分布式可用性组
适用于:![]() SQL Server
SQL Server
分布式可用性组 (AG) 是一种特殊类型的可用性组,横跨两个独立的可用性组。 分布式可用性组从 SQL Server 2016 开始提供。
本文介绍分布式可用性组功能。 若要配置分布式可用性组,请参阅配置分布式可用性组。
概述
分布式可用性组是一种特殊类型的可用性组,它跨两个单独的可用性组。 加入分布式可用性组的可用性组无需处于同一位置。 它们可以是物理也可以是虚拟的,可以在本地、公有云中或支持可用性组部署的任何位置。 这包括跨域甚至跨平台,例如一个可用性组托管在 Linux,一个托管在 Windows 上。 只要两个可用性组可以进行通信,就可以使用它们配置分布式可用性组。
传统可用性组在 Windows Server 故障转移群集 (WSFC) 上或在 Linux 的 Pacemaker 上配置了资源。 分布式可用性组不会在基础群集(WSFC 或 Pacemaker)中配置任何内容。 有关它的所有内容都保留在 SQL Server 中。 若要了解如何查看分布式可用性组的信息,请参阅查看分布式可用性组信息。
分布式可用性组要求基础可用性组具有侦听器。 在创建分布式可用性组时,通过 ENDPOINT_URL 参数为其指定已配置的侦听器,而不是像传统可用性组那样,为独立实例提供基础服务器名称(若是 SQL Server 故障转移群集实例 [FCI],则提供与网络名称资源相关联的值)。 尽管分布式可用性组的每个基础可用性组都具有侦听器,但分布式可用性组不具有侦听器。
下图显示了分布式可用性组的大致视图,该组跨两个可用性组(AG 1 和 AG 2),后者分别配置在各自的 WSFC 上。 分布式可用性组总共有四个副本,每个可用性组中两个。 每个可用性组可支持最大数量的副本,因此分布式可用性组最多可有 18 个副本。

可以在分布式可用性组中将数据移动配置为同步或异步。 但是,与传统可用性组相比,分布式可用性组中的数据移动略有不同。 尽管每个可用性组都具有主要副本,但只有一个数据库副本加入可以接受插入、更新和删除的分布式可用性组。 如下图所示,AG 1 为主要可用性组。 其主要副本将事务发送到 AG 1 的次要副本和 AG 2 的主要副本。 AG 2 的主要副本也称为转发器。 转发器是分布式可用性组中的次要可用性组中的主要副本。 转发器从主要可用性组中的主要副本接收事务,并将其转发到它自己的可用性组中的次要副本。 然后,转发器将更新 AG 2 的次要副本。
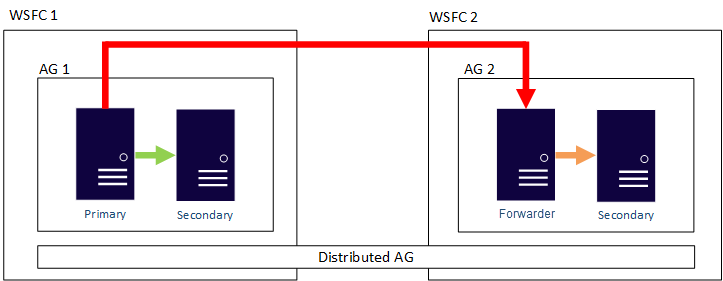
使 AG 2 的主要副本接受插入、更新和删除的唯一方法是从 AG 1 手动故障转移分布式可用性组。 在前面的图中,因为 AG 1 包含数据库的可写入副本,所以发出故障转移将使 AG 2 成为可以处理插入、更新和删除的可用性组。 有关如何将一个分布式可用性组故障转移到另一个分布式可用性组的信息,请参阅故障转移到次要可用性组。
注意
SQL Server 2016 中的分布式可用性组支持通过使用选项 FORCE_FAILOVER_ALLOW_DATA_LOSS 仅从一个可用性组故障转移到另一个可用性组。
注意
通过分布式可用性组使用事务复制时,转接副本无法配置为发布服务器。
版本和版次要求
SQL Server 2017 或更高版本中的分布式可用性组可以混合同一分布式可用性组中的 SQL Server 的主版本。 包含读/写主要副本的 AG 可以是与加入分布式 AG 的其他 AG 相同的版本或更低版本。 其他 AG 可以是相同版本或更高版本。 此方案面向升级和迁移方案。 例如,如果包含读/写主要副本的 AG 是 SQL Server 2016,但你希望升级/迁移到 SQL Server 2017 或更高版本,则可以使用 SQL Server 2017 配置加入分布式 AG 的其他 AG。
由于 SQL Server 2012 或 2014 中不存在分布式可用性组功能,因此通过这些版本创建的可用性组不能加入分布式可用性组。
