托管可用性
确保用户获得良好的电子邮件体验一直是邮件系统管理员的主要目标。 在Exchange Server组织中,必须积极监视系统的各个方面,并且必须快速解决检测到的任何问题。 为实现这一目标,名为托管可用性的功能提供内置的监视和恢复操作,可保留最终用户体验。
托管可用性
托管可用性(也称为 “活动监视”或 “本地主动监视”)是内置监视和恢复操作与 Exchange 高可用性平台的集成。 它设计用于在问题出现后立即被系统检测到以检测并恢复。 与 Exchange 之前的外部监视解决方案和技术不同的是,托管可用性不会尝试识别或沟通问题的根本原因。 与此相反,它将专注于处理用户体验的三个关键方面的恢复部分:
可用性:用户可以访问该服务吗?
延迟:用户体验如何?
错误:用户能否完成所需的操作?
托管可用性提供本机运行状况监控和恢复解决方案。 它不再监控系统的单个单独切片,而是监控端到端用户体验,并通过以恢复为主的操作保护最终用户的体验。
托管可用性是在每个 Exchange 服务器上运行的内部进程。 它每秒轮询和分析数百个运行状况度量。 如果发现错误,大部分时候会自动修复。 但始终会有一些托管可用性无法自行修复的问题。 在这些情况下,托管可用性将使用事件日志记录将问题上报给管理员。
托管可用性以两种服务形式实现:
Exchange Health Manager 服务 (MSExchangeHMHost.exe) :这是用于管理工作进程的控制器进程。 它用于在必要时构建、执行并启动和结束进程。 它还用于在进程失败的情况下恢复工作进程,以防止工作进程出现单点故障。
Exchange Health Manager 辅助角色进程 (MSExchangeHMWorker.exe) :这是负责在托管可用性框架中执行运行时任务的工作进程。
托管可用性使用永久存储执行其功能:
\bin\Monitoring\config 文件夹中的 XML 文件用于存储某些探测器和监视器工作项目的配置设置。
Active Directory 用于存储全局覆盖。
Windows 注册表用于存储运行时数据,如书签和本地(服务器特定)覆盖。
Windows crimson 通道事件日志基础结构用于存储工作项目结果。
运行状况邮箱用于探测活动。 将在服务器上存在的每个邮箱数据库上创建多个运行状况邮箱。
托管可用性组件
如同下图中所示,托管可用性包括三个持续运行的主要异构组件。
托管可用性组件
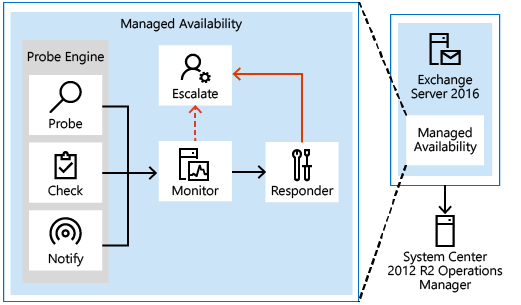
探测器
第一个组件称为探测器。 探测器负责在服务器上进行测量并收集数据。
探测器有三个主要类别:反复探测器、通知探测器和检查探测器。 反复探测器是系统进行的合成事务,以测试端到端用户体验。 检查是执行性能数据收集(包括用户流量)的基础结构。 检查探测器还使用设定的阈值测量收集的数据以确定用户故障的尖峰,这样使检查基础结构能在用户遇到问题时意识到出现问题。 最后,通知逻辑允许系统基于关键事件立即采取行动,而无需等待探测器收集的数据结果。 这些通常是无需大量样本集即可检测和识别的例外或条件。
反复探测器每隔几分钟运行一次,并评估服务运行状况的某些方面。 这些探测器可以通过 Exchange ActiveSync 将电子邮件发送到监视邮箱,它们可能会连接到 RPC 终结点,也可能会验证"客户端访问到邮箱"的连接。
所有探测器都在 Microsoft.Exchange.ActiveMonitoring\ProbeDefinition crimson 通道中的运行状况管理器服务启动上定义。 每个探测定义有许多属性,但最相关的属性是:
名字 探测的名称,以探测监视器的 SampleMask 开头。
TypeName 包含探测器逻辑的探测器的代码对象类型。
ServiceName 包含此探测器的运行状况集的名称。
TargetResource 探测器正在验证的对象。 执行时,它会追加到探测的名称,以成为探测结果 ResultName
RecurrenceIntervalSeconds 探测器的执行频率。
TimeoutSeconds 探测器在失败前将等待的时间。
