你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
使用网络观察程序和 Grafana 管理和分析网络安全组流日志
注意
本文引用了 CentOS,这是一个接近生命周期结束 (EOL) 状态的 Linux 发行版。 请相应地考虑你的使用和规划。 有关详细信息,请参阅 CentOS 生命周期结束指导。
可以通过网络安全组 (NSG) 流日志提供的信息了解网络接口上的入口和出口 IP 流量。 这些流日志针对每个 NSG 规则显示出站和入站流、流所适用的 NIC、有关流的 5 -元组信息(源/目标 IP、源/目标端口、协议),以及是允许还是拒绝流量。
网络中可能有许多启用了流日志记录的 NSG。 这么大量的日志记录数据导致难以对日志进行分析以及从中获得见解。 本文提供了一个解决方案来使用 Grafana(一个开源绘图工具)、ElasticSearch(一个分布式搜索和分析引擎)和 Logstash(一个开源服务器端数据处理管道)来集中管理这些 NSG 流日志。
方案
NSG 流日志是使用网络观察程序启用的,并且存储在 Azure Blob 存储中。 Logstash 插件用于连接和处理 Blob 存储中的流日志并将其发送到 ElasticSearch。 将流日志存储到 ElasticSearch 中之后,可在 Grafana 中对其进行分析,并在自定义的仪表板中将其可视化。
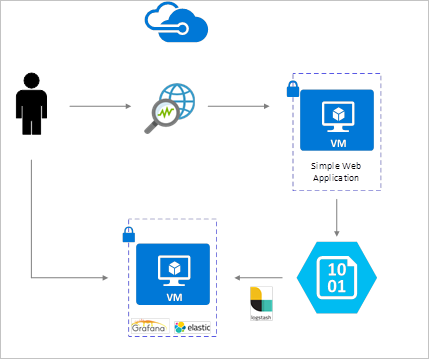
安装步骤
启用网络安全组流日志记录
就本方案来说,必须在帐户的至少一个网络安全组上启用网络安全组流日志记录。 有关启用网络安全组流日志的说明,请参阅以下文章:网络安全组流日志记录简介。
安装注意事项
在此示例中,Azure 中部署的 Ubuntu LTS 服务器上配置了 Grafana、ElasticSearch 和 Logstash。 此最小安装用于运行所有三个组件 - 均在同一 VM 上运行。 此安装应当仅用于测试和非关键工作负荷。 Logstash、Elasticsearch 和 Grafana 都可以构建为跨多个实例独立缩放。 有关详细信息,请参阅这些组件中每一个的文档。
安装 Logstash
可以使用 Logstash 将 JSON 格式的流日志平展到流元组级别。
以下说明用于在 Ubuntu 中安装 Logstash。 有关如何在 RHEL/CentOS 中安装此包的说明,请参阅《从包存储库安装 - yum》一文。
若要安装 Logstash,请运行以下命令:
curl -L -O https://artifacts.elastic.co/downloads/logstash/logstash-5.2.0.deb sudo dpkg -i logstash-5.2.0.deb配置 Logstash,以分析流日志并将其发送到 ElasticSearch。 使用以下命令创建 Logstash.conf 文件:
sudo touch /etc/logstash/conf.d/logstash.conf将以下内容添加到该文件。 更改存储帐户名称和访问密钥来反映你的存储帐户详细信息:
input { azureblob { storage_account_name => "mystorageaccount" storage_access_key => "VGhpcyBpcyBhIGZha2Uga2V5Lg==" container => "insights-logs-networksecuritygroupflowevent" codec => "json" # Refer https://learn.microsoft.com/azure/network-watcher/network-watcher-read-nsg-flow-logs # Typical numbers could be 21/9 or 12/2 depends on the nsg log file types file_head_bytes => 12 file_tail_bytes => 2 # Enable / tweak these settings when event is too big for codec to handle. # break_json_down_policy => "with_head_tail" # break_json_batch_count => 2 } } filter { split { field => "[records]" } split { field => "[records][properties][flows]"} split { field => "[records][properties][flows][flows]"} split { field => "[records][properties][flows][flows][flowTuples]"} mutate { split => { "[records][resourceId]" => "/"} add_field => { "Subscription" => "%{[records][resourceId][2]}" "ResourceGroup" => "%{[records][resourceId][4]}" "NetworkSecurityGroup" => "%{[records][resourceId][8]}" } convert => {"Subscription" => "string"} convert => {"ResourceGroup" => "string"} convert => {"NetworkSecurityGroup" => "string"} split => { "[records][properties][flows][flows][flowTuples]" => "," } add_field => { "unixtimestamp" => "%{[records][properties][flows][flows][flowTuples][0]}" "srcIp" => "%{[records][properties][flows][flows][flowTuples][1]}" "destIp" => "%{[records][properties][flows][flows][flowTuples][2]}" "srcPort" => "%{[records][properties][flows][flows][flowTuples][3]}" "destPort" => "%{[records][properties][flows][flows][flowTuples][4]}" "protocol" => "%{[records][properties][flows][flows][flowTuples][5]}" "trafficflow" => "%{[records][properties][flows][flows][flowTuples][6]}" "traffic" => "%{[records][properties][flows][flows][flowTuples][7]}" "flowstate" => "%{[records][properties][flows][flows][flowTuples][8]}" "packetsSourceToDest" => "%{[records][properties][flows][flows][flowTuples][9]}" "bytesSentSourceToDest" => "%{[records][properties][flows][flows][flowTuples][10]}" "packetsDestToSource" => "%{[records][properties][flows][flows][flowTuples][11]}" "bytesSentDestToSource" => "%{[records][properties][flows][flows][flowTuples][12]}" } add_field => { "time" => "%{[records][time]}" "systemId" => "%{[records][systemId]}" "category" => "%{[records][category]}" "resourceId" => "%{[records][resourceId]}" "operationName" => "%{[records][operationName]}" "Version" => "%{[records][properties][Version]}" "rule" => "%{[records][properties][flows][rule]}" "mac" => "%{[records][properties][flows][flows][mac]}" } convert => {"unixtimestamp" => "integer"} convert => {"srcPort" => "integer"} convert => {"destPort" => "integer"} add_field => { "message" => "%{Message}" } } date { match => ["unixtimestamp" , "UNIX"] } } output { stdout { codec => rubydebug } elasticsearch { hosts => "localhost" index => "nsg-flow-logs" } }