因为存在两个单独的可用性组,因此在加入分布式可用性组的副本上安装服务包或累积更新的过程与传统可用性组略有不同:
通过更新分布式可用性组中第二个可用性组的副本开始此操作。
修补分布式可用性组中主要可用性组的副本。
与标准可用性组一样,将主要可用性组故障转移到其副本(而不是次要可用性组的主要副本),并对其进行修补。 如果除主要可用性组外不存在副本,则需要手动故障转移到第二个可用性组。
Windows Server 版本和分布式可用性组
分布式可用性组跨多个可用性组,每个组分别位于其自己的基础 WSFC 上,分布式可用性组是仅限 SQL Server 的构造。 这意味着容纳各个可用性组的 WSFC 可具有不同主版本的 Windows Server。 如前一部分中所述,SQL Server 的主版本必须相同。 与初始图非常相似,下图显示 AG 1 和 AG 2 加入分布式可用性组,但每个 WSFC 是不同版本的 Windows Server。
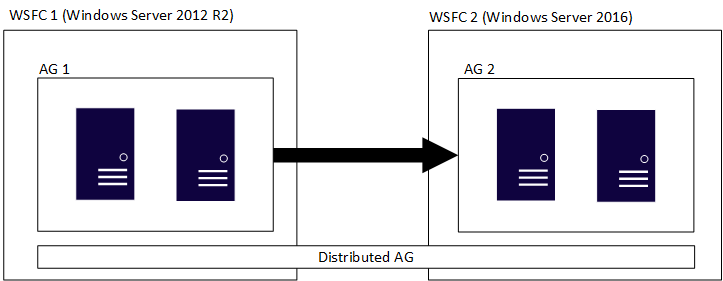
单个 WSFC 及其相应的可用性组遵循传统规则。 也就是说,它们可以加入域,也可以不加入域(Windows Server 2016 或更高版本)。 在单个分布式可用性组中合并两个不同可用性组时,存在四种情况:
- 两个 WSFC 加入同一域。
- 每个 WSFC 加入不同的域。
- 一个 WSFC 加入域,一个 WSFC 群集不加入域。
- 两个 WSFC 都不加入域。
如果两个 WSFC 加入同一域(不受信任的域),那么创建分布式可用性组时无需执行任何特殊操作。 对于未加入同一域的可用性组和 WSFC,通过证书启用分布式可用性组,方法类似于为独立于域的可用性组创建可用性组。 若要查看如何配置分布式可用性组的证书,请遵循创建独立于域的可用性组下的步骤 3-13。
对于分布式可用性组,每个基础可用性组中的主要副本必须具有彼此的证书。 如果已有未使用证书的终结点,请使用 ALTER ENDPOINT 重新配置这些终结点,以反映证书的使用。
使用方案
下面是分布式可用性组的三个主要使用方案:
灾难恢复和多站点方案
传统可用性组要求所有服务器属于同一 WSFC,因此很难跨多个数据中心。 下图显示传统多站点可用性组体系结构,包括数据流。 有一主要副本,它将事务发送到所有次要副本。 与分布式可用性组相比,这种配置在某些方面不占优势。 例如,必须在 WSFC 中实现 Active Directory(如果适用)和仲裁见证等。 此外,可能还需要考虑 WSFC 的其他方面,例如更改节点投票。

分布式可用性组可为跨多个数据中心的可用性组提供更加灵活的部署方案。 对于过去在灾难恢复等方案中使用日志传送等功能的情况,现在甚至可以使用分布式可用性组。 不过,与日志传送不同,分布式可用性组不得包含延迟的事务应用程序。 这意味着,对于错误更新或删除数据的人为过失事件,可用性组或分布式可用性组无法提供帮助。
分布式可用性组是松散耦合的;在这种情况下,这意味着它们无需单个 WSFC,并且它们由 SQL Server 维护。 WSFC 是单独进行维护的,而且最初在这两个可用性组之间异步同步,因此很容易在其他站点配置灾难恢复。 每个可用性组中的主要副本都同步其自己的次要副本。
- 分布式可用性组仅支持手动故障转移。 在切换数据中心的灾难恢复情况下,不应配置自动故障转移(除极少数例外)。
- 很可能无需为多站点或子网 WSFC 设置某些传统项或参数(如 CrossSubnetThreshold),但仍需了解数据传输的另一层的网络延迟。 不同之处在于,每个 WSFC 都维护其自身的可用性;群集并非包含 4 个节点的大型实体。 如上图所示,实际有两个单独的双节点 WSFC。
- 建议采用异步数据移动,因为此方法将用于灾难恢复目的。
- 如果在主要副本和第二个可用性组的至少一个次要副本之间配置同步数据移动,并在分布式可用性组上配置同步移动,则分布式可用性组将等待,直到所有同步副本确认它们具有数据。 如果多个分布式可用性组是菊花链 (AG1 -> AG2 -> AG3) 且设置为同步,则分布式可用性组将等待最后一个可用性组的最后一个副本更新。
