使用 PowerShell 创建自定义敏感信息类型
本文介绍如何创建定义自定义敏感信息类型的 XML 规则包文件。 本文介绍标识员工 ID 的自定义敏感信息类型。 可以使用本文中的示例 XML 作为自己的 XML 文件的起点。
有关敏感信息类型的详细信息,请参阅 了解敏感信息类型。
创建格式正确的 XML 文件后,可以使用 PowerShell 将其上传到 Microsoft 365。 然后,即可在策略中使用自定义敏感信息类型。 可以按预期测试其检测敏感信息的有效性。
注意
如果不需要 PowerShell 提供的精细控件,可以在Microsoft Purview 合规门户创建自定义敏感信息类型。 有关详细信息,请参阅创建自定义敏感信息类型。
提示
如果你不是 E5 客户,请使用为期 90 天的 Microsoft Purview 解决方案试用版来探索其他 Purview 功能如何帮助组织管理数据安全性和合规性需求。 立即从Microsoft Purview 合规门户试用中心开始。 了解有关 注册和试用条款的详细信息。
重要免责声明
Microsoft 支持部门无法帮助你创建内容匹配的定义。
对于自定义内容匹配开发、测试和调试,需要使用自己的内部 IT 资源,或使用咨询服务,例如 Microsoft 咨询服务 (MCS) 。 Microsoft 支持部门工程师可以为此功能提供有限的支持,但他们不能保证自定义内容匹配建议将完全满足你的需求。
MCS 可以提供正则表达式用于测试目的。 他们还可以帮助排查现有正则表达式模式在单个特定内容示例中无法按预期工作的问题。
请参阅本文中 要注意的潜在验证问题 。
有关用于处理文本的 Boost.RegEx(以前称为 RegEx++)引擎的详细信息,请参阅 Boost.Regex 5.1.3。
注意
如果使用和字符 (&) 作为自定义敏感信息类型中关键字 (keyword) 的一部分,则需要添加一个附加字词,并在字符周围添加空格。 例如,使用 L & PnotL&P。
规则包 XML 示例
下面是本文中创建的规则包的示例 XML。 以下各节对元素和属性进行了说明。
<?xml version="1.0" encoding="UTF-16"?>
<RulePackage xmlns="http://schemas.microsoft.com/office/2011/mce">
<RulePack id="DAD86A92-AB18-43BB-AB35-96F7C594ADAA">
<Version build="0" major="1" minor="0" revision="0"/>
<Publisher id="619DD8C3-7B80-4998-A312-4DF0402BAC04"/>
<Details defaultLangCode="en-us">
<LocalizedDetails langcode="en-us">
<PublisherName>Contoso</PublisherName>
<Name>Employee ID Custom Rule Pack</Name>
<Description>
This rule package contains the custom Employee ID entity.
</Description>
</LocalizedDetails>
</Details>
</RulePack>
<Rules>
<!-- Employee ID -->
<Entity id="E1CC861E-3FE9-4A58-82DF-4BD259EAB378" patternsProximity="300" recommendedConfidence="75">
<Pattern confidenceLevel="65">
<IdMatch idRef="Regex_employee_id"/>
</Pattern>
<Pattern confidenceLevel="75">
<IdMatch idRef="Regex_employee_id"/>
<Match idRef="Func_us_date"/>
</Pattern>
<Pattern confidenceLevel="85">
<IdMatch idRef="Regex_employee_id"/>
<Match idRef="Func_us_date"/>
<Any minMatches="1">
<Match idRef="Keyword_badge" minCount="2"/>
<Match idRef="Keyword_employee"/>
</Any>
<Any minMatches="0" maxMatches="0">
<Match idRef="Keyword_false_positives_local"/>
<Match idRef="Keyword_false_positives_intl"/>
</Any>
</Pattern>
</Entity>
<Regex id="Regex_employee_id">(\s)(\d{9})(\s)</Regex>
<Keyword id="Keyword_employee">
<Group matchStyle="word">
<Term>Identification</Term>
<Term>Contoso Employee</Term>
</Group>
</Keyword>
<Keyword id="Keyword_badge">
<Group matchStyle="string">
<Term>card</Term>
<Term>badge</Term>
<Term caseSensitive="true">ID</Term>
</Group>
</Keyword>
<Keyword id="Keyword_false_positives_local">
<Group matchStyle="word">
<Term>credit card</Term>
<Term>national ID</Term>
</Group>
</Keyword>
<Keyword id="Keyword_false_positives_intl">
<Group matchStyle="word">
<Term>identity card</Term>
<Term>national ID</Term>
<Term>EU debit card</Term>
</Group>
</Keyword>
<LocalizedStrings>
<Resource idRef="E1CC861E-3FE9-4A58-82DF-4BD259EAB378">
<Name default="true" langcode="en-us">Employee ID</Name>
<Description default="true" langcode="en-us">
A custom classification for detecting Employee IDs.
</Description>
<Description default="false" langcode="de-de">
Description for German locale.
