教程:使用 Azure Databricks 提取、转换和加载数据
本教程使用 Azure Databricks 执行 ETL(提取、转换和加载数据)操作。 将数据从 Azure Data Lake Storage Gen2 提取到 Azure Databricks 中,在 Azure Databricks 中对数据运行转换操作,然后将转换的数据加载到 Azure Synapse Analytics 中。
本教程中的步骤使用 Azure Databricks 的 Azure Synapse 连接器将数据传输到 Azure Databricks。 而此连接器又使用 Azure Blob 存储来临时存储在 Azure Databricks 群集和 Azure Synapse 之间传输的数据。
下图演示了应用程序流:

本教程涵盖以下任务:
- 创建 Azure Databricks 服务。
- 在 Azure Databricks 中创建 Spark 群集。
- 在 Data Lake Storage Gen2 帐户中创建文件系统。
- 上传示例数据到 Azure Data Lake Storage Gen2 帐户。
- 创建服务主体。
- 从 Azure Data Lake Storage Gen2 帐户中提取数据。
- 在 Azure Databricks 中转换数据。
- 将数据加载到 Azure Synapse 中。
如果没有 Azure 订阅,请在开始之前创建一个免费帐户。
注意
不能使用 Azure 免费试用订阅完成本教程 。 如果你有免费帐户,请转到个人资料并将订阅更改为“即用即付”。 有关详细信息,请参阅 Azure 免费帐户。 然后,移除支出限制,并为你所在区域的 vCPU 请求增加配额。 创建 Azure Databricks 工作区时,可以选择“试用版(高级 - 14天免费 DBU)”定价层,让工作区访问免费的高级 Azure Databricks DBU 14 天。
先决条件
在开始本教程之前,完成以下任务:
创建 Azure Synapse,创建服务器级防火墙规则,然后以服务器管理员身份连接到服务器。请参阅快速入门:使用 Azure 门户创建和查询 Synapse SQL 池。
为 Azure Synapse 创建主密钥。 请参阅创建数据库主密钥。
创建 Azure Blob 存储帐户并在其中创建容器。 另外,请检索用于访问该存储帐户的访问密钥。 请参阅快速入门:使用 Azure 门户上传、下载和列出 Blob。
创建 Azure Data Lake Storage Gen2 存储帐户。 请参阅快速入门:创建 Azure Data Lake Storage Gen2 存储帐户。
创建服务主体。 请参阅如何:使用门户创建可访问资源的 Microsoft Entra ID(旧称 Azure Active Directory)应用程序和服务主体。
在执行该文中的步骤时,需要完成一些特定的事项。
执行该文中将应用程序分配给角色部分中的步骤时,请确保将“存储 Blob 数据参与者”角色分配给 Data Lake Storage Gen2 帐户的作用域中的服务主体。 如果将角色分配给父资源组或订阅,那么在这些角色分配传播到存储帐户之前,会收到与权限相关的错误。
如果想使用访问控制列表 (ACL) 来关联服务主体和特定的文件或目录,请参考 Azure Data Lake Storage Gen2 中的访问控制。
执行本文中获取用于登录的值部分中的步骤时,请将租户 ID、应用 ID 和机密值粘贴到文本文件中。
登录 Azure 门户。
收集所需信息
确保完成本教程的先决条件。
在开始之前,应具有以下这些信息项:
✔️ Azure Synapse 的数据库名称、数据库服务器名称、用户名和密码。
✔️ blob 存储帐户的访问密钥。
✔️ Data Lake Storage Gen2 存储帐户的名称。
✔️ 订阅的租户 ID。
✔️ 向 Microsoft Entra ID(以前称为 Azure Active Directory)注册的应用的应用程序 ID。
✔️ 向 Microsoft Entra ID(以前称为 Azure Active Directory)注册的应用的身份验证密钥。
创建 Azure Databricks 服务
在本部分中,你将使用 Azure 门户创建 Azure Databricks 服务。
在 Azure 门户菜单中,选择“创建资源” 。
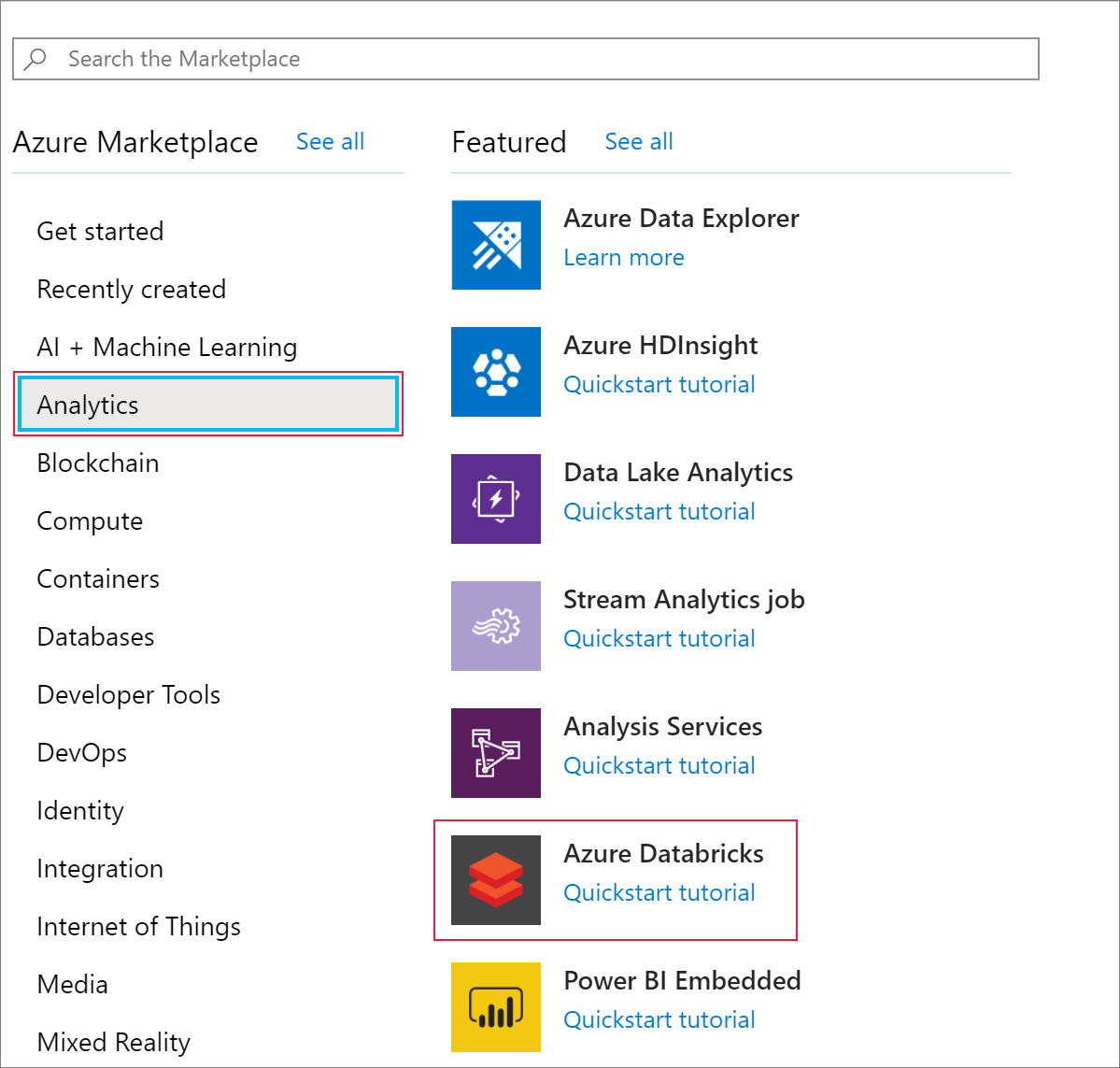
然后,选择“分析”>“Azure Databricks” 。
在“Azure Databricks 服务” 下,提供以下值来创建 Databricks 服务:
properties 说明 工作区名称 为 Databricks 工作区提供一个名称。 订阅 从下拉列表中选择自己的 Azure 订阅。 资源组 指定是要创建新的资源组还是使用现有的资源组。 资源组是用于保存 Azure 解决方案相关资源的容器。 有关详细信息,请参阅 Azure 资源组概述。 位置 选择“美国西部 2” 。 有关其他可用区域,请参阅各区域推出的 Azure 服务。 定价层 选择“标准” 。 创建帐户需要几分钟时间。 若要监视操作状态,请查看顶部的进度栏。
选择“固定到仪表板” ,然后选择“创建” 。
在 Azure Databricks 中创建 Spark 群集
在 Azure 门户中,转到所创建的 Databricks 服务,然后选择“启动工作区”。
系统随后会将你重定向到 Azure Databricks 门户。 在门户中选择“群集”。

在“新建群集”页中,提供用于创建群集的值。

