连接到 TIBCO Spotfire Analyst
本文介绍如何在 Azure Databricks 群集或 Azure Databricks SQL 仓库上使用 TIBCO Spotfire Analyst。
要求
Azure Databricks 工作区中的群集或 SQL 仓库。
群集或 SQL 仓库的连接详细信息,特别是“服务器主机名”、“端口”和“HTTP 路径”值。
Azure Databricks 个人访问令牌或 Microsoft Entra ID(以前称为 Azure Active Directory)令牌…… 若要创建个人访问令牌,请执行以下操作:
- 在 Azure Databricks 工作区中,单击顶部栏中 Azure Databricks 用户名,然后从下拉列表中选择“用户设置”。
- 单击“开发人员”。
- 在“访问令牌”旁边,单击“管理”。
- 单击“生成新令牌”。
- (可选)输入有助于将来识别此令牌的注释,并将令牌的默认生存期更改为 90 天。 若要创建没有生存期的令牌(不建议),请将“生存期(天)”框留空(保留空白)。
- 单击“生成” 。
- 将显示的令牌复制到安全位置,然后单击“完成”。
注意
请务必将复制的令牌保存到安全的位置。 请勿与他人共享复制的令牌。 如果丢失了复制的令牌,你将无法重新生成完全相同的令牌, 而必须重复此过程来创建新令牌。 如果丢失了复制的令牌,或者认为令牌已泄露,Databricks 强烈建议通过单击“访问令牌”页上令牌旁边的垃圾桶(撤销)图标立即从工作区中删除该令牌。
如果你无法在工作区中创建或使用令牌,可能是因为工作区管理员已禁用令牌或未授予你创建或使用令牌的权限。 请与工作区管理员联系,或参阅以下内容:
连接步骤
- 在 TIBCO Spotfire Analyst 中的导航栏上,单击加号(“文件和数据”)图标,然后单击“连接到” 。
- 选择“Databricks”并单击“新建连接” 。
- 在“Apache Spark SQL”对话框中的“常规”选项卡上,对于“服务器”,请输入在步骤 1 中获取的“服务器主机名”和“端口”字段值并以冒号分隔 。
- 对于“身份验证方法”,请选择“用户名和密码” 。
- 对于“用户名”,请输入单词
token。 - 对于“密码”,请输入在步骤 1 中获取的个人访问令牌。
