查询处理体系结构指南
适用于:![]() SQL Server
SQL Server![]() Azure SQL 数据库
Azure SQL 数据库![]() Azure SQL 托管实例
Azure SQL 托管实例
SQL Server 数据库引擎可处理对多种数据存储体系结构(例如,本地表、已分区表以及分布在多个服务器上的表)执行的查询。 以下部分介绍了 SQL Server 如何处理查询并通过执行计划缓存来优化查询重用。
执行模式
SQL Server 数据库引擎可使用两种不同的处理模式处理 Transact-SQL 语句:
- 行模式执行
- 批模式执行
行模式执行
行模式执行是用于传统 RDBMS 表(其中数据以行格式存储)的查询处理方法。 当执行查询并且查询访问行存储表中的数据时,执行树运算符和子运算符会读取表格架构中指定的所有列中的每个所需行。 然后,从读取的每一行中,SQL Server 检索结果集所需的列,即 SELECT 语句、JOIN 谓词或筛选谓词所引用的列。
注意
对于 OLTP 方案,行模式执行效率非常高,但在扫描大量数据时效率较低,例如数据仓库方案。
批模式执行
批模式执行是一种查询处理方法,用于统一处理多个行(因此采用“批”一词)。 批中的每列都作为一个矢量存储在单独的内存区域中,因此批模式处理是基于矢量的。 批模式处理还使用一些算法,这些算法针对多核 CPU 和新式硬件上的内存吞吐量增加进行了优化。
首次引入时,批处理模式执行与列存储存储格式紧密集成,并且围绕列存储存储格式进行了优化。 但是,从 SQL Server 2019 (15.x) 开始,在 Azure SQL 数据库中,批处理模式执行不再需要列存储索引。 有关详细信息,请参阅行存储上的批处理模式。
批模式处理在可能的情况下会对压缩数据运行,并消除了行模式执行所用的交换运算符。 结果是并行性更佳和性能更快。
当在批模式下执行查询并且查询访问列存储索引中的数据时,执行树运算符和子运算符会一次读取列段中的多行。 SQL Server 仅读取结果所需的列,即 SELECT 语句、JOIN 谓词或筛选谓词引用的列。 有关列存储索引的详细信息,请参阅列存储索引体系结构。
注意
批模式执行是非常高效的数据仓库方案,可读取和聚合大量数据。
SQL 语句处理
处理单个 Transact-SQL 语句是 SQL Server 执行 Transact-SQL 语句的最基本方法。 用于处理只引用本地基表(不引用视图或远程表)的单个 SELECT 语句的步骤说明了这个基本过程。
逻辑运算符的优先顺序
当一个语句中使用了多个逻辑运算符时,计算顺序依次为:NOT、AND最后是 OR。 算术运算符和位运算符优先于逻辑运算符处理。 有关详细信息,请参阅运算符优先级。
在下面的示例中,颜色条件适用于产品型号 21,而不适用于产品型号 20,因为 AND 的优先级高于 OR。
SELECT ProductID, ProductModelID
FROM Production.Product
WHERE ProductModelID = 20 OR ProductModelID = 21
AND Color = 'Red';
GO
可以通过添加括号强制先计算 OR 来改变查询的含义。 以下查询只查找型号 20 和 21 中红色的产品。
SELECT ProductID, ProductModelID
FROM Production.Product
WHERE (ProductModelID = 20 OR ProductModelID = 21)
AND Color = 'Red';
GO
因为运算符存在优先级,所以使用括号(即使不需要)可以提高查询的可读性,并减少出现细微错误的可能性。 使用括号不会造成重大的性能损失。 下面的示例比原始示例更可读,虽然它们在语义上是相同的。
SELECT ProductID, ProductModelID
FROM Production.Product
WHERE ProductModelID = 20 OR (ProductModelID = 21
AND Color = 'Red');
GO
优化 SELECT 语句
SELECT 语句是非程序性的,它不说明数据库服务器应用于检索所请求数据的确切步骤。 这意味着数据库服务器必须分析语句,以决定提取所请求数据的最有效方法。 这被称为“优化 SELECT 语句”。 处理此过程的组件称为“查询优化器”。 查询优化器的输入包括查询、数据库方案(表和索引的定义)以及数据库统计信息。 查询优化器的输出称为“查询执行计划”,有时也称为“查询计划”或为“执行计划”。 本文稍后将更详细地介绍执行计划的内容。
在优化单个 SELECT 语句期间查询优化器的输入和输出如下图中所示:
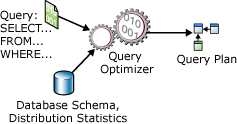
SELECT 语句只定义以下内容:
- 结果集的格式。 它通常在选择列表中指定。 然而,其他子句(如
ORDER BY和GROUP BY)也会影响结果集的最终格式。 - 包含源数据的表。 此表在
FROM子句中指定。 - 就
SELECT语句而言,表之间的逻辑关系。 这在联接规范中定义,联接规范可能出现在WHERE后的ON子句或FROM子句中。 - 为了符合
SELECT语句的要求,源表中的行所必须满足的条件。 这些条件在WHERE和HAVING子句中指定。
查询执行计划定义:
访问源表的顺序。
数据库服务器一般可以按许多不同的序列访问基表以生成结果集。 例如,如果SELECT语句引用三个表,数据库服务器可以先访问TableA,使用TableA中的数据从TableB中提取匹配的行,然后使用TableB中的数据从TableC中提取数据。 数据库服务器访问表的其他顺序包括:
TableC、TableB、TableA或
TableB、TableA、TableC或
TableB、TableC、TableA或
TableC、TableA、TableB用于从每个表提取数据的方法。
访问每个表中的数据一般也有不同的方法。 如果只需要有特定键值的几行,数据库服务器可以使用索引。 如果需要表中的所有行,数据库服务器则可以忽略索引并执行表扫描。 如果需要表中的所有行,而有一个索引的键列在ORDER BY中,则执行索引扫描而非表扫描可能会省去对结果集的单独排序。 如果表非常小,则对该表的几乎所有访问来说,表扫描可能都是最有效的方法。用于计算的方法,以及如何对每个表中的数据进行筛选、聚合和排序的方法。
从表访问数据时,可以使用不同的方法对数据进行计算,例如,计算标量值,以及对查询文本中定义的数据进行聚合和排序(例如,使用GROUP BY或ORDER BY子句时),以及如何筛选数据(例如在使用WHERE或HAVING子句时)。
从潜在的多个可能的计划中选择一个执行计划的过程称为“优化”。 查询优化器是数据库引擎最重要的组件之一。 虽然查询优化器在分析查询和选择计划时要使用一些开销,但当查询优化器选择了有效的执行计划时,这一开销将节省数倍。 例如,两家建筑公司可能拿到一所住宅的相同设计图。 如果一家公司开始时先花几天时间规划如何建造这所住宅,而另一家公司不做任何规划就开始施工,则花了时间规划项目的那家公司很可能首先完工。
SQL Server 查询优化器是基于成本的优化器。 就所使用的计算资源量而言,每个可能的执行计划都具有相关成本。 查询优化器必须分析可能的计划并选择一个预计成本最低的计划。 有些复杂的 SELECT 语句有成千上万个可能的执行计划。 在这些情况下,查询优化器不会分析所有可能的组合, 而是使用复杂的算法查找一个执行计划:其成本合理地接近最低可能成本。
SQL Server 查询优化器不只选择资源成本最低的执行计划,还选择能将结果最快地返回给用户且资源成本合理的计划。 例如,与串行处理查询相比,并行处理查询使用的资源一般更多但完成查询的速度更快。 因此如果不对服务器的负荷产生负面影响,SQL Server 查询优化器将使用并行执行计划返回结果。
SQL Server 查询优化器在估算用于从表或索引中提取信息的不同方法所需的资源成本时,依赖于分布统计信息。 为列和索引保留分布统计信息,并保存有关基础数据的密度 1 的信息。 这些信息表明特定索引或列中的值的选择性。 例如,在一个代表汽车的表中,很多汽车出自同一制造商,但每辆车都有唯一的车牌号 (VIN)。 因为 VIN 的密度比制造商低,所以 VIN 索引比制造商索引更具选择性。 如果索引统计信息不是最新的,则查询优化器可能无法针对表的当前状态做出最佳选择。 有关密度的详细信息,请参阅 统计信息。
1 密度定义数据中存在的唯一值的分布,或给定列的重复值平均数。 密度与值的选择性成反比,密度越小,值的选择性越大。
SQL Server 查询优化器很重要,因为它可以使数据库服务器针对数据库内的更改情况进行动态调整,而无需程序员或数据库管理员输入。 这样程序员可以集中精力描述最终的查询结果。 他们可以相信每次运行语句时,SQL Server 查询优化器总能针对数据库的状态生成有效的执行计划。
注意
SQL Server Management Studio 有三个选项来显示执行计划:
- 估计的执行计划,该计划是由查询优化器生成的已编译计划。
- 实际执行计划,该计划与编译的计划及其执行上下文相同。 这包括在执行完成之后可用的运行时信息,例如执行警告,或在较新版本的数据库引擎中,在执行过程中使用的已用时间和 CPU 时间。
- 实时查询统计信息,这与编译的计划及其执行上下文相同。 这包括执行过程中的运行时信息,每秒更新一次。 例如,运行时信息包括流经操作符的实际行数。
处理 SELECT 语句
SQL Server 处理单个 SELECT 语句的基本步骤包括如下内容:
- 分析器扫描
SELECT语句并将其分解成逻辑单元(如关键字、表达式、运算符和标识符)。 - 生成查询树(有时称为“序列树”),以描述将源数据转换成结果集需要的格式所用的逻辑步骤。
- 查询优化器分析访问源表的不同方法, 然后选择返回结果速度最快且使用资源最少的一系列步骤。 更新查询树以确切地记录这些步骤。 查询树的最终、优化的版本称为“执行计划”。
- 关系引擎开始执行计划。 在处理需要基表中数据的步骤时,关系引擎请求存储引擎向上传递从关系引擎请求的行集中的数据。
- 关系引擎将存储引擎返回的数据处理成为结果集定义的格式,然后将结果集返回客户端。
常数折叠和表达式计算
SQL Server 会先计算一些常数表达式来提高查询性能。 这称为常数折叠。 常数是 Transact-SQL 文本,例如 3、'ABC'、'2005-12-31'、1.0e3 或 0x12345678。
可折叠表达式
SQL Server 将常数折叠与下列类型的表达式配合使用:
- 仅包含常数的算术表达式,例如
1 + 1和5 / 3 * 2。 - 仅包含常数的逻辑表达式,例如
1 = 1和1 > 2 AND 3 > 4。 - 被 SQL Server 认为可折叠的内置函数,包括
CAST和CONVERT。 通常,如果内部函数只与输入有关而与其他上下文信息(例如 SET 选项、语言设置、数据库选项和加密密钥)无关,则该内部函数是可折叠的。 不确定性函数是不可折叠的。 确定性内置函数是可折叠的,但也有例外情况。 - CLR 用户定义类型的确定性方法和确定性标量值 CLR 用户定义函数(从 SQL Server 2012 (11.x) 开始)。 有关详细信息,请参阅 CLR 用户定义函数和方法的常数折叠。
注意
使用大型对象类型时将出现例外。 如果折叠进程的输出类型是大型对象类型(text、ntext、image、nvarchar(max)、varchar(max)、varbinary(max) 或 XML),则 SQL Server 不折叠该表达式。
不可折叠的表达式
所有其他表达式类型都是不可折叠的。 特别是下列类型的表达式是不可折叠的:
- 非常数表达式,例如,结果取决于列值的表达式。
- 结果取决于局部变量或参数的表达式,例如 @x。
- 不确定性函数。
- 用户定义的 Transact-SQL 函数1。
- 结果取决于语言设置的表达式。
- 结果取决于 SET 选项的表达式。
- 结果取决于服务器配置选项的表达式。
1 在 SQL Server 2012 (11.x) 之前,确定性标量值 CLR 用户定义函数和 CLR 用户定义类型的方法不可折叠。
可折叠和不可折叠常数表达式的示例
请考虑下列查询:
SELECT *
FROM Sales.SalesOrderHeader AS s
INNER JOIN Sales.SalesOrderDetail AS d
ON s.SalesOrderID = d.SalesOrderID
WHERE TotalDue > 117.00 + 1000.00;
如果此查询的 PARAMETERIZATION 数据库选项未设置为 FORCED,则在编译查询之前,将计算表达式 117.00 + 1000.00 并用计算结果 1117.00 替换该表达式。 常数折叠的优点如下:
- 运行时不必重复计算表达式。
- 查询优化器可使用计算表达式后所得的值来估计
TotalDue > 117.00 + 1000.00查询部分的结果集的大小。
