本参考体系结构演示如何使用 Azure Databricks 训练一个建议模型,并使用 Azure Cosmos DB、Azure 机器学习和 Azure Kubernetes 服务 (AKS) 将该模型作为 API 部署。 有关此体系结构的参考实现,请参阅在 GitHub 上生成实时建议 API。
体系结构

下载此体系结构的 Visio 文件。
本参考体系结构用于训练和部署实时推荐器服务 API,以便为用户提供排名前 10 的影片的建议。
数据流
- 跟踪用户行为。 例如,后端服务可能会记录用户何时对影片进行了评分或单击了某个产品或某篇新闻文章。
- 从可用的数据源将数据加载到 Azure Databricks 中。
- 准备数据并将其拆分为训练集和测试集,以便训练模型。 (此指南介绍拆分数据的选项。)
- 根据数据对 Spark 协作筛选模型进行拟合。
- 使用评分和排名指标对模型质量进行评估。 (此指南详细介绍了可以用来评估推荐器的指标。)
- 按用户预先计算排名前 10 的建议,并在 Azure Cosmos DB 中将其作为缓存存储。
- 使用机器学习 API 将 API 服务部署到 AKS,以便容器化和部署 API。
- 当后端服务从用户获取请求时,请调用托管在 AKS 中的建议 API,以便获取排名前 10 的建议并将其显示给用户。
组件
- Azure Databricks。 Databricks 是一个开发环境,用于在 Spark 群集上准备输入数据并训练推荐器模型。 Azure Databricks 还提供一个交互式工作区,用于运行笔记本并在其上进行协作,以便执行数据处理或机器学习任务。
- Azure Kubernetes 服务 (AKS)。 AKS 用于在 Kubernetes 群集上部署机器学习模型服务 API 并使之可操作。 AKS 托管容器化模型,提供符合吞吐量要求的可伸缩性,同时提供标识和访问管理以及日志记录和运行状况监视功能。
- Azure Cosmos DB。 Azure Cosmos DB 是一种全球分布式数据库服务,用于为每位用户存储排名前 10 的推荐影片。 Azure Cosmos DB 特别适合本方案,因为它的延迟低(99% 的情况下为 10 毫秒),可以为给定用户读取排名靠前的建议项。
- 机器学习。 此服务用于跟踪和管理机器学习模型,然后将这些模型打包并部署到可缩放的 AKS 环境。
- Microsoft 推荐器。 此开源存储库包含实用程序代码和示例,有助于用户完成推荐器系统的生成、评估和可操作方面的入门。
方案详细信息
本体系结构可以通用于大多数建议引擎方案,包括针对产品、影片和新闻的建议。
可能的用例
方案:一家媒体组织希望向其用户提供影片或视频建议。 通过提供个性化建议,组织可以满足多个业务目标,包括提高点击率、提高站点参与度以及提高用户满意度。
此解决方案针对零售行业以及媒体和娱乐行业进行优化。
注意事项
