失败和容错
在日常讨论中,我们可能会随意谈论系统故障的原因。 往往可以交替使用错误、故障、失败、bug、缺陷等这些术语。 在数据中心,专业人员切勿混淆这些词语或使用一个词语代替另一个词语。 下面是与容错讨论相关的术语的精确定义:
bug 是系统设计中的异常现象,导致其行为与要求或预期的行为不一致。 从某种意义上讲,这可能是系统或软件未能达到预期的期望,但 bug 并不是系统故障。 事实上,许多 bug 是系统性能完全符合设计要求但与设计意图完全相反的产物。 此处的关键词是“一致性”。Bug 的行为可能会在系统的所有实例中重现。 调试是对系统进行重新设计以消除 bug 的行为。
故障是系统中的异常,导致其行为与设计相反,或完全停止工作。 在这里,系统的设计可能没有缺陷,但在这种设计的一个实现或实例中,它可能无法正常运行。 故障会导致行为无法在系统的任何其他实例中重现。 消除故障的行为称为修复。 系统故障可能通过以下三种方式之一表现出来:
永久性故障:对系统造成破坏,只有完全更换相应的组件才能解决此问题
暂时性故障:暂时(虽然通常没有重复发生)对系统造成破坏,就地修复或补救即可解决此问题,或者可能会在无干预的情况下自行解决问题
间歇性故障:通常是是暂时的、重复性的系统中断,这通常由组件的降级或设计不当导致,并且可能导致永久性故障无法得到纠正。
失败:系统的全部或部分完全崩溃,通常是由未解决的故障引起的。 在这里,故障是原因,而失败是结果。 容错 (FT) 系统是在不利的情况下按预期方式运行,或根据服务水平协议 (SLA) 的预期要求运行的系统,因此可以避免在出现故障时出现失败。
缺陷:制造硬件组件或实例化软件组件中出现的异常现象,这会导致其操作出错,并有可能导致实现该组件的系统发生故障。 此类异常只能通过替换进行修正。
错误:是产生不希望的结果或错误结果的操作的产物。 在计算设备中,错误可能是其设计中的 Bug 或实现中的故障的征兆,并且可能是即将发生的失败的有效指示。
对容错系统进行维护需要 IT 专家、管理员或操作员理解这些概念并了解它们之间的差异。 根据定义,云计算平台就是一个容错系统。 它是为预期故障而设计和构建的,旨在避免服务故障。 从工程的角度来看,这种复原能力就是“云”概念的含义。 当电话工程师在其系统关系图中首次使用云的形状时,它代表了不必查看或了解的网络组件,但其服务级别足够可靠,以至于不需要成为关系图的一部分,它们可能会被云遮盖。
当企业 IT 网络等信息系统与公有云平台联系时,该平台有义务充当 FT 系统。 但是,它不可以并且不能使与之通信的系统具有比现在更高的容错。 容错不是豁免,也不能保证系统中是否存在故障。 更重要的是,FT 系统不一定是完美无缺的。 相反,容错是指系统在出现故障时能够保持预期服务级别。
任何信息系统的目的都是使利用信息的功能自动化。 容错本身只能在一定程度上实现自动化。 Internet(最初的名称是 ARPANET)本身将容错视为其主要目标之一。 在灾难中,可以重新路由数字通信以绕过地址不再可访问的系统。 但 Internet 并不是一台自行维护的计算机,实际上,任何信息系统都不是。
任何信息系统都需要持续的人工努力才能实现和维护其服务目标。 最好的系统可使人为干预和补救变得简单、即时并按计划进行。
云平台中的容错
早期的云服务平台的容错可以说是不及其架构师预期的容错。 例如,在缺乏监视的情况下,客户过度预配服务资源(例如多个数据库实例或重复的内存缓存)的能力被证明无效,这有时会导致在灾难情况下无法使用备份或副本。 此外,过度预配有悖于云业务模型的其中某项基本原则:仅为所需资源付费。 如果在主 VM 出现故障的情况下租用额外的虚拟机实例,则组织将无法节省运营费用。
FT 系统确实允许冗余,但通过明智和动态的方式进行调整,以适应当前时刻的需求和资源可用性限制。 在客户端/服务器时代,整个服务器会定期备份,包括其本地数据存储及其连接的网络存储卷。 “备份所有内容”本身就是一种企业道德准则。 公共云服务变得既经济又实用后,组织便开始使用它们来“备份所有内容”。经过一段时间后,他们开始意识到云可以做的不仅仅是延续旧的方法。 云平台可以从容错开始设计,而不是在实现容错后进行容错。
应对方法
无论系统设计得多么完善,其大多数容错都将取决于系统和管理系统的人员对故障的第一个证据的响应程度。 下面是组织在故障发生后缓解故障所使用的一些应对方法。
非抢先式作业迁移
非抢先式作业迁移技术可确保不将显然遇到故障的工作负载的主机重新分配给具有相同工作负载的主机。 这种好处保护了“作业”,尽管它可能会使系统无法收集重复的错误实例作为故障的证据,但这可能会更容易通过记录正确的路径进行跟踪。