</Description>
</Resource>
</LocalizedStrings>
</Rules>
</RulePackage>
你的关键要求是什么? [Rule、Entity、Pattern 元素]
请务必了解规则的 XML 架构的基本结构。 你对结构的理解有助于自定义敏感信息类型识别正确的内容。
规则定义一个或多个实体 (也称为) 敏感信息类型。 每个实体定义一个或多个模式。 模式是策略在评估内容时查找的内容, (例如电子邮件和文档) 。
在 XML 标记中,“规则”是指定义敏感信息类型的模式。 请勿将本文中对规则的引用与其他 Microsoft 功能中常见的“条件”或“操作”相关联。
最简单方案:包含一个模式的实体
下面是一个简单的方案:你希望策略识别包含组织中使用的九位数员工 ID 的内容。 模式引用规则中标识九位数字的正则表达式。 包含 9 位数字的任何内容都满足模式。

但是,此模式可以标识 任何 九位数,包括更长的数字或其他类型的九位数数字,这些数字不是员工 ID。 这种类型的不需要的匹配称为 误报。
更常见方案:包含多个模式的实体
由于可能存在误报,因此通常使用多个模式来定义实体。 多个模式为目标实体提供支持证据。 例如,其他关键字、日期或其他文本可帮助识别原始实体 (例如,九位数的员工编号) 。
例如,若要提高识别包含员工 ID 的内容的可能性,可以定义要查找的其他模式:
- 标识雇用日期的模式。
- 标识雇用日期和“员工 ID”关键字 (keyword) 的模式。
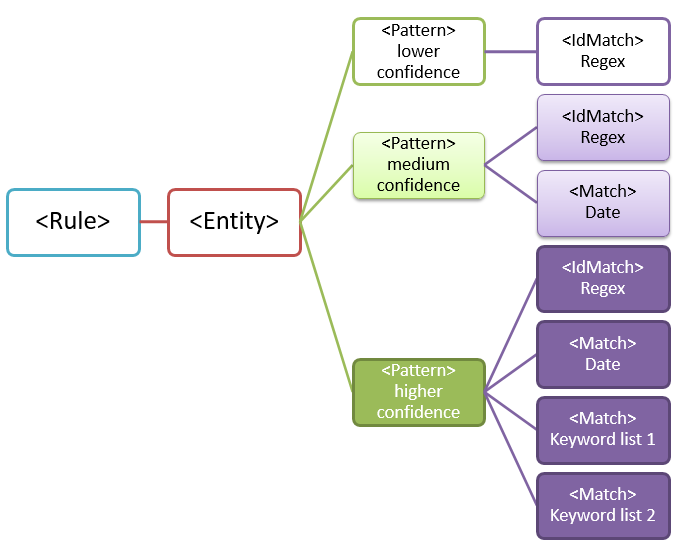
对于多模式匹配,需要考虑一些要点:
需要更多证据的模式具有更高的可信度级别。 根据置信度级别,可以执行以下操作:
- 使用更严格的操作 (,例如块内容) 具有更高置信度匹配项。
- 使用限制性较低的操作 (,例如) 低置信度匹配项发送通知。
支持
IdMatch和Match元素引用实际是 元素的子元素(而不是Pattern)的Rule正则表达式和关键字。 引用Pattern支持元素,但它们包含在 中Rule。 此行为意味着支持元素的单个定义(如正则表达式或关键字 (keyword) 列表)可由多个实体和模式引用。
需要标识哪个实体? [实体元素,ID 属性]
实体是具有明确定义的模式的敏感信息类型,例如信用卡数字。 每个实体都有一个唯一的 GUID 作为其 ID。
命名实体并生成 GUID
- 在所选的 XML 编辑器中,添加
Rules和Entity元素。 - 添加包含自定义实体名称的注释,例如员工 ID。 稍后,将实体名称添加到本地化字符串部分,创建策略时,该名称将显示在管理中心。
- 为实体生成唯一的 GUID。 例如,在 Windows PowerShell 中,可以运行 命令
[guid]::NewGuid()。 稍后,还将 GUID 添加到实体的本地化字符串部分。

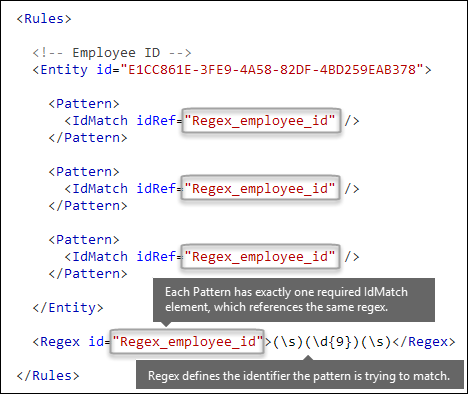
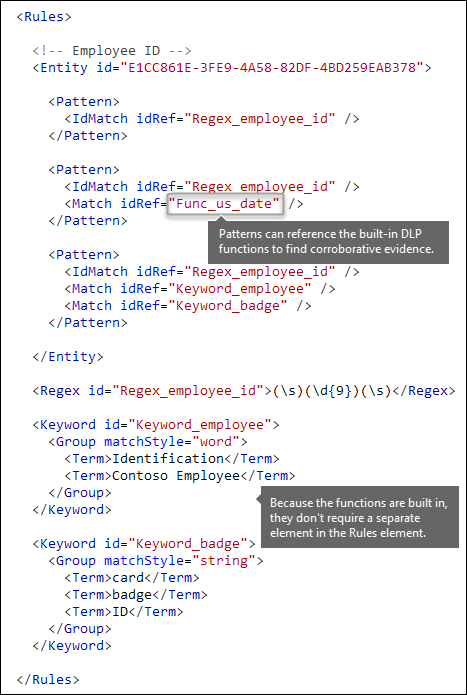
要匹配哪种模式? [Pattern 元素、IdMatch 元素、Regex 元素]
该模式包含敏感信息类型要查找的内容的列表。 该模式可以包括正则表达式、关键字和内置函数。 函数执行运行正则表达式等任务来查找日期或地址。 敏感信息类型可能具有多个模式,每个模式均具有唯一的可信度。
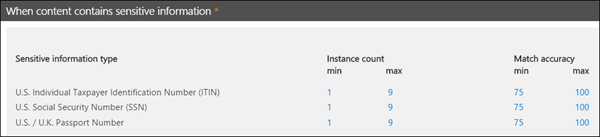
在下图中,所有模式都引用同一个正则表达式。 此正则表达式查找由空格(\s) ... (\s)包围的 9 位数字(\d{9})。 元素 IdMatch 引用此正则表达式,它是查找 Employee ID 实体的所有模式的常见要求。 IdMatch 是模式要尝试匹配的标识符。 一个 Pattern 元素必须正好有一个 IdMatch 元素。
满足的模式匹配将返回计数和置信度级别,可在策略中的条件中使用。 向策略添加用于检测敏感信息类型的条件时,可以编辑计数和置信度,如下图所示。 本文稍后将介绍) 置信度 (也称为匹配准确度。

正则表达式功能强大,因此需要了解一些问题。 例如,标识过多内容的正则表达式可能会影响性能。 若要了解有关这些问题的详细信息,请参阅本文后面的 潜在验证问题 部分。
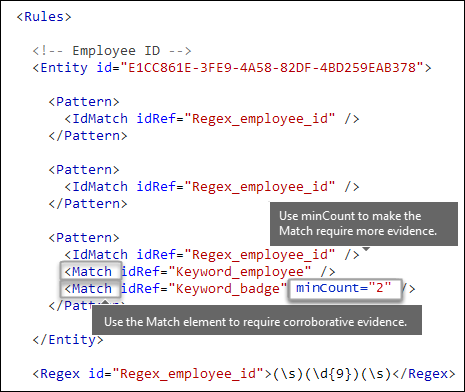
是否需要其他证据? [Match 元素,minCount 属性]
除了 IdMatch之外,模式还可以使用 Match 元素来要求其他支持证据,例如关键字 (keyword) 、正则表达式、日期或地址。
可能包含 Pattern 多个 Match 元素:
- 直接在 元素中
Pattern。 - 使用
Any元素组合。
Match 元素与隐式 AND 运算符联接。 换句话说,必须满足所有 Match 元素才能匹配模式。
可以使用 Any 元素来引入 AND 或 OR 运算符。 Any本文稍后将介绍 元素。
可以使用可选 minCount 属性来指定需要为每个 Match 元素找到多少个匹配实例。 例如,可以指定仅在找到关键字 (keyword) 列表中的至少两个关键字时才满足模式。
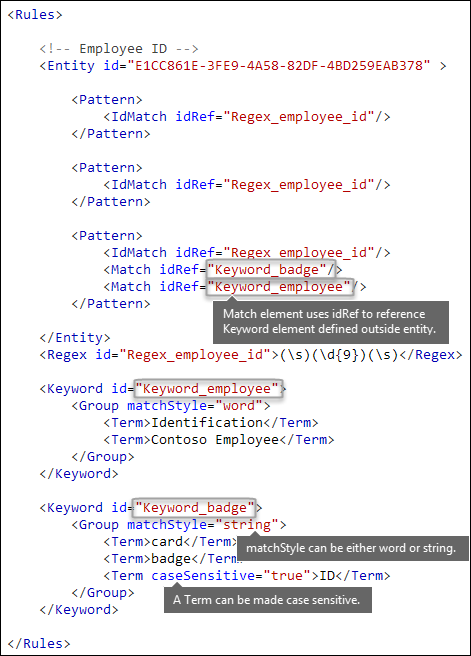
关键字 [Keyword、Group 和 Term 元素,matchStyle 和 caseSensitive 特性]