填写以下字段的值,对于其他字段接受默认值:
输入群集的名称。
请务必选中“在不活动超过 分钟后终止”复选框。 如果未使用群集,则请提供一个持续时间(以分钟为单位),超过该时间后群集会被终止。
选择“创建群集”。 群集运行后,可将笔记本附加到该群集,并运行 Spark 作业。
在 Azure Data Lake Storage Gen2 帐户中创建文件系统
在本部分中,你将在 Azure Databricks 工作区中创建一个 Notebook,然后运行代码片段来配置存储帐户
在 Azure 门户中,转到你创建的 Azure Databricks 服务,然后选择“启动工作区”。
在左侧选择“工作区” 。 在工作区下拉列表中,选择创建>笔记本。

在“创建 Notebook”对话框中,输入 Notebook 的名称。 选择“Scala”作为语言,然后选择前面创建的 Spark 群集。

选择创建。
以下代码块设置 Spark 会话中访问的任何 ADLS Gen 2 帐户的默认服务主体凭据。 第二个代码块会将帐户名称追加到该设置,从而指定特定的 ADLS Gen 2 帐户的凭据。 将任一代码块复制并粘贴到 Azure Databricks 笔记本的第一个单元格中。
会话配置
val appID = "<appID>" val secret = "<secret>" val tenantID = "<tenant-id>" spark.conf.set("fs.azure.account.auth.type", "OAuth") spark.conf.set("fs.azure.account.oauth.provider.type", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider") spark.conf.set("fs.azure.account.oauth2.client.id", "<appID>") spark.conf.set("fs.azure.account.oauth2.client.secret", "<secret>") spark.conf.set("fs.azure.account.oauth2.client.endpoint", "https://login.microsoftonline.com/<tenant-id>/oauth2/token") spark.conf.set("fs.azure.createRemoteFileSystemDuringInitialization", "true")帐户配置
val storageAccountName = "<storage-account-name>" val appID = "<app-id>" val secret = "<secret>" val fileSystemName = "<file-system-name>" val tenantID = "<tenant-id>" spark.conf.set("fs.azure.account.auth.type." + storageAccountName + ".dfs.core.windows.net", "OAuth") spark.conf.set("fs.azure.account.oauth.provider.type." + storageAccountName + ".dfs.core.windows.net", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider") spark.conf.set("fs.azure.account.oauth2.client.id." + storageAccountName + ".dfs.core.windows.net", "" + appID + "") spark.conf.set("fs.azure.account.oauth2.client.secret." + storageAccountName + ".dfs.core.windows.net", "" + secret + "") spark.conf.set("fs.azure.account.oauth2.client.endpoint." + storageAccountName + ".dfs.core.windows.net", "https://login.microsoftonline.com/" + tenantID + "/oauth2/token") spark.conf.set("fs.azure.createRemoteFileSystemDuringInitialization", "true") dbutils.fs.ls("abfss://" + fileSystemName + "@" + storageAccountName + ".dfs.core.windows.net/") spark.conf.set("fs.azure.createRemoteFileSystemDuringInitialization", "false")在此代码块中,请将
<app-id>、<secret>、<tenant-id>和<storage-account-name>占位符值替换为在完成本教程的先决条件时收集的值。 将<file-system-name>占位符值替换为你想要为文件系统指定的任何名称。<app-id>和<secret>来自在创建服务主体的过程中向 active directory 注册的应用。<tenant-id>来自你的订阅。<storage-account-name>是 Azure Data Lake Storage Gen2 存储帐户的名称。