- 在“高级”选项卡上,对于“Thrift 传输模式”,请选择“HTTP” 。
- 对于“HTTP 路径”,请输入在步骤 1 中获取的“HTTP 路径”字段值 。
- 在“常规”选项卡上,单击“连接” 。
- 成功连接后,在“数据库”列表中选择要使用的数据库,然后单击“确定” 。
选择要分析的 Azure Databricks 数据
在“连接中的视图”对话框中选择数据。
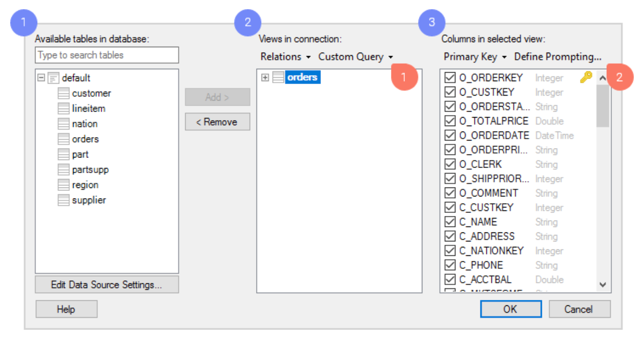
- 浏览 Azure Databricks 中可用的表。
- 将所需的表添加为视图,这些视图将是在 TIBCO Spotfire 中分析的数据表。
- 对于每个视图,可以决定要包含哪些列。 如果要创建非常具体且灵活的数据选择,则可以访问此对话框中的一系列强大工具,例如:
- 自定义查询。 使用自定义查询,可以通过键入自定义 SQL 查询来选择要分析的数据。
- 提示。 将数据选择留给分析文件的用户。 基于选择的列配置提示。 然后,打开分析的最终用户可以选择限制和查看仅相关值的数据。 例如,用户可以选择特定时间范围内或特定地理区域内的数据。
- 单击“确定”。
将查询下推到 Azure Databricks 或导入数据
选择要分析的数据后,最后一步是选择要如何从 Azure Databricks 检索数据。 将显示要添加到分析中的数据表的摘要,可以单击每个表以更改数据加载方法。
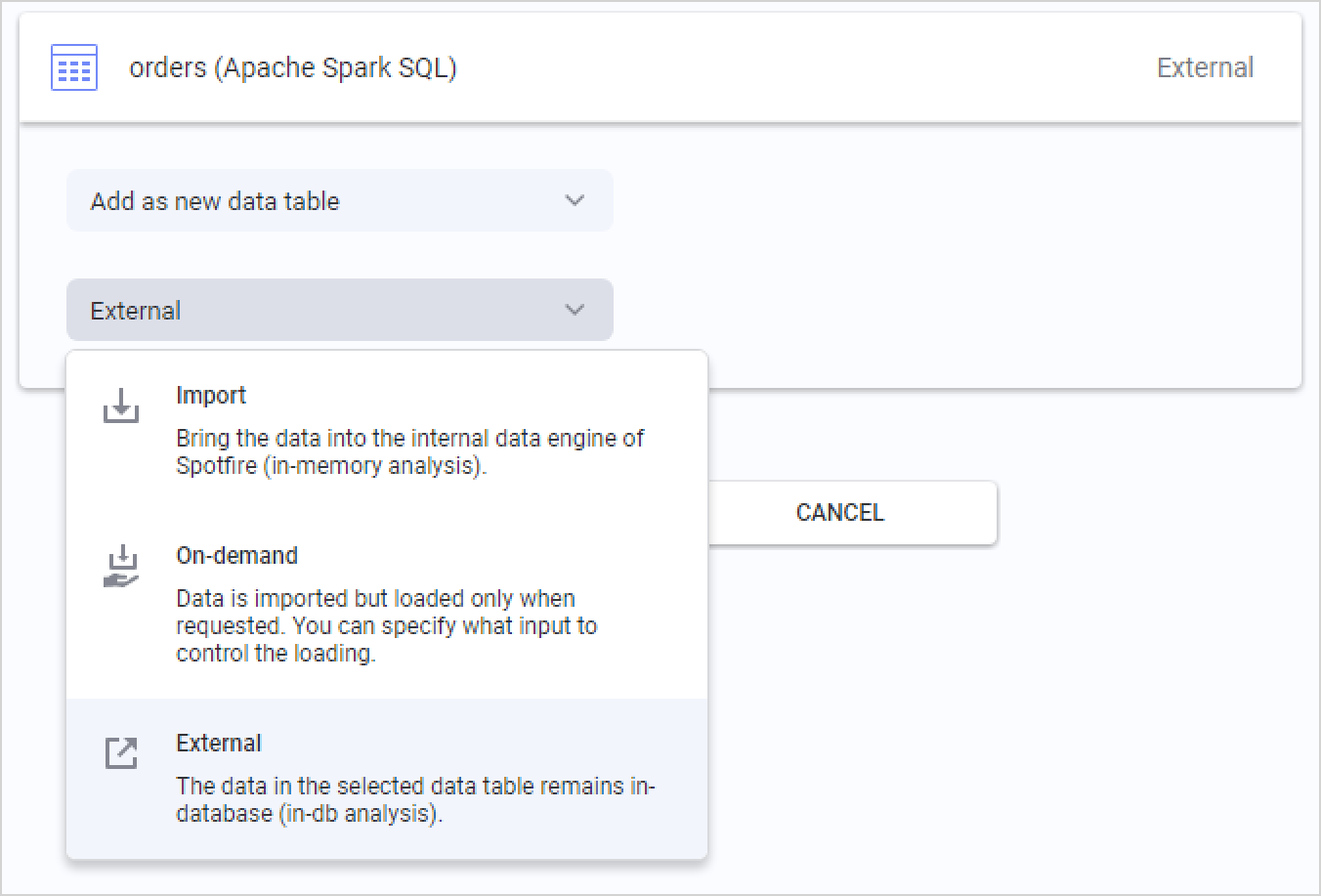
Azure Databricks 的默认选项是“外部”。 这意味着数据表将保留在 Azure Databricks 中的数据库中,并且 TIBCO Spotfire 将基于你在分析中的操作将不同的查询推送到数据库,以获取相关的数据切片。
还可以选择“导入”,TIBCO Spotfire 将预先提取整个数据表,从而可以进行本地内存中分析。 导入数据表时,还可以在 TIBCO Spotfire 的嵌入式内存中数据引擎中使用分析功能。
第三个选项是“按需”(对应于动态 WHERE 子句),这意味着将基于分析中的用户操作提取数据切片。 可以定义条件,这些条件可以是诸如标记或筛选数据或更改文档属性之类的操作。 按需数据加载也可以与“外部”数据表结合使用。