教程 1:预测信用风险 - 机器学习工作室(经典版)
适用于: 机器学习工作室(经典)
机器学习工作室(经典) Azure 机器学习
Azure 机器学习
重要
对机器学习工作室(经典)的支持将于 2024 年 8 月 31 日结束。 建议在该日期之前转换到 Azure 机器学习。
从 2021 年 12 月 1 日开始,你将无法创建新的机器学习工作室(经典)资源。 在 2024 年 8 月 31 日之前,可继续使用现有的机器学习工作室(经典)资源。
ML 工作室(经典)文档即将停用,将来可能不会更新。
在本教程中,我们将深入探讨开发预测分析解决方案的过程。 我们将在机器学习工作室(经典版)中开发一个简单模型。 然后将该模型部署为机器学习 Web 服务。 部署的模型将使用新数据进行预测。 本教程是由三个部分构成的系列教程的第一部分。
假设用户需要根据他们提供的贷款申请相关信息预测个人的信用风险。
信用风险评估是个较为复杂的问题,但本教程会将其适当简化。 你将使用它作为示例,展示如何使用机器学习工作室(经典)来创建预测分析解决方案。 在该解决方案中,将使用机器学习工作室(经典)和机器学习 Web 服务。
在这篇由三个部分构成的教程中,我们将从公开的信用风险数据着手。 然后开发并训练预测模型。 最后将该模型部署为 Web 服务。
本教程部分介绍以下操作:
- 创建机器学习工作室(经典版)工作区
- 上传现有数据
- 创建试验
然后,可以使用此试验训练第 2 部分中的模型,并在第 3 部分部署这些模型。
先决条件
本教程默认用户此前至少使用过机器学习工作室(经典版)一次,且对机器学习概念有一些了解。 但不假设用户精通其中任一领域。
如果以前从来没用过机器学习工作室(经典版),则可能一开始需要学习在机器学习工作室(经典版)中创建第一个数据科学试验快速入门。 该快速入门指导用户首次完成机器学习工作室(经典版)的使用。 教程中会介绍各种基础知识:如何将模块拖放到试验中、如何将模块连接到一起、如何运行试验,以及如何查看结果。
提示
可在 Azure AI 库中找到本教程中开发的试验的工作副本。 请前往 Tutorial - Predict credit risk(教程 - 预测信用风险)并单击“在工作室中打开”将试验副本下载到机器学习工作室(经典)的工作区 。
创建机器学习工作室(经典版)工作区
若要使用机器学习工作室(经典版),你必须拥有一个机器学习工作室(经典)工作区。 此工作区包含创建、管理和发布试验所需的工具。
要创建工作区,请参阅创建和共享机器学习工作室(经典版)工作区。
创建工作区后,打开机器学习工作室(经典版)(https://studio.azureml.net/Home)。 如果有多个工作区,可在窗口右上角的工具栏中选择工作区。

提示
如果你是工作区的所有者,则可通过邀请其他人到工作区来共享所进行的试验。 可以在“设置”页面上的“机器学习工作室(经典版)”中执行此操作。 只需每位用户的 Microsoft 帐户或组织帐户即可。
在“设置”页上,单击“用户”,并在窗口底部单击“邀请更多用户”。
上传现有数据
若要开发用于信用风险的预测模型,我们需要用于训练和测试模型的数据。 对于本教程,我们将使用 UC Irvine 机器学习存储库的“UCI Statlog(德国信用数据)数据集”。 可在此处找到以下内容:
https://archive.ics.uci.edu/ml/datasets/Statlog+(German+Credit+Data)
