二元分类
分类与回归一样,是一种受监督的机器学习技术,因此遵循相同的适用于训练、验证和评估模型的迭代过程。 用于训练分类模型的算法不是像回归模型那样计算数值,而是计算类分配的概率值以及用于评估模型性能的评估指标,将预测类与实际类进行比较。
二元分类算法用于训练模型,该模型可预测单个类的两个可能标签之一。 本质上是预测 true 或 false。 在大多数实际方案中,用于训练和验证模型的数据观测值包含多个特征 (x) 值和一个为 1 或 0 的 y 值。
示例 - 二元分类
为了了解二元分类的工作原理,我们来看一个简化的示例,该示例使用单个特征 (x) 来预测标签 y 是 1 还是 0。 在此示例中,我们将使用患者的血糖水平来预测患者是否患有糖尿病。 下面是用于训练模型的数据:
 |
 |
|---|---|
| 血糖 (x) | 糖尿病? (y) |
| 67 | 0 |
| 103 | 1 |
| 114 | 1 |
| 72 | 0 |
| 116 | 1 |
| 65 | 0 |
训练二元分类模型
为了训练模型,我们将使用一种算法将训练数据拟合为一个函数,该函数计算类标签为 true(换句话说,患者有糖尿病)的概率。 概率以某个 0.0 到 1.0 之间的值来度量,使得所有可能的类的总概率为 1.0。 例如,如果一名患者患糖尿病的概率为 0.7,那么该患者未患糖尿病的相应概率为 0.3。
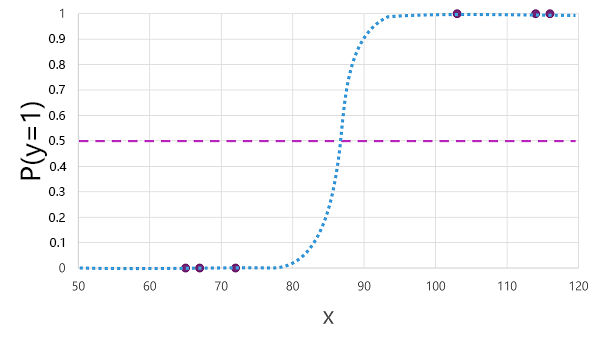
有许多可用于二元分类的算法,例如逻辑回归,它会导出值在 0.0 到 1.0 之间的 sigmoid(S 形)函数,如下所示:
注意
尽管名称如此,但在机器学习中,逻辑回归用于分类,而不是用于回归。 重点是它生成的函数的逻辑性质,该函数描述了下限值和上限值(用于二元分类时为 0.0 和 1.0)之间的 S 形曲线。
该算法生成的函数描述了 x 为给定值时 y 为 true (y=1) 的概率。 从数学上来说,可以这样表达该函数:
f(x) = P(y=1 | x)
就训练数据中六个观测值中的三个来说,我们知道 y 肯定为 true,因此就这些观测值来说,y=1 的概率为 1.0;就其他三个来说,我们知道 y 肯定为 false,因此 y=1 的概率为 0.0。 S 形曲线描绘了概率分布情况,因此在曲线上标出 x 的值就可以确定 y 为 1 的相应概率。
该图还包含一条水平线,指示基于此函数的模型将预测 true (1) 或 false (0) 的阈值。 阈值位于 y (P(y) = 0.5) 的中间点。 对于此点或高于此点的任何值,模型会预测 true (1);而对于低于此点的任何值,模型会预测 false (0)。 例如,对于血糖水平为 90 的患者,该函数将得出的概率值为 0.9。 由于 0.9 高于阈值 0.5,因此模型会预测 true (1) - 换句话说,预测患者患有糖尿病。
评估二元分类模型
与回归一样,在训练二元分类模型时,我们会保留一个随机数据子集来验证训练后的模型。 假设我们保留以下数据来验证糖尿病分类器:
| 血糖 (x) | 糖尿病? (y) |
|---|---|
| 66 | 0 |
| 107 | 1 |
| 112 | 1 |
| 71 | 0 |
| 87 | 1 |
| 89 | 1 |
将我们之前派生的逻辑函数应用于 x 值会生成下图。
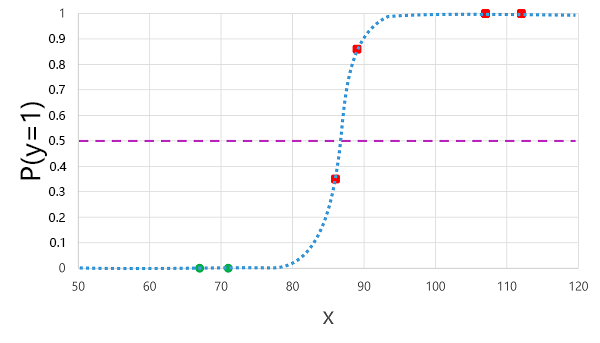
模型为每个观测值生成预测标签 1 或 0,具体取决于函数计算出的概率是高于阈值还是低于阈值。 然后,我们可以将预测的类标签 (ŷ) 与实际的类标签 (y) 进行比较,如下所示:
| 血糖 (x) | 实际的糖尿病诊断 (y) | 预测的糖尿病诊断 (ŷ) |
|---|---|---|
| 66 | 0 | 0 |
| 107 | 1 | 1 |
| 112 | 1 | 1 |
| 71 | 0 | 0 |
| 87 | 1 | 0 |