如前所述,识别敏感信息通常需要其他关键字作为确凿证据。 例如,除了匹配九位数的数字外,还可以使用 Keyword 元素查找“卡”、“徽章”或“ID”等字词。 元素 Keyword 具有一个 ID 属性,该属性可由多个模式或实体中的多个 Match 元素引用。
关键字作为元素中的Group元素列表Term包含。 元素 Group 具有具有两个 matchStyle 可能值的属性:
matchStyle=“word”:单词匹配标识被空格或其他分隔符包围的整个单词。 除非需要匹配亚洲语言中部分字词或字词,否则应始终使用单词。
matchStyle=“string”:字符串匹配标识字符串,无论字符串被什么括起来。 例如,“ID”与“bid”和“idea”匹配。
string仅当需要匹配亚洲字词时或关键字 (keyword) 可能包含在其他字符串中时使用。
最后,可以使用 caseSensitive 元素的 Term 属性来指定内容必须与关键字 (keyword) 完全匹配,包括小写字母和大写字母。
正则表达式 [Regex 元素]
在此示例中,员工 ID 实体已使用 IdMatch 元素来引用模式的正则表达式:用空格包围的 9 位数字。 此外,模式可以使用 Match 元素来引用附加 Regex 元素来标识确凿证据,例如采用美国邮政编码格式的 5 位或 9 位数字。
日期或地址等其他模式 [内置函数]
敏感信息类型还可以使用内置函数来识别确凿证据。 例如,美国日期、欧盟日期、到期日期或美国地址。 Microsoft 365 不支持上传自己的自定义函数。 但是,创建自定义敏感信息类型时,实体可以引用内置函数。
例如,员工 ID 徽章上有一个雇用日期,因此此自定义实体可以使用内置 Func_us_date 函数来标识美国常用的格式的日期。
有关详细信息,请参阅 敏感信息类型函数。
不同证据组合 [Any 元素、minMatches 和 maxMatches 特性]
在元素中 Pattern ,所有 IdMatch 和 Match 元素都使用隐式 AND 运算符联接。 换句话说,在满足模式之前,必须满足所有匹配项。
可以通过使用 Any 元素对元素进行分组 Match 来创建更灵活的匹配逻辑。 例如,可以使用 Any 元素来匹配其子 Match 元素的所有、无或确切的子元素子集。
元素 Any 具有可选的 minMatches 和 maxMatches 属性,可用于定义在匹配模式之前必须满足多少个子 Match 元素。 这些属性定义元素数Match,而不是为匹配项找到的证据实例数。 若要定义特定匹配项的最小实例数(例如列表中的两个Match关键字),请使用 minCount 元素的 属性 (如上) 所示。
至少匹配一个 Match 子元素
若要仅需要最少数量的 Match 元素,可以使用 minMatches 属性。 实际上,这些 Match 元素与隐式 OR 运算符联接。 如果从任一列表中找到美国格式的日期或关键字 (keyword) ,则满足此Any元素。
<Any minMatches="1" >
<Match idRef="Func_us_date" />
<Match idRef="Keyword_employee" />
<Match idRef="Keyword_badge" />
</Any>
匹配确切的一部分 Match 子元素
若要需要确切数量的Match元素,请将 和 maxMatches 设置为minMatches相同的值。 仅当正好找到一个日期或关键字 (keyword) 时,才会满足此Any元素。 如果还有其他匹配项,则模式不匹配。
<Any minMatches="1" maxMatches="1" >
<Match idRef="Func_us_date" />
<Match idRef="Keyword_employee" />
<Match idRef="Keyword_badge" />
</Any>
匹配任何子级“Match”元素
如果要要求缺少特定证据才能满足某个模式,可以将 minMatches 和 maxMatches 都设置为 0。 如果你有一个关键字 (keyword) 列表或其他可能指示误报的证据,这将很有用。
例如,员工 ID 实体查找关键字 (keyword) “卡”,因为它可能引用“ID 卡”。 但是,如果卡仅出现在短语“信用卡”中,则此内容中的“卡”不太可能表示“ID 卡”。 因此,可以将“信用卡”作为关键字 (keyword) 添加到要从满足模式的术语列表中。
<Any minMatches="0" maxMatches="0" >
<Match idRef="Keyword_false_positives_local" />
<Match idRef="Keyword_false_positives_intl" />
</Any>
匹配多个唯一术语
如果要匹配多个唯一术语,请使用 uniqueResults 参数,设置为 true,如以下示例所示:
<Pattern confidenceLevel="75">
<IdMatch idRef="Salary_Revision_terms" />
<Match idRef=" Salary_Revision_ID " minCount="3" uniqueResults="true" />
</Pattern>
在此示例中,使用至少三个唯一匹配为薪资修订定义模式。