使用名为 german.data 的文件。 将此文件下载到本地硬盘驱动器。
german.data 数据集包含 1000 个以前的信贷申请人的 20 个变量行。 这 20 个变量代表数据集的特征集(特征向量),此特征集提供每个信贷申请人的标识特征。 每行增加一列表示申请人经计算的信贷风险,其中700 个申请人标识为低信贷风险,300 个申请人标识为高信贷风险。
UCI 网站提供此数据的功能向量的属性说明。 此数据包括财务信息、信用历史记录、就业状态和个人信息。 每个申请人都将提供二进制分级,指示他们的信贷风险是高还是低。
我们将使用此数据训练一个预测分析模型。 操作完成后,模型应能够接受新个体的特征向量,并预测其信用风险是低还是高。
下面是一个有趣的转折。
UCI 网站上的数据集说明提及了如果我们对人员的信用风险进行错误的分类所要付出的代价。 如果模型预测某个人员具有高信用风险,而实际上该人员具有低信用风险,则该模型进行了错误分类。
但对金融机构而言,反向错误分类会付出五倍的代价:如果模型预测某个人员具有低信贷风险,而实际上该人员具有高信贷风险。
因此,我们想要训练模型,使后一种类型的错误分类代价高于其他方式的错误分类五倍。
在试验中训练模型时实现此目的的一个简单方法是复制(5 次)表示高信用风险用户的条目。
然后,如果模型将实际上具有高风险的某人错误分类为低信用风险,则模型会执行该相同的错误分类五次(每个重复项一次)。 这会增加此错误在训练结果中的成本。
转换数据集格式
原始数据集使用空格分隔的格式。 机器学习工作室(经典版)使用逗号分隔值 (CSV) 文件效果更好,所以我们通过将空格替换为逗号来转换数据集。
转换此数据的方法有很多。 一种方法是使用以下 Windows PowerShell 命令:
cat german.data | %{$_ -replace " ",","} | sc german.csv
另一种方法是使用 Unix sed 命令:
sed 's/ /,/g' german.data > german.csv
在任一情况下,我们已在可在试验中使用的名为 german.csv 的文件中创建了逗号分隔版的数据。
将数据集上传到机器学习工作室(经典版)
数据转换为 CSV 格式后,需要将其上传到机器学习工作室(经典版)。
打开机器学习工作室(经典版)主页 (https://studio.azureml.net)。
单击窗口左上角的菜单
 ,单击“Azure 机器学习”,选择“工作室”,然后登录。
,单击“Azure 机器学习”,选择“工作室”,然后登录。单击窗口底部的“+ 新建”。
选择“数据集”。
选择“从本地文件”。

在“上传新数据集”对话框中单击“浏览”,找到创建的 german.csv 文件。
输入数据集名称。 在本教程中,此数据集名为“UCI 德国信用卡数据”。
对于数据类型,请选择“没有标题的一般 CSV 文件(.nh.csv)”。
添加说明(如果需要)。
单击确定复选标记。
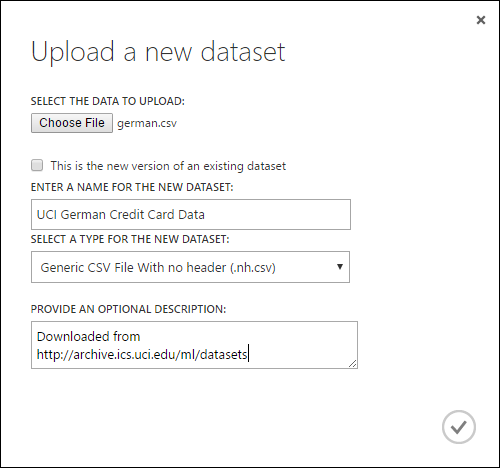
这会数据上传到可在试验中使用的数据集模块。
可以通过单击工作室(经典版)窗口左侧的“数据集”选项卡,来管理已上传到工作室(经典版)的数据集。

有关将其他数据导入试验类型的详细信息,请参阅将训练数据导入机器学习工作室(经典版)。
创建试验