这些注意事项实施 Azure 架构良好的框架的支柱原则,即一套可用于改善工作负载质量的指导原则。 有关详细信息,请参阅 Microsoft Azure 架构良好的框架。
Azure Databricks 上 Spark 模型的批处理评分描述参考体系结构使用 Spark 和 Azure Databricks 执行计划的批处理评分过程。 建议使用此方法生成新建议。
性能效率
性能效率是指工作负载能够以高效的方式扩展以满足用户对它的需求。 有关详细信息,请参阅性能效率要素概述。
性能是实时建议的主要考量,因为建议通常落在站点上用户请求的关键路径中。
将 AKS 和 Azure Cosmos DB 组合在一起以后,此体系结构就可以为中型工作负荷提供建议,其开销极小。 在进行 200 个并发用户的负载测试时,此体系结构可以在中等延迟(大约 60 毫秒)情况下提供建议,表现出的吞吐量为每秒 180 个请求。 负载测试是针对默认部署配置(一个 3x D3 v2 AKS 群集,包含 12 个 vCPU、42 GB 内存、11,000 请求单元 (RU)/秒,针对 Azure Cosmos DB 进行预配)运行的。
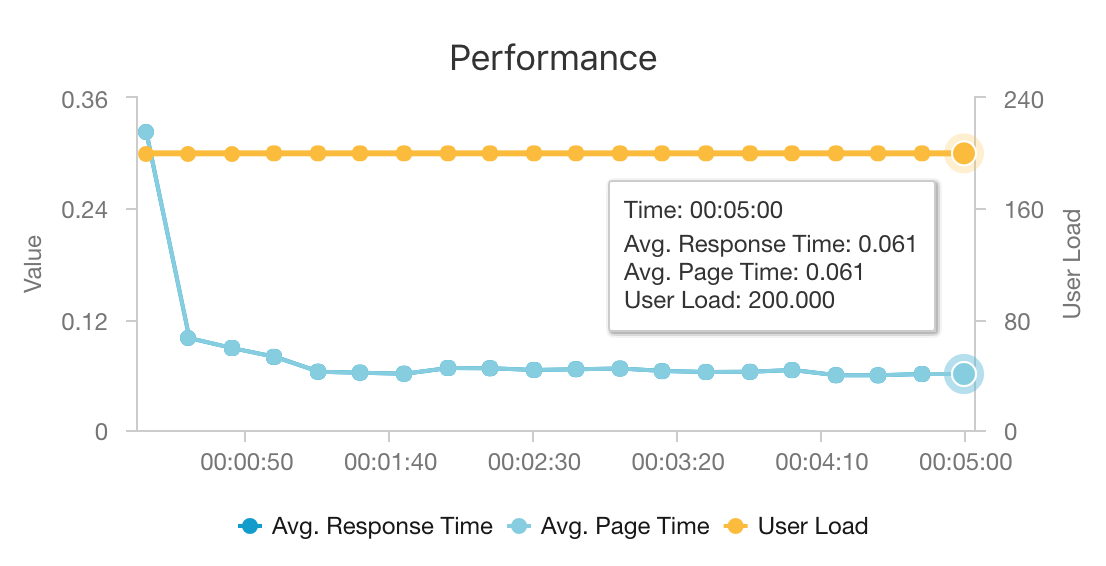
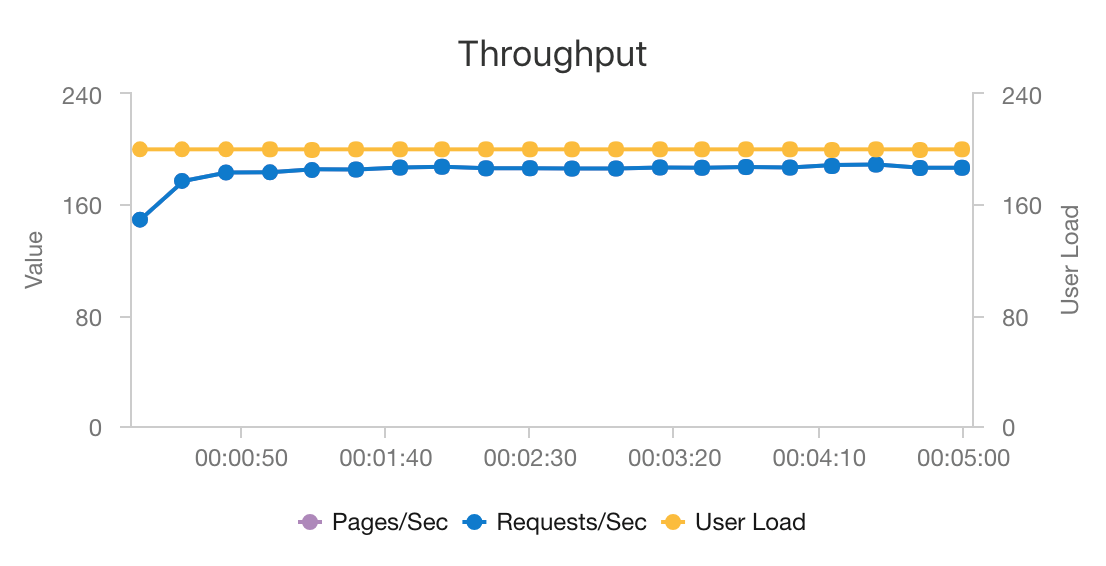
建议使用 Azure Cosmos DB 是因为它的统包式全球分发功能,以及它可以用来满足应用的任何数据库要求。 要稍微降低延迟,可以考虑使用 Azure Redis 缓存代替 Azure Cosmos DB 来提供查找服务。 对于高度依赖后端存储中数据的系统,Azure Cache for Redis 可以改进其性能。
可伸缩性
如果不打算使用 Spark,或者因工作负荷较小而不需要分发,则可考虑使用 Data Science Virtual Machine (DSVM) 代替 Azure Databricks。 DSVM 是搭载有机器学习和数据科学深度学习框架和工具的 Azure 虚拟机。 就像使用 Azure Databricks 一样,在 DSVM 中创建的任何模型都可以通过机器学习作为 AKS 上的服务来操作。
在训练期间,请在 Azure Databricks 中预配一个较大的固定大小的 Spark 群集,或者配置自动缩放。 在启用自动缩放的情况下,Databricks 会监视群集上的负载,并根据需要进行纵向扩展和缩放。 如果数据大,而你需要缩短数据准备或建模任务的完成时间,则可预配或横向扩展较大型的群集。
根据性能和吞吐量要求缩放 AKS 群集。 请谨慎地增加 Pod 数以充分利用群集,并按服务需求缩放群集的节点。 还可以在 AKS 群集上设置自动缩放。 有关详细信息,请参阅将模型部署到 Azure Kubernetes 服务群集。
若要管理 Azure Cosmos DB 性能,请估算每秒所需的读取数,然后预配所需的 RU/秒值(吞吐量)。 使用最佳做法进行分区和水平缩放。
