使用格式化文件跳过表列 (SQL Server)
适用于:![]() SQL Server
SQL Server![]() Azure SQL 数据库
Azure SQL 数据库![]() Azure SQL 托管实例
Azure SQL 托管实例![]() Azure Synapse Analytics
Azure Synapse Analytics![]() Analytics Platform System (PDW)
Analytics Platform System (PDW)
本文描述当源数据文件中不存在该已跳过列的数据时,如何使用格式化文件跳过导入表列。 数据文件可包含比目标表中的列数更少的字段,即你可以跳过导入列,前提是目标表中满足以下两个条件中至少一个:
- 跳过的列可以为 null。
- 跳过的列具有默认值。
备注
Azure Synapse Analytics不支持此语法(包括批量插入)。 在 Azure Synapse Analytics 和其他云数据库平台集成中,通过 Azure 数据工厂中的 COPY 语句或使用 T-SQL 语句(如 COPY INTO)和 PolyBase 完成数据移动。
示例表和数据文件
本文中的示例需要一个处于 dbo 架构下的名为 myTestSkipCol 的表。 可以在示例数据库(例如 WideWorldImporters 或 AdventureWorks)或任何其他数据库中创建此表。 此表的创建方式如下所示:
USE WideWorldImporters;
GO
CREATE TABLE myTestSkipCol
(
Col1 smallint,
Col2 nvarchar(50) NULL,
Col3 nvarchar(50) not NULL
);
GO
本文中的示例还使用示例数据文件 myTestSkipCol2.dat。 虽然目标表包含三个列,但此数据文件仅包含两个字段。
1,DataForColumn3
1,DataForColumn3
1,DataForColumn3
基本步骤
可以使用非 XML 格式化文件或 XML 格式化文件跳过表列。 这两种情况都可通过两步完成:
- 使用 bcp 命令行实用工具创建默认格式化文件。
- 在文本编辑器中修改默认格式化文件。
修改后的格式化文件必须将每个现有字段映射到目标表中的相应列。 它还必须指示要跳过哪些列。
例如,若要将数据从 myTestSkipCol2.dat 批量导入 myTestSkipCol 表,则格式化文件必须将第一个数据字段映射到 Col1,跳过 Col2,并将第二个字段映射到 Col3。
选项 #1 - 使用非 XML 格式化文件
步骤 #1 - 创建默认非 XML 格式化文件
在命令提示符下运行以下 bcp 命令为 myTestSkipCol 示例表创建默认非 XML 格式化文件:
bcp WideWorldImporters..myTestSkipCol format nul -f myTestSkipCol_Default.fmt -c -T
重要
可能必须通过 -S 参数指定要连接的服务器实例的名称。 此外,可能还须通过 -U 和 -P 参数指定用户名和密码。 有关详细信息,请参阅 bcp Utility。
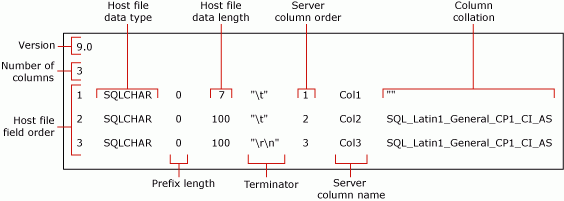
以上命令创建了一个非 XML 格式化文件, myTestSkipCol_Default.fmt。 此格式化文件称为 默认格式化文件 ,因为它是 bcp生成的格式。 默认格式化文件说明数据文件字段与表列之间的一一对应关系。
以下截图显示了此示例默认格式化文件中的值。
备注
有关格式化文件字段的详细信息,请参阅非 XML 格式化文件 (SQL Server)。
步骤 #2 - 修改非 XML 格式化文件
若要修改默认非 XML 格式化文件,有两种替代方法。 两种方法都假定数据文件中没有数据字段,并且不会有数据插入到对应的表列中。
若要跳过某个表列,可编辑默认非 XML 格式化文件并使用以下方法之一修改此文件:
选项 #1 - 删除行
跳过列的首选方法包括以下三个步骤:
- 首先,删除说明源数据文件中丢失字段的任何格式化文件行。
- 然后,减小所删除行后的每个格式化文件行的“宿主文件字段顺序”值。 这是为了使“宿主文件字段顺序”值按顺序排列(1 到 n),它反映了数据文件中各个数据字段的实际位置。
- 最后,减小“列数”字段中的值以反映数据文件中的实际字段数。