提供的 Logstash 配置文件由三个部分组成:input、filter 和 output。 input 部分指定 Logstash 要处理的日志的输入源 – 在本例中,我们将使用“azureblob”输入插件(在后续步骤中安装),以便可以访问 Blob 存储中存储的 NSG 流日志 JSON 文件。
然后,filter 部分将平展每个流日志文件,以便使每个单独的流元组及其关联属性成为单独的 Logstash 事件。
最后,output 部分将每个 Logstash 事件转发到 ElasticSearch 服务器。 可以随意修改 Logstash 配置文件来适应具体需求。
安装适用于 Azure Blob 存储的 Logstash 输入插件
使用该 Logstash 插件可以直接从指定的 Blob 存储帐户访问流日志。 若要安装此插件,请从默认 Logstash 安装目录(在此示例中为 /usr/share/logstash/bin)运行以下命令:
sudo /usr/share/logstash/bin/logstash-plugin install logstash-input-azureblob
有关此插件的详细信息,请参阅 Logstash input plugin for Azure Storage Blobs(适用于 Azure 存储 Blob 的 Logstash 输入插件)。
安装 ElasticSearch
可以使用以下脚本安装 ElasticSearch。 有关安装 ElasticSearch 的信息,请参阅 Elastic Stack(弹性堆栈)。
sudo apt-get install apt-transport-https openjdk-8-jre-headless uuid-runtime pwgen -y
wget -qO - https://packages.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
echo "deb https://packages.elastic.co/elasticsearch/5.x/debian stable main" | sudo tee -a /etc/apt/sources.list.d/elasticsearch-5.x.list
sudo apt-get update && apt-get install elasticsearch
sudo sed -i s/#cluster.name:.*/cluster.name:\ grafana/ /etc/elasticsearch/elasticsearch.yml
sudo systemctl daemon-reload
sudo systemctl enable elasticsearch.service
sudo systemctl start elasticsearch.service
安装 Grafana
若要安装并运行 Grafana,请运行以下命令:
wget https://s3-us-west-2.amazonaws.com/grafana-releases/release/grafana_4.5.1_amd64.deb
sudo apt-get install -y adduser libfontconfig
sudo dpkg -i grafana_4.5.1_amd64.deb
sudo service grafana-server start
有关更多的安装信息,请参阅 Installing on Debian / Ubuntu(在 Debian / Ubuntu 上进行安装)。
将 ElasticSearch 服务器添加为数据源
接下来,需要将包含流日志的 ElasticSearch 索引添加为数据源。 可以通过选择“添加数据源”并使用相关信息完成表单来添加数据源。 可以在下面的屏幕截图中找到此配置的示例:

创建仪表板
现在,你已成功配置了 Grafana 来从包含 NSG 流日志的 ElasticSearch 索引读取数据,可以创建并个性化仪表板了。 若要创建新仪表板,请选择“创建第一个仪表板”。 以下示例图形配置显示了按 NSG 规则分段的流:
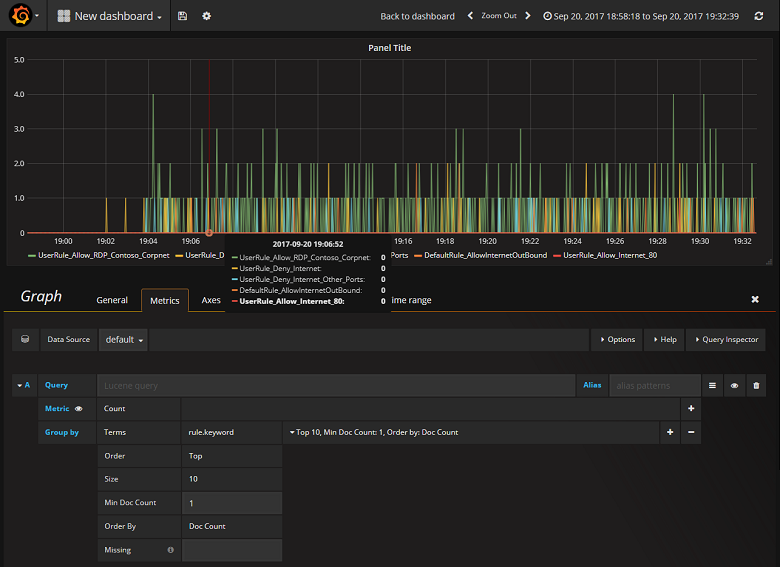
以下屏幕截图描绘了一个图形和图表,其中显示了出现最多的流及其频率。 流还可以按 NSG 规则以及按决策显示。 Grafana 是可以高度自定义的,因此,建议创建仪表板来适应你的特定监视需求。 下面的示例显示了一个典型的仪表板:
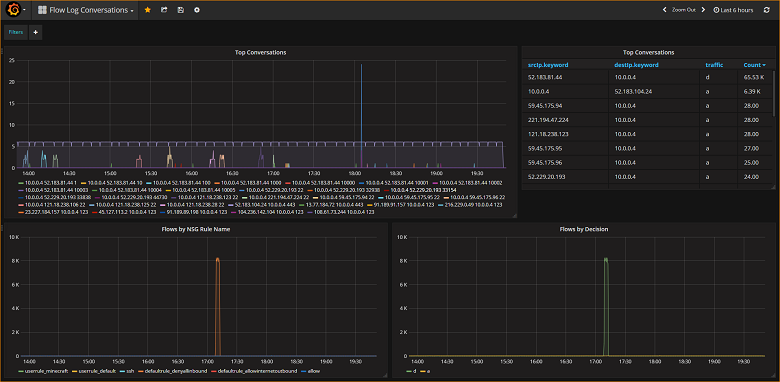
结论
通过将网络观察程序与 ElasticSearch 和 Grafana 集成,现在能够以方便、集中的方式管理和可视化 NSG 流日志和其他数据。 Grafana 提供了许多其他强大的绘图功能,使用这些功能还可以进一步管理流日志,以及更好地了解网络流量。 现在,你已设置了 Grafana 实例并将其连接到了 Azure,可以继续尽情了解它所提供的其他功能了。
后续步骤
- 了解有关使用网络观察程序的详细信息。