| 89 | 1 | 1 |
二元分类评估指标
计算二元分类模型的评估指标的第一步通常是为每个可能的类标签创建正确预测和错误预测的数量矩阵:
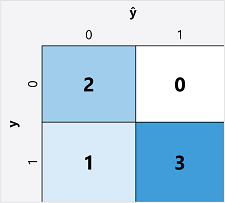
此可视化效果称为混淆矩阵,它显示预测总计,其中:
- ŷ=0 且 y=0:真阴性 (TN)
- ŷ=1 且 y=0:假阳性 (FP)
- ŷ=0 且 y=1:假阴性 (FN)
- ŷ=1 且 y=1:真阳性 (TP)
混淆矩阵的排列是这样的:正确 (true) 预测显示在从左上角到右下角的对角线上。 通常情况下,颜色强度用于指示每个单元格中的预测数量,因此快速浏览一下预测良好的模型应该就会看出深阴影对角线趋势。
精确度
可以根据混淆矩阵计算出的最简单指标是准确度 - 模型正确预测的比例。 准确度的计算方式如下:
(TN+TP) ÷ (TN+FN+FP+TP)
在我们的糖尿病示例中,计算如下:
(2+3) ÷ (2+1+0+3)
= 5 ÷ 6
= 0.83
因此,就我们的验证数据来说,糖尿病分类模型在 83% 的情况下产生正确的预测。
准确度一开始似乎是评估模型的一个很好的指标,但请考虑这一点。 假设 11% 的人口患有糖尿病。 可以创建一个始终预测 0 的模型,即使在没有真正尝试通过评估患者的特征来区分患者的情况下,其准确率仍可达到 89%。 我们真正需要的是更深入地了解模型在预测 1(代表阳性病例)和 0(代表阴性病例)时的表现。
召回率
召回率是度量此模型正确识别的阳性病例比例的指标。 换句话说,与确实患有糖尿病的患者人数相比,此模型预测有多少人患有糖尿病?
召回率的公式为:
TP ÷ (TP+FN)
就我们的糖尿病示例来说:
3 ÷ (3+1)
= 3 ÷ 4
= 0.75
因此,我们的模型正确地将 75% 的糖尿病患者识别为糖尿病患者。
精度
精准率是与召回率类似的指标,但度量的是预测为阳性病例且真实标签实际上也为阳性的比例。 换句话说,在模型预测患有糖尿病的患者中,实际患有糖尿病的患者的比例是多少?
精准率公式为:
TP ÷ (TP+FP)
就我们的糖尿病示例来说:
3 ÷ (3+0)
= 3 ÷ 3
= 1.0
因此,在我们的模型预测的患有糖尿病的患者中,100% 的人确实患有糖尿病。
F1 分数
F1 分数是一个结合了召回率和精准率的总体指标。 F1 分数的公式为:
(2 x 精准率 x 召回率) ÷ (精准率 + 召回率)
就我们的糖尿病示例来说:
(2 x 1.0 x 0.75) ÷ (1.0 + 0.75)
= 1.5 ÷ 1.75
= 0.86
曲线下面积 (AUC)
召回率的另一个名称是真阳性率 (TPR)。此外还有一个称为假阳性率 (FPR) 的等效指标,其计算公式为 FP÷(FP+TN)。 我们已经知道,在使用阈值 0.5 时,我们的模型的 TPR 为 0.75。我们可以使用 FPR 的公式计算出 0÷2 的值为 0。
当然,如果我们更改模型预测 true (1) 的阈值,则会影响阳性和阴性预测的数量,因此会更改 TPR 和 FPR 指标。 这些指标通常用于通过绘制接收方操作特征 (ROC) 曲线来评估模型,该曲线会比较 0.0 到 1.0 之间的每个可能阈值的 TPR 和 FPR:
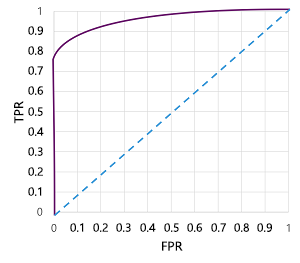
完美模型的 ROC 曲线会沿左侧的 TPR 轴直线上升,然后穿过顶部的 FPR 轴。 由于曲线的绘图面积为 1x1,因此该完美曲线下的面积将为 1.0(这意味着模型始终是正确的)。 相比之下,从左下角到右上角的对角线表示通过随机猜测二进制标签获得的结果;产生的曲线下面积为 0.5。 换句话说,给定两个可能的类标签,你可以合理预期猜对的概率为 50%。
就我们的糖尿病模型来说,会生成上面的曲线,曲线下面积 (AUC) 指标为 0.875。 由于 AUC 高于 0.5,因此我们可以得出结论:该模型在预测患者是否患有糖尿病方面比随机猜测的表现更好。