Migrate
由于分布式可用性组支持两个完全不同的可用性组配置,因此它们使得灾难恢复、多站点方案和迁移方案更加容易。 无论是迁移到新的硬件还是虚拟机(本地或公有云中的 IaaS),只要过去可使用备份、复制和还原或日志传送的位置,配置分布式可用性组都允许其中发生迁移。
在保留相同 SQL Server 版本时更改或升级基础操作系统,迁移功能尤其有用。 尽管 Windows Server 2016 允许在相同硬件上从 Windows Server 2012 R2 滚动升级,但大多数用户都选择部署新的硬件或虚拟机。
若要完成迁移到新的配置,在此过程末尾,停止指向原始可用性组的所有数据流量,并将分布式可用性组更改为同步数据移动。 此操作可确保第二个可用性组的主要副本完全同步,以免出现数据丢失。 验证同步后,将分布式可用性组故障转移到次要可用性组。 有关详细信息,请参阅 故障转移到次要可用性组。
迁移后,第二个可用性组成为了新的主要可用性组,可能需要执行以下任一步骤:
- 重命名次要可用性组上的侦听器(可能删除或重命名原始主要可用性组中的一个旧侦听器),或通过原始主要可用性组中的侦听器重新创建一个侦听器,以便应用程序和用户可以访问新的配置。
- 如果无法进行重命名或重新创建,请将应用程序和用户指向第二个可用性组上的侦听器。
迁移到更高版本的 SQL Server
在迁移方案中,虽然可以配置分布式 AG 以将数据库迁移到高于源版本的 SQL Server 目标,但存在一些限制。
将分布式 AG 配置为高于源版本的 SQL Server 迁移目标时,不支持自动种子设定,因此种子设定模式必须设置为 MANUAL。 如果不禁用 AUTO-SEEDING,迁移将失败,并会看到错误 946“无法打开数据库‘DistributionAG’版本 xxx”。 将数据库升级到最新版本”。 必须将种子设定模式设置为 MANUAL,并从主 AG 手动执行源数据库的完整和事务日志备份。 然后,将其与事务日志一起手动还原到辅助 AG。 有关详细信息,请查看用于配置分布式 AG 的手动种子设定步骤,以及用于将数据库从主 AG 备份还原到辅助 AG 的脚本。
假设辅助 AG (AG2) 是迁移目标,并且版本高于主 AG (AG1),请考虑以下限制:
- 只要主 AG 的版本更低,你就不会对辅助 AG 上的任何副本数据库拥有读取访问权限。
- 在此期间,更新将继续从主 AG (AG1) 流向辅助 AG (AG2),但辅助 AG 的状态将显示为“部分正常”,辅助 AG (AG2) 的次要副本上的数据库将显示为“正在同步/恢复中”(即使 AG 同步提交也是如此)。
- 将分布式 AG 故障转移到更高版本 (AG2) 后,AG2 状态应会变为“正常”。
- 在此期间,无法故障回复到 AG1,因为它的版本更低。
- 由于 AG1 的版本较低,因此故障转移到 AG2 后,AG2 的更新不会复制到 AG1。
- 在此处,选择是否要解除原始(主)AG 授权,或者是否要升级 AG1 并维护分布式 AG。
- 如果选择解除 AG1 授权,请从分布式 AG 中删除原始主 AG,该过程将完成。
- 如果选择维护分布式 AG,请升级 AG1 的 SQL Server 版本以匹配 AG2。 升级 AG1 后,AG1 将恢复正常,分布式 AG 也将恢复正常,副本将同步,并可以进行故障回复。
横向扩展可读副本
单个分布式可用性组最多可拥有 16 个次要副本,具体视需要而定。 因此,它最多可拥有 18 个副本供读取,包括不同可用性组的两个主要副本。 此方法意味着,多个站点可实现近实时访问,以便向各应用程序报告。
与仅使用单个可用性组相比,分布式可用性组可帮助扩大只读场。 分布式可用性组可通过两种方式扩大可读副本:
- 可使用分布式可用性组中第二个可用性组的主要副本来创建另一个分布式可用性组,即使数据库未处于恢复状态。
- 还可以使用第一个可用性组的主要副本来创建另一个分布式可用性组。
换句话说,就是主要副本可以参与不同的分布式可用性组。 下图显示 AG 1 和 AG 2 均参与分布式 AG 1,而 AG 2 和 AG 3 参与分布式 AG 2。 AG 2 的主要副本(或转发器)是分布式 AG 1 的次要副本和分布式 AG 2 的主要副本。
