设计和策略的复原能力
人们最常与“灾难恢复”一起听到的短语是“业务连续性”。连续性具有积极的含义。 它表明了将灾难事件的范围或实际上范围更小的任何内容限制在数据中心墙内的这种理想情况。
但“连续性”不是工程术语,尽管我们努力将其转换为一个工程术语。 业务连续性没有单一的公式、方法或秘诀。 对于任何组织,可能都有自己的一套与其从事的业务类型和方式有关的最佳做法。 连续性是指成功地应用这些做法以取得积极的结果。
复原能力的含义
工程师了解复原能力的概念。 系统在不同环境下表现良好时,这就是一种复原能力。 风险管理人员认为,如果企业已实现自动防故障装置、安全措施和灾难过程,可以应对其可能面临的任何不利影响,那么就表示该企业已做好充分的准备。 工程师可能不会用“正常”与“受到威胁”、“安全”与“灾难”这种简单明了的术语来理解系统运行的环境。当系统面对不利情况提供连续且可预测的服务水平时,他们会认为支持业务的系统处于正常运行状态。
在 2011 年,正当云计算成为数据中心的发展趋势时,隶属欧盟的欧洲网络信息安全机构 (ENISA) 应欧盟政府的要求发布了一份报告,详细展示他们用来采集和收集信息的系统的复原能力。 该报告直接指出,ICT(在欧洲,“ICT”是指“IT”,其中包括通信)人员之间尚未就“复原能力”的实际含义或如何衡量这一问题达成任何共识。
这使得 ENISA 发现了由堪萨斯大学 (KU) 的一组研究人员发起的项目。此项目由 James P. G.Sterbenz 教授领导,并打算在美国国防部进行部署。 它被称为可复原且可生存的网络计划 (ResiliNets)1,这是一种可视化各种情况下信息系统复原能力变化状态的方法。 ResiliNets 是组织中复原能力策略的共识模型的原型。
KU 模型利用了许多熟悉且易于解释的指标,本章中已介绍了其中一些指标。 它们包括:
容错 - 如前所述,容错是指系统在出现故障时,能够保持预期服务级别
容断 - 相同系统面对不是由系统本身引起的不可预测且通常是极端操作(例如停电、Internet 带宽不足和流量高峰)的情况,能够保持预期服务水平
生存能力 - 对系统在包括自然灾害在内的所有可能情况下,提供合理的服务性能水平(如果并非始终具有确定性)的能力的估计
ResiliNets 提出的关键理论是,通过结合系统工程和人工努力,可以使信息系统在数量上更具复原能力。 更重要的是,人们在日常实践中继续做的事情都会使系统更强大。
KU 团队从作战战区的士兵、水手和海军陆战队如何学习并记住战术部署原理中获得启示,提出了一种餐巾纸背面式记忆法,用于记住 ResiliNets 做法的生命周期:D2R2 + DR。 如图 9 所示,此处的变量按以下顺序表示:**
防御使系统免受其正常运行的威胁
检测由于可能的故障以及外部环境而产生的不利影响
修复这些影响可能对系统造成的后续影响,即使该影响仍然存在
恢复至正常服务级别
诊断事件的根本原因
根据需要优化未来的行为,以便为其再次发生做好更好的准备
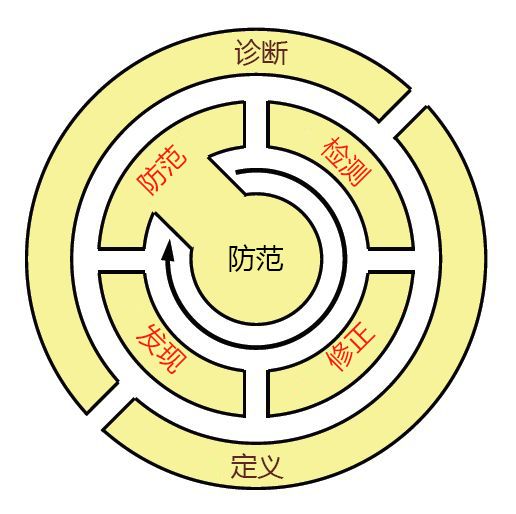
图 9:在利用 ResiliNets 的环境中,最佳做法活动的生命周期。