下面的示例基于 myTestSkipCol 表的默认格式化文件。 此修改过的格式化文件将第一个数据字段映射到 Col1,并跳过 Col2将第二个数据字段映射到 Col3。 已删除 Col2 的行。 第一个字段后的分隔符也已从 \t 更改为 ,。
14.0
2
1 SQLCHAR 0 7 "," 1 Col1 ""
2 SQLCHAR 0 100 "\r\n" 3 Col3 SQL_Latin1_General_CP1_CI_AS
选项 #2 - 修改行定义
若要跳过某个表列,也可以修改与表列对应的格式化文件行的定义。 在此格式化文件行中,“前缀长度”、“宿主文件数据长度”和“服务器列顺序”值必须设置为 0, 并且“终止符”和“列排序规则”字段必须设置为 ""(即设置为空值或 NULL 值)。 “服务器列名”值必须为非空白字符串,但不一定为实际列名。 其余格式字段必须为它们的默认值。
下面的示例也是从 myTestSkipCol 表的默认格式化文件派生出来的。
14.0
3
1 SQLCHAR 0 7 "," 1 Col1 ""
2 SQLCHAR 0 0 "" 0 Col2 ""
3 SQLCHAR 0 100 "\r\n" 3 Col3 SQL_Latin1_General_CP1_CI_AS
非 XML 格式化文件的示例
下面的示例基于本文前述的 myTestSkipCol 示例表和 myTestSkipCol2.dat 示例数据文件。
使用 BULK INSERT
此示例使用前面部分中所述创建的任一已修改非 XML 格式化文件。 在此例中,修改过的格式化文件名为 myTestSkipCol2.fmt。 要在 SQL Server Management Studio (SSMS) 中使用 BULK INSERT 批量导入 myTestSkipCol2.dat 数据文件,请运行以下代码。 更新计算机上示例文件位置的文件系统路径。
USE WideWorldImporters;
GO
BULK INSERT myTestSkipCol
FROM 'C:\myTestSkipCol2.dat'
WITH (FORMATFILE = 'C:\myTestSkipCol2.fmt');
GO
SELECT * FROM myTestSkipCol;
GO
选项 #2 - 使用 XML 格式化文件
步骤 #1 - 创建默认 XML 格式化文件
在命令提示符下运行以下 bcp 命令为 myTestSkipCol 示例表创建默认 XML 格式化文件:
bcp WideWorldImporters..myTestSkipCol format nul -f myTestSkipCol_Default.xml -c -x -T
重要
可能必须通过 -S 参数指定要连接的服务器实例的名称。 此外,可能还须通过 -U 和 -P 参数指定用户名和密码。 有关详细信息,请参阅 bcp Utility。
以上命令将创建 XML 格式化文件 myTestSkipCol_Default.xml。 此格式化文件称为 默认格式化文件 ,因为它是 bcp生成的格式。 默认格式化文件说明数据文件字段与表列之间的一一对应关系。
<?xml version="1.0"?>
<BCPFORMAT xmlns="http://schemas.microsoft.com/sqlserver/2004/bulkload/format" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<RECORD>
<FIELD ID="1" xsi:type="CharTerm" TERMINATOR="\t" MAX_LENGTH="7"/>
<FIELD ID="2" xsi:type="CharTerm" TERMINATOR="\t" MAX_LENGTH="100" COLLATION="SQL_Latin1_General_CP1_CI_AS"/>
<FIELD ID="3" xsi:type="CharTerm" TERMINATOR="\r\n" MAX_LENGTH="100" COLLATION="SQL_Latin1_General_CP1_CI_AS"/>
</RECORD>
<ROW>
<COLUMN SOURCE="1" NAME="Col1" xsi:type="SQLSMALLINT"/>
<COLUMN SOURCE="2" NAME="Col2" xsi:type="SQLNVARCHAR"/>
<COLUMN SOURCE="3" NAME="Col3" xsi:type="SQLNVARCHAR"/>
</ROW>
</BCPFORMAT>