其他证据必须离实体有多近? [patternsProximity 属性]
敏感信息类型正在查找表示员工 ID 的模式,作为该模式的一部分,它还要查找确凿证据,例如关键字 (keyword) ,例如“ID”。 这种证据越接近,模式就越有可能是实际的员工 ID。 可以使用 Entity 元素的必需 patternsProximity 属性确定模式中其他证据必须与实体的接近程度。
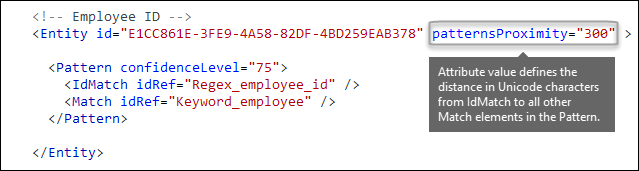
对于实体中的每个模式,patternsProximity 属性值定义与 IdMatch 位置) 为该模式指定的所有其他匹配项的 unicode 字符 (距离。 邻近感应窗口通过 IdMatch 位置锚定,窗口扩展到 IdMatch 的左右。
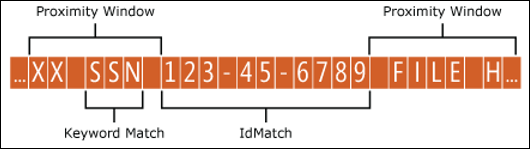
下面的示例说明了邻近度窗口如何影响模式匹配,其中员工 ID 自定义实体的 IdMatch 元素需要至少一个关键字 (keyword) 或日期的证实匹配。 只有 ID1 匹配,因为对于 ID2 和 ID3,在邻近窗口中找不到或仅找到部分确凿证据。
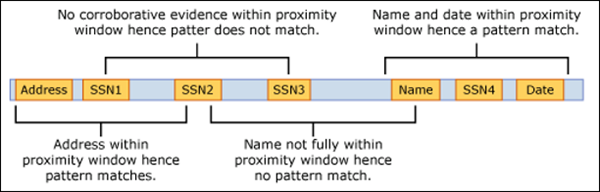
对于电子邮件,邮件正文和每个附件被视为单独的项目。 这意味着邻近度窗口不会超出每个项的末尾。 对于 (附件或正文) 的每个项,idMatch 和确证证据都需要驻留在该项目中。
不同模式的正确置信度是多少? [confidenceLevel 属性,recommendedConfidence 属性]
模式所需的证据越多,你就越有信心在模式匹配时识别出实际实体 ((例如员工 ID) )。 例如,与只需要 9 位 ID 号的模式相比,你对需要 9 位 ID 号、雇用日期和关键字 (keyword) 的模式更有信心。
Pattern 元素具有必需的 confidenceLevel 属性。 可以将 confidenceLevel 的值 (65/75/85 之间的值,该值指示低/中/高置信度) 作为实体中每个模式的唯一 ID。 上传自定义敏感信息类型并创建策略后,可在创建的规则的条件中引用这些可信度级别。

除每个模式的 confidenceLevel 外,Entity 还有一个 recommendedConfidence 属性。 可将推荐的可信度属性视为规则的默认可信度级别。 在策略中创建规则时,如果未指定要使用的规则的置信度级别,该规则将根据建议的实体置信度级别进行匹配。 请注意,对于规则包中的每个实体 ID,recommendedConfidence 属性是必需的,如果缺少,则无法保存使用敏感信息类型的策略。
是否要在合规性门户的 UI 中支持其他语言? [LocalizedStrings 元素]
如果合规性团队使用Microsoft Purview 合规门户在不同区域设置和不同语言中创建策略,则可以提供自定义敏感信息类型的名称和说明的本地化版本。 若符合性团队使用支持语言的 Microsoft 365,则 UI 中会出现本地化的名称。
Rules 元素必须包含 LocalizedStrings 元素,该元素包含引用自定义实体 GUID 的 Resource 元素。 反过来,每个 Resource 元素包含一个或多个 Name 和 Description 元素,每个元素都使用 langcode 特性为特定语言提供本地化字符串。

请注意,本地化字符串只能用于决定自定义敏感信息类型在合规中心的 UI 中的显示方式。 不能使用本地化字符串来提供不同版本的本地化关键字列表或正则表达式。
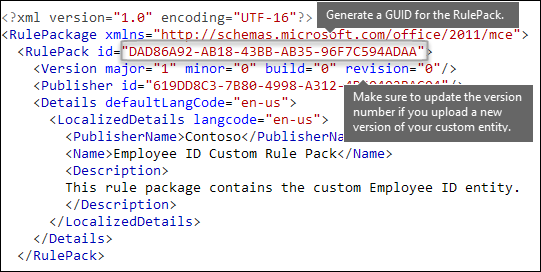
其他规则包标记 [RulePack GUID]
最后,每个 RulePackage 的开头都包含一些需要填写的常规信息。 可以使用以下标记作为模板,并替换 “ 。 . 包含你自己的信息的占位符。
最重要的是,需要为 RulePack 生成 GUID。 之前,你为实体生成了 GUID;这是 RulePack 的第二个 GUID。 有几种方法可生成 GUID,可在 PowerShell 中通过键入 [guid]::NewGuid() 轻松生成。
Version 元素也很重要。 首次上传规则包时,Microsoft 365 会记下版本号。 稍后,如果更新规则包并上传新版本,请确保更新版本号,否则 Microsoft 365 不会部署规则包。
<?xml version="1.0" encoding="utf-16"?>
<RulePackage xmlns="http://schemas.microsoft.com/office/2011/mce">
<RulePack id=". . .">
<Version major="1" minor="0" build="0" revision="0" />
<Publisher id=". . ." />
<Details defaultLangCode=". . .">
<LocalizedDetails langcode=" . . . ">
<PublisherName>. . .</PublisherName>
<Name>. . .</Name>
<Description>. . .</Description>
</LocalizedDetails>
</Details>
</RulePack>
<Rules>
. . .