有几百个反复探测器。 这些探测器中有许多都是以单个数据库为基础,所以随着数据库数量的增加,探测器的数量也随之增长。 大多数探测器都是在代码中定义的,因此不能直接找到。
反复探测器的基础知识如下所示:启动每个 RecurrenceIntervalSeconds,并检查(或探测)某些方面的运行状况。 如果组件运行状况良好,则探测器将判定为合格,并将信息性事件传入或写入 ResultType 为 3 的 Microsoft.Exchange.ActiveMonitoring\ProbeResult 通道。 如果检查失败或者超时,探测器将判定为故障,并将错误事件写入同一通道。 ResultType 为 4 表示检查失败,ResultType 为 1 表示检查超时。如果许多探测超时,将重新运行,达到 MaxRetryAttempts 属性的值。
注意
ProbeResult crimson 通道会因为处理数百个每隔几分钟运行一次的探测器以及记录事件而变得非常繁忙,因此如果你对生产环境中的事件日志尝试高成本的查询时,会对你的 Exchange 服务器性能产生真正的影响。
通知是指不是由运行状况管理器框架运行的,而是由服务器上的一些其他服务运行的探测器。 这些服务自行执行监测,然后通过直接写入探测结果将数据反馈到托管可用性框架中。 在 ProbeDefinition 通道中无法看到这些探测器,因为该通道只描述由托管可用性框架运行的探测器。 例如,ServerOneCopyMonitor 监视器由 MSExchangeDAGMgmt 服务写入的探测结果触发。 该服务执行自己的监视,确定是否有问题,并记录探测结果。 大多数通知探测器必须能够记录导致监视器不正常的红色事件,以及使监视器重新恢复正常的绿色事件。
检查探测器只在性能计数器高于或低于定义的阈值时才会记录事件。 实际上,它们是通知探头的一种特殊情况,因为当达到配置的阈值时,将有服务监视服务器上的性能计数器,并将事件记录到 ProbeResult 通道。
若要找到被视为不正常的计数器和阈值,您可以查看监视器找到此检查探测器。 类型 为 Microsoft.Office.Datacenter.ActiveMonitoring.OverallConsecutiveSampleValueAboveThresholdMonitor 或 Microsoft.Office.Datacenter.ActiveMonitoring.OverallConsecutiveSampleValueBelowThresholdMonitor 类型的监视器意味着他们监视的探测是检查探测
监视器
由探测器收集的测量结果将流入第二个组件,即监视器。 监视器包含系统在收集的数据上使用的所有业务逻辑。 类似于模式识别引擎,监视器将在收集的所有测量上寻找各种不同的模式,然后决定组件是否正常运行。
监视器将查询数据,以基于预定义的规则集来确定是否需要采取措施。 根据规则或问题本质的不同,监视器能够启动响应器或通过事件日志条目将问题上报给用户。 此外,监视器定义在发生故障后执行响应程序的时间,以及恢复操作的工作流。 监视器具有各种状态。 从系统状态角度来说,监视器具有两种状态:
正常:监视器正常运行,所有收集的指标都在正常操作参数内。
不正常:监视器不正常,并且已通过响应方启动了恢复或通过升级通知管理员。
从管理角度来看,监视器具有 Exchange 命令行管理程序中显示的其他状态:
已降级:当监视器在 0 到 60 秒之间处于不正常状态时,它被视为已降级。 如果监视器处于未正常运行状态超过 60 秒,则被视为未正常运行。
已禁用:监视器已被管理员显式禁用。
不可用:Exchange 运行状况服务定期查询每个监视器的状态。 如果查询未得到响应,监视器状态将变为不可用。
正在修复:管理员设置“正在修复”状态,以向系统指示人工正在采取纠正措施,使系统和用户能够区分在采取纠正措施 ((例如数据库复制重设了) )的同时可能发生的其他故障。