按 SHIFT + ENTER 键,运行此块中的代码。
将示例数据引入 Azure Data Lake Storage Gen2 帐户
开始学习本部分之前,必须完成以下先决条件:
将以下代码输入到 Notebook 单元格中:
%sh wget -P /tmp https://raw.githubusercontent.com/Azure/usql/master/Examples/Samples/Data/json/radiowebsite/small_radio_json.json
在单元格中,按 SHIFT + ENTER 来运行代码 。
现在,请在此单元格下方的新单元格中输入以下代码,将括号中出现的值替换为此前使用的相同值:
dbutils.fs.cp("file:///tmp/small_radio_json.json", "abfss://" + fileSystemName + "@" + storageAccountName + ".dfs.core.windows.net/")
在单元格中,按 SHIFT + ENTER 来运行代码 。
从 Azure Data Lake Storage Gen2 帐户中提取数据
现在可以将示例 json 文件加载为 Azure Databricks 中的数据帧。 将以下代码粘贴到新单元格中。 将括号中显示的占位符替换为你的值。
val df = spark.read.json("abfss://" + fileSystemName + "@" + storageAccountName + ".dfs.core.windows.net/small_radio_json.json")按 SHIFT + ENTER 键,运行此块中的代码。
运行以下代码来查看数据帧的内容:
df.show()会显示类似于以下代码片段的输出:
+---------------------+---------+---------+------+-------------+----------+---------+-------+--------------------+------+--------+-------------+---------+--------------------+------+-------------+------+ | artist| auth|firstName|gender|itemInSession| lastName| length| level| location|method| page| registration|sessionId| song|status| ts|userId| +---------------------+---------+---------+------+-------------+----------+---------+-------+--------------------+------+--------+-------------+---------+--------------------+------+-------------+------+ | El Arrebato |Logged In| Annalyse| F| 2|Montgomery|234.57914| free | Killeen-Temple, TX| PUT|NextSong|1384448062332| 1879|Quiero Quererte Q...| 200|1409318650332| 309| | Creedence Clearwa...|Logged In| Dylann| M| 9| Thomas|340.87138| paid | Anchorage, AK| PUT|NextSong|1400723739332| 10| Born To Move| 200|1409318653332| 11| | Gorillaz |Logged In| Liam| M| 11| Watts|246.17751| paid |New York-Newark-J...| PUT|NextSong|1406279422332| 2047| DARE| 200|1409318685332| 201| ... ...现在,你已将数据从 Azure Data Lake Storage Gen2 提取到 Azure Databricks 中。
在 Azure Databricks 中转换数据
原始示例数据 small_radio_json.json 文件捕获某个电台的听众,有多个不同的列。 在此部分,请对该数据进行转换,仅检索数据集中的特定列。
首先,仅从已创建的 dataframe 检索 firstName、lastName、gender、location 和 level 列。
val specificColumnsDf = df.select("firstname", "lastname", "gender", "location", "level") specificColumnsDf.show()接收的输出如以下代码片段所示:
+---------+----------+------+--------------------+-----+ |firstname| lastname|gender| location|level| +---------+----------+------+--------------------+-----+ | Annalyse|Montgomery| F| Killeen-Temple, TX| free| | Dylann| Thomas| M| Anchorage, AK| paid| | Liam| Watts| M|New York-Newark-J...| paid| | Tess| Townsend| F|Nashville-Davidso...| free| | Margaux| Smith| F|Atlanta-Sandy Spr...| free| | Alan| Morse| M|Chicago-Napervill...| paid| |Gabriella| Shelton| F|San Jose-Sunnyval...| free| | Elijah| Williams| M|Detroit-Warren-De...| paid| | Margaux| Smith| F|Atlanta-Sandy Spr...| free| | Tess| Townsend| F|Nashville-Davidso...| free| | Alan| Morse| M|Chicago-Napervill...| paid| | Liam| Watts| M|New York-Newark-J...| paid| | Liam| Watts| M|New York-Newark-J...| paid| | Dylann| Thomas| M| Anchorage, AK| paid| | Alan| Morse| M|Chicago-Napervill...| paid| | Elijah| Williams| M|Detroit-Warren-De...| paid| | Margaux| Smith| F|Atlanta-Sandy Spr...| free| | Alan| Morse| M|Chicago-Napervill...| paid| | Dylann| Thomas| M| Anchorage, AK| paid| | Margaux| Smith| F|Atlanta-Sandy Spr...| free| +---------+----------+------+--------------------+-----+可以进一步转换该数据,将 level 列重命名为 subscription_type。
val renamedColumnsDF = specificColumnsDf.withColumnRenamed("level", "subscription_type") renamedColumnsDF.show()接收的输出如以下代码片段所示。
+---------+----------+------+--------------------+-----------------+ |firstname| lastname|gender| location|subscription_type| +---------+----------+------+--------------------+-----------------+ | Annalyse|Montgomery| F| Killeen-Temple, TX| free| | Dylann| Thomas| M| Anchorage, AK| paid| | Liam| Watts| M|New York-Newark-J...| paid| | Tess| Townsend| F|Nashville-Davidso...| free| | Margaux| Smith| F|Atlanta-Sandy Spr...| free| | Alan| Morse| M|Chicago-Napervill...| paid| |Gabriella| Shelton| F|San Jose-Sunnyval...| free| | Elijah| Williams| M|Detroit-Warren-De...| paid| | Margaux| Smith| F|Atlanta-Sandy Spr...| free| | Tess| Townsend| F|Nashville-Davidso...| free| | Alan| Morse| M|Chicago-Napervill...| paid| | Liam| Watts| M|New York-Newark-J...| paid| | Liam| Watts| M|New York-Newark-J...| paid| | Dylann| Thomas| M| Anchorage, AK| paid| | Alan| Morse| M|Chicago-Napervill...| paid| | Elijah| Williams| M|Detroit-Warren-De...| paid| | Margaux| Smith| F|Atlanta-Sandy Spr...| free| | Alan| Morse| M|Chicago-Napervill...| paid| | Dylann| Thomas| M| Anchorage, AK| paid| | Margaux| Smith| F|Atlanta-Sandy Spr...| free| +---------+----------+------+--------------------+-----------------+
将数据加载到 Azure Synapse 中
在本部分,请将转换的数据上传到 Azure Synapse 中。 使用适用于 Azure Databricks 的 Azure Synapse 连接器直接上传数据帧,在 Azure Synapse 池中作为表来存储。