另一方面,如果 dbo.f 是用户定义的标量函数,则不折叠表达式 dbo.f(100),因为 SQL Server 不折叠包含用户定义函数的表达式,即使这些函数是确定性函数也是如此。 有关参数化的详细信息,请参阅本文稍后的强制参数化部分。
表达式计算
此外,有些不可进行常数折叠但其参数在编译时已知的表达式(无论其参数是参数变量还是常数)将由优化期间优化器中包括的结果集大小(基数)估计器来计算。
具体而言,在编译时将计算下列内置函数和特殊运算符(如果它们的所有输入都已知):UPPER、LOWER、RTRIM、DATEPART( YY only )、GETDATE、CAST 和 CONVERT。 如果所有输入都是已知的,则在编译时计算下列运算符:
- 算术运算符:+、-、*、/、一元运算符 -
- 逻辑运算符:
AND、OR、NOT - 比较运算符:<、>、<=、>=、<>、
LIKE、IS NULL、IS NOT NULL
在基数估计过程中,查询优化器不计算其他任何函数或运算符。
编译时表达式计算的示例
以下面的存储过程为例:
USE AdventureWorks2022;
GO
CREATE PROCEDURE MyProc( @d datetime )
AS
SELECT COUNT(*)
FROM Sales.SalesOrderHeader
WHERE OrderDate > @d+1;
在优化存储过程中的 SELECT 语句期间,查询优化器尝试计算 OrderDate > @d+1 条件结果集的所需基数。 表达式 @d+1 不可进行常数折叠,因为 @d 是一个参数。 但是,在优化时,该参数值是已知的。 这使查询优化器能够准确估计结果集的大小,有助于其选择较好的查询计划。
现在考虑一个与上面的示例类似的示例,不同之处是在此查询中局部变量 @d2 替换了 @d+1,并且表达式在 SET 语句中计算而不是在查询中计算。
USE AdventureWorks2022;
GO
CREATE PROCEDURE MyProc2( @d datetime )
AS
BEGIN
DECLARE @d2 datetime
SET @d2 = @d+1
SELECT COUNT(*)
FROM Sales.SalesOrderHeader
WHERE OrderDate > @d2
END;
在 SQL Server 中优化 MyProc2 中的 SELECT 语句时,@d2 的值是未知的。 因此,查询优化器为 OrderDate > @d2 的选择性使用默认估计值(在此示例中为 30%)。
处理其他语句
上述处理 SELECT 语句的基本步骤也适用于其他 Transact-SQL 语句,例如 INSERT、UPDATE 和 DELETE。 UPDATE 和 DELETE 语句必须把要修改或要删除的行集作为目标。 识别这些行的过程与识别组成 SELECT 语句结果集的源行的过程相同。 UPDATE 和 INSERT 语句可能都包含嵌入式 SELECT 语句,该语句提供要更新或插入的数据值。
即使像 CREATE PROCEDURE 或 ALTER TABLE 这样的数据定义语言 (DDL) 语句也被最终解析为系统目录表上的一系列关系操作,而有时则根据数据表解析(如 ALTER TABLE ADD COLUMN)。
工作表
关系引擎可能需要生成一个工作表,以执行 Transact-SQL 语句中指定的逻辑操作。 工作表是用于保存中间结果的内部表。 某些 GROUP BY、 ORDER BY或 UNION 查询会生成工作表。 例如,如果 ORDER BY 子句引用了不为任何索引涵盖的列,则关系引擎可能需要生成一个工作表,以便按照所请求的顺序对结果集进行排序。 工作表有时也用作临时保存执行部分查询计划所得结果的假脱机。 工作表在 tempdb 中生成,并在不再需要时自动删除。
视图解析
SQL Server 查询处理器对索引视图和非索引视图将区别对待:
- 索引视图的行以表的格式存储在数据库中。 如果查询优化器决定使用查询计划的索引视图,则索引视图将按照基表的处理方式进行处理。
- 只有非索引视图的定义才存储,而不存储视图的行。 查询优化器将视图定义中的逻辑纳入执行计划,而该执行计划是它为引用非索引视图的 Transact-SQL 语句生成的。
SQL Server 查询优化器用于决定何时使用索引视图的逻辑与用于决定何时对表使用索引的逻辑相似。 如果索引视图中的数据包括所有或部分 Transact-SQL 语句,而且查询优化器确定视图的某个索引是低成本的访问路径,则不论查询中是否引用了该视图的名称,查询优化器都将选择此索引。
当 Transact-SQL 语句引用非索引视图时,分析器和查询优化器将分析 Transact-SQL 语句的源和视图的源,然后将它们解析为单个执行计划。 没有单独用于 Transact-SQL 语句或视图的计划。
例如,请看下面的视图:
USE AdventureWorks2022;
GO
CREATE VIEW EmployeeName AS
SELECT h.BusinessEntityID, p.LastName, p.FirstName
FROM HumanResources.Employee AS h
JOIN Person.Person AS p
ON h.BusinessEntityID = p.BusinessEntityID;
GO
根据此视图,这两个 Transact-SQL 语句在基表上执行相同的操作且生成相同的结果:
/* SELECT referencing the EmployeeName view. */
SELECT LastName AS EmployeeLastName, SalesOrderID, OrderDate
FROM AdventureWorks2022.Sales.SalesOrderHeader AS soh
JOIN AdventureWorks2022.dbo.EmployeeName AS EmpN
ON (soh.SalesPersonID = EmpN.BusinessEntityID)
WHERE OrderDate > '20020531';
/* SELECT referencing the Person and Employee tables directly. */
SELECT LastName AS EmployeeLastName, SalesOrderID, OrderDate
FROM AdventureWorks2022.HumanResources.Employee AS e
JOIN AdventureWorks2022.Sales.SalesOrderHeader AS soh
ON soh.SalesPersonID = e.BusinessEntityID
JOIN AdventureWorks2022.Person.Person AS p
ON e.BusinessEntityID =p.BusinessEntityID
WHERE OrderDate > '20020531';
SQL Server Management Studio 显示计划功能显示关系引擎为这两个 SELECT 语句生成相同的执行计划。
对视图使用提示
在视图扩展为访问其基表时,放置在查询中的视图的提示可能会与其他提示冲突。 发生这种情况时,查询将返回错误。 例如,请考虑下列视图,它们的定义中包含有表提示:
USE AdventureWorks2022;
GO
CREATE VIEW Person.AddrState WITH SCHEMABINDING AS
SELECT a.AddressID, a.AddressLine1,
s.StateProvinceCode, s.CountryRegionCode
FROM Person.Address a WITH (NOLOCK), Person.StateProvince s
WHERE a.StateProvinceID = s.StateProvinceID;
现在假设您输入此查询:
SELECT AddressID, AddressLine1, StateProvinceCode, CountryRegionCode
FROM Person.AddrState WITH (SERIALIZABLE)
WHERE StateProvinceCode = 'WA';
查询将失败,因为在展开视图 SERIALIZABLE 时此查询中应用于该视图的提示 Person.AddrState 传播到了该视图中的表 Person.Address 和 Person.StateProvince 。 但是,展开视图还将显示 NOLOCK 上的 Person.Address提示。 由于 SERIALIZABLE 提示和 NOLOCK 提示冲突,所以得到的查询不正确。
PAGLOCK、 NOLOCK、 ROWLOCK、 TABLOCK或 TABLOCKX 表提示相互冲突, HOLDLOCK、 NOLOCK、 READCOMMITTED、 REPEATABLEREAD、 SERIALIZABLE 表提示也一样。
提示可以通过不同级别的嵌套视图传播。 例如,假设查询对视图 HOLDLOCK 应用了 v1提示。 当扩展 v1 时,我们发现视图 v2 是其定义的一部分。 v2的定义包括其一个基表的 NOLOCK 提示。 但此表也从视图 HOLDLOCK 上的查询继承了 v1提示。 由于 NOLOCK 提示和 HOLDLOCK 提示冲突,所以查询将失败。
当在包含视图的查询中使用 FORCE ORDER 提示时,视图中表的联接顺序将由有序构造中视图的位置决定。 例如,下面的查询将从三个表和一个视图中进行选择:
SELECT * FROM Table1, Table2, View1, Table3
WHERE Table1.Col1 = Table2.Col1
AND Table2.Col1 = View1.Col1
AND View1.Col2 = Table3.Col2;
OPTION (FORCE ORDER);
另外, View1 的定义显示如下:
CREATE VIEW View1 AS
SELECT Colx, Coly FROM TableA, TableB
WHERE TableA.ColZ = TableB.Colz;
查询计划中的联接顺序为 Table1、 Table2、 TableA、 TableB、 Table3。
解析视图的索引
与任何索引相同,仅当查询优化器确定在 SQL Server 的查询计划中使用索引视图有益时,SQL Server 才会选择这样做。
索引视图可以在任何版本的 SQL Server 中创建。 在某些较早版本的 SQL Server 中,查询优化器会自动考虑索引视图。 在某些较早版本的 SQL Server 中,必须使用 NOEXPAND 表提示,才能使用索引视图。 在 SQL Server 2016 (13.x) Service Pack 1 之前,仅在特定版本的 SQL Server 中支持查询优化器自动使用索引视图。 因为所有版本都支持自动使用索引视图。 Azure SQL 数据库和 Azure SQL 托管实例还支持在不指定 NOEXPAND 提示的情况下自动使用索引视图。
当满足下列条件时,SQL Server 查询优化器会使用索引视图:
- 下列会话选项均设置为
ON:ANSI_NULLSANSI_PADDINGANSI_WARNINGSARITHABORTCONCAT_NULL_YIELDS_NULLQUOTED_IDENTIFIER
NUMERIC_ROUNDABORT会话选项设置为 OFF。- 查询优化器查找视图索引列与查询中的元素之间的匹配项,例如:
- WHERE 子句中的搜索条件谓词
- 联接操作
- 聚合函数
GROUP BY子句- 表引用
- 估计的索引使用成本是查询优化器考虑使用的所有访问机制中的最低成本。
- 查询中引用(直接或通过展开视图访问其基础表)的且与索引视图中的表引用相对应的每个表在该查询中都必须具有应用于表的相同提示集。
注意
在此上下文中,不管当前事务隔离级别如何, READCOMMITTED 和 READCOMMITTEDLOCK 提示始终被认为是不同的提示。
除 SET 选项和表提示的要求外,查询优化器也使用上述规则确定表索引是否包含查询。 不必在查询中指定其他内容即可使用索引视图。
查询不必在 FROM 子句中显式引用索引视图,查询优化器即可使用该索引视图。 如果查询所引用的基表中的列也同时存在于索引视图中,并且,查询优化器估计使用索引视图将提供最低成本的访问机制,则查询优化器会选择索引视图,其方式类似于当查询中不直接引用基表索引时选择基表索引。 视图中包含查询未引用的列时,只要视图提供包含一个或多个查询中所指定列的最低成本选项,查询优化器即可选择该视图。
查询优化器将 FROM 子句中引用的索引视图视为标准视图。 查询优化器在优化进程开始时将视图的定义展开至查询中。 然后,执行索引视图匹配。 可将索引视图用于查询优化器选择的最终执行计划中,或该计划可以通过访问视图引用的基表来具体化视图中的必要数据。 查询优化器会选择成本最低的方式。
对索引视图使用提示