在这些阶段的每个阶段中,都会获得人员和系统的某些性能和操作指标。 可以使用欧几里德几何平面将这些指标组合产生的点绘制在图表上,如图 9.10 所示。 每个指标都可以减少为两个一维值:一个反映服务级别参数 P,另一个代表操作状态 N。由于 ResiliNets 周期的所有六个阶段均已实现并重复执行,因此将服务状态 S 绘制在图表上的坐标 (N, P) 处。
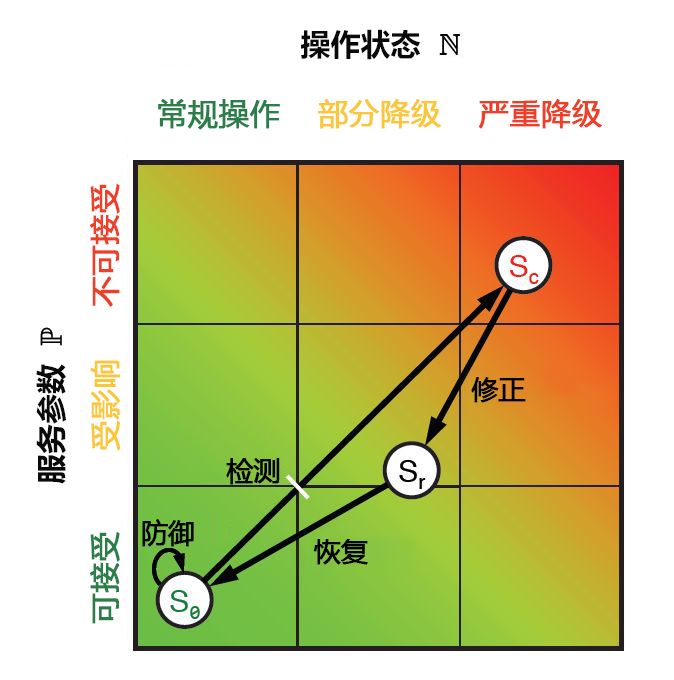
图 10:ResiliNets 状态空间和策略内部循环。
实现其服务目标的组织将使其 S 状态紧紧地悬停在图表的左下角,希望使其在所谓的内部循环期间保持在此处或附近。 当服务目标降级时,状态将沿着不需要的向量向右上方移动。
尽管 ResiliNets 模型尚未成为企业中 IT 复原能力的普遍描述,但一些知名组织(尤其是公共部门)采用了此模型,从而引发了一些推动云革命的改变:
性能可视化效果。 复原能力不必成为向相关利益干系人报告其现状的一种理念。 实际上,证明这一点也并不复杂。 结合了来自云的指标的新式性能管理平台已经整合了仪表板和类似工具,从而使案例变得更加有效。
恢复措施和过程无需等待灾难的来临。 设计完善的严密信息系统将每天实现维护过程,这与危机过程中的补救过程几乎没有差别。该系统由工程师和操作人员组成,他们会随时保持警惕。 例如,在热备用服务器灾难恢复环境中,补救服务级别问题实际上可能会自动解决,而主路由器只是使流量远离受影响的组件。 换句话说,为失败做准备不一定要等待失败发生。
信息系统是由人组成的。 自动化可以使人们的工作效率更高以及更高效地生产产品。 但它无法替代旨在应对无法预料的环境情况和环境变化的系统中的人。
面向恢复的计算
ResiliNets 是 Microsoft 在世纪之交后帮助提出的一种概念实现,称为面向恢复的计算 (ROC)。2它的主要原则是,故障和 bug 是计算环境的永恒真理。 可以说,与其花费过多的时间对这种环境进行消毒,不如让组织采用常见措施对环境进行接种,这样做可能会更好。 这种计算等同于在 20 世纪初之前提出的激进概念(人们每天应多洗手)。
公有云中的复原能力
公有云服务提供商都遵守复原能力的原则和框架,即使他们选择不使用复原能力名称来称呼它也是如此。 但是,除非云平台将组织的信息资产全部吸收到云中,否则它不能增强数据中心的复原能力。 混合云实现的复原能力取决于管理员的勤奋程度。 如果我们可以假设 CSP 的管理员勤于遵守复原能力(否则会违反其 SLA 的条款),那么维护整个系统的复原能力始终是客户的任务。
Azure 复原能力框架
业务连续性策略的国际标准准则是 ISO 22301。 与其他国际标准化组织 (ISO) 框架一样,它为最佳做法和操作规定了准则,遵守这些准则可使组织获得专业认证。
此 ISO 框架实际上并没有定义业务连续性,也没有定义复原能力。 相反,它定义了连续性在组织自身环境中的含义。 其指导文件中写道:“组织应基于业务影响分析和风险评估的输出,确定并选择业务连续性策略。 业务连续性策略应由一个或多个解决方案组成”。它不会继续列出这些解决方案可能是什么或应该是什么。3
