你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
快速入门:适用于 Python 的 Azure Cosmos DB for MongoDB 与 MongoDB 驱动程序
适用对象:![]() MongoDB
MongoDB
开始使用 PyMongo 在 Azure Cosmos DB 资源中创建数据库、集合和文档。 请按照以下步骤安装程序包并试用基本任务的示例代码。
注意
示例代码片段在 GitHub 上作为 Python 项目提供。
在本快速入门中,你将使用适用于 Python 的开源 MongoDB 客户端驱动程序 PyMongo 来与 Azure Cosmos DB API for MongoDB 通信。 此外,你将使用 MongoDB 扩展命令,这些命令旨在帮助你创建和获取特定于 Azure Cosmos DB 容量模型的数据库资源。
先决条件
- 具有活动订阅的 Azure 帐户。 免费创建帐户。
- Python 3.8+
- Azure 命令行接口 (CLI) 或 Azure PowerShell
先决条件检查
- 在终端或命令窗口中,运行
python --version检查是否安装了最新版本的 Python。 - 运行
az --version(Azure CLI) 或Get-Module -ListAvailable Az*(Azure PowerShell),检查是否安装了适当的 Azure 命令行工具。
设置
本部分引导你创建 Azure Cosmos DB 帐户并设置使用 MongoDB npm 包的项目。
创建 Azure Cosmos DB 帐户
本快速入门将使用 API for MongoDB 创建单个 Azure Cosmos DB 帐户。
为 accountName、resourceGroupName 和 location 创建 shell 变量。
# Variable for resource group name resourceGroupName="msdocs-cosmos-quickstart-rg" location="westus" # Variable for account name with a randomnly generated suffix let suffix=$RANDOM*$RANDOM accountName="msdocs-$suffix"如果尚未登录,请使用
az login命令登录到 Azure CLI。使用
az group create命令在订阅中创建新的资源组。az group create \ --name $resourceGroupName \ --location $location使用
az cosmosdb create命令创建具有默认设置的新 Azure Cosmos DB for MongoDB 帐户。az cosmosdb create \ --resource-group $resourceGroupName \ --name $accountName \ --locations regionName=$location --kind MongoDB



获取 MongoDB 连接字符串
使用
az cosmosdb keys list命令,从帐户的连接字符串列表中查找 API for MongoDB 连接字符串。az cosmosdb keys list --type connection-strings \ --resource-group $resourceGroupName \ --name $accountName请记下“主密钥”值。 稍后将使用这些凭据。

创建新的 Python 应用
使用首选的终端创建一个新空文件夹,并将目录切换到该文件夹。
注意
如果你只想查看已完成的代码,请下载或者分叉并克隆包含完整示例的示例代码片段存储库。 还可以在 Azure Cloud Shell 中对该存储库运行
git clone,以演练本快速入门中的步骤。创建一个列出了 PyMongo 和 python-dotenv 包的 requirements.txt 文件。
# requirements.txt pymongo python-dotenv创建一个虚拟环境并安装这些包。
# py -3 uses the global python interpreter. You can also use python3 -m venv .venv. py -3 -m venv .venv source .venv/Scripts/activate pip install -r requirements.txt
配置环境变量
若要在代码中使用“连接字符串”值,请在运行应用程序的本地环境中设置此值。 若要设置环境变量,请使用首选终端运行以下命令:
$env:COSMOS_CONNECTION_STRING = "<cosmos-connection-string>"
对象模型
让我们看看 API for MongoDB 中的资源层次结构,以及用于创建和访问这些资源的对象模型。 Azure Cosmos DB 在由帐户、数据库、集合和文档组成的层次结构中创建资源。
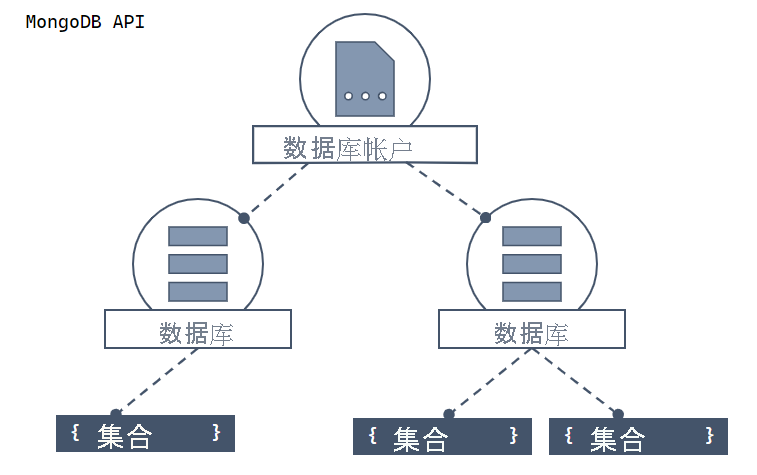
顶部是显示 Azure Cosmos DB 帐户的层次结构示意图。 帐户包含两个子数据库分片。 其中一个数据库分片包含两个子集合分片。 另一个数据库分片包含单个子集合分片。 该子集合分片包含三个子文档分片。