可以通过使用 EXPAND VIEWS 查询提示防止将视图索引用于查询,也可以使用 NOEXPAND 表提示强制将索引用于查询的 FROM 子句指定的索引视图。 但应该让查询优化器动态确定用于每个查询的最佳访问方法。 只在经测试证实 EXPAND 和 NOEXPAND 可显著提高性能的特定情形中使用它们。
EXPAND VIEWS选项指定对于整个查询,查询优化器不应使用任何视图索引。当为视图指定了
NOEXPAND时,查询优化器将考虑使用为视图定义的任何索引。 通过可选的NOEXPAND子句指定的INDEX(),可强制查询优化器使用指定索引。 只能为索引视图指定NOEXPAND,而不能为还未创建索引的视图指定。 在 SQL Server 2016 (13.x) Service Pack 1 之前,仅在特定版本的 SQL Server 中支持查询优化器自动使用索引视图。 因为所有版本都支持自动使用索引视图。 Azure SQL 数据库和 Azure SQL 托管实例还支持在不指定NOEXPAND提示的情况下自动使用索引视图。
如果在包含视图的查询中既未指定 NOEXPAND 也未指定 EXPAND VIEWS ,则展开该视图以访问基础表。 如果组成视图的查询包含表提示,则这些提示将传播到基础表。 (“视图解析”中详细说明了此过程。)只要视图的基础表中的提示集彼此相同,查询就可以与索引视图进行匹配。 在大部分情况下,这些提示彼此匹配,因为它们直接从视图继承而来。 但是,如果查询引用表而不是引用视图,且直接应用于这些表的提示并不相同,则这类查询就无法与索引视图进行匹配。 如果在视图展开后,INDEX、PAGLOCK、ROWLOCK、TABLOCKX、UPDLOCK 或 XLOCK 提示应用于查询中引用的表,则查询不符合索引视图匹配的条件。
如果形式为 INDEX (index_val[ ,...n] ) 的表提示引用了查询中的视图,而你还没有指定 NOEXPAND 提示,则忽略该索引提示。 若要指定使用特定索引,请使用 NOEXPAND。
通常,查询优化器将索引视图与查询匹配后,对查询中表或视图指定的所有提示都将直接应用于索引视图。 如果查询优化器选择不使用索引视图,则所有提示将直接传播到视图中引用的表。 有关详细信息,请参阅“视图解析”。 此传播不应用于联接提示。 仅在查询中提示的原始位置应用提示。 将查询与索引视图匹配时,查询优化器不考虑联接提示。 如果查询计划使用了与包含联接提示的查询部分匹配的索引视图,则计划中不使用联接提示。
索引视图定义中不允许有提示。 在 80 和更高的兼容模式中,SQL Server 在维护索引视图定义或执行使用索引视图的查询时将忽略索引视图定义内的提示。 尽管在 80 兼容模式中,在索引视图定义中使用提示不会生成语法错误,但会忽略提示。
有关详细信息,请参阅表提示 (Transact-SQL)。
解析分布式分区视图
SQL Server 查询处理器会优化分布式分区视图的性能。 分布式分区视图性能的最重要方面是尽量减少成员服务器之间传输的数据量。
SQL Server 生成智能的动态计划,该计划有效利用分布式查询访问远程成员表中的数据:
- 查询处理器首先使用 OLE DB 从每个成员表中检索 CHECK 约束定义。 这样,查询处理器就可以在各成员表之间映射键值的分布。
- 查询处理器将 Transact-SQL 语句
WHERE子句中指定的键范围与显示行在成员表中如何分布的映射进行比较。 然后查询处理器生成查询执行计划,该计划使用分布式查询只检索那些完成 Transact-SQL 语句所需的远程行。 也可以采用这种方式生成执行计划:任何对远程成员表数据或元数据的访问,都被延迟到需要这些信息时。
例如,有这样一个系统:其中 Customers 表在 Server1(CustomerID 从 1 到 3299999)、Server2(CustomerID 从 3300000 到 6599999)和 Server3(CustomerID 从 6600000 到 9999999)间进行分区。
考虑为在 Server1 上执行的下列查询所生成的执行计划:
SELECT *
FROM CompanyData.dbo.Customers
WHERE CustomerID BETWEEN 3200000 AND 3400000;
该查询的执行计划从本地成员表中提取 CustomerID 键值从 3200000 到 3299999 的行,并发出分布式查询以从 Server2 中检索键值从 3300000 到 3400000 的行。
SQL Server 查询处理器还可以在查询执行计划中创建动态逻辑,用于必须生成计划时键值未知的 Transact-SQL 语句。 例如下面的存储过程:
CREATE PROCEDURE GetCustomer @CustomerIDParameter INT
AS
SELECT *
FROM CompanyData.dbo.Customers
WHERE CustomerID = @CustomerIDParameter;
SQL Server 无法预测每次执行该过程时 @CustomerIDParameter 参数将提供什么键值。 由于无法预测键值,因此查询处理器还无法预测必须访问哪个成员表。 为了处理这种情况,SQL Server 生成了具有条件逻辑(称为动态筛选)的执行计划,可基于输入参数值来控制访问哪个成员表。 假设在 Server1 上执行了 GetCustomer 存储过程,则执行计划逻辑可以表示如下:
IF @CustomerIDParameter BETWEEN 1 and 3299999
Retrieve row from local table CustomerData.dbo.Customer_33
ELSE IF @CustomerIDParameter BETWEEN 3300000 and 6599999
Retrieve row from linked table Server2.CustomerData.dbo.Customer_66
ELSE IF @CustomerIDParameter BETWEEN 6600000 and 9999999
Retrieve row from linked table Server3.CustomerData.dbo.Customer_99
有时,对即使没有参数化的查询,SQL Server 也生成这些类型的动态执行计划。 查询优化器可参数化查询,以便重新使用执行计划。 如果查询优化器参数化引用了分区视图的查询,则查询优化器不再假设所需行将来自指定的基表。 它将必须在执行计划中使用动态筛选。
存储过程和触发器执行
SQL Server 仅存储存储过程和触发器的源。 第一次执行存储过程或触发器时,源被编译为执行计划。 如果在执行计划从内存老化掉之前再次执行该存储过程或触发器,则关系引擎将检测现有计划并重新使用它。 如果该计划已从内存老化掉,将生成新的计划。 此进程类似于 SQL Server 对所有 Transact-SQL 语句采用的进程。 与动态 Transact-SQL 的批处理相比,存储过程和触发器在 SQL Server 中的主要性能优势是,它们的 Transact-SQL 语句始终相同。 因此,关系引擎能够轻松地将它们与任何现有执行计划相匹配。 可以轻松地重新使用存储过程和触发器计划。
存储过程和触发器的执行计划与调用存储过程或激发触发器的批处理的执行计划是独立执行的。 这样就有更大的机会重用存储过程和触发器的执行计划。
执行计划的缓存和重复使用
SQL Server 有一个用于存储执行计划和数据缓冲区的内存池。 池内分配给执行计划或数据缓冲区的百分比随系统状态动态波动。 内存池中用于存储执行计划的部分称为计划缓存。
计划缓存为所有编译的计划提供了两个存储:
- “对象计划”缓存存储 (OBJCP),用于与持久化对象(存储过程、函数和触发器)相关的计划。
- “SQL 计划”缓存存储 (SQLCP),用于与自动参数化、动态或已准备的查询相关的计划。
下面的查询提供了有关这两个缓存存储的内存使用情况的信息:
SELECT * FROM sys.dm_os_memory_clerks
WHERE name LIKE '%plans%';
注意
计划缓存有两个不用于存储计划的附加存储:
- “绑定树”缓存存储区 (PHDR),用于在视图、约束和默认值的计划编译期间使用的数据结构。 这些结构称为绑定树或 Algebrizer 树。
- “扩展存储过程”缓存存储 (XPROC),用于预定义的系统过程(如使用 DLL 而非 Transact-SQL 语句定义的
sp_executeSql或xp_cmdshell)。 缓存的结构只包含在其中实现此过程的函数名称和 DLL 名称。
SQL Server 执行计划包含下列主要组件:
已编译计划(或查询计划)
由编译过程生成的查询计划主要是由任意数量的用户使用的可重入的只读数据结构。 它存储有关以下内容的信息:执行上下文
每个正在执行查询的用户都有一个包含其执行专用数据(如参数值)的数据结构。 此数据结构称为执行上下文。 执行上下文数据结构会重复使用,但其内容不会。 如果其他用户执行相同的查询,则会为新用户重新初始化上下文数据结构。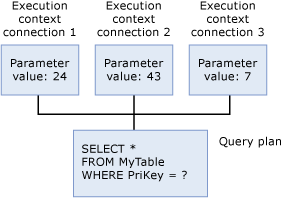
在 SQL Server 中执行任何 Transact-SQL 语句时,数据库引擎将首先查看计划缓存,以确认是否存在用于同一 Transact-SQL 语句的现有执行计划。 如果 Transact-SQL 语句与先前根据缓存计划执行的 Transact-SQL 语句的每个字符完全匹配,则该语句符合现有条件。 SQL Server 会重用找到的任何现有计划,从而节省重新编译 Transact-SQL 语句的开销。 如果没有执行计划,SQL Server 将为查询生成新的执行计划。
注意
有些 Transact-SQL 语句的执行计划未保留在计划缓存中,例如在行存储上运行的大容量操作语句或包含大于 8 KB 的字符串文字的语句。 这些计划仅在执行查询时存在。
SQL Server 有一个高效的算法,可查找用于任何特定 Transact-SQL 语句的现有执行计划。 在大多数系统中,这种扫描所使用的最小资源比通过重新使用现有计划而不是编译每个 Transact-SQL 语句所节省的资源要少。
该算法将新的 Transact-SQL 语句与计划缓存内现有的未用执行计划相匹配,并要求完全限定所有对象引用。 例如,假定 Person 是用户执行以下 SELECT 语句的默认架构。 虽然在此示例中不需要 Person 表完全限定执行,但这意味着第二个语句与现有计划不匹配,但第三个语句匹配:
USE AdventureWorks2022;
GO
SELECT * FROM Person;
GO
SELECT * FROM Person.Person;
GO
SELECT * FROM Person.Person;
GO
对于给定的执行,更改以下任意 SET 选项都将影响重用计划的能力,因为数据库引擎执行常数折叠并且这些选项会影响此类表达式的结果:
ANSI_NULL_DFLT_OFF
FORCEPLAN
ARITHABORT
DATEFIRST
ANSI_PADDING
NUMERIC_ROUNDABORT
ANSI_NULL_DFLT_ON
LANGUAGE
CONCAT_NULL_YIELDS_NULL
DATEFORMAT
ANSI_WARNINGS
QUOTED_IDENTIFIER
ANSI_NULLS
NO_BROWSETABLE
ANSI_DEFAULTS
为同一个查询缓存多个计划
查询和执行计划在数据库引擎中是唯一可识别的,与指纹非常类似:
- “查询计划哈希”是在给定查询的执行计划上计算的二进制哈希值,用于唯一标识类似的执行计划。
- “查询哈希”是在查询的 Transact-SQL 文本上计算出的二进制哈希值,用于唯一标识查询。
可以使用“计划句柄”从计划缓存中检索已编译的计划,该句柄是仅当计划保留在缓存中时才保持不变的暂时性标识符。 计划句柄是派生自整个批处理的已编译计划的一个哈希值。 即使批处理中的一个或多个语句重新编译,编译计划的计划句柄仍保持不变。
注意
如果为批处理而不是单个语句编译了某个计划,则可以使用计划句柄和语句偏移来检索批处理中单个语句的计划。
sys.dm_exec_requests DMV 包含每条记录的 statement_start_offset 和 statement_end_offset 列,它们表示当前正在执行的批处理或持久化对象的当前执行语句。 有关详细信息,请参阅 sys.dm_exec_requests (Transact-SQL)。
sys.dm_exec_query_stats DMV 同样包含每条记录中的这些列,它们引用语句在批处理或持久对象中的位置。 有关详细信息,请参阅 sys.databases dm_exec_query_stats (Transact-SQL)。
批处理的实际 Transact-SQL 文本存储在单独的内存空间中,该位置与计划缓存,即 SQL Manager 缓存 (SQLMGR) 的存储位置不同。 使用 SQL 句柄,可以从 SQL Manager 缓存检索已编译计划的 Transact-SQL 文本,这是一个暂时性标识符,仅当至少有一个引用它的计划保留在计划缓存中时,它才保持不变。 SQL 句柄是派生自整个批处理文本的哈希值,并且保证对于每个批处理都唯一。
