你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
无缓存反模式
反模式是一种常见的设计缺陷,可能会在压力过大的情况下使软件或应用程序中断,因此不应该被忽视。 在处理许多并发请求的云应用程序中反复提取相同的数据会导致出现无缓存反模式。 这会降低性能和可伸缩性。
在不缓存数据的情况下,可能会导致一些意外的行为,包括:
- 反复从访问开销较高(体现在 I/O 开销或延迟方面)的资源提取相同的信息。
- 为多个请求反复构造相同的对象或数据结构。
- 向具有服务配额并对超过特定限制的客户端施加约束的远程服务发出过多的调用。
这些问题可能进一步导致响应时间不佳、数据存储中资源争用加剧,以及可伸缩性不佳。
无缓存反模式的示例
以下示例使用实体框架连接到数据库。 即使多个请求提取完全相同的数据,每个客户端请求也会导致调用数据库。 重复请求的成本(体现在 I/O 开销和数据访问费用方面)可能会迅速累积。
public class PersonRepository : IPersonRepository
{
public async Task<Person> GetAsync(int id)
{
using (var context = new AdventureWorksContext())
{
return await context.People
.Where(p => p.Id == id)
.FirstOrDefaultAsync()
.ConfigureAwait(false);
}
}
}
可在此处找到完整示例。
出现此反模式的原因通常是:
- 不使用缓存的解决方案更容易实施,在低负载下可正常运转。 缓存使代码变得更复杂。
- 不能清楚地了解使用缓存的优点和缺点。
- 关心保持缓存数据的准确性和全新性所涉及的开销。
- 应用程序是从本地系统迁移的,其中的网络延迟不是问题,并且系统在昂贵的高性能硬件上运行,因此,原始设计中未考虑缓存。
- 开发人员未意识到缓存在给定方案中是一个可行的选项。 例如,开发人员在实现 Web API 时可能不会考虑使用 Etag。
如何修复无缓存反模式
最流行的缓存策略是按需策略或缓存端策略。
- 读取时,应用程序尝试从缓存中读取数据。 如果数据不在缓存中,应用程序会从数据源中检索数据,并将其添加到缓存。
- 写入时,应用程序将更改直接写入数据源,并从缓存中删除旧值。 下一次有需要时,会在缓存中检索和添加数据。
此方法适合经常更改的数据。 下面将前一示例更新为使用缓存端模式。
public class CachedPersonRepository : IPersonRepository
{
private readonly PersonRepository _innerRepository;
public CachedPersonRepository(PersonRepository innerRepository)
{
_innerRepository = innerRepository;
}
public async Task<Person> GetAsync(int id)
{
return await CacheService.GetAsync<Person>("p:" + id, () => _innerRepository.GetAsync(id)).ConfigureAwait(false);
}
}
public class CacheService
{
private static ConnectionMultiplexer _connection;
public static async Task<T> GetAsync<T>(string key, Func<Task<T>> loadCache, double expirationTimeInMinutes)
{
IDatabase cache = Connection.GetDatabase();
T value = await GetAsync<T>(cache, key).ConfigureAwait(false);
if (value == null)
{
// Value was not found in the cache. Call the lambda to get the value from the database.
value = await loadCache().ConfigureAwait(false);
if (value != null)
{
// Add the value to the cache.
