本参考体系结构演示一个可以引入数据流、处理数据,并将结果写入后端数据库的事件驱动式无服务器体系结构。
体系结构
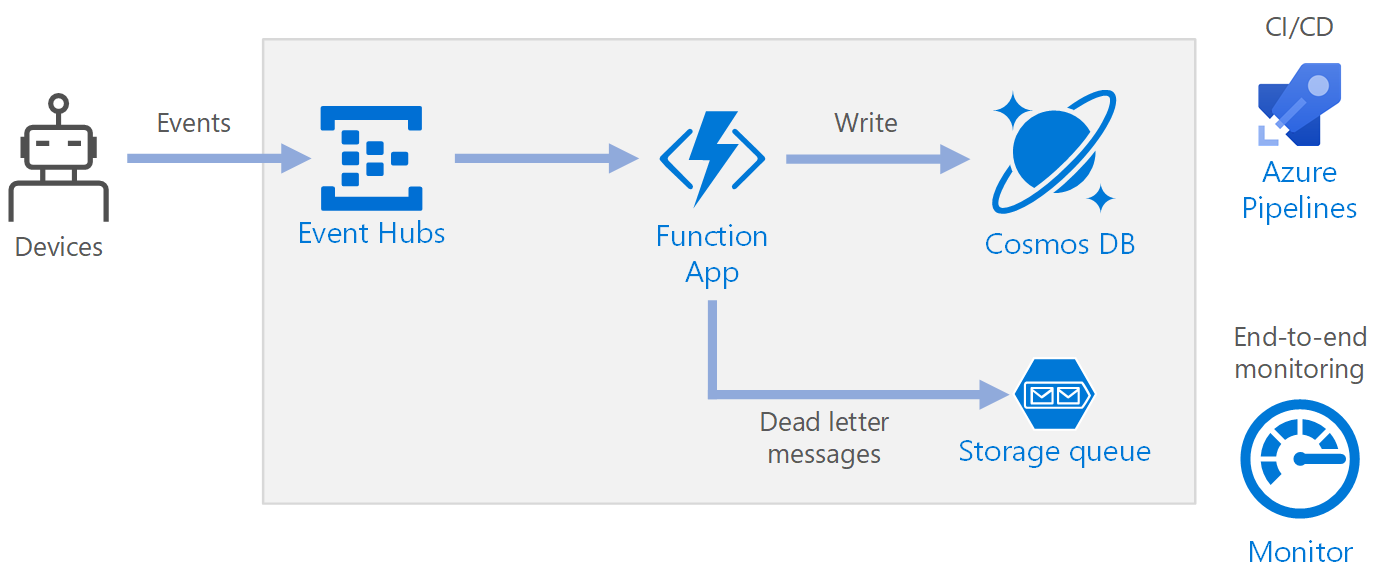
工作流
- 事件到达 Azure 事件中心。
- 触发函数应用来处理事件。
- 该事件将存储在 Azure Cosmos DB 数据库中。
- 如果函数应用未能成功存储事件,事件将保存到存储队列,以供之后处理。
组件
事件中心引入数据流。 事件中心面向高吞吐量数据流场景。
注意
对于物联网 (IoT) 场景,建议使用 Azure IoT 中心。 IoT 中心包含与 Azure 事件中心 API 兼容的内置终结点,因此,无需对后端处理进行重大更改,就能在本体系结构中使用任一服务。 有关详细信息,请参阅将 IoT 设备连接到 Azure:IoT 中心和事件中心。
函数应用。 Azure Functions 是一个无服务器计算选项。 它使用事件驱动的模型,其中的一段代码(“函数”)由触发器调用。 在本体系结构中,当事件抵达事件中心时,会触发一个函数,该函数处理事件并将结果写入存储。
函数应用适合用于处理来自事件中心的单个记录。 对于更复杂的流处理场景,请考虑结合 Azure Databricks 或 Azure 流分析使用 Apache Spark。
Azure Cosmos DB。 Azure Cosmos DB 是一个多模型数据库服务,可在基于消耗的无服务器模式下使用。 对于此方案,事件处理函数将使用 Azure Cosmos DB for NoSQL 存储 JSON 记录。
队列存储。 队列存储用于将消息加入死信队列。 如果处理事件时出错,函数会将事件数据存储到死信队列供稍后处理。 有关详细信息,请参阅本文后面的复原能力部分。
Azure Monitor。 Monitor 收集解决方案中部署的 Azure 服务的性能指标。 在仪表板中可视化这些指标可以洞察解决方案的运行状况。
Azure Pipelines。 Pipelines 是用于生成、测试和部署应用程序的持续集成 (CI) 和持续交付 (CD) 服务。
注意事项
这些注意事项实施 Azure 架构良好的框架的支柱原则,即一套可用于改善工作负载质量的指导原则。 有关详细信息,请参阅 Microsoft Azure 架构良好的框架。
可用性
下面所示的部署驻留在单个 Azure 区域中。 更具弹性的灾难恢复方法利用不同服务中的异地分发功能:
- 事件中心。 创建两个事件中心命名空间:主要(主动)命名空间和次要(被动)命名空间。 除非故障转移到次要命名空间,否则消息将自动路由到主动命名空间。 有关详细信息,请参阅 Azure 事件中心异地灾难恢复。
- 函数应用。 部署另一个函数应用,用于等待从次要事件中心命名空间读取数据。 此函数将数据写入死信队列的辅助存储帐户。
- Azure Cosmos DB。 Azure Cosmos DB 支持多个写入区域,因此可以向添加到 Azure Cosmos DB 帐户中的任何区域写入数据。 如果未启用多写入,仍可以故障转移主要写入区域。 Azure Cosmos DB 客户端 SDK 和 Azure 函数绑定会自动处理故障转移,因此你无需更新任何应用程序配置设置。
- Azure 存储。 将 RA-GRS 存储用于死信队列。 这会在另一个区域中创建只读副本。 如果主要区域不可用,可以读取当前位于队列中的项。 此外,在次要区域中预配另一个存储帐户,在故障转移后,函数可将数据写入该存储帐户。
可伸缩性
事件中心
事件中心的吞吐量容量以吞吐量单位来度量。 可以通过启用自动扩充来自动缩放事件中心。自动扩充可以根据流量,最高将吞吐量单位自动扩展到配置的上限。
函数应用中的事件中心触发器根据事件中心内的分区数进行缩放。 每次为每个分区分配一个函数实例。 若要最大程度地提高吞吐量,请分批接收事件,而不要逐个接收。
Azure Cosmos DB
Azure Cosmos DB 提供两种不同的容量模式:
若要确保工作负载可缩放,请务必在创建 Azure Cosmos DB 容器时选择适当的分区键。 下面是适当分区键的一些特征:
- 键值空间较大。
- 为每个键值平均分配读取/写入,避免出现热键。
- 为任何一个键值存储的数据上限不超过最大物理分区大小 (20 GB)。
- 文档的分区键不会更改。 无法更新现有文档中的分区键。
在本参考体系结构的方案中,函数针对发送数据的每个设备正好存储一个文档。 函数使用 upsert 操作持续以最新的设备状态更新文档。 设备 ID 非常适合在此场景中用作分区键,因为写入操作将在不同的键之间平均分配,并且每个分区的大小严格受限,因为每个键值对应单个文档。 有关分区键的详细信息,请参阅 Azure Cosmos DB 中的分区和缩放。
复原
配合 Functions 使用事件中心触发器时,可以捕获处理循环中的异常。 如果发生未经处理的异常,Functions 运行时不会重试消息。 如果无法处理某个消息,会将该消息放入死信队列。 使用带外进程来检查消息并确定纠正措施。
以下代码演示引入函数如何捕获异常,并将未经处理的消息放入死信队列。
[FunctionName("RawTelemetryFunction")]
[StorageAccount("DeadLetterStorage")]
public static async Task RunAsync(
[EventHubTrigger("%EventHubName%", Connection = "EventHubConnection", ConsumerGroup ="%EventHubConsumerGroup%")]EventData[] messages,
[Queue("deadletterqueue")] IAsyncCollector<DeadLetterMessage> deadLetterMessages,
ILogger logger)
{
foreach (var message in messages)
{
DeviceState deviceState = null;
try
{
deviceState = telemetryProcessor.Deserialize(message.Body.Array, logger);
}
catch (Exception ex)
{
logger.LogError(ex, "Error deserializing message", message.SystemProperties.PartitionKey, message.SystemProperties.SequenceNumber);
await deadLetterMessages.AddAsync(new DeadLetterMessage { Issue = ex.Message, EventData = message });
}
try
{
await stateChangeProcessor.UpdateState(deviceState, logger);
}
catch (Exception ex)
{
logger.LogError(ex, "Error updating status document", deviceState);
await deadLetterMessages.AddAsync(new DeadLetterMessage { Issue = ex.Message, EventData = message, DeviceState = deviceState });
}
}
}
请注意,函数使用队列存储输出绑定将项放入队列。
所示代码还会将异常记录到 Application Insights。 可以使用分区键和序号将死信消息与日志中的异常相关联。
死信队列中的消息应该包含足够的信息,使你能够了解错误的上下文。 在此示例中,DeadLetterMessage 类包含异常消息、原始事件数据,以及反序列化的事件消息(如果有)。
public class DeadLetterMessage
{
public string Issue { get; set; }