注意
与已编译的计划一样,Transact-SQL 文本会按批存储,包括注释。 SQL 句柄包含整个批处理文本的 MD5 哈希,并且保证对于每个批处理都唯一。
以下查询提供了有关 SQL Manager 缓存的内存使用情况的信息:
SELECT * FROM sys.dm_os_memory_objects
WHERE type = 'MEMOBJ_SQLMGR';
SQL 句柄和计划句柄之间存在 1:N 的关系。 如果已编译计划的缓存键不同,则会发生这种情况。 出现此情况的原因可能是,在两次执行相同批处理的 SET 选项发生了更改。
请思考以下存储过程:
USE WideWorldImporters;
GO
CREATE PROCEDURE usp_SalesByCustomer @CID int
AS
SELECT * FROM Sales.Customers
WHERE CustomerID = @CID
GO
SET ANSI_DEFAULTS ON
GO
EXEC usp_SalesByCustomer 10
GO
使用以下查询验证在计划缓存中可以找到的内容:
SELECT cp.memory_object_address, cp.objtype, refcounts, usecounts,
qs.query_plan_hash, qs.query_hash,
qs.plan_handle, qs.sql_handle
FROM sys.dm_exec_cached_plans AS cp
CROSS APPLY sys.dm_exec_sql_text (cp.plan_handle)
CROSS APPLY sys.dm_exec_query_plan (cp.plan_handle)
INNER JOIN sys.dm_exec_query_stats AS qs ON qs.plan_handle = cp.plan_handle
WHERE text LIKE '%usp_SalesByCustomer%'
GO
下面是结果集:
memory_object_address objtype refcounts usecounts query_plan_hash query_hash
--------------------- ------- --------- --------- ------------------ ------------------
0x000001CC6C534060 Proc 2 1 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
plan_handle
------------------------------------------------------------------------------------------
0x0500130095555D02D022F111CD01000001000000000000000000000000000000000000000000000000000000
sql_handle
------------------------------------------------------------------------------------------
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
现在使用其他参数执行存储过程,但不要对执行上下文做出其他更改:
EXEC usp_SalesByCustomer 8
GO
再次验证可在计划缓存中找到的内容。 下面是结果集。
memory_object_address objtype refcounts usecounts query_plan_hash query_hash
--------------------- ------- --------- --------- ------------------ ------------------
0x000001CC6C534060 Proc 2 2 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
plan_handle
------------------------------------------------------------------------------------------
0x0500130095555D02D022F111CD01000001000000000000000000000000000000000000000000000000000000
sql_handle
------------------------------------------------------------------------------------------
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
请注意,usecounts 已增加到 2,这意味着相同的缓存计划以原方式重复使用,这是因为重用了执行上下文数据结构。 现在,请更改 SET ANSI_DEFAULTS 选项,并使用相同的参数执行存储过程。
SET ANSI_DEFAULTS OFF
GO
EXEC usp_SalesByCustomer 8
GO
再次验证可在计划缓存中找到的内容。 下面是结果集:
memory_object_address objtype refcounts usecounts query_plan_hash query_hash
--------------------- ------- --------- --------- ------------------ ------------------
0x000001CD01DEC060 Proc 2 1 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
0x000001CC6C534060 Proc 2 2 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
plan_handle
------------------------------------------------------------------------------------------
0x0500130095555D02B031F111CD01000001000000000000000000000000000000000000000000000000000000
0x0500130095555D02D022F111CD01000001000000000000000000000000000000000000000000000000000000
sql_handle
------------------------------------------------------------------------------------------
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
请注意,sys.dm_exec_cached_plans DMV 输出中现在有两个条目:
usecounts列显示第一条记录中的值1,该记录是使用SET ANSI_DEFAULTS OFF执行一次的计划。usecounts列显示第二条记录中的值2,该记录是使用SET ANSI_DEFAULTS ON执行的计划,因为它执行了两次。- 不同的
memory_object_address会引用计划缓存中不同的执行计划条目。 但是,这两个条目的sql_handle值相同,因为它们引用相同的批。- 将
ANSI_DEFAULTS设置为 OFF 的执行具有新的plan_handle,并且它可用于对具有一组相同的 SET 选项的调用。 新的计划句柄是必需的,因为由于 SET 选项已更改,执行上下文已重新初始化。 但这并不会触发重新编译:这两个条目引用相同的计划和查询,相同的query_plan_hash和query_hash值可证明。
- 将
这实际上意味着,在缓存中有两个对应于同一个批处理的计划条目,并且它强调了有必要在重复执行相同的查询时,确保影响 SET 选项的计划缓存相同,以优化计划重用,并使计划缓存大小保持在所需的最小值。
提示
存在一个常见的隐患,即不同的客户端可能具有不同的 SET 选项默认值。 例如,通过 SQL Server Management Studio 建立的连接会自动将 QUOTED_IDENTIFIER 设置为 ON,而 SQLCMD 会将 QUOTED_IDENTIFIER 设置为 OFF。 从这两个客户端执行相同的查询将产生多个计划(如上面的示例中所述)。
从计划缓存中删除执行计划
只要计划缓存中有足够的存储空间,执行计划就会保留在其中。 当存在内存不足的情况时,SQL Server 数据库引擎将使用基于成本的方法来确定要从计划缓存中删除哪些执行计划。 要做出基于成本的决策,SQL Server 数据库引擎将根据以下因素增加和减少每个执行计划的当前开销变量。
当某个用户进程将执行计划插入缓存中时,该用户进程会将当前开销设置为等于原始查询编译开销;对于即席执行计划,该用户进程会将当前开销设置为零。 以后,用户进程每次引用执行计划时,都会将当前开销重置为原始编译开销;对于即席执行计划,用户进程会增加当前开销。 对于所有计划而言,当前开销的最大值就是原始编译开销。
当存在内存不足的情况时,SQL Server 数据库引擎会通过从计划缓存中删除执行计划来进行响应。 为了确定删除哪些计划,SQL Server 数据库引擎会重复检查每个执行计划的状态并将删除当前开销为零的执行计划。 当存在内存不足的情况时,当前开销为零的执行计划不会被自动删除;而只有在 SQL Server 数据库引擎检查该计划并发现其当前开销为零时,才会删除该计划。 当检查执行计划时,如果当前没有查询使用该计划,则 SQL Server 数据库引擎将降低当前开销以将其推向零。
SQL Server 数据库引擎会重复检查执行计划,直到删除了足够多的执行计划,以满足内存要求为止。 如果存在内存不足的情况,执行计划的成本可能会多次增加和减少。 当内存不足的情况完全消失时,SQL Server 数据库引擎将停止降低未使用执行计划的当前开销,并且所有执行计划都将保留在计划缓存中,即使其开销为零也是如此。
SQL Server 数据库引擎使用资源监视器和用户工作线程从计划缓存中释放内存,以响应内存不足。 资源监视器和用户工作线程可以检查并发运行的计划,从而降低每个未使用执行计划的当前开销。 如果存在全局内存不足的情况,资源监视器将会从计划缓存中删除执行计划。 它释放内存以强制实施系统内存、进程内存、资源池内存和所有缓存最大大小的策略。
所有缓存的最大大小是缓存池大小的一个函数,不能超出最大服务器内存的大小。 有关配置最大服务器内存的详细信息,请参阅 max server memory 中的 sp_configure设置。
当存在单一缓存不足的情况时,用户工作线程将会从计划缓存中删除执行计划。 它们强制实施最大单一缓存大小和最大单一缓存条目数的策略。
以下示例说明会从计划缓存中删除哪些执行计划:
- 一个经常被引用的执行计划,该计划的开销从未等于零。 除非遇到内存不足和当前开销为零的情况,否则该计划保留在计划缓存中,不会被删除。
- 插入的一个即席执行计划,并且在内存不足情况出现之前没有再次引用该计划。 由于即席计划在初始化后当前开销为零,因此在 SQL Server 数据库引擎检查执行计划时,会发现当前开销为零,于是从计划缓存中删除该计划。 如果不存在内存不足的情况,当前开销为零的即席执行计划将保留在计划缓存中。
若要从缓存中手动删除单个计划或所有计划,请使用 DBCC FREEPROCCACHE。 DBCC FREESYSTEMCACHE 也可用于清除任何缓存,包括计划缓存。 从 SQL Server 2016 (13.x) 开始,使用 ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE 清除范围内数据库的过程(计划)缓存。
通过 sp_configure 和 reconfigure 对某些配置设置进行的更改也会导致从计划缓存中删除计划。 可在 DBCC FREEPROCCACHE 一文的“备注”部分中找到这些配置设置的列表。 此类配置更改将在错误日志中记录以下信息性消息:
SQL Server has encountered %d occurrence(s) of cachestore flush for the '%s' cachestore (part of plan cache) due to some database maintenance or reconfigure operations.