成本优化
成本优化是关于寻找减少不必要的费用和提高运营效率的方法。 有关详细信息,请参阅成本优化支柱概述。
此方案中的主要成本动因包括:
- 训练所需的 Azure Databricks 群集大小。
- 满足性能要求所需的 AKS 群集大小。
- 根据性能要求预配的 Azure Cosmos DB RU。
通过降低重新训练的频率以及在 Spark 群集不使用的情况下将其关闭,对 Azure Databricks 成本进行管理。 AKS 和 Azure Cosmos DB 的成本与站点所需的吞吐量和性能相关,并且会根据入站流量上下浮动。
部署此方案
若要部署此体系结构,请按照安装文档中的 Azure Databricks 说明进行操作。 简单来说,该说明要求:
- 创建一个 Azure Databricks 工作区。
- 在 Azure Databricks 中使用以下配置创建新群集:
- 群集模式:标准
- Databricks 运行时版本:4.3 (包括 Apache Spark 2.3.1、Scala 2.11)
- Python 版本:3
- 驱动程序类型:Standard_DS3_v2
- 辅助角色类型:Standard_DS3_v2(所需最小值和最大值)
- 自动终止:(视需要进行选择)
- Spark 配置:(视需要进行选择)
- 环境变量:(视需要进行选择)
- 在 Azure Databricks 工作区中创建个人访问令牌。 有关详细信息,请参阅 Azure Databricks 身份验证文档。
- 将 Microsoft 推荐器存储库克隆到一个可以在其中执行脚本的环境中(例如,你的本地计算机)。
- 按照快速安装中的安装说明在 Azure Databricks 上安装相关库。
- 按照快速安装中的安装说明为操作化过程准备 Azure Databricks。
- 在工作区中,导入 ALS 影片操作化笔记本。 登录到 Azure Databricks 工作区后,请执行以下操作:
- 选择工作区左侧的“主页”。
- 右键单击主目录中的空白处。 选择“导入” 。
- 选择 “URL”,并将以下内容粘贴到文本字段中:
https://github.com/Microsoft/Recommenders/blob/main/examples/05_operationalize/als_movie_o16n.ipynb - 单击“导入” 。
- 在 Azure Databricks 中打开笔记本并附加配置的群集。
- 运行笔记本来创建必需的 Azure 资源,以便创建建议 API,为给定用户提供排名前 10 的影片的建议。
作者
本文由 Microsoft 维护, 它最初是由以下贡献者撰写的。
主要作者:
- Miguel Fierro | 首席数据科学家经理
- Nikhil Joglekar | 产品经理、Azure 算法和数据科学
若要查看非公开领英个人资料,请登录领英。