注意
有关 XML 格式化文件结构的详细信息,请参阅 XML 格式化文件 (SQL Server)。
步骤 #2 - 修改 XML 格式化文件
下面是将跳过 Col2 的已修改 XML 格式化文件 myTestSkipCol2.xml。 Col2 的 FIELD 和 ROW 条目已删除,并且条目已重新编号。 第一个字段后的分隔符也已从 \t 更改为 ,。
<?xml version="1.0"?>
<BCPFORMAT xmlns="http://schemas.microsoft.com/sqlserver/2004/bulkload/format" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<RECORD>
<FIELD ID="1" xsi:type="CharTerm" TERMINATOR="," MAX_LENGTH="7"/>
<FIELD ID="2" xsi:type="CharTerm" TERMINATOR="\r\n" MAX_LENGTH="100" COLLATION="SQL_Latin1_General_CP1_CI_AS"/>
</RECORD>
<ROW>
<COLUMN SOURCE="1" NAME="Col1" xsi:type="SQLSMALLINT"/>
<COLUMN SOURCE="2" NAME="Col3" xsi:type="SQLNVARCHAR"/>
</ROW>
</BCPFORMAT>
XML 格式化文件的示例
下面的示例基于本文前述的 myTestSkipCol 示例表和 myTestSkipCol2.dat 示例数据文件。
为将数据从 myTestSkipCol2.dat 导入 myTestSkipCol 表,示例使用修改过的 XML 格式化文件 myTestSkipCol2.xml。
对视图使用 BULK INSERT
使用 XML 格式化文件时,你无法在通过 bcp 命令或 BULK INSERT 语句直接向表导入内容时跳过列。 但是,您可以向表中除最后一列的所有列导入。 如果必须跳过最后一列以外的任何列,必须创建仅包含数据文件所含列的目标表视图。 然后,您可以将此文件中的数据大容量导入此视图。
下面的示例在 myTestSkipCol 表上创建 v_myTestSkipCol 视图。 此视图跳过第二表列 Col2。 然后此例使用 BULK INSERT 将 myTestSkipCol2.dat 数据文件导入此视图。
在 SSMS 中,运行以下代码。 更新计算机上示例文件位置的文件系统路径。
USE WideWorldImporters;
GO
CREATE VIEW v_myTestSkipCol AS
SELECT Col1,Col3
FROM myTestSkipCol;
GO
BULK INSERT v_myTestSkipCol
FROM 'C:\myTestSkipCol2.dat'
WITH (FORMATFILE='C:\myTestSkipCol2.xml');
GO
使用 OPENROWSET(BULK...)
若要使用 XML 格式化文件通过 OPENROWSET(BULK...) 跳过表列,必须提供选择列表以及目标表中列的显式列表,如下所示:
INSERT ...<column_list> SELECT <column_list> FROM OPENROWSET(BULK...)
下面的示例使用 OPENROWSET 大容量行集提供程序和 myTestSkipCol2.xml 格式化文件。 此示例将 myTestSkipCol2.dat 数据文件大容量导入至 myTestSkipCol 表。 语句中包含了需要提供的选择列表以及目标表中列的显式列表。
在 SSMS 中,运行以下代码。 更新计算机上示例文件位置的文件系统路径。
USE WideWorldImporters;
GO
INSERT INTO myTestSkipCol
(Col1,Col3)
SELECT Col1,Col3
FROM OPENROWSET(BULK 'C:\myTestSkipCol2.Dat',
FORMATFILE='C:\myTestSkipCol2.Xml'
) as t1 ;
GO
后续步骤
反馈
即将发布:在整个 2024 年,我们将逐步淘汰作为内容反馈机制的“GitHub 问题”,并将其取代为新的反馈系统。 有关详细信息,请参阅:https://aka.ms/ContentUserFeedback。
提交和查看相关反馈