</Rules>
</RulePackage>
完成后,RulePack 元素应如下所示。
验证
Microsoft 365 将常用 SCT 的函数处理器公开为验证程序。 下面是它们的列表。
当前可用的验证程序列表
Func_credit_cardFunc_ssnFunc_unformatted_ssnFunc_randomized_formatted_ssnFunc_randomized_unformatted_ssnFunc_aba_routingFunc_south_africa_identification_numberFunc_brazil_cpfFunc_ibanFunc_brazil_cnpjFunc_swedish_national_identifierFunc_india_aadhaarFunc_uk_nhs_numberFunc_Turkish_National_IdFunc_australian_tax_file_numberFunc_usa_uk_passportFunc_canadian_sinFunc_formatted_itinFunc_unformatted_itinFunc_dea_number_v2Func_dea_numberFunc_japanese_my_number_personalFunc_japanese_my_number_corporate
这使你能够定义自己的正则表达式并对其进行验证。 若要使用验证程序,请定义自己的正则表达式,并使用 Validator 属性添加所选的函数处理器。 定义后,可以在 SIT 中使用此正则表达式。
在下面的示例中,为信用卡定义了正则表达式 - Regex_credit_card_AdditionalDelimiters,然后使用Func_credit_card作为验证程序,使用校验和函数对信用卡进行验证。
<Regex id="Regex_credit_card_AdditionalDelimiters" validators="Func_credit_card"> (?:^|[\s,;\:\(\)\[\]"'])([0-9]{4}[ -_][0-9]{4}[ -_][0-9]{4}[ -_][0-9]{4})(?:$|[\s,;\:\(\)\[\]"'])</Regex>
<Entity id="675634eb7-edc8-4019-85dd-5a5c1f2bb085" patternsProximity="300" recommendedConfidence="85">
<Pattern confidenceLevel="85">
<IdMatch idRef="Regex_credit_card_AdditionalDelimiters" />
<Any minMatches="1">
<Match idRef="Keyword_cc_verification" />
<Match idRef="Keyword_cc_name" />
<Match idRef="Func_expiration_date" />
</Any>
</Pattern>
</Entity>
Microsoft 365 提供两个泛型验证程序
校验和验证程序
在此示例中,定义了员工 ID 的校验和验证器来验证 EmployeeID 的正则表达式。
<Validators id="EmployeeIDChecksumValidator">
<Validator type="Checksum">
<Param name="Weights">2, 2, 2, 2, 2, 1</Param>
<Param name="Mod">28</Param>
<Param name="CheckDigit">2</Param> <!-- Check 2nd digit -->
<Param name="AllowAlphabets">1</Param> <!— 0 if no Alphabets -->
</Validator>
</Validators>
<Regex id="Regex_EmployeeID" validators="ChecksumValidator">(\d{5}[A-Z])</Regex>
<Entity id="675634eb7-edc8-4019-85dd-5a5c1f2bb085" patternsProximity="300" recommendedConfidence="85">
<Pattern confidenceLevel="85">
<IdMatch idRef="Regex_EmployeeID"/>
</Pattern>
</Entity>
日期验证程序
在此示例中,为正则表达式部分定义了日期验证器,该部分为 date。
<Validators id="date_validator_1"> <Validator type="DateSimple"> <Param name="Pattern">DDMMYYYY</Param> <!—supported patterns DDMMYYYY, MMDDYYYY, YYYYDDMM, YYYYMMDD, DDMMYYYY, DDMMYY, MMDDYY, YYDDMM, YYMMDD --> </Validator> </Validators>
<Regex id="date_regex_1" validators="date_validator_1">\d{8}</Regex>
针对 Exchange Online 的变化
以前,你可能已使用过 Exchange Online PowerShell 为 DLP 导入自定义敏感信息类型。 现在,可以在 Exchange 管理中心]“https://go.microsoft.com/fwlink/p/?linkid=2059104") 和Microsoft Purview 合规门户中使用自定义敏感信息类型。 作为此改进的一部分,应使用安全性 & 符合性 PowerShell 导入自定义敏感信息类型,不能再从 PowerShell Exchange Online导入它们。 自定义敏感信息类型将像往常一样正常工作,但是,在合规中心进行的更改可能需要至多一小时才会出现在 Exchange 管理中心。
请注意,在合规中心中,可以使用New-DlpSensitiveInformationTypeRulePackage cmdlet 上载规则包。 (以前,在 Exchange 管理中心,你使用了 ClassificationRuleCollection' cmdlet.)