重新编译执行计划
根据数据库新状态的不同,数据库中的某些更改可能导致执行计划效率降低或无效。 SQL Server 将检测到使执行计划无效的更改,并将计划标记为无效。 此后,必须为执行查询的下一个连接重新编译新的计划。 导致计划无效的情况包括:
- 对查询所引用的表或视图进行更改(
ALTER TABLE和ALTER VIEW)。 - 对单个过程进行更改,这将从缓存中删除该过程的所有计划 (
ALTER PROCEDURE)。 - 对执行计划所使用的任何索引进行更改。
- 对执行计划所使用的统计信息进行更新,这些更新可能是从语句(如
UPDATE STATISTICS)显式生成,也可能是自动生成的。 - 删除执行计划所使用的索引。
- 显式调用
sp_recompile。 - 对键进行大量更改(这些更改是对查询所引用的表进行修改的其他用户执行
INSERT或DELETE语句所产生的)。 - 对于带触发器的表,如果插入的或删除的表内的行数显著增长。
- 使用
WITH RECOMPILE选项执行存储过程。
为了使语句正确,或要获得可能更快的查询执行计划,大多数都需要进行重新编译。
在低于 2005 版的 SQL Server 版本中,只要批处理中的语句导致重新编译,就会重新编译整个批处理,无论此批处理是通过存储过程、触发器、临时批处理还是预定义语句提交的。 从 SQL Server 2005 (9.x) 开始,只会重新编译批处理中触发重新编译的语句。 另外,由于 SQL Server 2005 (9.x) 和更高版本扩展了功能集,因此它们具有其他类型的重新编译。
语句级重新编译有助于提高性能,因为在大多数情况下,只有少数语句导致了重新编译并造成相关损失(指 CPU 时间和锁)。 因此,对于不需要重新编译的批处理中的其他语句,可以避免这些损失。
sql_statement_recompile 扩展事件 (xEvent) 报告语句级重新编译。 当任何类型的批处理需要语句级重新编译时,都将发生此 xEvent。 这包括存储过程、触发器、即席批处理和查询。 可通过几个接口来提交批处理,这类接口包括 sp_executesql、动态 SQL、“准备”方法或“执行”方法。
sql_statement_recompile xEvent 的 recompile_cause 列包含一个整数代码,指示重新编译的原因。 下表包含可能的原因:
架构已更改
统计信息已更改
编译延迟
SET 选项已更改
临时表已更改
远程行集已更改
FOR BROWSE 权限已更改
查询通知环境已更改
分区视图已更改
游标选项已更改
OPTION (RECOMPILE) 已请求
参数化计划已刷新
影响数据库版本的计划已更改
查询存储计划强制执行策略已更改
查询存储计划强制执行失败
查询存储缺少计划
注意
在 xEvents 不可用的 SQL Server 版本中,SQL Server Profiler SP:Recompile 跟踪事件同样可用于报告语句级重新编译。
跟踪事件 SQL:StmtRecompile 也报告语句级重新编译,并且此跟踪事件还可用于跟踪和调试重新编译。
SP:Recompile 仅针对存储过程和触发器生成,而 SQL:StmtRecompile 则针对存储过程、触发器、即席批处理、使用 sp_executesql执行的批处理、预定义查询和动态 SQL 生成。
SP:Recompile 和 SQL:StmtRecompile 的 EventSubClass 列都包含一个整数代码,用以指明重新编译的原因。 此处对代码进行了说明。
注意
当 AUTO_UPDATE_STATISTICS 数据库选项设置为 ON 时,如果查询以表或索引视图为目标,而自上次执行后,表或索引视图的统计信息已更新或其基数已发生很大变化,查询将被重新编译。
此行为适用于标准用户定义表、临时表以及由 DML 触发器创建的插入表和删除表。 如果过多的重新编译影响到查询性能,请考虑将此设置更改为 OFF。 当 AUTO_UPDATE_STATISTICS 数据库选项设置为 OFF 时,不会因统计信息或基数的更改而发生任何重新编译,但是,由 DML INSTEAD OF 触发器创建的插入表和删除表除外。 因为这些表是在 tempdb 中创建的,因此,是否重新编译访问这些表的查询取决于 tempdb 中 AUTO_UPDATE_STATISTICS 的设置。
请注意,在低于 2005 版的 SQL Server 中,即使此设置为 OFF,查询也将继续基于 DML 触发器插入表和删除表的基数更改进行重新编译。
参数和执行计划的重复使用
使用参数(包括 ADO、OLE DB 和 ODBC 应用程序中的参数标记)有助于重用执行计划。
警告
与将最终用户键入的值串联到字符串中,然后使用数据访问 API 方法、 EXECUTE 语句或 sp_executesql 存储过程来执行该字符串相比,使用参数或参数标记来保存这些值更安全。
下面两个 SELECT 语句之间的唯一区别是 WHERE 子句中比较的值不同:
SELECT *
FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 1;
SELECT *
FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 4;
这两个查询的执行计划之间的唯一区别是为与 ProductSubcategoryID 列进行比较而存储的值。 虽然目的是要让 SQL Server 总是认为语句实际生成了相同的计划并重复使用这些计划,但是 SQL Server 有时不能在复杂的 Transact-SQL 语句中检测到上述情况。
使用参数将常数与 Transact-SQL 语句分隔开有助于关系引擎识别重复计划。 可以按下列方式使用参数:
在 Transact-SQL 中,使用
sp_executesql:DECLARE @MyIntParm INT SET @MyIntParm = 1 EXEC sp_executesql N'SELECT * FROM AdventureWorks2022.Production.Product WHERE ProductSubcategoryID = @Parm', N'@Parm INT', @MyIntParm建议对动态生成 SQL 语句的 Transact-SQL 脚本、存储过程或触发器使用此方法。
ADO、OLE DB 和 ODBC 使用参数标记。 参数标记是问号 (?),在 SQL 语句中替代常数并绑定到程序变量。 例如,可以在 ODBC 应用程序中执行下列操作:
使用
SQLBindParameter将整数变量绑定到 SQL 语句中的第一个参数标记。为变量赋整数值。
执行语句,并指定参数标记 (?):
SQLExecDirect(hstmt, "SELECT * FROM AdventureWorks2022.Production.Product WHERE ProductSubcategoryID = ?", SQL_NTS);
在应用程序中使用参数标记时,SQL Server 附带的 SQL Server Native Client OLE DB 提供程序和 SQL Server Native Client ODBC 驱动程序使用
sp_executesql将语句发送到 SQL Server。设计使用参数的存储过程。
如果未将参数显式生成到应用程序的设计中,则还可以依赖 SQL Server 查询优化器,通过使用简单参数化的默认行为自动参数化某些查询。 另外,也可以通过将 ALTER DATABASE 语句的 PARAMETERIZATION 选项设置为 FORCED,强制查询优化器考虑将数据库中的所有查询参数化。
启用强制参数化后,仍会发生简单参数化。 例如,根据强制参数化规则,无法将以下查询参数化:
SELECT * FROM Person.Address
WHERE AddressID = 1 + 2;
但根据简单参数化规则,可以将该查询参数化。 尝试强制参数化失败后,仍将接着尝试简单参数化。
简单参数化
在 SQL Server 中,在 Transact-SQL 语句中使用参数或参数标记可以提高关系引擎将新的 Transact-SQL 语句与现有的、以前编译的执行计划相匹配的能力。
警告
与将最终用户键入的值串联到字符串中,然后使用数据访问 API 方法、 EXECUTE 语句或 sp_executesql 存储过程来执行该字符串相比,使用参数或参数标记来保存这些值更安全。
如果执行不带参数的 Transact-SQL 语句,SQL Server 将在内部对该语句进行参数化以增加将其与现有执行计划相匹配的可能性。 此过程称为简单参数化。 在低于 2005 版的 SQL Server 版本中,该过程被称为自动参数化。
请看下面的语句:
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 1;
可以将该语句最后的值 1 指定为一个参数。 关系引擎将假定已指定参数来代替值 1,并在此基础上为此批处理生成执行计划。 由于这种简单参数化,SQL Server 将认为下列两个语句实质上生成了相同的执行计划,并对第二个语句重用第一个计划:
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 1;
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 4;
处理复杂的 Transact-SQL 语句时,关系引擎可能难以确定哪些表达式可以参数化。 若要提高关系引擎将复杂的 Transact-SQL 语句与现有的、未使用的执行计划相匹配的能力,请使用 sp_executesql 或参数标记显式指定参数。
注意
当使用 +、-、*、/ 或 % 算术运算符将 int、smallint、tinyint 或 bigint 常数值隐式或显式转换为 float、real、decimal 或 numeric 数据类型时,SQL Server 将应用特定规则以计算表达式结果的类型和精度。 但这些规则各不相同,取决于查询是否被参数化。 因此,在某些情况下,查询中的相似表达式可能会产生不同的结果。
在简单参数化的默认行为下,SQL Server 只对相对较少的一些查询进行参数化。 但是,可以通过将 PARAMETERIZATION 命令的 ALTER DATABASE 选项设置为 FORCED,来指定对数据库中的所有查询都进行参数化(但受到某些限制)。 对于存在大量并发查询的数据库,这样做可减少查询编译的频率,从而提高数据库的性能。
您也可以指定对单个查询以及其他在语法上等效,只有参数值不同的查询进行参数化。
提示
使用对象关系映射 (ORM) 解决方案(如实体框架 (EF))时,手动 LINQ 查询树或某些原始 SQL 查询等应用程序查询可能不会参数化,这会影响计划重新使用以及在查询存储中跟踪查询的能力。 有关详细信息,请参阅 EF 查询缓存和参数化以及 EF 原始 SQL 查询。
强制参数化
通过指定将数据库中的所有 SELECT、 INSERT、 UPDATE和 DELETE 语句参数化,可以覆盖 SQL Server 的默认简单参数化行为(但会受到某些限制)。 通过在 PARAMETERIZATION 语句中将 FORCED 选项设置为 ALTER DATABASE 可以启用强制参数化。 通过降低查询编译和重新编译的频率,强制参数化可提高某些数据库的性能。 能够受益于强制参数化的数据库通常是需要处理来自源(例如,销售点应用程序)的大量并发查询的数据库。
当 PARAMETERIZATION 选项设置为 FORCED时, SELECT、 INSERT、 UPDATE或 DELETE 语句中出现的任何文本值(无论以什么形式提交)都将在查询编译期间转换为参数。 但下列查询构造中出现的文本例外:
INSERT...EXECUTE语句。- 存储过程、触发器或用户定义函数的正文中包含的语句。 SQL Server 已对这些例程重用了查询计划。
- 已在客户端应用程序中参数化的预定义语句。
- 包含 XQuery 方法调用的语句,此方法将出现在其参数通常都会被参数化的上下文(例如,
WHERE子句)中。 如果方法出现在参数不会参数化的上下文中,则会参数化该语句的其余部分。 - Transact-SQL 游标内的语句。 (API 游标内的
SELECT语句将参数化。) - 不推荐使用的查询构造。
- 在
ANSI_PADDING或ANSI_NULLS上下文中运行的任何语句都设置为OFF。 - 包含 2,097 个以上的可参数化文字的语句。
- 引用变量的语句,例如,
WHERE T.col2 >= @bb。 - 包含
RECOMPILE查询提示的语句。 - 包含
COMPUTE子句的语句。 - 包含
WHERE CURRENT OF子句的语句。
另外,未参数化下面的查询子句。 在这些情况下,只有子句未参数化。 同一查询中的其他子句或许可以进行强制参数化。
- 任何
SELECT语句的 <select_list>。 这包括子查询的SELECT列表和INSERT语句内的SELECT列表。 SELECT语句中出现的子查询IF语句。- 查询的