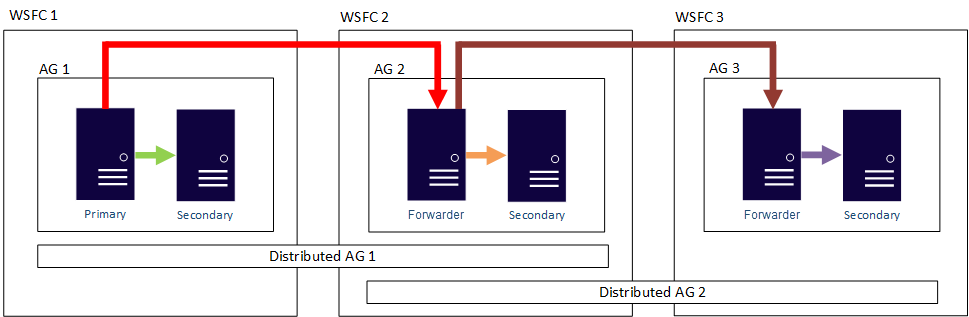
下图显示 AG 1 为两个不同分布式可用性组的主要副本:分布式 AG 1(包含 AG 1 和 AG 2)和分布式 AG 2(包含 AG 1 和 AG 3)。
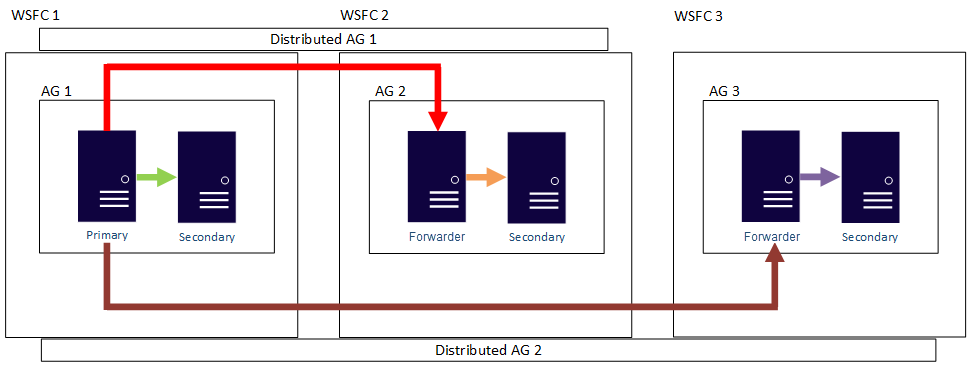
在前面两个示例中,三个可用性组中至多可以具有 27 个副本,这些副本可用于只读查询。
只读路由并不完全适用于分布式可用性组。 更具体地说,
- 只读路由可配置,且适用于分布式可用性组的主要可用性组。
- 只读路由可配置,但不用于分布式可用性组的次要可用性组。 如果使用侦听器连接到次要可用性组,则所有查询将转到次要可用性组的主要副本。 否则,将需要配置每个副本,以允许将所有连接作为次要副本并直接访问它们。 但如果故障转移之后,次要可用性组变为主要可用性组,只读路由仍适用。 在 SQL Server 2016 的更新或将来的 SQL Server 版本中,此行为可能会发生更改。
初始化辅助可用性组
分布式可用性组将自动种子设定设计为用于初始化第二个可用性组上主要副本的主要方法。 如果执行以下操作,将可在第二个可用性组的主要副本上进行完整的数据库还原:
- 通过 WITH NORECOVERY 还原数据库备份。
- 如有必要,通过 WITH NORECOVERY 还原适当的事务日志备份。
- 创建第二个可用性组,而不指定数据库名称,将 SEEDING_MODE 设置为 AUTOMATIC。
- 使用自动种子设定创建分布式可用性组。
在将第二个可用性组的主要副本添加到分布式可用性组时,将根据第一个可用性组的主数据库检查副本,且自动种子设定会将数据库捕获到源。 以下是一些注意事项:
第二个可用性组的主要副本上的
sys.dm_hadr_automatic_seeding中所示的输出将显示current_state失败,原因是“种子设定检查消息超时”。第二个可用性组的主要副本上的当前 SQL Server 错误日志将显示自动种子设定已生效,且 LSN 已同步。
第一个可用性组的主要副本上的
sys.dm_hadr_automatic_seeding中所示的输出将显示 COMPLETED 的 current_state。自动种子设定还可与分布式可用性组具有不同行为。 为在第二个副本上开始进行自动种子设定,必须在副本上发出命令
ALTER AVAILABILITY GROUP [AGName] GRANT CREATE ANY DATABASE命令。 尽管对于参与基础可用性组的任何次要副本来说,这种情况仍然适用,但第二个可用性组的主要副本已具有正确权限,允许在将自动种子设定添加到分布式可用性组后开始进行自动种子设定。
监视运行状况
分布式可用性组是仅限 SQL Server 的构造,未见于基础 WSFC。 下面的代码示例显示了两个不同的 WSFC(CLUSTER_A 和 CLUSTER_B),每个群集都有其自己的可用性组。 此处仅讨论 CLUSTER_A 中的 AG1 和 CLUSTER_B 中的 AG2。
PS C:\> Get-ClusterGroup -Cluster CLUSTER_A
Name OwnerNode State
---- --------- -----
AG1 DENNIS Online
Available Storage GLEN Offline
Cluster Group JY Online
New_RoR DENNIS Online
Old_RoR DENNIS Online
SeedingAG DENNIS Online
PS C:\> Get-ClusterGroup -Cluster CLUSTER_B
Name OwnerNode State
---- --------- -----
AG2 TOMMY Online
Available Storage JC Offline
Cluster Group JC Online