上传规则包
若要上传规则包,请按照以下步骤操作:
将文件另存为采用 Unicode 编码的 .xml 文件。
使用以下语法:
New-DlpSensitiveInformationTypeRulePackage -FileData ([System.IO.File]::ReadAllBytes('PathToUnicodeXMLFile'))本示例从 C:\My Documents 上传名为 MyNewRulePack.xml 的 Unicode XML 文件。
New-DlpSensitiveInformationTypeRulePackage -FileData ([System.IO.File]::ReadAllBytes('C:\My Documents\MyNewRulePack.xml'))有关语法和参数的详细信息,请参阅 New-DlpSensitiveInformationTypeRulePackage。
注意
支持的规则包数量最多为10个,但每个包可以包含多个敏感信息类型的定义。
若要验证是否已成功新建敏感信息类型,请按以下任一步骤操作:
运行 Get-DlpSensitiveInformationTypeRulePackage cmdlet,验证新规则包是否已列出:
Get-DlpSensitiveInformationTypeRulePackageRun the Get-DlpSensitiveInformationType,验证敏感信息类型是否已列出:
Get-DlpSensitiveInformationType对于自定义敏感信息类型,Publisher 属性值将不是 Microsoft Corporation。
将 <Name> 替换为敏感信息类型的 Name 值(例如,员工 ID),然后运行 Get-DlpSensitiveInformationType cmdlet:
Get-DlpSensitiveInformationType -Identity "<Name>"
要注意的潜在验证问题
上传规则包 XML 文件时,系统会验证 XML 并检查已知的错误模式和明显的性能问题。 下面是验证检查的一些已知问题( 正则表达式):
正则表达式中的 Lookbehind 断言应仅为固定长度。 可变长度断言将导致错误。
例如,
"(?<=^|\s|_)"不会通过验证。 第一个模式 (^) 长度为零,而接下来的两个模式 (\s和_) 的长度为 1。 编写此正则表达式的另一种方法是"(?:^|(?<=\s|_))"。不能以与所有匹配项匹配的交流发电机
|开头或结尾,因为它被视为空匹配项。例如,
|a或b|不会通过验证。不能以模式开头
.{0,m}或结尾,该模式没有功能用途,只会损害性能。例如,
.{0,50}ASDF或ASDF.{0,50}不会通过验证。组中不能有
.{0,m}或.{1,m},组中不能有.\*或.+。例如,
(.{0,50000})不会通过验证。不能在组中具有
{0,m}或{1,m}重复器的任何字符。例如,
(a\*)不会通过验证。不能以
.{1,m}开头或结尾;请改用.。例如,
.{1,m}asdf不会通过验证。 请改用.asdf。组上不能有无限的中继器 (,例如
*或+) 。例如,
(xx)\*和(xx)+不会通过验证。关键字最多可包含 50 个字符。 如果组中的关键字超过此字符数,建议将术语组创建为关键字字典,并在 XML 结构中引用关键字字典的 GUID 作为文件中的 Match 或 idMatch 实体的一部分。
每个自定义敏感信息类型最多可以包含 2048 个关键字。
单个租户中关键字字典的最大大小压缩为 480 KB,以符合 AD 架构限制。 创建自定义敏感信息类型时,请尽情地根据需要多次引用同一词典。 请先在敏感信息类型中创建自定义关键字列表,然后如果关键字列表中有超过 2048 个关键字或某个关键字长度超过 50 个字符时,请使用关键字词典。
租户中最多允许 50 种基于关键字字典的敏感信息类型。
确保每个 Entity 元素都包含一个 recommendedConfidence 属性。
使用 PowerShell Cmdlet 时,反序列化数据的最大返回大小约为 1 兆字节。 这会影响规则包 XML 文件的大小。 将所上传文件的建议上限设置为 770 KB,以确保结果一致,处理时不会出错。
XML 结构不需要设置空格、制表符或回车符/换行符等格式。 在针对上传空间进行优化时,请注意这一点。 诸如 Microsoft Visual Code 等工具提供连接线功能来压缩 XML 文件。
如果自定义敏感信息类型存在可能会影响性能的问题,便无法上传,且可能会导致以下错误消息之一出现:
Generic quantifiers which match more content than expected (e.g., '+', '*')Lookaround assertionsComplex grouping in conjunction with general quantifiers
对内容重新爬网以标识敏感信息
Microsoft 365 使用搜索爬取器识别网站内容中的敏感信息并进行分类。 SharePoint Online 和 OneDrive for Business 网站中的内容更新时会自动重新爬取内容。 但若要确定所有现有内容中的新自定义类型的敏感信息,必须重新爬取该内容。
在 Microsoft 365 中,无法手动请求整个组织的重新爬网,但可以手动请求网站集、列表或库的重新爬网。 有关详细信息,请参阅 手动请求对网站、库或列表进行爬网和重新编制索引。
参考:规则包 XML 架构定义
可复制此标记,并将它另存为 XSD 文件,以用来验证规则包 XML 文件。
<?xml version="1.0" encoding="utf-8"?>
<xs:schema xmlns:mce="http://schemas.microsoft.com/office/2011/mce"
targetNamespace="http://schemas.microsoft.com/office/2011/mce"
xmlns:xs="https://www.w3.org/2001/XMLSchema"
elementFormDefault="qualified"
attributeFormDefault="unqualified"
id="RulePackageSchema">
<!-- Use include if this schema has the same target namespace as the schema being referenced, otherwise use import -->
<xs:element name="RulePackage" type="mce:RulePackageType"/>
<xs:simpleType name="LangType">
<xs:union memberTypes="xs:language">
<xs:simpleType>
<xs:restriction base="xs:string">
<xs:enumeration value=""/>
</xs:restriction>
</xs:simpleType>
</xs:union>
</xs:simpleType>
<xs:simpleType name="GuidType" final="#all">
<xs:restriction base="xs:token">
<xs:pattern value="[0-9a-fA-F]{8}\-([0-9a-fA-F]{4}\-){3}[0-9a-fA-F]{12}"/>
</xs:restriction>
</xs:simpleType>
<xs:complexType name="RulePackageType">
<xs:sequence>
<xs:element name="RulePack" type="mce:RulePackType"/>
<xs:element name="Rules" type="mce:RulesType">
<xs:key name="UniqueRuleId">
<xs:selector xpath="mce:Entity|mce:Affinity|mce:Version/mce:Entity|mce:Version/mce:Affinity"/>
<xs:field xpath="@id"/>
</xs:key>
<xs:key name="UniqueProcessorId">
<xs:selector xpath="mce:Regex|mce:Keyword|mce:Fingerprint"></xs:selector>
<xs:field xpath="@id"/>
</xs:key>
<xs:key name="UniqueResourceIdRef">
<xs:selector xpath="mce:LocalizedStrings/mce:Resource"/>
<xs:field xpath="@idRef"/>
</xs:key>
<xs:keyref name="ReferencedRuleMustExist" refer="mce:UniqueRuleId">
<xs:selector xpath="mce:LocalizedStrings/mce:Resource"/>
<xs:field xpath="@idRef"/>
</xs:keyref>
<xs:keyref name="RuleMustHaveResource" refer="mce:UniqueResourceIdRef">
<xs:selector xpath="mce:Entity|mce:Affinity|mce:Version/mce:Entity|mce:Version/mce:Affinity"/>
<xs:field xpath="@id"/>
</xs:keyref>
</xs:element>
</xs:sequence>
</xs:complexType>
<xs:complexType name="RulePackType">
<xs:sequence>
<xs:element name="Version" type="mce:VersionType"/>
<xs:element name="Publisher" type="mce:PublisherType"/>
<xs:element name="Details" type="mce:DetailsType">
<xs:key name="UniqueLangCodeInLocalizedDetails">
<xs:selector xpath="mce:LocalizedDetails"/>
<xs:field xpath="@langcode"/>
</xs:key>
<xs:keyref name="DefaultLangCodeMustExist" refer="mce:UniqueLangCodeInLocalizedDetails">
<xs:selector xpath="."/>
<xs:field xpath="@defaultLangCode"/>
</xs:keyref>
</xs:element>
<xs:element name="Encryption" type="mce:EncryptionType" minOccurs="0" maxOccurs="1"/>
</xs:sequence>