每种类型的资源均由 Python 类表示。 下面是最常见的类:
MongoClient - 使用 PyMongo 时的第一步是创建一个 MongoClient 以连接到 Azure Cosmos DB API for MongoDB。 此客户端对象用于对服务进行配置和执行请求。
数据库 - Azure Cosmos DB API for MongoDB 支持一个或多个独立数据库。
集合 - 一个数据库可以包含一个或多个集合。 集合是存储在 MongoDB 中的一组文档,大致相当于关系数据库中的表。
文档 - 文档是一组键值对。 文档具有动态架构。 动态架构是指同一集合中的文档不需要有相同的字段集或结构。 集合文档中的常见字段可以包含不同类型的数据。
若要详细了解实体的层次结构,请参阅 Azure Cosmos DB 资源模型一文。
代码示例
本文中所述的示例代码创建名为 adventureworks 的数据库和名为 products 的集合。 products 集合设计为包含产品详细信息,例如名称、类别、数量和销售指标。 每个产品还包含一个唯一标识符。 https://github.com/Azure-Samples/azure-cosmos-db-mongodb-python-getting-started/tree/main/001-quickstart/ 上提供了完整的示例代码。
对于以下步骤,数据库将不使用分片,而是显示一个使用 PyMongo 驱动程序的同步应用程序。 对于异步应用程序,请使用 Motor 驱动程序。
验证客户端
在项目目录中创建 run.py 文件。 在编辑器中,添加 require 语句以引用你要使用的包,包括 PyMongo 和 python-dotenv 包。
import os import sys from random import randint import pymongo from dotenv import load_dotenv从 .env 文件中定义的环境变量获取连接信息。
load_dotenv() CONNECTION_STRING = os.environ.get("COSMOS_CONNECTION_STRING")定义要在代码中使用的常量。
DB_NAME = "adventureworks" COLLECTION_NAME = "products"
连接到 Azure Cosmos DB API for MongoDB
使用 MongoClient 对象连接到 Azure Cosmos DB for MongoDB 资源。 connect 方法返回对数据库的引用。
client = pymongo.MongoClient(CONNECTION_STRING)
获取数据库
使用 list_database_names 方法检查数据库是否存在。 如果数据库不存在,请运行 create database extension 命令使用指定的预配吞吐量创建该数据库。
# Create database if it doesn't exist
db = client[DB_NAME]
if DB_NAME not in client.list_database_names():
# Create a database with 400 RU throughput that can be shared across
# the DB's collections
db.command({"customAction": "CreateDatabase", "offerThroughput": 400})
print("Created db '{}' with shared throughput.\n".format(DB_NAME))
else:
print("Using database: '{}'.\n".format(DB_NAME))
获取集合
使用 list_collection_names 方法检查集合是否存在。 如果集合不存在,请使用 create collection extension 命令创建它。
# Create collection if it doesn't exist
collection = db[COLLECTION_NAME]
if COLLECTION_NAME not in db.list_collection_names():
# Creates a unsharded collection that uses the DBs shared throughput
db.command(
{"customAction": "CreateCollection", "collection": COLLECTION_NAME}
)
print("Created collection '{}'.\n".format(COLLECTION_NAME))
else:
print("Using collection: '{}'.\n".format(COLLECTION_NAME))
创建索引
使用 update collection extension 命令创建索引。 还可以在 create collection extension 命令中设置索引。 在此示例中将索引设置为 name 属性,以便稍后可以对产品名称使用游标类 sort 方法进行排序。
indexes = [
{"key": {"_id": 1}, "name": "_id_1"},
{"key": {"name": 2}, "name": "_id_2"},