await SetAsync(cache, key, value, expirationTimeInMinutes).ConfigureAwait(false);
}
}
return value;
}
}
请注意,GetAsync 方法现在调用 CacheService 类,而不是直接调用数据库。 CacheService 类首先尝试从 Azure Redis 缓存中获取项。 如果在该缓存中未找到值,CacheService 会调用由调用方传递给它的 lambda 函数。 该 lambda 函数负责从数据库提取数据。 此实现将存储库与特定的缓存解决方案分离开来,并将 CacheService 与数据库分离开来。
缓存策略注意事项
如果缓存不可用(可能是暂时性故障造成的),请不要向客户端返回错误。 而应该从原始数据源提取数据。 但请注意,在恢复缓存时,原始数据存储可能忙于处理请求,导致超时和连接失败。 (毕竟这是首先使用缓存的动机之一。)使用断路器模式等技术可避免数据源瘫痪。
缓存动态数据的应用程序应设计为支持最终一致性。
对于 Web API,可以通过在请求和响应消息中包含 Cache-Control 标头并使用 Etag 标识对象版本,来支持客户端缓存。 有关详细信息,请参阅 API 实现。
不需要缓存整个实体。 如果某个实体的大部分内容是静态的,但只有一小部分经常更改,请缓存静态元素,并从数据源检索动态元素。 此方法有助于减少针对数据源执行的 I/O 数量。
在某些情况下,如果易失性数据的生存期较短,将它缓存可能会有帮助。 例如,假设某个设备持续发送状态更新。 有利的做法可能是在此信息抵达时将其缓存,而完全不将它写入持久性存储。
为了防止数据过时,许多缓存解决方案支持可配置的失效期,以便在达到指定的间隔后,从缓存中自动删除数据。 可能需要根据方案优化过期时间。 高度静态的数据在缓存中的保留时间可以长于可能很快过时的易失性数据。
如果缓存解决方案未提供内置过期,你可能需要实现一个后台进程,以不时地扫描缓存,防止它不受限制地扩大。
除了缓存来自外部数据源的数据以外,还可以使用缓存来保存复杂计算的结果。 但是,在执行此操作之前,请检测应用程序,确定应用程序是否真正受 CPU 的约束。
在应用程序启动时准备好缓存可能很有帮助。 在缓存中填充最有可能会用到的数据。
始终包含检测机制来检测缓存命中数和缓存未命中数。 使用此信息来优化缓存策略,例如,要缓存哪些数据,以及在数据过期之前要在缓存中保存数据多长时间。