任务复制
许多分布式信息系统可同时运行任务的多个实例(对于 Kubernetes 业务流程来说,是副本)。 如果存在明显或可疑的系统故障,则基于策略的管理系统可用于复制任务。
检查点和恢复点
通过最简单的形式,检查点和还原点包括在各个时间点拍摄系统快照,并允许管理员在需要还原时回滚到指定的时间点。 当涉及事务时,例如,当应用程序对数据库执行必须作为一个整体(事务)成功或失败的两个或多个操作时,此策略将变得更加复杂。 一个常见的示例是应用程序,应用程序从一个帐户中贷款,而从另一个帐户中借记。 这些操作必须作为一个整体成功或失败,以避免产生或破坏财务资产。
在事务的检查点恢复系统中,事务的可撤回记录存储在进程树的内存中。 在事务处理期间的某些时候,它使用的内存资源被复制并存放在还原池中。 如果日志分析表明故障可能是由软件引起的,则为进程树创建分支,将事务状态移回较早的点,然后尝试使用新的事务。 如果新事务比故障事务更成功(例如,纠错测试顺利完成),则将修剪旧的进程分支,并从该点开始沿树的新分支继续进行,这就是工程师所说的“上下文切换”。1
此方法的一种高级版本在进程树中实现了跟踪系统,因此,当错误再次发生时,系统可以向后处理进程并跟踪出现错误的原因。 然后,它可以在触发错误之前选择适当的还原点或修复点。[2]
华盛顿大学和 Microsoft 研究的研究人员创建了另一种名为 SGuard 的实现,用于对大型数据流进行容错处理。 SGuard 利用 Hadoop 分布式文件系统 (HDFS) 来计划在处理过程中同时写入数据流的多个快照。 根据需要将这些快照划分为较小的部分,进而将流处理细分为较小的段。 检查点存储在 HDFS 中。 此系统的有点在于,可以维护流数据事务的记录以及在高度分散的位置中维护流数据的多个可行副本。 尽管实现 SGuard 需要进行大量准备工作,但由于其主要操作是为响应故障事件而触发的,因此仍将其看作是一种反应式容错方法。3
防范方法
在发现任何故障之前,要采用防范 FT 方法。 目的是预防,但是在新式实现中,此方法应属于一种方法论而不是准则。 下面是新式云平台当前使用的一些方法。
资源复制
有效的资源复制策略的关键不只是“备份所有内容”。系统分析员应能够确定发生故障事件后系统中(例如数据库引擎、Web 服务器或虚拟网络路由器)可自行恢复的资源和不可恢复的资源。 智能复制可能是容错系统中的第一道防线。
有四种用于实现资源复制的常用策略,所有这些策略如图 1 所示:
主动复制 - 所有复制的资源同时处于活动状态,每个资源独立维护自己的状态(使其正常运行的本地数据)。 此属性表示一个类中的所有复制资源均会收到客户的请求,并且所有资源都将处理响应。 但是,它是其响应已传递到客户端的类中指定的主要资源。 如果一个资源(包括主节点)发生故障,则会将另一个节点指定为其接替节点。 此系统要求主节点和副本节点之间的处理具有确定性,要在一个设定的行程中同时进行。
半主动复制 - 半主动复制类似于主动复制,不同之处在于副本节点不一定会处理请求或不与主节点同时处理请求。 辅助资源的输出被抑制并记录下来,并准备在主要资源发生故障时立即进行切换。
被动复制 - 只有主资源节点处理请求,而其他资源(副本)保持状态,并等待在发生故障时被指定为主资源。 客户端与之联系的主要资源会将任何状态更改中继到所有副本。 属于某个类的所有原件和副本都被视为组的成员,如果某个成员似乎发生了故障,即使实际上没有发生故障,该成员也会被踢出小组。 故障事件期间,确实存在延迟或服务质量 (QoS) 下降的可能性,尽管被动复制在正常操作中确实消耗了较少的资源。
半被动复制 - 此方法与被动复制具有相同的关系模式,只是没有永久的主要资源。 而是,依次将协调器的角色分配给每个资源,并通过称为旋转协调器样式的令牌传递模型确定转弯的协调性。
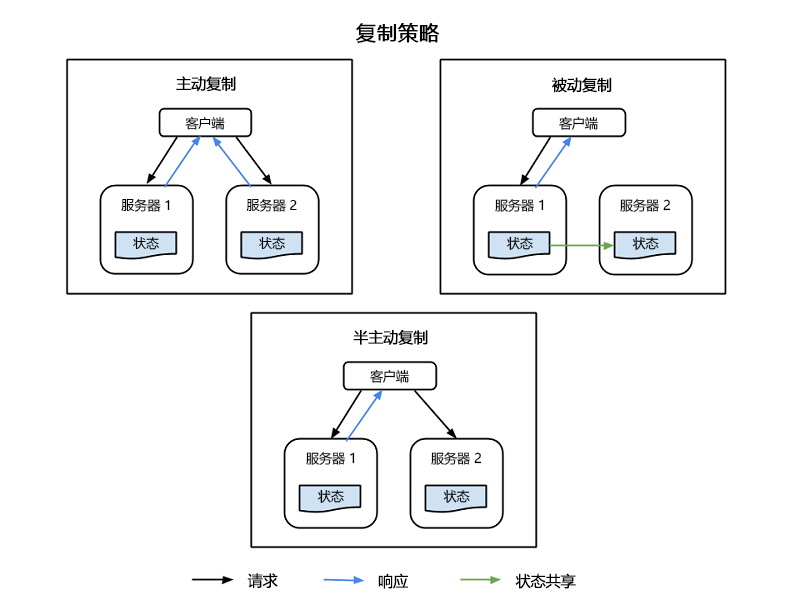
图 1:复制的信息系统中的客户端节点、主节点和副本节点。
负载均衡
负载均衡器在运行相同应用程序的多个服务器之间分配来自各种客户端的请求,从而分配工作负载并减轻系统组件的压力。 使用负载均衡器的一个正向副作用是,有些负载均衡器自动使流量远离无响应的服务器,从而减少了全面故障的机会。 在更新式的派生产品中(例如微服务),其中软件被设计为分布在整个云平台上,工作负载可细分为单独的功能,这些功能本身可分布在服务器端处理器之间,旨在实现均等分布和中等利用率水平。