有关分布式可用性组的所有详细信息均在 SQL Server 中,具体而言,是在可用性组动态管理视图中。 目前,SQL Server Management Studio 中所示的分布式可用性组的唯一信息关于是可用性组的主副本的。 如下图中所示,在可用性组文件夹中,SQL Server Management Studio 将显示存在分布式可用性组。 该图显示 AG1 是位于该实例本地的单个可用性组(而不是分布式可用性组)的主副本。
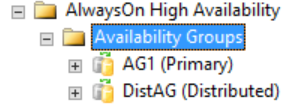
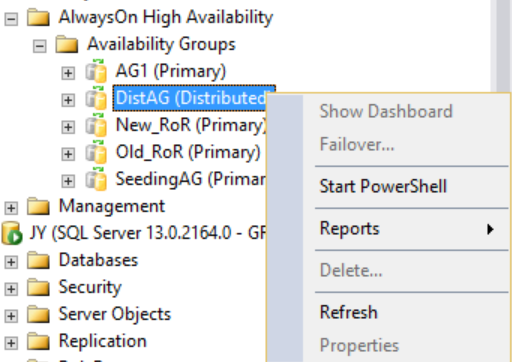
然而,如果右键单击分布式可用性组,则无选项可用(如下图所示),而展开的可用性数据库、可用性组侦听器和可用性副本文件夹均为空。 SQL Server Management Studio 16 将显示此结果,但它可能在 SQL Server Management Studio 的将来版本中发生更改。
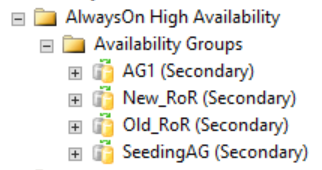
如下图中所示,次要副本在 SQL Server Management Studio 中不显示任何与分布式可用性组相关的内容。 这些可用性组名称将映射到上一个 CLUSTER_A WSFC 映像中显示的角色。
通过 DMV 列出所有可用性副本名称
使用动态管理视图时,这些概念仍然适用。 使用以下查询,可查看所有可用性组(常规和分布式)及参与其中的节点。 仅当查询参与分布式可用性组的 WSFC 中的主副本时,才显示此结果。 在名为 is_distributed 的动态管理视图 sys.availability_groups 中有一个新列,它在可用性组为分布式可用性组时为 1。 若要查看此列:
-- shows replicas associated with availability groups
SELECT
ag.[name] AS [AG Name],
ag.Is_Distributed,
ar.replica_server_name AS [Replica Name]
FROM sys.availability_groups AS ag
INNER JOIN sys.availability_replicas AS ar
ON ag.group_id = ar.group_id;
GO
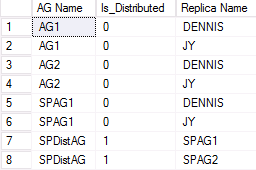
参与分布式可用性组的另一个 WSFC 的输出实例如下图所示。 SPAG1 由两个副本组成:DENNIS 和 JY。 但是,名为 SPDistAG 的分布式可用性组包含两个参与的可用性组的名称(SPAG1 和 SPAG2),而不是像传统可用性组那样包含实例的名称。
通过 DMV 列出分布式 AG 运行状况
在 SQL Server Management Studio 中,仪表板和其他区域中显示的任何状态都仅用于该可用性组内的本地同步。 若要显示分布式可用性组的运行状况,请查询动态管理视图。 下面的示例查询可扩展和优化前面的查询:
-- shows sync status of distributed AG
SELECT
ag.[name] AS [AG Name],
ag.is_distributed,
ar.replica_server_name AS [Underlying AG],
ars.role_desc AS [Role],
ars.synchronization_health_desc AS [Sync Status]
FROM sys.availability_groups AS ag
INNER JOIN sys.availability_replicas AS ar
ON ag.group_id = ar.group_id
INNER JOIN sys.dm_hadr_availability_replica_states AS ars
ON ar.replica_id = ars.replica_id