如果缺少缓存造成了瓶颈,则添加缓存可能会大幅增加请求数量,导致 Web 前端过载。 客户端可能开始收到 HTTP 503(服务不可用)错误。 这些问题表明需要横向扩展前端。
如何检测无缓存反模式
可以执行以下步骤来帮助识别缺少缓存是否导致了性能问题:
检查应用程序设计。 盘点应用程序使用的所有数据存储。 对于每个数据存储,确定应用程序是否使用了缓存。 在可能的情况下,确定数据更改频率。 适合缓存的初始候选项包括缓慢更改的数据,以及频繁读取的静态引用数据。
检测应用程序并监视实时系统,找出应用程序检索数据或计算信息的频率。
在测试环境中分析应用程序,捕获有关与数据访问操作或其他经常执行的计算关联的开销的低级指标。
在测试环境中执行负载测试,识别系统在承受正常工作负荷和重度负载的情况下如何响应。 负载测试应使用真实工作负荷模拟在生产环境中观察到的数据访问模式。
检查底层数据存储的数据访问统计信息,并检查相同数据请求的重复频率。
示例诊断
以下部分将这些步骤应用到前面所述的示例应用程序。
检测应用程序并监视实时系统
应用程序已部署到生产环境时,检测并监视应用程序,以获取有关用户发出的特定请求的信息。
下图显示了在负载测试期间 New Relic 捕获的监视数据。 在本例中,执行唯一的 HTTP GET 操作是 Person/GetAsync。 但在实时生产环境中,了解每个请求的相对执行频率可以深入分析应该缓存哪些资源。
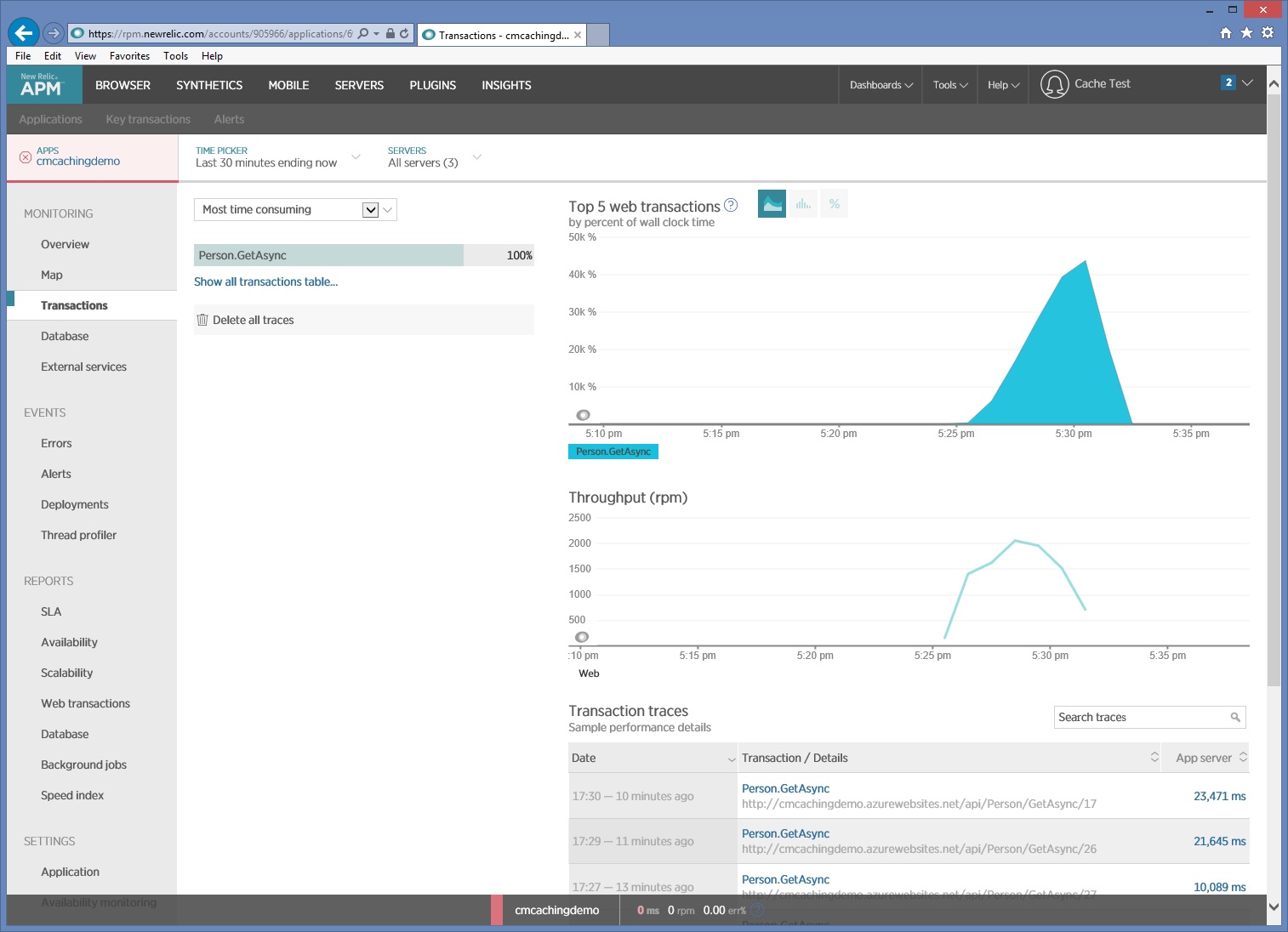
如果需要更深入的分析,可以在测试环境(而不是生产系统)中使用探查器捕获低级性能数据。 查看 I/O 请求速率、内存使用率和 CPU 利用率等指标。 这些指标可以显示向数据存储或服务发出的大量请求,或者执行相同计算的重复处理。
对应用程序进行负载测试
下图显示了对示例应用程序执行负载测试的结果。 该负载测试模拟一个包含多达 800 个用户的阶跃负载,这些用户执行一系列典型操作。
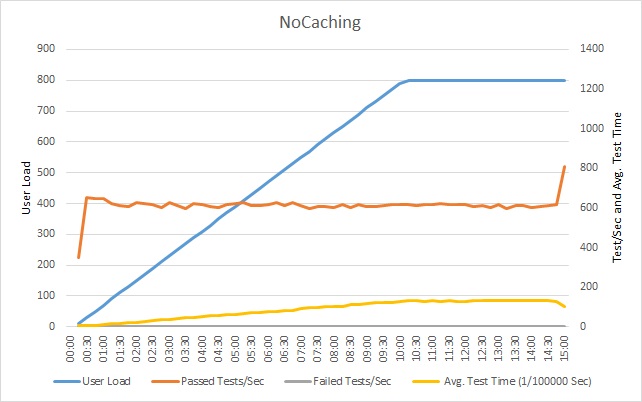
每秒成功执行的测试数达到平稳状态,因此,其他请求的速度减慢。 平均测试时间随着工作负荷的增大而平稳增加。 达到用户负载峰值后,响应时间趋向平稳。
检查数据访问统计信息