本教程的下一步是在机器学习工作室(经典版)中创建一个使用我们上传的数据集的试验。
在工作室(经典版)中,单击窗口底部的“+新建”。
选择“实验”,并选择“空白实验”。
选择画布顶部的默认实验名称,然后将它重命名为有意义的名称。

提示
在“属性”窗格中填写实验的“摘要”和“说明”会是一个很好的做法。 这些属性提供了记录实验的机会,以便任何看到它的人都能理解目标和方法。

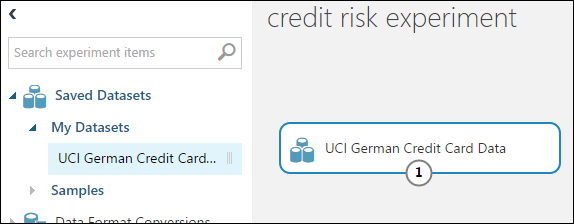
在实验画布左侧的模块控制板中,展开“已保存的数据集”。
找到在“我的数据集”下创建的数据集,并将其拖动到画布上。 此外还可以通过在控制板上方的“搜索”框中输入名称来查找数据集。
准备数据
可以通过以下方法查看整个数据集的前 100 行数据和一些统计信息:单击数据集的输出端口(底部的小圆圈)并选择“可视化”。
因为数据文件没有列标题,所以工作室(经典版)提供了通用标题(Col1、Col2 等)。 好标题不是创建模型的关键,但它们使实验中的数据处理变得更加容易。 此外,当我们最终在 Web 服务中发布此模型时,标题将有助于识别服务用户的列。
可以使用编辑元数据模块来添加列标题。
可以使用编辑元数据模块来更改与数据集关联的元数据。 在本例中,我们使用它来为列标题提供更友好的名称。
要使用编辑元数据,请首先指定要修改的列(在本例中为所有列)。接下来,指定要对这些列执行的操作(在此情况下为更改列标题)。
在模块控制板的“搜索”框中键入“元数据”。 编辑元数据显示在模块列表中。
单击并将编辑元数据模块拖到画布上,并将其放到之前添加的数据集的下方。
将数据集连接到编辑元数据:单击数据集的输出端口(数据集底部的小圆圈),将其拖动到编辑元数据的输入端口(模块顶部的小圆圈),然后释放鼠标按键。 即便是在画布上来回移动,数据集和模块仍保持连接。
实验现在看起来应当与下图类似:

红色感叹号表示尚未设置此模块的属性。 我们会在下一步完成该操作。
提示
可以双击模块并输入文本,为模块添加注释。 这有助于快速查看模块在实验中的运行情况。 在本例中,请双击编辑元数据模块,并输入注释“添加列标题”。 单击画布上的任意位置以关闭文本框。 若要显示注释,请单击模块上的向下箭头。
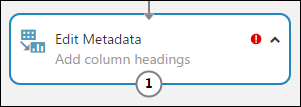
选择编辑元数据,并在画布右侧的“属性”窗格中,单击“启动列选择器” 。
在“选择列”对话框中,选择“可用列”中的所有行,并单击 > 以将其移动到“选定列”。 此对话框应如下所示:
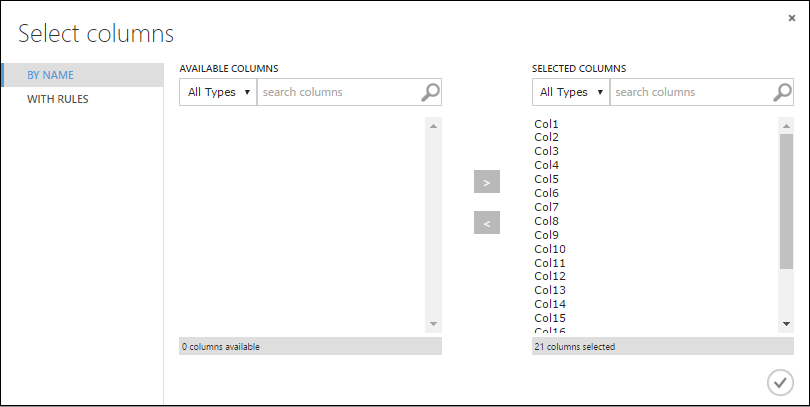
单击确定复选标记。
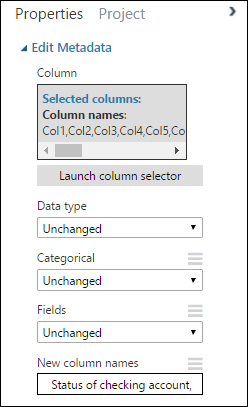
回到“属性”窗格中,查找“新列名称”参数。 在此字段中,输入数据集中 21 列的名称列表,以逗号分隔并按列排序。 可以从 UCI 网站上的数据集文档中获取列名称,或为了方便起见,也可以复制并粘贴以下列表:
Status of checking account, Duration in months, Credit history, Purpose, Credit amount, Savings account/bond, Present employment since, Installment rate in percentage of disposable income, Personal status and sex, Other debtors, Present residence since, Property, Age in years, Other installment plans, Housing, Number of existing credits, Job, Number of people providing maintenance for, Telephone, Foreign worker, Credit risk“属性”窗格将如下所示:
创建训练和测试数据集
需要一些用于训练模型的数据和一些用于测试模型的数据。 因此,在试验的下一步中,我们将数据集拆分为两个单独的数据集:一个用于训练模型,一个用于测试模型。
为此,请使用拆分数据模块。
默认情况下,拆分比为 0.5,并且设置了“随机拆分”参数。 这意味着,随机的一半数据通过拆分数据模块的一个端口输出,另一半通过另一个端口输出。 可以调整这些参数,以及“随机种子”参数,以更改训练和测试数据之间的拆分。 在本例中,我们将其保持不变。
提示
第一个输出数据集中行的分数属性决定了通过左输出端口输出的数据量。 例如,如果将比率设置为 0.7,则 70% 的数据将通过左端口输出,30% 通过右端口输出。
双击拆分数据模块,并输入注释“训练/测试数据拆分 50%”。
可以使用拆分数据模块的输出,但我们选择使用左输出作为训练数据,右输出作为测试数据。
如上一步骤中所述,将高信贷风险错误分类为低的成本比将低信用风险错误分类为高的成本高五倍。 考虑到这一点,我们生成一个新的数据集来反映这个成本函数。 在新数据集中,每个高风险示例会复制五次,而每个低风险示例则不复制。
可以使用 R 代码进行此复制:
找到执行 R 脚本模块并将其拖到试验画布上。
双击执行 R 脚本模块,并输入注释“设置成本调整”。
在“属性”窗格中,删除 R 脚本参数中的默认文本,并输入以下脚本:
dataset1 <- maml.mapInputPort(1) data.set<-dataset1[dataset1[,21]==1,] pos<-dataset1[dataset1[,21]==2,] for (i in 1:5) data.set<-rbind(data.set,pos) maml.mapOutputPort("data.set")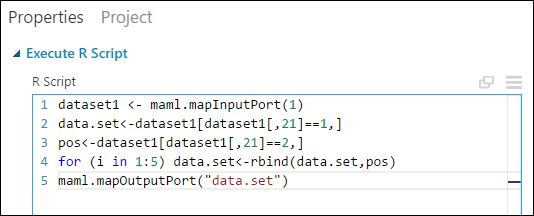
需要对 拆分数据模块的每个输出执行相同的复制操作,以便训练和测试数据具有相同的成本调整。 执行此操作的最简单方法是:复制刚才生成的执行 R 脚本模块,将其连接到拆分数据模块的另一个输出端口。
右键单击执行 R 脚本模块,并选择“复制”。
右键单击实验画布,并选择“粘贴”。
在画布底部,单击“运行”。
提示
执行 R 脚本模块的副本包含与原始模块相同的脚本。 在画布上复制和粘贴模块时,副本将保留原始文件的所有属性。
我们的实验现在如下所示:
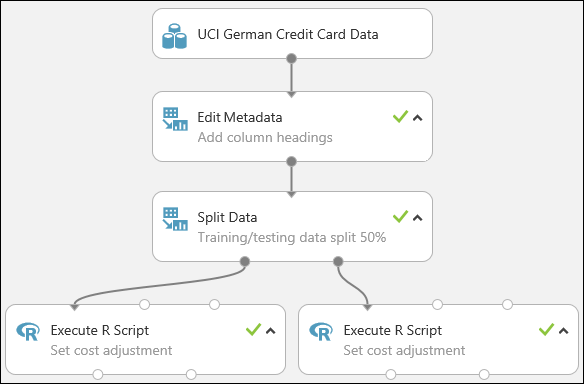
有关在实验中使用 R 脚本的详细信息,请参阅使用 R 扩展实验。
清理资源
如果不再需要通过本文创建的资源,请删除它们,以免产生费用。 在导出和删除产品内用户数据一文中了解具体信息。
后续步骤
在本教程中,我们已完成以下步骤:
- 创建机器学习工作室(经典版)工作区
- 将现有数据上传到工作区
- 创建试验
现在,可以开始训练和评估此数据的模型。