WHERE ag.is_distributed = 1;
GO

通过 DMV 查看基础性能
若要进一步扩展前面的查询,还可以通过在 sys.dm_hadr_database_replicas_states 中添加内容,通过动态管理视图查看基础性能。 动态管理视图当前仅存储第二个可用性组的相关信息。 下面的示例查询针对主要可用性组运行,可产生如下所示的示例输出:
-- shows underlying performance of distributed AG
SELECT
ag.[name] AS [Distributed AG Name],
ar.replica_server_name AS [Underlying AG],
dbs.[name] AS [Database],
ars.role_desc AS [Role],
drs.synchronization_health_desc AS [Sync Status],
drs.log_send_queue_size,
drs.log_send_rate,
drs.redo_queue_size,
drs.redo_rate
FROM sys.databases AS dbs
INNER JOIN sys.dm_hadr_database_replica_states AS drs
ON dbs.database_id = drs.database_id
INNER JOIN sys.availability_groups AS ag
ON drs.group_id = ag.group_id
INNER JOIN sys.dm_hadr_availability_replica_states AS ars
ON ars.replica_id = drs.replica_id
INNER JOIN sys.availability_replicas AS ar
ON ar.replica_id = ars.replica_id
WHERE ag.is_distributed = 1;
GO

通过 DMV 查看分布式 AG 的性能计数器
以下查询显示与特定分布式可用性组关联的性能计数器。
-- displays OS performance counters related to the distributed ag named 'distributedag'
SELECT * FROM sys.dm_os_performance_counters WHERE instance_name LIKE '%distributed%'
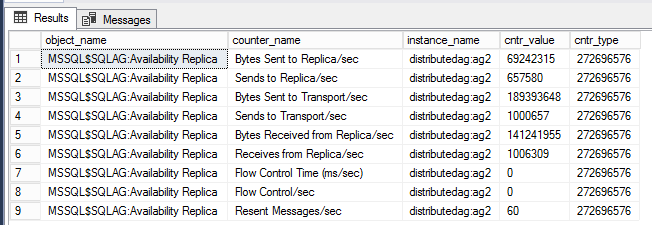
注意
LIKE 筛选器应具有分布式可用性组的名称。 在本例中,分布式可用性组的名称为“distributedag”。 更改 LIKE 修饰符以反映分布式可用性组的名称。
通过 DMV 显示 AG 和分布式 AG 的运行状况
以下查询显示有关可用性组和分布式可用性组运行状况的大量信息。 (经 Tracy Boggiano 授权重现。)
-- displays sync status, send rate, and redo rate of availability groups,
-- including distributed AG
SELECT ag.name AS [AG Name],
ag.is_distributed,
ar.replica_server_name AS [AG],
dbs.name AS [Database],
ars.role_desc,
drs.synchronization_health_desc,
drs.log_send_queue_size,
drs.log_send_rate,
drs.redo_queue_size,
drs.redo_rate,
drs.suspend_reason_desc,
drs.last_sent_time,
drs.last_received_time,
drs.last_hardened_time,
drs.last_redone_time,