TOP、TABLESAMPLE、HAVING、GROUP BY、ORDER BY、OUTPUT...INTO或FOR XML子句。 OPENROWSET、OPENQUERY、OPENDATASOURCE、OPENXML或任意FULLTEXT运算符的参数(直接或作为子表达式)。LIKE子句的模式和 escape_character 参数。CONVERT子句的样式参数。IDENTITY子句中的整数常数。- 使用 ODBC 扩展语法指定的常数。
- 可折叠常数表达式,它们是
+、-、*、/和%运算符的参数。 考虑是否能够进行强制参数化时,当以下条件之一成立时,SQL Server 将认为表达式是可折叠常数表达式:- 表达式中没有列、变量、或子查询。
- 表达式包含
CASE子句。
- 查询提示子句的参数。 这些参数包括
FAST查询提示的 number_of_rows 参数、MAXDOP查询提示的 number_of_processors 参数,以及MAXRECURSION查询提示的 number 参数。
参数化在单条 Transact-SQL 语句内发生。 即,批处理中的单条语句将参数化。 在编译之后,参数化查询将在它最初提交时所在的批的上下文中执行。 如果缓存了查询的执行计划,则可以通过引用 sys.syscacheobjects 动态管理视图的 sql 列来确定此查询是否已参数化。 如果查询已参数化,则参数的名称和数据类型将出现在此列中已提交的批的文本前面(例如 @1 tinyint)。
注意
参数名称是任意的。 用户或应用程序不必拘泥于特定的命名顺序。 另外,下面的内容可能会因 SQL Server 版本不同以及 Service Pack 升级而异:参数名称、参数化文本的选择以及参数化文本中的间距。
参数的数据类型
当 SQL Server 参数化文本时,参数将转换为下列数据类型:
- 其大小适合 int 数据类型的整数文本将参数化为 int。对于较大的整数文本,如果它是包含任意比较运算符(包括
<、<=、=、!=、>、>=、!<、!>、<>、ALL、ANY、SOME、BETWEEN和IN)的谓词的组成部分,则将这些文本参数化为 numeric(38,0)。 如果不是包含比较运算符的谓词的组成部分,则此类文本将参数化为数字,其精度仅够表示其大小,并且没有小数位。 - 如果定点数值是包含比较运算符的谓词的组成部分,则此类数值将参数化为数字,其精度为 38,并且小数位数仅够表示其大小。 如果定点数值不是包含比较运算符的谓词的组成部分,则此类数值将参数化为数字,其精度和小数位数仅够表示其大小。
- 浮点数值将参数化为 float(53)。
- 如果非 Unicode 字符串文本在 8,000 个字符以内,将参数化为 varchar(8000),如果多于 8,000 个字符,则参数化为 varchar(max)。
- 如果 Unicode 字符串文本在 4,000 个字符以内,将参数化为 nvarchar(4000),如果多于 4,000 个字符,则参数化为 nvarchar(max)。
- 如果二进制文本在 8,000 字节以内,将参数化为 varbinary(8000)。 如果多于 8,000 字节,则转换为 varbinary(max)。
- Money 类型的文本,将参数化为 money。
强制参数化使用指南
当把 PARAMETERIZATION 选项设置为 FORCED 时考虑以下事项:
- 强制参数化实际上是在对查询进行编译时将查询中的文本常数更改为参数。 因此,查询优化器可能会选择不太理想的查询计划。 尤其是查询优化器不太可能将查询与索引视图或计算列索引相匹配。 此外,还可能会选择对分区表和分布式分区视图执行的不太理想的查询计划。 强制参数化不能用于高度依赖索引视图和计算列索引的环境。 通常,只有在确定执行此操作不会对性能产生负面影响后,经验丰富的数据库管理员才应使用
PARAMETERIZATION FORCED选项。 - 一旦(上下文中正在执行查询的)数据库中的
PARAMETERIZATION选项设置为FORCED,则引用了多个数据库的分布式查询即可进行强制参数化。 - 将
PARAMETERIZATION选项设置为FORCED将刷新数据库的计划缓存中的所有查询计划,当前正在编译、重新编译或执行的查询除外。 在设置更改时正在编译或执行的查询计划将在下次执行时参数化。 - 设置
PARAMETERIZATION选项是一项联机操作,它不需要数据库级别的排他锁。 - 在重新附加或还原数据库时,
PARAMETERIZATION选项的当前设置将保留。
您可以指定对单个查询和其他语法相同只有参数值不同的查询进行简单参数化,以覆盖强制参数化行为。 相反,即使数据库中禁用了强制参数化,您也可以指定仅对一组语法相同的查询进行强制参数化。 计划指南 具有此用途。
注意
PARAMETERIZATION 选项设置为 FORCED 时,错误消息的报告可能与 PARAMETERIZATION 选项设置为 SIMPLE 时不同:在强制参数化下可能会报告多条错误消息,而在简单参数化下可能报告的消息条数较少,并且可能无法准确报告出现错误的行号。
准备 SQL 语句
SQL Server 关系引擎完全支持在执行 SQL 语句前准备 Transact-SQL 语句。 如果应用程序需要多次执行 Transact-SQL 语句,可以使用数据库 API 来执行下列操作:
- 准备一次语句。 这将 Transact-SQL 语句编译为执行计划。
- 每当需要执行语句时都会执行预编译的执行计划。 这可防止第一次执行 Transact-SQL 语句后,必须在每次执行时重新编译。 语句的准备和执行由 API 函数和方法控制。 它不属于 Transact-SQL 语言。 SQL Server Native Client OLE DB 访问接口和 SQL Server Native Client ODBC 驱动程序支持用于执行 Transact-SQL 语句的准备/执行模型。 在准备请求中,提供程序或驱动程序将语句发送到 SQL Server,其中包含准备语句的请求。 SQL Server 编译执行计划,并向提供程序或驱动程序返回该计划的句柄。 在请求执行时,访问接口或驱动程序向服务器发送请求以执行与句柄相关联的计划。
预定义语句不能用于在 SQL Server 上创建临时对象。 预定义语句不能引用创建临时对象(如临时表)的系统存储过程。 必须直接执行这些过程。
过多地使用准备/执行模型会降低性能。 如果一条语句只执行一次,直接执行只需要与服务器进行一次网络往返。 准备并执行只执行一次的 Transact-SQL 语句,则需要多进行一次网络往返;一次是准备语句,一次是执行语句。
如果使用参数标记,可更有效地准备语句。 例如,假设可能偶尔让应用程序从 AdventureWorks 示例数据库检索产品信息。 应用程序可以采用两种方法执行此操作。
使用第一种方法,应用程序可以为请求的每个产品执行一个单独的查询:
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductID = 63;
使用第二种方法,应用程序可以执行下列操作:
准备带参数标记 (?) 的语句:
SELECT * FROM AdventureWorks2022.Production.Product WHERE ProductID = ?;将程序变量绑定到参数标记上。
每次需要产品信息时,用键值填充绑定的变量,然后执行该语句。
如果执行语句的次数多于三次,第二种方法更有效。
在 SQL Server 中,由于 SQL Server 会重用执行计划,因此准备/执行模型相对于直接执行没有显著的性能优势。 SQL Server 具有有效的算法,可以将当前的 Transact-SQL 语句与之前执行同一个 Transact-SQL 语句时生成的执行计划进行匹配。 如果应用程序使用参数标记多次执行一个 Transact-SQL 语句,SQL Server 将在第二次以及后续执行中重新使用第一次执行的执行计划(除非该计划已在计划缓存中老化)。 准备/执行模型还具有下列优点:
- 与通过算法将 Transact-SQL 语句与现有执行计划进行匹配的方法相比,通过识别句柄查找执行计划的方法更有效。
- 应用程序可以控制何时创建和重新使用执行计划。
- 准备/执行模型可移植到其他数据库,包括早期版本的 SQL Server。
参数敏感度
参数敏感度,也称为“参数探查”,是指 SQL Server 在编译或重新编译期间“探查”当前参数值,并将其传递给查询优化器,以便将这些参数值用于生成可能更高效的查询执行计划的这一过程。
在编译或重新编译期间,将针对以下类型的批处理对参数值进行探查:
- 存储过程
- 通过
sp_executesql提交的查询 - 预定义查询
有关排查错误参数探查问题的详细信息,请参阅:
- 调查并解决参数敏感问题
- 参数和执行计划的重复使用
- 参数敏感计划优化
- 排查 Azure SQL 数据库中具有参数敏感查询执行计划问题的查询
- 排查 Azure SQL 托管实例中具有参数敏感查询执行计划问题的查询
注意
对于使用 RECOMPILE 提示的查询,将探查参数值和局部变量的当前值。 探查的参数值和局部变量值在批处理中所处的位置刚好就在具有 RECOMPILE 提示的语句前面。 特别是,对于参数,不会探查随批处理调用而出现的值。
并行查询处理
SQL Server 为具有多个微处理器 (CPU) 的计算机提供了并行查询,以优化查询执行和索引操作。 由于 SQL Server 可以使用多个操作系统工作线程并行执行查询或索引操作,因此,可以快速有效地完成操作。
在查询优化过程中,SQL Server 将查找可能会受益于并行执行的查询或索引操作。 对于这些查询,SQL Server 会将交换运算符插入查询执行计划中,以便为查询的并行执行做准备。 交换运算符是在查询执行计划中提供进程管理、数据再分发和流控制的运算符。 交换运算符包含作为子类型的 Distribute Streams、 Repartition Streams和 Gather Streams 逻辑运算符,其中的一个或多个运算符会出现在并行查询的查询计划的显示计划输出中。
重要
某些构造禁止 SQL Server 在整个执行计划或部分执行计划中利用并行度的功能。
禁止并行度的构造包括:
标量 UDF
有关标量用户定义函数的详细信息,请参阅创建用户定义函数。 从 SQL Server 2019 (15.x) 开始,SQL Server 数据库引擎能够内联这些函数,并在查询处理期间解锁并行度的使用。 有关标量 UDF 内联的详细信息,请参阅 SQL 数据库中的智能查询处理。远程查询
有关远程查询的详细信息,请参阅 Showplan 逻辑运算符和物理运算符参考。动态游标
有关游标的详细信息,请参阅 DECLARE CURSOR。递归查询
有关递归的详细信息,请参阅定义和使用递归公用表表达式的准则和 T-SQL 中的递归。多语句表值函数 (MSTVF)
有关 MSTVF 的详细信息,请参阅创建用户定义函数(数据库引擎)。TOP 关键字
有关详细信息,请参阅 TOP (Transact-SQL)。
查询执行计划可能包含 QueryPlan 元素中的 NonParallelPlanReason 属性,该属性描述未使用并行度的原因。 此属性的值包括:
| NonParallelPlanReason 值 | 说明 |
|---|---|
| MaxDOPSetToOne | 最大并行度设为 1。 |
| EstimatedDOPIsOne | 估计并行度为 1。 |
| NoParallelWithRemoteQuery | 远程查询不支持并行度。 |
| NoParallelDynamicCursor | 动态游标不支持并行计划。 |
| NoParallelFastForwardCursor | 快进游标不支持并行计划。 |
| NoParallelCursorFetchByBookmark | 按书签提取的游标不支持并行计划。 |
| NoParallelCreateIndexInNonEnterpriseEdition | 非企业版不支持创建并行索引。 |
| NoParallelPlansInDesktopOrExpressEdition | 桌面版和 Express 版不支持并行计划。 |
| NonParallelizableIntrinsicFunction | 查询引用不可并行的内部函数。 |
| CLRUserDefinedFunctionRequiresDataAccess | 需要数据访问的 CLR UDF 不支持并行。 |
| TSQLUserDefinedFunctionsNotParallelizable | 查询引用不可并行的 T-SQL 用户定义函数。 |
| TableVariableTransactionsDoNotSupportParallelNestedTransaction | 表变量事务不支持并行嵌套事务。 |