]
db.command(
{
"customAction": "UpdateCollection",
"collection": COLLECTION_NAME,
"indexes": indexes,
}
)
print("Indexes are: {}\n".format(sorted(collection.index_information())))
创建文档
使用 adventureworks 数据库的 product 属性创建文档:
- category 属性。 此属性可用作逻辑分区键。
- name 属性。
- 库存 quantity 属性。
- sale 属性,指示产品是否在售。
"""Create new document and upsert (create or replace) to collection"""
product = {
"category": "gear-surf-surfboards",
"name": "Yamba Surfboard-{}".format(randint(50, 5000)),
"quantity": 1,
"sale": False,
}
result = collection.update_one(
{"name": product["name"]}, {"$set": product}, upsert=True
)
print("Upserted document with _id {}\n".format(result.upserted_id))
通过调用集合级操作 update_one 在集合中创建文档。 在此示例中,你将更新插入而不是创建新文档。 在此示例中不需要更新插入文档,因为产品名称是随机的。 但是,如果你要多次运行代码并且产品名称相同,则最好是更新插入文档。
update_one 操作的结果包含可在后续操作中使用的 _id 字段值。 _id 属性是自动创建的。
获取文档
使用 find_one 方法获取文档。
doc = collection.find_one({"_id": result.upserted_id})
print("Found a document with _id {}: {}\n".format(result.upserted_id, doc))
在 Azure Cosmos DB 中,可同时使用唯一标识符 (_id) 和分区键来执行低开销的点读取操作。
查询文档
插入文档后,可通过运行查询来获取与特定筛选器匹配的所有文档。 此示例查找与特定类别匹配的所有文档:gear-surf-surfboards。 定义查询后,调用 Collection.find 以获取 Cursor 结果,然后使用 sort。
"""Query for documents in the collection"""
print("Products with category 'gear-surf-surfboards':\n")
allProductsQuery = {"category": "gear-surf-surfboards"}
for doc in collection.find(allProductsQuery).sort(
"name", pymongo.ASCENDING
):
print("Found a product with _id {}: {}\n".format(doc["_id"], doc))
疑难解答:
- 如果收到错误(例如
The index path corresponding to the specified order-by item is excluded.),请确保已创建索引。
运行代码
此应用创建 API for MongoDB 数据库和集合,并创建一个文档,然后读回完全相同的文档。 最后,该示例发出一个查询,用于返回与指定的产品类别匹配的文档。 对于每个步骤,该示例都会向控制台输出有关其已执行的步骤的信息。
若要运行应用,请使用终端导航到应用程序目录并运行该应用程序。
python run.py
应用的输出应类似于此示例:
Created db 'adventureworks' with shared throughput.
Created collection 'products'.
Indexes are: ['_id_', 'name_1']
Upserted document with _id <ID>
Found a document with _id <ID>:
{'_id': <ID>,
'category': 'gear-surf-surfboards',
'name': 'Yamba Surfboard-50',
'quantity': 1,
'sale': False}
Products with category 'gear-surf-surfboards':
Found a product with _id <ID>:
{'_id': ObjectId('<ID>'),
'name': 'Yamba Surfboard-386',
'category': 'gear-surf-surfboards',
'quantity': 1,
'sale': False}
清理资源
当不再需要 Azure Cosmos DB for NoSQL 帐户时,可以删除相应的资源组。
使用 az group delete 命令删除资源组。
az group delete --name $resourceGroupName