drs.last_commit_time,
drs.secondary_lag_seconds
FROM sys.databases dbs
INNER JOIN sys.dm_hadr_database_replica_states drs
ON dbs.database_id = drs.database_id
INNER JOIN sys.availability_groups ag
ON drs.group_id = ag.group_id
INNER JOIN sys.dm_hadr_availability_replica_states ars
ON ars.replica_id = drs.replica_id
INNER JOIN sys.availability_replicas ar
ON ar.replica_id = ars.replica_id
--WHERE ag.is_distributed = 1
GO

通过 DMV 查看分布式 AG 的元数据
以下查询将显示有关可用性组(包括分布式可用性组)使用的终结点 URL 的信息。 (经 David Barbarin 授权重现。)
-- shows endpoint url and sync state for ag, and dag
SELECT
ag.name AS group_name,
ag.is_distributed,
ar.replica_server_name AS replica_name,
ar.endpoint_url,
ar.availability_mode_desc,
ar.failover_mode_desc,
ar.primary_role_allow_connections_desc AS allow_connections_primary,
ar.secondary_role_allow_connections_desc AS allow_connections_secondary,
ar.seeding_mode_desc AS seeding_mode
FROM sys.availability_replicas AS ar
JOIN sys.availability_groups AS ag
ON ar.group_id = ag.group_id;
GO

通过 DMV 显示种子设定的当前状态
以下查询显示有关种子设定当前状态的信息。 这对于解决副本之间的同步错误非常有用。 (经 David Barbarin 授权重现。)
-- shows current_state of seeding
SELECT ag.name AS aag_name,
ar.replica_server_name,
d.name AS database_name,
has.current_state,
has.failure_state_desc AS failure_state,
has.error_code,
has.performed_seeding,
has.start_time,
has.completion_time,
has.number_of_attempts
FROM sys.dm_hadr_automatic_seeding AS has
INNER JOIN sys.availability_groups AS ag
ON ag.group_id = has.ag_id
INNER JOIN sys.availability_replicas AS ar
ON ar.replica_id = has.ag_remote_replica_id
INNER JOIN sys.databases AS d
ON d.group_database_id = has.ag_db_id;
GO

相关内容
反馈
即将发布:在整个 2024 年,我们将逐步淘汰作为内容反馈机制的“GitHub 问题”,并将其取代为新的反馈系统。 有关详细信息,请参阅:https://aka.ms/ContentUserFeedback。
提交和查看相关反馈