如前所述,Azure Synapse 连接器使用 Azure Blob 存储作为临时存储,以便将数据从 Azure Databricks 上传到 Azure Synapse。 因此,一开始请提供连接到存储帐户所需的配置。 必须已经按照本文先决条件部分的要求创建了帐户。
提供从 Azure Databricks 访问 Azure 存储帐户所需的配置。
val blobStorage = "<blob-storage-account-name>.blob.core.windows.net" val blobContainer = "<blob-container-name>" val blobAccessKey = "<access-key>"指定一个在 Azure Databricks 和 Azure Synapse 之间移动数据时需要使用的临时文件夹。
val tempDir = "wasbs://" + blobContainer + "@" + blobStorage +"/tempDirs"运行以下代码片段,以便在配置中存储 Azure Blob 存储访问密钥。 此操作可确保不需将访问密钥以纯文本形式存储在笔记本中。
val acntInfo = "fs.azure.account.key."+ blobStorage sc.hadoopConfiguration.set(acntInfo, blobAccessKey)提供连接到 Azure Synapse 实例所需的值。 先决条件是必须已创建 Azure Synapse Analytics 服务。 为 dwServer 使用完全限定的服务器名称 。 例如,
<servername>.database.windows.net。//Azure Synapse related settings val dwDatabase = "<database-name>" val dwServer = "<database-server-name>" val dwUser = "<user-name>" val dwPass = "<password>" val dwJdbcPort = "1433" val dwJdbcExtraOptions = "encrypt=true;trustServerCertificate=true;hostNameInCertificate=*.database.windows.net;loginTimeout=30;" val sqlDwUrl = "jdbc:sqlserver://" + dwServer + ":" + dwJdbcPort + ";database=" + dwDatabase + ";user=" + dwUser+";password=" + dwPass + ";$dwJdbcExtraOptions" val sqlDwUrlSmall = "jdbc:sqlserver://" + dwServer + ":" + dwJdbcPort + ";database=" + dwDatabase + ";user=" + dwUser+";password=" + dwPass运行以下代码片段来加载转换的数据帧 renamedColumnsDF ,在 Azure Synapse 中将其存储为表。 此代码片段在 SQL 数据库中创建名为 SampleTable 的表。
spark.conf.set( "spark.sql.parquet.writeLegacyFormat", "true") renamedColumnsDF.write.format("com.databricks.spark.sqldw").option("url", sqlDwUrlSmall).option("dbtable", "SampleTable") .option( "forward_spark_azure_storage_credentials","True").option("tempdir", tempDir).mode("overwrite").save()注意
此示例使用
forward_spark_azure_storage_credentials标志,Azure Synapse 可以根据该标志使用访问密钥访问 blob 存储中的数据。 这是唯一支持的身份验证方法。如果将 Azure Blob 存储限制为特选虚拟网络,则 Azure Synapse 需要托管服务标识而非访问密钥。 这将导致错误“此请求无权执行此操作”。
连接到 SQL 数据库,验证是否看到名为 SampleTable 的数据库。

运行一个 select 查询,验证表的内容。 该表的数据应该与 renamedColumnsDF dataframe 相同。

清理资源
完成本教程后,可以终止群集。 在 Azure Databricks 工作区的左侧选择“群集” 。 对于要终止的群集,请将鼠标指向“操作” 下面的省略号 (...),然后选择“终止” 图标。

如果不手动终止群集,但在创建群集时选中了“在不活动 分钟后终止”复选框,则该群集会自动停止。 在这种情况下,如果群集保持非活动状态超过指定的时间,则会自动停止。
后续步骤
在本教程中,你了解了如何执行以下操作:
- 创建 Azure Databricks 服务
- 在 Azure Databricks 中创建 Spark 群集
- 在 Azure Databricks 中创建 Notebook
- 从 Data Lake Storage Gen2 帐户提取数据
- 在 Azure Databricks 中转换数据
- 将数据加载到 Azure Synapse 中