| DMLQueryReturnsOutputToClient | DML 查询将输出返回到客户端,并且不可并行化。 |
| MixedSerialAndParallelOnlineIndexBuildNotSupported | 单个联机索引生成的串行和并行计划组合不受支持。 |
| CouldNotGenerateValidParallelPlan | 验证并行计划失败,故障回复到串行计划。 |
| NoParallelForMemoryOptimizedTables | 引用的内存中 OLTP 表不支持并行。 |
| NoParallelForDmlOnMemoryOptimizedTable | 内存中 OLTP 表上的 DML 不支持并行。 |
| NoParallelForNativelyCompiledModule | 引用的本机编译模块不支持并行。 |
| NoRangesResumableCreate | 可恢复的创建操作的范围生成失败。 |
插入交换运算符之后,结果便为并行查询执行计划。 并行查询执行计划可以使用多个工作线程。 非并行(串行)查询使用的串行执行计划仅使用一个工作线程来实现执行。 并行查询使用的实际工作线程数在查询计划执行初始化时确定,并由计划的复杂程度和并行度确定。
并行度 (DOP) 确定正在使用的最大 CPU 数;它并不表示正在使用的工作线程数。 DOP 限制根据任务设置。 它不是按请求限制或按查询限制。 这意味着,在并行查询期间,单个请求可以生成多个任务,然后将它们分配给计划程序。 并发执行不同的任务时,可能会在任意给定的查询执行点同时使用超过 MAXDOP 指定数量的处理器。 有关详细信息,请参阅线程和任务体系结构指南。
如果满足以下任一条件,则 SQL Server 查询优化器不会对查询使用并行执行计划:
- 串行执行计划是微不足道的,或者不会超过并行度设置的开销阈值。
- 串行执行计划的总估计子树开销低于优化器探索的任何并行执行计划。
- 查询包含无法并行运行的标量运算符或关系运算符。 某些运算符可能会导致查询计划的一部分以串行模式运行,或者导致整个计划以串行模式运行。
注意
并行计划的总估计子树成本可能低于并行度设置的开销阈值。 这表示串行计划的总估计子树开销高于该阈值,并且选择了总估计子树开销较低的查询计划。
并行度 (DOP)
SQL Server 自动检测每个并行查询执行或索引数据定义语言 (DDL) 操作实例的最佳并行度。 此操作所依据的条件如下:
SQL Server 是否在具有多个微处理器或 CPU 的计算机(例如对称多处理计算机 (SMP))上运行。 只有具有多个 CPU 的计算机才能使用并行查询。
可用的工作线程是否足够。 每个查询或索引操作均要求一定数量的工作线程才能执行。 执行并行计划比执行串行计划需要更多的工作线程,所需工作线程数会随着并行度的提高而增加。 无法满足特定并行度的并行计划的工作线程要求时,SQL Server 数据库引擎将自动减少并行度或完全放弃指定的工作负荷上下文中的并行计划。 然后执行串行计划(一个工作线程)。
所执行的查询或索引操作的类型。 创建索引、重新生成索引或删除聚集索引等索引操作,以及大量占用 CPU 周期的查询最适合采用并行计划。 例如,大型表的联接、大型的聚合和大型结果集的排序等都很适合采用并行计划。 对于简单查询(常用于事务处理应用程序)而言,执行并行查询所需的额外协调工作会大于潜在的性能提升。 为了区分能够从并行计划中受益的查询和不能从中受益的查询,SQL Server 数据库引擎将比较执行查询或索引操作的估计开销与并行度的开销阈值。 如果适合性测试发现其他值更适合正在运行的工作负载,用户可以使用 sp_configure 更改默认值 5。
待处理的行数是否足够。 如果查询优化器确定行数太少,则不引入交换运算符来分发行。 因此,将串行执行运算符。 以串行计划执行运算符可避免出现这样的情况:启动、分发和协调的开销超过并行执行运算符所获得的收益。
当前的分发内容统计信息是否可用。 如果不能达到最高并行度,则在放弃并行计划之前会考虑较低的并行度。 例如,创建视图的聚集索引后,将无法评估分发内容统计信息,因为聚集索引尚不存在。 在此情况下,SQL Server 数据库引擎无法为索引操作提供最高并行度。 不过,某些运算符(例如,排序和扫描)仍能从并行执行中获益。
注意
并行索引操作只能在 SQL Server Enterprise、Developer 和 Evaluation 版本中使用。
执行时,SQL Server 数据库引擎将确定当前系统工作负荷和前面介绍的配置信息是否允许并行执行。 如果可以确保并行执行,SQL Server 数据库引擎将确定最佳工作线程数,并在这些工作线程间分配并行计划的执行。 从查询或索引操作开始在多工作线程上并行执行起,将一直使用相同的工作线程数,直到操作完成。 每次从计划缓存中检索执行计划时,SQL Server 数据库引擎都会重新检查最佳工作线程决策数。 例如,第一次执行某个查询时最终采用了串行计划,后来第二次执行相同的查询将使用三个工作线程的并行计划,第三次执行将使用四个工作线程的并行计划。
并行查询执行计划中的 update 和 delete 运算符将按顺序执行,但 WHERE 或 UPDATE 语句的 DELETE 子句可以并行执行。 之后,实际的数据更改将串行应用到数据库。
从 SQL Server 2012 (11.x) 开始,还会按顺序执行 insert 运算符。 但是,可以并行执行 INSERT 语句的 SELECT 部分。 之后,实际的数据更改将串行应用到数据库。
从 SQL Server 2014 (12.x) 和数据库兼容性级别 110 开始,可以并行执行 SELECT ... INTO 语句。 其他形式的 insert 运算符的工作方式与 SQL Server 2012 (11.x) 的方式相同。
从 SQL Server 2016 (13.x) 和数据库兼容性级别 130 开始,在插入堆或聚集列存储索引 (CCI),以及使用 TABLOCK 提示时,可以并行执行 INSERT ... SELECT 语句。 还可以使用 TABLOCK 提示为并行启用到本地临时表(由 # 前缀标识)和全局临时表(由 ## 前缀标识)的插入。 有关详细信息,请参阅 INSERT (Transact-SQL)。
并行执行计划可以填充静态和由键集驱动的游标。 然而,只有串行执行可以提供动态游标行为。 查询优化器始终为查询生成串行执行计划,这是动态游标的一部分。
覆盖并行度
并行度设置并行计划执行中要使用的处理器数量。 此配置可以在不同级别设置:
服务器级别,使用最大并行度 (MAXDOP) 服务器配置选项。
适用范围:SQL Server注意
SQL Server 2019 (15.x) 引入了在安装过程中设置 MAXDOP 服务器配置选项的自动建议。 安装程序用户界面允许接受建议的设置或输入自己的值。 有关详细信息,请参阅“数据库引擎配置 - MaxDOP”页。
工作负载级别:使用 MAX_DOP Resource Governor 工作负载组配置选项。
适用范围:SQL Server数据库级别:使用 MAXDOP 数据库范围配置。
适用范围:SQL Server 和 Azure SQL 数据库查询或索引语句级别:使用 MAXDOP 查询提示 或 MAXDOP 索引选项。 例如,可以使用 MAXDOP 选项来控制(增加或减少)联机索引操作的专用处理器数。 通过这种方式,你就可以在并发用户间平衡索引操作所使用的资源。
适用范围:SQL Server 和 Azure SQL 数据库
将“最大并行度”选项设置为 0 (默认值),可使 SQL Server 在执行并行计划时使用所有可用的处理器(最多可达 64 台处理器)。 尽管 MAXDOP 选项设置为 0 时,SQL Server 会将运行时目标设置为 64 个逻辑处理器,但如果需要,可以手动设置不同的值。 针对查询和索引将 MAXDOP 选项设置为 0 时,将允许 SQL Server 在执行并行计划时针对给定的查询或索引使用所有可用的处理器(最大可达 64 个处理器)。 MAXDOP 并不是所有并行查询的强制值,而是符合并行度要求的所有查询的暂定目标值。 这意味着,如果在运行时没有足够的可用工作线程,查询可能会以比 MAXDOP 服务器配置选项更低的并行度执行。
提示
有关详细信息,请参阅 MAXDOP 建议,了解有关在服务器、数据库、查询或提示级别配置 MAXDOP 的指南。
并行查询示例
以下查询计算指定季度(自 2000 年 4 月 1 日开始)内下的订单数,其中至少有一个订单项的客户接收日期晚于提交日期。 该查询列出这类订单的计数,按每个订单的优先级分组并按优先级升序排序。
下例使用理论表名和列名。
SELECT o_orderpriority, COUNT(*) AS Order_Count
FROM orders
WHERE o_orderdate >= '2000/04/01'
AND o_orderdate < DATEADD (mm, 3, '2000/04/01')
AND EXISTS
(
SELECT *
FROM lineitem
WHERE l_orderkey = o_orderkey
AND l_commitdate < l_receiptdate
)
GROUP BY o_orderpriority
ORDER BY o_orderpriority
假设以下索引在 lineitem 和 orders 表中进行定义:
CREATE INDEX l_order_dates_idx
ON lineitem
(l_orderkey, l_receiptdate, l_commitdate, l_shipdate)
CREATE UNIQUE INDEX o_datkeyopr_idx
ON ORDERS
(o_orderdate, o_orderkey, o_custkey, o_orderpriority)
下面是为前面显示的查询生成的一种可能的并行计划:
|--Stream Aggregate(GROUP BY:([ORDERS].[o_orderpriority])
DEFINE:([Expr1005]=COUNT(*)))
|--Parallelism(Gather Streams, ORDER BY:
([ORDERS].[o_orderpriority] ASC))
|--Stream Aggregate(GROUP BY:
([ORDERS].[o_orderpriority])
DEFINE:([Expr1005]=Count(*)))
|--Sort(ORDER BY:([ORDERS].[o_orderpriority] ASC))
|--Merge Join(Left Semi Join, MERGE:
([ORDERS].[o_orderkey])=
([LINEITEM].[l_orderkey]),
RESIDUAL:([ORDERS].[o_orderkey]=
[LINEITEM].[l_orderkey]))
|--Sort(ORDER BY:([ORDERS].[o_orderkey] ASC))
| |--Parallelism(Repartition Streams,
PARTITION COLUMNS:
([ORDERS].[o_orderkey]))
| |--Index Seek(OBJECT:
([tpcd1G].[dbo].[ORDERS].[O_DATKEYOPR_IDX]),
SEEK:([ORDERS].[o_orderdate] >=
Apr 1 2000 12:00AM AND
[ORDERS].[o_orderdate] <
Jul 1 2000 12:00AM) ORDERED)
|--Parallelism(Repartition Streams,
PARTITION COLUMNS:
([LINEITEM].[l_orderkey]),
ORDER BY:([LINEITEM].[l_orderkey] ASC))
|--Filter(WHERE:
([LINEITEM].[l_commitdate]<
[LINEITEM].[l_receiptdate]))
|--Index Scan(OBJECT:
([tpcd1G].[dbo].[LINEITEM].[L_ORDER_DATES_IDX]), ORDERED)
下图显示了一个查询计划,该计划按并行度等于 4 执行且包括一个双表联接。
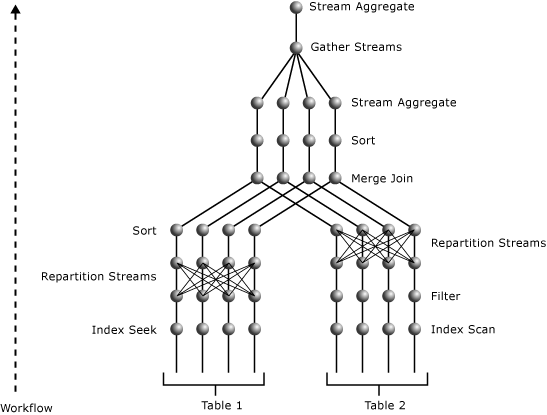
这个并行计划包含三个并行运算符。 o_datkey_ptr 索引的 Index Seek 运算符和 l_order_dates_idx 索引的 Index Scan 运算符都会并行执行。 将生成若干排他流。 这可以分别通过 Index Scan 和 Index Seek 运算符上面最接近的 Parallelism 运算符来确定。 二者都在对交换类型重新分区。 即它们正在流之间重新组织数据并生成与输入数量相同的输出流。 这个流数等于并行度。