虚拟化(云计算的关键组成部分)通过使工作负载具有可移植性,使处理器之间的工作负载分布更加均匀,从而可以将工作负载迁移到可充分利用它们的物理处理器上。 容器化将虚拟化的工作负载与虚拟处理器分离开来,从而改进了此方法,使工作负载驻留在操作系统最适合它们的服务器节点中。 此原则是 Kubernetes 等系统演示的工作负载业务流程的关键。
恢复活力和重新配置
在长时间部署软件实例的信息系统中,可能需要重启该软件。 虽然某些早期的云平台尝试随着时间的推移对软件实例的服务级别进行采样以确定何时需要重启,但后来的云平台采用了更简单的安排定期重启的这一方法。 在这些重启阶段中,可能会自动调整启动配置文件,以适应不断变化的系统情况,或在启动后预先制止潜在故障。
抢先迁移
当虚拟化首先成为数据中心的主要内容时,建议采用抢先迁移的方法,通过轮流方式将工作负载分配给处理器来平衡服务器硬件压力。 云平台频繁地跨虚拟基础结构重新分配工作负载,以至于在很大程度上没必要使用这种方法。 但是,在最近的讨论中,人们再次提到这一话题以及用于预测各种信息系统中的工作负载压力的人工智能方法。 此类系统可以制定自己的规则,以将更多关键工作负载从预测到具有较高故障可能性的服务器节点上移开。
自行修复
在内容传递网络 (CDN) 或社交媒体平台等广泛分布的信息系统中,各种服务器的功能可以分布在多个地址上,这些地址通常位于不同位置或数据中心。 自行修复网络定期轮询各种连接(例如性能管理平台),以获取流量流和响应能力。 每当性能出现不匹配时,路由器可能都会将请求从可疑组件中转移出去,最终阻止流量通过这些组件。 然后可以测试相应组件的运行状态是否有错误迹象。 然后可以重启相应组件以查看行为是否仍然存在,并且仅在诊断未发现故障可能性的情况下才返回活动状态。 这种类型的自动化事务响应是高度分布式数据中心中自行修复的新式示例。4
基于 Barter 的进程计划
云平台(包括基于公有云的服务,但可能还包括本地基础结构)是唯一能够报告其自身状态的平台。 当 Amazon 在 2009 年开始实现修改后的 SaaS 模型时,其工程师提出了一个名为 Spot 实例调度的概念。 在该系统中,使用客户身份的无提示代理会公布给定作业的资源要求,并广播一种竞标请求,特别是从整个云平台的服务器节点发出的竞标请求。 每个节点都会报告自身的功能,以根据时间和消耗的资源来满足竞标要求。 花费最少的竞标者会赢得合同,并被指定为该作业的 Spot 实例 (SI)。 这种调度方式目前是 Amazon Elastic Compute Cloud 的一种选择。5
参考
Ioana, Cristescu. 《用于多线程处理应用程序的记录和重播容错系统》. Technical University of Cluj Napoca. http://scholar.harvard.edu/files/cristescu/files/paper.pdf。
Sidiroglou, Stelios, et al.ASSURE: Automatic Software Self-healing Using Rescue Points. Columbia University, 2009.
Kwon Yong-Chul, et al. Fault-tolerant Stream Processing Using a Distributed, Replicated File System. Association for Computing Machinery, 2008. https://db.cs.washington.edu/projects/moirae/moirae-vldb08.pdf。
Yang, Chen. Checkpoint and Restoration of Micro-service in Docker Containers. School of Information Security Engineering, Shanghai Jiao Tong University, China, 2015. https://download.atlantis-press.com/article/25844460.pdf。
Amazon Web Services, Inc. Spot Instance Requests Amazon, 2020. https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/spot-requests.html。