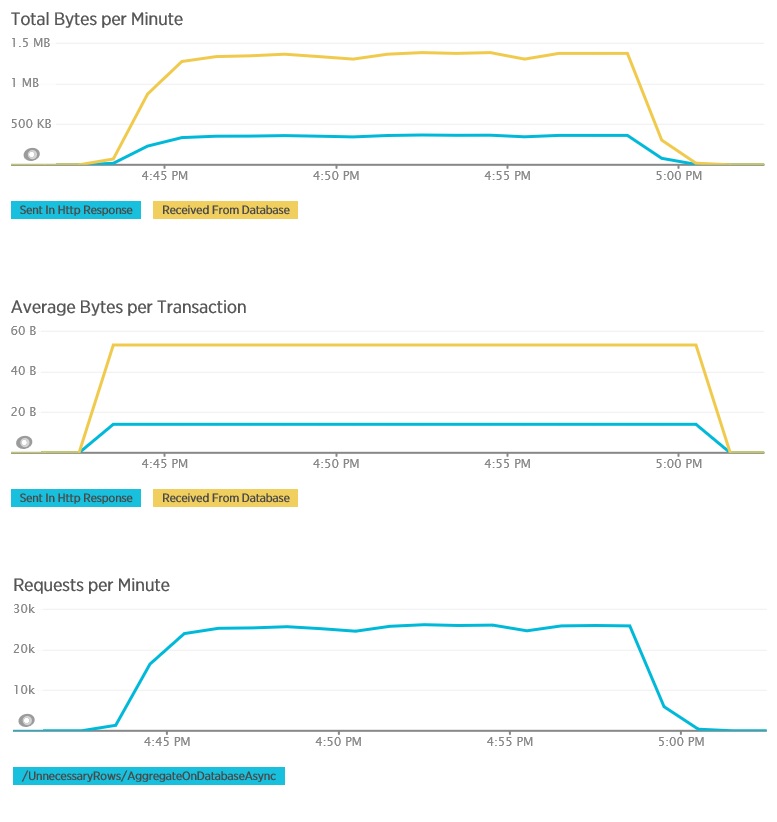
使用 AggregateOnDatabaseAsync 方法执行的负载测试生成了以下结果:
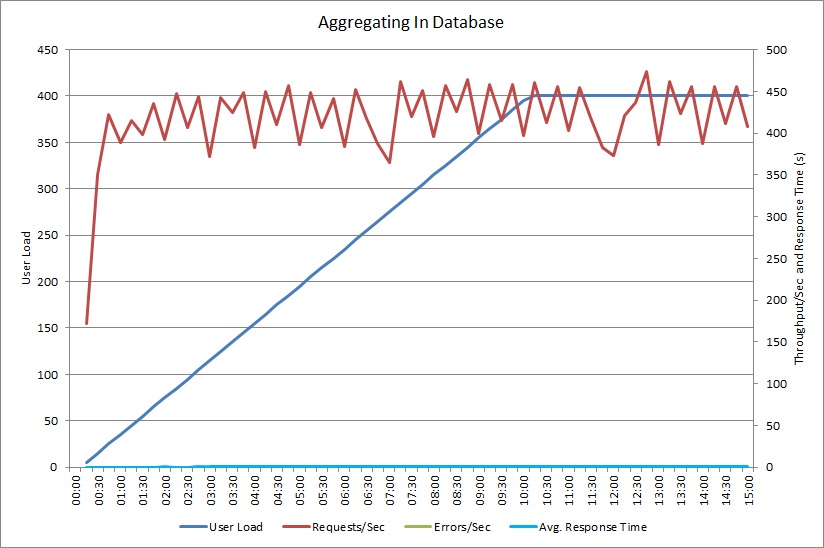
现在,平均响应时间极短。 这是数量级的性能改善,主要原因是来自数据库的 I/O 大幅减少。
下面是 AggregateOnDatabaseAsync 方法的相应遥测数据。 从数据库中检索的数据量大大减少,从每个事务 280 Kb 以上缩减到 53 个字节。 因此,每分钟的最大持续请求数已从大约 2,000 提升到 25,000 以上。
相关资源
反馈
即将发布:在整个 2024 年,我们将逐步淘汰作为内容反馈机制的“GitHub 问题”,并将其取代为新的反馈系统。 有关详细信息,请参阅:https://aka.ms/ContentUserFeedback。
提交和查看相关反馈