每个监视器在其定义中都有一个 SampleMask 属性。 执行监视器时,它会在 ProbeResult 通道中查找具有与监视器的 SampleMask 匹配的 ResultName 的事件。 这些事件可能来自反复探测器、通知探测器或检查探测器。 如果达到了探测器的阈值,则会出现不正常状况。 从监视器的角度看,所有三个探测器类型与它们每个登录到 ProbeResult 通道的类型是一样。
值得注意的是,单个探测失败不一定表示服务器出现问题。 这是监视器的设计,用于正确识别何时存在需要修复的实际问题。 这就是为什么许多监视器在不正常情况出现之前对很多探测器故障设置了阈值的原因。 即使这样,许多问题都可以通过响应程序自动进行修复,所以查找需要人工干预的问题的最好去处是 Microsoft.Exchange.ManagedAvailability\Monitoring crimson 通道。 这将包括最新的探测器错误。
响应器
最后,响应器负责恢复和升级操作。 顾名思义,响应器对由监视器生成的警报执行某种响应。 在某个程序运行不正常时,第一个操作是尝试恢复该组件。 这可能包括多阶段恢复操作;例如,第一次尝试可能是重启应用程序池,第二次尝试可能是重启服务,第三次尝试可能是重启服务器,并且后续尝试可能会使服务器脱机,以使其不再接受流量。 如果恢复操作不成功,则系统会通过事件日志通知将问题上报给用户。
响应者会执行各种恢复操作,例如重置应用程序辅助角色池或重启服务器。 存在多种响应器类型:
重启响应器 终止并重启服务。
重置应用程序池响应器 在 Internet 信息服务 (IIS) 中停止并重启应用程序池。
故障转移响应器 启动数据库或服务器故障转移。
缺陷检查响应器 启动服务器缺陷检查,从而导致服务器重新启动。
脱机响应器 使服务器上的协议停止运行(拒绝客户端请求)。
联机响应器 使服务器上的某个协议重新运行(接受客户端请求)。
上报响应器 通过事件日志记录将问题上报给管理员。
除了上面列出的响应器,某些组件也有自己独特的专用响应器。
所有响应者都包含限制行为,该行为提供用于控制响应方操作的内置排序机制。 限制行为设计为确保系统不会由于响应器恢复操作而受损害或变得更糟。 所有响应器均会以某种方式进行限制。 限制发生时,可能会跳过或延迟响应器恢复操作,这取决于响应器操作。 例如,当限制缺陷检查响应器时,其操作将被跳过,而不是延迟。
运行状况设置
从报告的角度来看,托管可用性具有两个运行状况视图,一个内部视图和一个外部视图。
内部视图使用运行状况设置。 Exchange Server (中的每个组件(例如,Outlook 网页版、Exchange ActiveSync、信息存储服务、内容索引、传输服务等)) 使用探测、监视器和响应程序通过托管可用性进行监视。 给定组件的一组探测、监视器和响应程序称为 运行状况集。 运行状况设置是一组探测器、监视器和响应器,用于确定该组件是否正常运行。 例如,运行状况集的当前状态 (,它是正常还是不正常) 通过使用运行状况集的监视器的状态来确定。 如果运行状况设置的所有监视器均正常运行,则说明运行状况设置处于正常状态。 如果任何监视器不处于正常状态,则运行状况设置状态由最差的监视器决定。
有关查看服务器运行状况或运行状况设置状态的详细步骤,请参阅Manage health sets and server health。
运行状况组
托管可用性的外部视图由运行状况组组成。 运行状况组向 System Center Operations Manager 2012 R2 公开。
有四个主要的运行状况组:
客户触点 影响实时用户交互的组件,如协议或信息存储。
服务组件 没有直接的实时用户交互的组件,例如 Microsoft Exchange 邮箱复制服务或脱机通讯簿生成过程 (OABGen)。
服务器组件 服务器的物理资源,例如磁盘空间、内存和网络。
依赖项可用性 服务器能够访问必要的依赖项,例如 Active Directory、DNS 等。
安装 Exchange 管理包后,System Center Operations Manager (SCOM) 充当运行状况门户,用于查看与 Exchange 环境相关的信息。 SCOM 主控板包含 Exchange 服务器运行状况的以下三个视图:
活动警报 上报响应器将事件写入 Windows 事件日志中,由 SCOM 内的监视器使用。 这些事件在"活动警报"视图中显示为警报。
组织运行状况 此视图中显示了 Exchange 组织运行状况的总体运行状况汇总摘要。 这些汇总包括显示单个数据库可用性组的运行状况以及特定 Active Directory 站点内的运行状况。
服务器运行状况 相关的运行状况设置组合到运行状况组并汇总在此视图中。
覆盖
覆盖使管理员能够配置托管可用性探测器、监视器和响应器的某些方面。 覆盖可用于微调托管可用性使用的一些阈值。 覆盖可用于对意外事件启用紧急操作,这可能需要不同于现成默认设置的配置设置。
可以创建覆盖并将其应用于单个服务器(称为服务器覆盖),也可将其应用于一组服务器(称为全局覆盖)。 服务器覆盖配置数据存储在覆盖应用的服务器上的 Windows 注册表中。 全局覆盖配置数据存储在 Active Directory 中。
覆盖可以配置为无限期持续,或将它们配置为特定的持续时间。 此外,全局覆盖可以配置为应用于所有服务器,或仅应用于运行 Exchange 特定版本的服务器。
配置替代时,它不会立即生效。 Microsoft Exchange 运行状况管理器服务每隔 10 分钟检查一次更新的配置数据。 此外,全局覆盖依赖于 Active Directory 复制延迟。
有关查看或配置服务器或全局替代的详细步骤,请参阅 配置托管可用性替代。
管理任务和 Cmdlet
管理员通常会在托管可用性方面执行三个主要操作任务:
提取或查看系统运行状况
查看运行状况设置以及探测器、监视器和响应器的相关详细信息
管理覆盖
托管可用性的两个主要管理工具是 Windows 事件日志和 Exchange 命令行管理程序。 托管可用性在 Exchange ActiveMonitoring 和 ManagedAvailability crimson 通道事件日志中记录大量信息,例如:
探测器、监视器和响应器定义,记录在各自的*定义事件日志中。
探测器、监视器和响应器结果,记录在各自的*结果事件日志中。
有关响应程序恢复操作的详细信息,包括何时启动恢复操作,以及它被视为已完成 (是否成功) ,这些操作记录在 RecoveryActionResults 事件日志中。
有 12 个 cmdlet 用于托管可用性,如下表所示。
| Cmdlet | 说明 |
|---|---|
| Get-ServerHealth | 用于获取原始服务器的运行状况信息,例如运行状况设置及其当前状态(是否正常)、运行状况设置监视器、服务器组件、探测器的目标资源,以及与探测器或监视器启动或停止时间和状态转换时间有关的时间戳。 |
| Get-HealthReport | 用于获取运行状况摘要视图,其中包括运行状况设置及其当前状态。 |
| Get-MonitoringItemIdentity | 用于查看与特定运行状况设置相关的探测器、监视器和响应器。 |
| Get-MonitoringItemHelp | 用于查看有关探测器、监视器和响应器的某些属性的说明。 |
| Add-ServerMonitoringOverride | 用于创建探测器、监视器或响应器的特定于服务器的局部覆盖。 |
| Get-ServerMonitoringOverride | 用来查看指定服务器上的局部覆盖的列表。 |
| Remove-ServerMonitoringOverride | 用于从特定服务器删除局部覆盖。 |
| Add-GlobalMonitoringOverride | 用于为一组服务器创建全局覆盖。 |
| Get-GlobalMonitoringOverride | 用于查看在组织中配置的全局覆盖的列表。 |
| Remove-GlobalMonitoringOverride | 用于删除全局覆盖。 |
| Set-ServerComponentState | 用于配置一个或多个服务器组件的状态。 |
| Get-ServerComponentState | 用于查看一个或多个服务器组件的状态。 |