图 11 是 Microsoft 对 Azure 的 ISO 22301 合规性的多阶段实现的描述。 请注意,其中包括服务级别协议 (SLA) 正常运行时间目标。 对于选择这种复原能力级别的客户,Azure 会在其本地可用性区域内复制虚拟数据中心,然后再预配其地理位置相距数百英里的单独副本。 但出于法律原因(特别是为了遵守欧盟的隐私法),这种地理位置分隔的冗余通常仅限于“数据驻留边界”,例如北美或欧洲。
![Figure 11: Azure Resiliency Framework, which protects active components on multiple levels, in accordance with ISO 22301. [Courtesy Microsoft]](../../cmu-cloud-admin/cmu-disaster-recovery-backup/media/fig9-11.jpg)
图 11:根据 ISO 22301 规定,Azure 复原能力框架可在多个级别上保护活动组件。 [Courtesy Microsoft]
尽管 ISO 22301 与复原能力有关,并且通常被描述为一组复原能力准则,但是通过测试的 Azure 的复原能力级别仅适用于 Azure 平台,而不适用于该平台上托管的客户资产。 客户仍然有责任管理、维护和经常改进其流程,包括如何在 Azure 云和其他地方复制其资产。
Google 容器引擎
直到现在,软件仍被视为计算机的状态,它在功能上与硬件相同,但仍采用数字形式。 从这个角度来看,软件已被视为是信息系统中相对静态的组件。 安全协议规定软件必须定期更新,并且随着更新和 bug 修复的出现,“定期”通常表示每年需要更新几次。
云动态使这些成为可能,但是许多 IT 工程师没有想到的是,软件能够渐进地不断发展。 持续集成和持续交付 (CI/CD) 是一组新出现的原则,其中自动化使服务器和客户端上的软件增量更改得以频繁地(通常是每天)分阶段进行。 智能手机用户通过应用商店中每周更新几次的应用定期体验 CI/CD。 CI/CD 带来的每一种变化都可能是微小的,但事实上,即便是微小的更改也可能迅速轻松得以部署,这会导致不可预料却让人乐于接受的副作用,更加可复原的信息系统。
借助 CI/CD 部署模型,通常可在公有云基础结构上预配和维护完全冗余的服务器群集,这不仅是测试新生产的软件组件是否存在 bug 的一种方式,也是在模拟的工作环境中暂存这些组件以发现潜在故障的一种方式。 这样,可以在安全的环境中执行补救过程,这不会直接影响面向客户或面向用户的服务级别,直到已应用、测试并批准用于部署的补救措施为止。
Google 容器引擎(简称 GKE,其中的“K”是 “Kubernetes”的缩写)是 Google Cloud Platform 的环境,供客户部署基于容器的应用程序和服务,而不是基于 VM 的应用程序。 完整的容器化部署可能包括在应用程序代码需要利用容器自身文件系统时使用的微服务(“µ-服务”)、与工作负载分离并设计为独立运行的数据库(“状态数据集”)、相关代码库以及小型操作系统。 图 9.12 描述了 Google 实际上为其 GKE 客户建议的这样一种部署。