<xs:attribute name="id" type="mce:GuidType" use="required"/>
</xs:complexType>
<xs:complexType name="VersionType">
<xs:attribute name="major" type="xs:unsignedShort" use="required"/>
<xs:attribute name="minor" type="xs:unsignedShort" use="required"/>
<xs:attribute name="build" type="xs:unsignedShort" use="required"/>
<xs:attribute name="revision" type="xs:unsignedShort" use="required"/>
</xs:complexType>
<xs:complexType name="PublisherType">
<xs:attribute name="id" type="mce:GuidType" use="required"/>
</xs:complexType>
<xs:complexType name="LocalizedDetailsType">
<xs:sequence>
<xs:element name="PublisherName" type="mce:NameType"/>
<xs:element name="Name" type="mce:RulePackNameType"/>
<xs:element name="Description" type="mce:OptionalNameType"/>
</xs:sequence>
<xs:attribute name="langcode" type="mce:LangType" use="required"/>
</xs:complexType>
<xs:complexType name="DetailsType">
<xs:sequence>
<xs:element name="LocalizedDetails" type="mce:LocalizedDetailsType" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute name="defaultLangCode" type="mce:LangType" use="required"/>
</xs:complexType>
<xs:complexType name="EncryptionType">
<xs:sequence>
<xs:element name="Key" type="xs:normalizedString"/>
<xs:element name="IV" type="xs:normalizedString"/>
</xs:sequence>
</xs:complexType>
<xs:simpleType name="RulePackNameType">
<xs:restriction base="xs:token">
<xs:minLength value="1"/>
<xs:maxLength value="64"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="NameType">
<xs:restriction base="xs:normalizedString">
<xs:minLength value="1"/>
<xs:maxLength value="256"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="OptionalNameType">
<xs:restriction base="xs:normalizedString">
<xs:minLength value="0"/>
<xs:maxLength value="256"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="RestrictedTermType">
<xs:restriction base="xs:string">
<xs:minLength value="1"/>
<xs:maxLength value="100"/>
</xs:restriction>
</xs:simpleType>
<xs:complexType name="RulesType">
<xs:sequence>
<xs:choice maxOccurs="unbounded">
<xs:element name="Entity" type="mce:EntityType"/>
<xs:element name="Affinity" type="mce:AffinityType"/>
<xs:element name="Version" type="mce:VersionedRuleType"/>
</xs:choice>
<xs:choice minOccurs="0" maxOccurs="unbounded">
<xs:element name="Regex" type="mce:RegexType"/>
<xs:element name="Keyword" type="mce:KeywordType"/>
<xs:element name="Fingerprint" type="mce:FingerprintType"/>
<xs:element name="ExtendedKeyword" type="mce:ExtendedKeywordType"/>
</xs:choice>
<xs:element name="LocalizedStrings" type="mce:LocalizedStringsType"/>
</xs:sequence>
</xs:complexType>
<xs:complexType name="EntityType">
<xs:sequence>
<xs:element name="Pattern" type="mce:PatternType" maxOccurs="unbounded"/>
<xs:element name="Version" type="mce:VersionedPatternType" minOccurs="0" maxOccurs="unbounded" />
</xs:sequence>
<xs:attribute name="id" type="mce:GuidType" use="required"/>
<xs:attribute name="patternsProximity" type="mce:ProximityType" use="required"/>
<xs:attribute name="recommendedConfidence" type="mce:ProbabilityType"/>
<xs:attribute name="workload" type="mce:WorkloadType"/>
</xs:complexType>
<xs:complexType name="PatternType">
<xs:sequence>
<xs:element name="IdMatch" type="mce:IdMatchType"/>
<xs:choice minOccurs="0" maxOccurs="unbounded">
<xs:element name="Match" type="mce:MatchType"/>
<xs:element name="Any" type="mce:AnyType"/>
</xs:choice>
</xs:sequence>
<xs:attribute name="confidenceLevel" type="mce:ProbabilityType" use="required"/>
</xs:complexType>
<xs:complexType name="AffinityType">
<xs:sequence>
<xs:element name="Evidence" type="mce:EvidenceType" maxOccurs="unbounded"/>
<xs:element name="Version" type="mce:VersionedEvidenceType" minOccurs="0" maxOccurs="unbounded" />
</xs:sequence>
<xs:attribute name="id" type="mce:GuidType" use="required"/>
<xs:attribute name="evidencesProximity" type="mce:ProximityType" use="required"/>
<xs:attribute name="thresholdConfidenceLevel" type="mce:ProbabilityType" use="required"/>
<xs:attribute name="workload" type="mce:WorkloadType"/>
</xs:complexType>
<xs:complexType name="EvidenceType">
<xs:sequence>
<xs:choice maxOccurs="unbounded">
<xs:element name="Match" type="mce:MatchType"/>
<xs:element name="Any" type="mce:AnyType"/>
</xs:choice>
</xs:sequence>
<xs:attribute name="confidenceLevel" type="mce:ProbabilityType" use="required"/>
</xs:complexType>
<xs:complexType name="IdMatchType">
<xs:attribute name="idRef" type="xs:string" use="required"/>
</xs:complexType>
<xs:complexType name="MatchType">
<xs:attribute name="idRef" type="xs:string" use="required"/>
<xs:attribute name="minCount" type="xs:positiveInteger" use="optional"/>
<xs:attribute name="uniqueResults" type="xs:boolean" use="optional"/>
</xs:complexType>
<xs:complexType name="AnyType">
<xs:sequence>
<xs:choice maxOccurs="unbounded">
<xs:element name="Match" type="mce:MatchType"/>
<xs:element name="Any" type="mce:AnyType"/>
</xs:choice>
</xs:sequence>
<xs:attribute name="minMatches" type="xs:nonNegativeInteger" default="1"/>