public EventData EventData { get; set; }
public DeviceState DeviceState { get; set; }
}
使用 Azure Monitor 监视事件中心。 如果显示了输入但未显示输出,则表示消息尚未处理。 在此情况下,请转到 Log Analytics 并查找异常或其他错误。
DevOps
尽可能使用基础结构作为代码 (IaC)。 IaC 使用声明性方法(如 Azure 资源管理器)管理基础结构、应用程序和存储资源。 这将有助于使用 DevOps 作为持续集成和持续交付 (CI/CD) 解决方案来自动化部署。 模板应进行版本控制并作为发布管道的一部分包含在内。
创建模板时,请对资源进行分组,以便按工作负载整理和隔离资源。 考虑工作负载的常见方法是单个无服务器应用程序或虚拟网络。 隔离工作负载的目的是将资源关联到团队,使 DevOps 团队能够独立管理这些资源的所有方面并执行 CI/CD。
此体系结构包括使用具有 YAML 和 Azure Functions 槽的 Azure 管道配置无人机状态函数应用的步骤。
部署服务时,需要对其进行监视。 请考虑使用 Application Insights 来让开发人员监视性能和检测问题。
有关详细信息,请参阅 DevOps 清单。
灾难恢复
下面所示的部署驻留在单个 Azure 区域中。 更具弹性的灾难恢复方法利用不同服务中的异地分发功能:
事件中心。 创建两个事件中心命名空间:主要(主动)命名空间和次要(被动)命名空间。 除非故障转移到次要命名空间,否则消息将自动路由到主动命名空间。 有关详细信息,请参阅 Azure 事件中心异地灾难恢复。
函数应用。 部署另一个函数应用,用于等待从次要事件中心命名空间读取数据。 此函数将数据写入死信队列的辅助存储帐户。
Azure Cosmos DB。 Azure Cosmos DB 支持多个写入区域,因此可以向添加到 Azure Cosmos DB 帐户中的任何区域写入数据。 如果未启用多写入,仍可以故障转移主要写入区域。 Azure Cosmos DB 客户端 SDK 和 Azure 函数绑定会自动处理故障转移,因此你无需更新任何应用程序配置设置。
Azure 存储。 将 RA-GRS 存储用于死信队列。 这会在另一个区域中创建只读副本。 如果主要区域不可用,可以读取当前位于队列中的项。 此外,在次要区域中预配另一个存储帐户,在故障转移后,函数可将数据写入该存储帐户。
成本优化
成本优化是关于寻找减少不必要的费用和提高运营效率的方法。 有关详细信息,请参阅成本优化支柱概述。
使用 Azure 定价计算器估算成本。 下面是有关 Azure Functions 和 Azure Cosmos DB 的一些其他注意事项。
Azure Functions
Azure Functions 支持两种托管模型:
- 消耗计划。 在运行代码时自动分配计算能力。
- 应用服务计划。 一组虚拟机 (VM) 会分配给代码。 应用服务计划定义 VM 数目和 VM 大小。
在此体系结构中,到达事件中心的每个事件都会触发一个处理该事件的函数。 从成本角度来看,建议使用消耗计划,因为只需为所使用的计算资源付费。
Azure Cosmos DB
使用 Azure Cosmos DB,你需要为你针对数据库执行的操作以及你的数据使用的存储付费。
- 数据库操作。 数据库操作的收费方式取决于你使用的 Azure Cosmos DB 帐户的类型。
- 存储。 给定小时内数据和索引所消耗的存储总量(以 GB 为单位)按统一费率计费。
在本参考体系结构中,函数针对发送数据的每个设备正好存储一个文档。 该函数使用更新插入操作,以最新设备状态持续更新文档,这在使用的存储方面比较经济高效。 有关详细信息,请参阅 Azure Cosmos DB 定价模型。
使用 Azure Cosmos DB 容量计算器快速估算工作负载成本。
部署此方案
 GitHub 中提供了本体系结构的参考实现。
GitHub 中提供了本体系结构的参考实现。