数据存储提供有用的数据访问统计信息和其他信息,例如,哪些查询的重复最频繁。 例如,在 Microsoft SQL Server 中,sys.dm_exec_query_stats 管理视图提供最近执行的查询的统计信息。 sys.dm_exec-query_plan 视图中提供每个查询的文本。 可以使用 SQL Server Management Studio 等工具运行以下 SQL 查询,并确定查询的执行频率。
SELECT UseCounts, Text, Query_Plan
FROM sys.dm_exec_cached_plans
CROSS APPLY sys.dm_exec_sql_text(plan_handle)
CROSS APPLY sys.dm_exec_query_plan(plan_handle)
结果中的 UseCount 列指示每个查询的运行频率。 下图显示第三个查询已运行 250,000 次以上,远远超过其他任何查询。
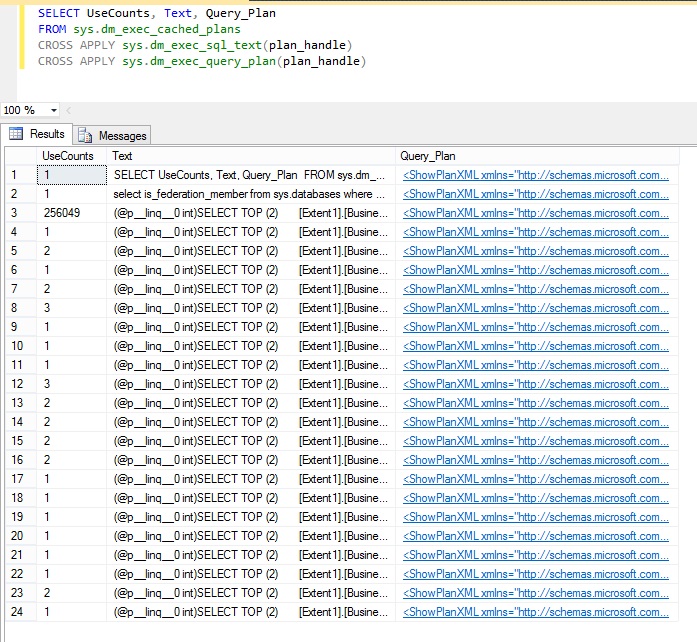
下面是导致发出过多数据库请求的 SQL 查询:
(@p__linq__0 int)SELECT TOP (2)
[Extent1].[BusinessEntityId] AS [BusinessEntityId],
[Extent1].[FirstName] AS [FirstName],
[Extent1].[LastName] AS [LastName]
FROM [Person].[Person] AS [Extent1]
WHERE [Extent1].[BusinessEntityId] = @p__linq__0
这是实体框架在前面所示的 GetByIdAsync 方法中生成的查询。
实施缓存策略解决方案并验证结果
合并缓存后,请重复负载测试,并将结果与前面未使用缓存执行的负载测试进行比较。 下面是将缓存添加到示例应用程序后的负载测试结果。
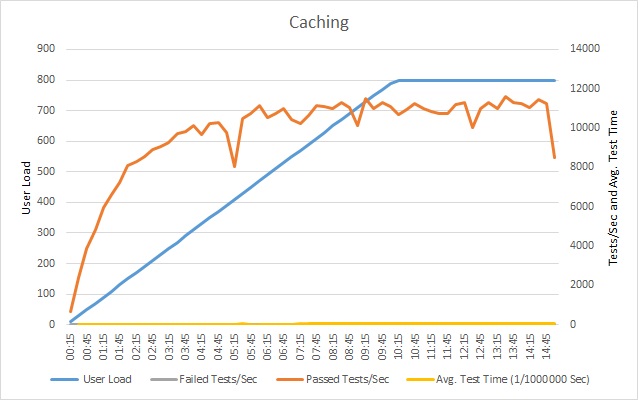
成功测试数量仍保持平稳状态,但用户负载更高。 在承受此负载时,请求速率明显高于前面的测试。 平均测试时间仍然随着负载的增大而增加,但最大响应时间为 0.05 毫秒,相比之前的 1 毫秒提升了 20 倍。
相关资源
反馈
即将发布:在整个 2024 年,我们将逐步淘汰作为内容反馈机制的“GitHub 问题”,并将其取代为新的反馈系统。 有关详细信息,请参阅:https://aka.ms/ContentUserFeedback。
提交和查看相关反馈