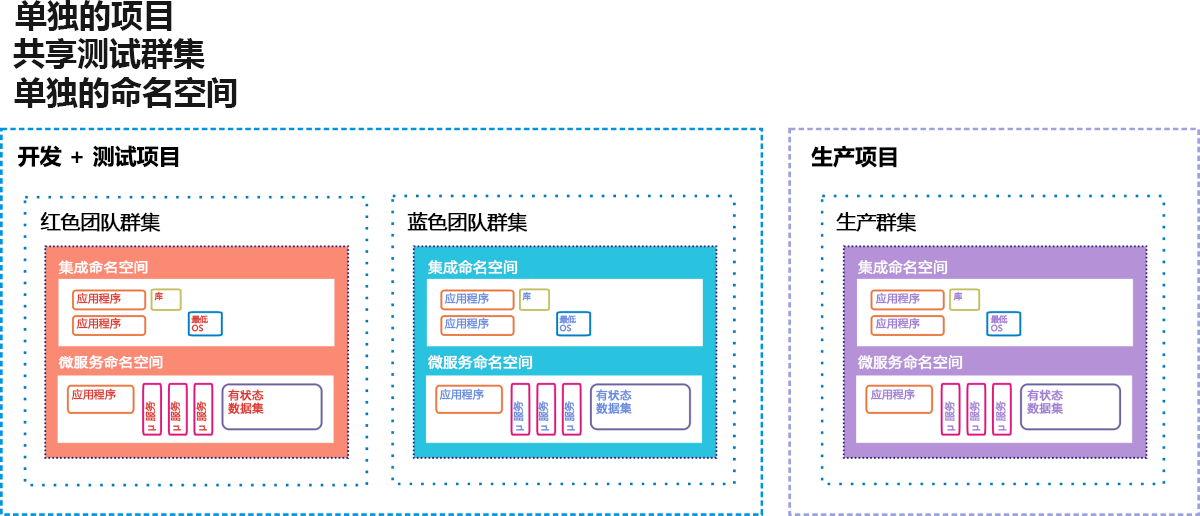
图 12:作为 Google 容器引擎的 CI/CD 过渡环境的热备用服务器选项。
在 GKE 中,项目类似于数据中心,因为它被认为拥有数据中心通常拥有的所有资源,只是以虚拟形式存在。 可能会将一个或多个服务器群集分配给一个项目。 容器化组件存在于自己的命名空间中,就像它们的自家领域一样。 每个组件都由允许其成员容器访问的所有可寻址组件组成,并且命名空间之外的任何内容都必须使用远程 IP 地址进行寻址。 Google 的工程师建议,老式的客户端/服务器应用程序(被容器开发人员称为“整体”)可以与容器化的应用程序共存,只要每个类在共享同一项目的同时利用其自身的命名空间来保证安全性即可。
在此建议的部署关系图中,有三个活动群集,每个群集运行两个命名空间:一个用于旧的命名空间,一个用于新的命名空间。 这些群集中有两个群集被委派用于测试:一个群集用于初始开发测试,而另一个群集则用于最终过渡。 在 CI/CD 管道中,新的代码容器被注入到一个测试群集中。 在此之前,它必须通过一系列自动化测试,证明相对没有 bug,然后才能转移到过渡阶段。 第二个群集在那里等待新的软件容器。 只有通过第二阶段过渡测试的代码才可以注入到最终客户正在使用的实时生产群集中。
但是,即使在那里也有自动防故障装置。 在 A/B 部署方案中,新代码与旧代码在指定的时间内共存。 如果新代码无法满足规范要求或将故障引入系统,则可以将其撤回,而留下旧代码。 如果假释间隔期满且新代码执行良好,则撤回旧代码。
此过程是信息系统的系统化和半自动化方式,可以避免引入导致故障的错误。 但是,除非生产群集本身是在热备用服务器模式下复制的,否则它本身并不是防灾难的设置。 当然,此复制方案会消耗大量基于云的资源。 但所涉及的成本可能仍远低于组织在系统中断时不受保护而导致的费用。
参考资料
Sterbenz, James P.G.等."ResiliNets:Multilevel Resilient and Survivable Networking Initiative." https://resilinets.org/main_page.html.
Patterson, David, et al. "Recovery Oriented Computing: Motivation, Definition, Principles, and Examples." Microsoft Research, March 2002. https://www.microsoft.com/research/publication/recovery-oriented-computing-motivation-definition-principles-and-examples/。
ISO. "Security and resilience - Business continuity management systems - Requirements." https://dri.ca/docs/ISO_DIS_22301_(E).pdf.