<xs:attribute name="maxMatches" type="xs:nonNegativeInteger" use="optional"/>
</xs:complexType>
<xs:simpleType name="ProximityType">
<xs:union>
<xs:simpleType>
<xs:restriction base='xs:string'>
<xs:enumeration value="unlimited"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType>
<xs:restriction base="xs:positiveInteger">
<xs:minInclusive value="1"/>
</xs:restriction>
</xs:simpleType>
</xs:union>
</xs:simpleType>
<xs:simpleType name="ProbabilityType">
<xs:restriction base="xs:integer">
<xs:minInclusive value="1"/>
<xs:maxInclusive value="100"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="WorkloadType">
<xs:restriction base="xs:string">
<xs:enumeration value="Exchange"/>
<xs:enumeration value="Outlook"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="EngineVersionType">
<xs:restriction base="xs:token">
<xs:pattern value="^\d{2}\.01?\.\d{3,4}\.\d{1,3}$"/>
</xs:restriction>
</xs:simpleType>
<xs:complexType name="VersionedRuleType">
<xs:choice maxOccurs="unbounded">
<xs:element name="Entity" type="mce:EntityType"/>
<xs:element name="Affinity" type="mce:AffinityType"/>
</xs:choice>
<xs:attribute name="minEngineVersion" type="mce:EngineVersionType" use="required" />
</xs:complexType>
<xs:complexType name="VersionedPatternType">
<xs:sequence>
<xs:element name="Pattern" type="mce:PatternType" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute name="minEngineVersion" type="mce:EngineVersionType" use="required" />
</xs:complexType>
<xs:complexType name="VersionedEvidenceType">
<xs:sequence>
<xs:element name="Evidence" type="mce:EvidenceType" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute name="minEngineVersion" type="mce:EngineVersionType" use="required" />
</xs:complexType>
<xs:simpleType name="FingerprintValueType">
<xs:restriction base="xs:string">
<xs:minLength value="2732"/>
<xs:maxLength value="2732"/>
</xs:restriction>
</xs:simpleType>
<xs:complexType name="FingerprintType">
<xs:simpleContent>
<xs:extension base="mce:FingerprintValueType">
<xs:attribute name="id" type="xs:token" use="required"/>
<xs:attribute name="threshold" type="mce:ProbabilityType" use="required"/>
<xs:attribute name="shingleCount" type="xs:positiveInteger" use="required"/>
<xs:attribute name="description" type="xs:string" use="optional"/>
</xs:extension>
</xs:simpleContent>
</xs:complexType>
<xs:complexType name="RegexType">
<xs:simpleContent>
<xs:extension base="xs:string">
<xs:attribute name="id" type="xs:token" use="required"/>
</xs:extension>
</xs:simpleContent>
</xs:complexType>
<xs:complexType name="KeywordType">
<xs:sequence>
<xs:element name="Group" type="mce:GroupType" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute name="id" type="xs:token" use="required"/>
</xs:complexType>
<xs:complexType name="GroupType">
<xs:sequence>
<xs:choice>
<xs:element name="Term" type="mce:TermType" maxOccurs="unbounded"/>
</xs:choice>
</xs:sequence>
<xs:attribute name="matchStyle" default="word">
<xs:simpleType>
<xs:restriction base="xs:NMTOKEN">
<xs:enumeration value="word"/>
<xs:enumeration value="string"/>
</xs:restriction>
</xs:simpleType>
</xs:attribute>
</xs:complexType>
<xs:complexType name="TermType">
<xs:simpleContent>
<xs:extension base="mce:RestrictedTermType">
<xs:attribute name="caseSensitive" type="xs:boolean" default="false"/>
</xs:extension>
</xs:simpleContent>
</xs:complexType>
<xs:complexType name="ExtendedKeywordType">
<xs:simpleContent>
<xs:extension base="xs:string">
<xs:attribute name="id" type="xs:token" use="required"/>
</xs:extension>
</xs:simpleContent>
</xs:complexType>
<xs:complexType name="LocalizedStringsType">
<xs:sequence>
<xs:element name="Resource" type="mce:ResourceType" maxOccurs="unbounded">
<xs:key name="UniqueLangCodeUsedInNamePerResource">
<xs:selector xpath="mce:Name"/>
<xs:field xpath="@langcode"/>
</xs:key>
<xs:key name="UniqueLangCodeUsedInDescriptionPerResource">
<xs:selector xpath="mce:Description"/>
<xs:field xpath="@langcode"/>
</xs:key>
</xs:element>
</xs:sequence>
</xs:complexType>
<xs:complexType name="ResourceType">
<xs:sequence>
<xs:element name="Name" type="mce:ResourceNameType" maxOccurs="unbounded"/>
<xs:element name="Description" type="mce:DescriptionType" minOccurs="0" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute name="idRef" type="mce:GuidType" use="required"/>
</xs:complexType>
<xs:complexType name="ResourceNameType">
<xs:simpleContent>
<xs:extension base="xs:string">
<xs:attribute name="default" type="xs:boolean" default="false"/>
<xs:attribute name="langcode" type="mce:LangType" use="required"/>
</xs:extension>
</xs:simpleContent>
</xs:complexType>
<xs:complexType name="DescriptionType">
<xs:simpleContent>
<xs:extension base="xs:string">
<xs:attribute name="default" type="xs:boolean" default="false"/>
<xs:attribute name="langcode" type="mce:LangType" use="required"/>
</xs:extension>
</xs:simpleContent>
</xs:complexType>
</xs:schema>
更多信息
反馈
即将发布:在整个 2024 年,我们将逐步淘汰作为内容反馈机制的“GitHub 问题”,并将其取代为新的反馈系统。 有关详细信息,请参阅:https://aka.ms/ContentUserFeedback。
提交和查看相关反馈