l_order_dates_idx Index Scan 运算符上面的 parallelism 运算符正在将 L_ORDERKEY 的值用作键来对其输入流重新分区。 这样, L_ORDERKEY 的相同值将得到相同的输出流。 同时,输出流维护 L_ORDERKEY 列的顺序,以满足 Merge Join 运算符的输入要求。
Index Seek 运算符上面的 parallelism 运算符正在使用 O_ORDERKEY 的值对其输入流重新分区。 由于其输入没有按照 O_ORDERKEY 列的值进行排序,而且这是 Merge Join 运算符中的联接列,所以 parallelism 和 Merge Join 运算符之间的 Sort 运算符确保为联接列上的 Merge Join 运算符进行输入排序。 与 Merge Join 运算符一样,Sort 运算符也是并行执行的。
最上面的 parallelism 运算符将若干流的结果收集成一个流。 之后,该 parallelism 运算符下方的 Stream Aggregate 运算符所执行的部分聚合被聚集到单个的 SUM 值中,这个值是该 parallelism 运算符上方的 Stream Aggregate 运算符中每个不同的 O_ORDERPRIORITY 值之和。 因为此计划有两个交换部分,且并行度等于 4,所以它使用了八个工作线程。
有关此示例中使用的运算符的详细信息,请参阅 Showplan 逻辑运算符和物理运算符参考。
并行索引操作
为创建或重新生成索引或删除聚集索引的索引操作生成的查询计划允许在有多个微处理器的计算机上执行并行、多工作线程操作。
注意
并行索引操作只能在从 SQL Server 2008 (10.0.x) 开始的企业版中使用。
SQL Server 使用与其用于其他查询的相同算法来确定索引操作的并行度(单独运行的工作线程的总数)。 索引操作的最大并行度由 max degree of parallelism 服务器配置选项确定。 通过在 CREATE INDEX、ALTER INDEX、DROP INDEX 和 ALTER TABLE 语句中设置 MAXDOP 索引选项,可以覆盖单个索引操作的最大并行度值。
当 SQL Server 数据库引擎生成索引执行计划时,并行操作数设置为以下值中的最小值:
- 计算机中的微处理器 (CPU) 数。
- 最大并行度服务器配置选项中指定的数目。
- 尚未超过为 SQL Server 工作线程执行的工作阈值的 CPU 数。
例如,在具有 8 个 CPU 的计算机上,而最大并行度设置为 6,则为索引操作生成的并行工作线程数不超过 6 个。 如果在生成索引执行计划时计算机中的 5 个 CPU 超出了 SQL Server 工作的阈值,则执行计划仅指定三个并行工作线程。
并行索引操作的主要阶段包括:
- 协调工作线程快速并随机地扫描表,以估计索引键的分布情况。 协调工作线程建立键的边界,这将创建若干与并行操作度相等的键范围,其中每个键范围所包含的行数都差不多。 例如,如果表中有四百万行,并行度为 4,则协调工作线程确定用于将行分为四个行集的键值,其中每个行集中包含 1 百万行。 如果无法建立足以使用所有 CPU 的键范围,则并行度也将相应降低。
- 协调工作线程分派与并行操作度相等的若干工作线程,并等待这些工作线程完成它们的工作。 每个工作线程都使用筛选器扫描基表,筛选器只检索键值位于分配给工作线程的范围内的行。 每个工作线程都为其键范围内的行生成索引结构。 在已分区索引的情况下,每个工作线程将生成指定数目的分区。 工作线程之间不能共享分区。
- 当所有并行工作线程都完成后,协调工作线程将索引子单元连接到单个索引中。 此阶段只适用于脱机索引操作。
个别 CREATE TABLE 或 ALTER TABLE 语句可以有多个要求创建索引的约束。 虽然每个单独的索引创建操作可能是具有多个 CPU 的计算机上的并行操作,但是这些多个索引创建操作连续执行。
分布式查询体系结构
Microsoft SQL Server 支持两种用于在 Transact-SQL 语句中引用异类 OLE DB 数据源的方法:
链接服务器名称
系统存储过程sp_addlinkedserver和sp_addlinkedsrvlogin用于给 OLE DB 数据源提供服务器名称。 可以在 Transact-SQL 语句中使用由四个部分构成的名称引用这些链接服务器中的对象。 例如,如果DeptSQLSrvr的一个链接服务器名称是用另一个 SQL Server 的实例定义的,则下面的语句引用该服务器上的一个表:SELECT JobTitle, HireDate FROM DeptSQLSrvr.AdventureWorks2022.HumanResources.Employee;也可以在
OPENQUERY语句中指定链接服务器名称以从 OLE DB 数据源打开一个行集。 之后,可以在 Transact-SQL 语句中像引用表一样引用该行集。即席连接器名称
在很少引用数据源时,OPENROWSET或OPENDATASOURCE函数是用连接到链接服务器所需的信息指定的。 之后,可以在 Transact-SQL 语句中使用与引用表相同的方法引用行集:SELECT * FROM OPENROWSET('Microsoft.Jet.OLEDB.4.0', 'c:\MSOffice\Access\Samples\Northwind.mdb';'Admin';''; Employees);
SQL Server 使用 OLE DB 在关系引擎和存储引擎之间通信。 关系引擎将每个 Transact-SQL 语句分解为一系列操作,这些操作在由存储引擎从基表打开的简单 OLE DB 行集上执行。 这意味着关系引擎也可以在任何 OLE DB 数据源上打开简单 OLE DB 行集。
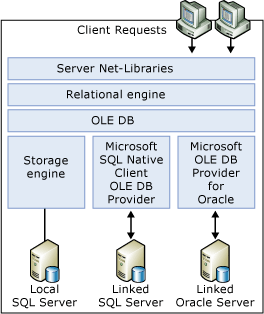
关系引擎使用 OLE DB 应用程序编程接口 (API) 打开链接服务器上的行集、提取行并管理事务。
对于每个作为链接服务器访问的 OLE DB 数据源,运行 SQL Server 的服务器上必须存在 OLE DB 提供程序。 在特定 OLE DB 数据源上可执行哪些 Transact-SQL 操作取决于 OLE DB 提供程序的功能。
对于每个 SQL Server 实例, sysadmin 固定服务器角色的成员可以使用 SQL Server DisallowAdhocAccess 属性启用或禁用对 OLE DB 提供程序使用即席连接器名称。 如果启用了即席访问,则任何登录到该实例的用户都可以执行包含即席连接器名称的 Transact-SQL 语句,该即席连接器名称引用了网络中可以通过 OLE DB 访问接口访问的任何数据源。 为了控制对数据源的访问,sysadmin 角色的成员可以对该 OLE DB 提供程序禁用即席访问,从而限制用户只能访问由管理员定义的链接服务器名称所引用的那些数据源。 默认情况下,对 SQL Server OLE DB 提供程序启用即席访问,而对所有其他的 OLE DB 提供程序禁用即席访问。
分布式查询可允许用户使用运行 SQL Server 服务的 Microsoft Windows 帐户的安全上下文来访问其他数据源(例如,文件、非关系数据源 [如 Active Directory] 等)。 SQL Server 可以正确模拟 Windows 登录名,但不能模拟 SQL Server 登录名。 这样,就有可能使分布式查询用户能够访问自己本没有访问权限、但运行 SQL Server 服务的帐户有访问权限的另一数据源。 使用 sp_addlinkedsrvlogin 定义被授权访问相应链接服务器的特定登录名。 此控制对即席名称无效,所以对 OLE DB 访问接口启用即席访问时要小心。
如果可能,SQL Server 会将联接、限制、投影、排序以及按操作划分的组等关系操作推送到 OLE DB 数据源。 SQL Server 默认不会将基表扫描到 SQL Server 中,也不会执行关系运算本身。 SQL Server 会查询 OLE DB 提供程序,确定其支持的 SQL 语法级别,并根据该信息向提供程序推送尽可能多的关系操作。
SQL Server 指定 OLE DB 提供程序返回统计信息的机制,该统计信息指明键值在 OLE DB 数据源内的分布情况。 这使 SQL Server 查询优化器可以根据每条 Transact-SQL 语句的要求,更好地分析数据源中的数据模式,从而提高查询优化器生成最佳执行计划的能力。
针对已分区表和索引的查询处理增强功能
SQL Server 2008 (10.0.x) 改进了许多并行计划的已分区表的查询处理性能,更改了并行和串行计划的表示方式,并增强了编译时和运行时执行计划中所提供的分区信息。 本文介绍了这些改进,提供了有关如何解释已分区表和索引的查询执行计划的指导,并提供改进已分区对象的查询性能的最佳做法。
注意
在 SQL Server 2014 (12.x) 之前,只有 SQL Server Enterprise Edition、Developer Edition 和 Evaluation Edition 支持已分区表和已分区索引。 从 SQL Server 2016 (13.x) SP1 开始,SQL Server Standard 版本也支持已分区表和索引。
新增的可识别分区的查找操作
在 SQL Server 中,已分区表的内部表示形式已发生变化,确保呈现给查询处理器的表为多列索引( PartitionID 作为起始列)。 PartitionID 是一个内部使用的隐藏计算列,用于表示包含特定行的分区的 ID 。 例如,假设一个定义为 T(a, b, c)的表 T 在 a 列进行了分区,并在 b 列有聚集索引。 在 SQL Server 中,此已分区表在内部被视为一个具有架构 T(PartitionID, a, b, c) 和具有组合键 (PartitionID, b)的聚集索引的未分区表。 这样查询优化器便可以基于 PartitionID 对任何已分区表或索引执行查找操作。
现在,分区的排除任务已在此查找操作中完成。
In addition, the Query Optimizer is extended so that a seek or scan operation with one condition can be done on PartitionID (作为逻辑首列)以及其他可能的索引键列执行某一条件下的查找或扫描操作,然后,对于符合第一级查找操作的条件的每个不同值,再针对一个或多个其他列执行不同条件下的二级查找。 也就是说,这种称为“跳跃扫描”的操作允许查询优化器基于某一条件来执行查找或扫描操作以确定要访问的分区,然后在该运算符内执行一个二级索引查找操作以返回这些分区中符合另一个不同条件的行。 例如,请考虑以下查询。
SELECT * FROM T WHERE a < 10 and b = 2;
对于本示例,假设定义为 T(a, b, c)的表 T 在 a 列进行了分区,并在 b 列有聚集索引。 表 T 的分区边界由以下分区函数定义:
CREATE PARTITION FUNCTION myRangePF1 (int) AS RANGE LEFT FOR VALUES (3, 7, 10);
为求解该查询,查询处理器将执行第一级查找操作以查找包含符合条件 T.a < 10的行的每个分区。 这将标识要访问的分区。 然后,在标识的每个分区内,处理器将针对 b 列的聚集索引执行一个二级查找以查找符合条件 T.b = 2 和 T.a < 10的行。
下图所示为跳跃扫描操作的逻辑表示形式, 其中显示了在 T 列和 a 列中包含数据的表 b。 分区编号为 1 到 4,分区边界由垂直虚线表示。 对分区执行的第一级查找操作(图中未显示)已确定分区 1、2 和 3 符合查找条件(由为该表定义的分区和 a 列的谓词指示), 即 T.a < 10。 曲线指示了跳跃扫描操作的二级查找部分所遍历的路径。 实际上,跳跃扫描操作将在这些分区的每个分区中查找符合条件 b = 2的行。 跳跃扫描操作的总开销等于三个单独索引查找之和。
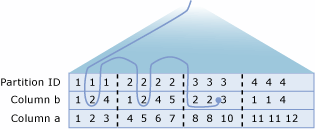
在查询执行计划中显示分区信息
可以使用 Transact-SQL SET 语句 SET SHOWPLAN_XML 或 SET STATISTICS XML,或者使用 SQL Server Management Studio 中的图形执行计划输出来检查已分区表和已分区索引上的查询执行计划。 例如,选择“查询编辑器”工具栏上的“显示估计的执行计划”可以显示编译时执行计划,选择“包括实际的执行计划”可以显示运行时计划。
使用这些工具,您可以确定以下信息:
- 访问已分区表或已分区索引的操作,如
scans、seeks、inserts、updates、merges和deletes。 - 查询访问的分区。 例如,运行时执行计划中包含所访问分区的总计数以及所访问的连续分区的范围。
- 何时在查找或扫描操作中使用跳跃扫描操作以便从一个或多个分区中检索数据。
增强的分区信息
SQL Server 为编译时执行计划和运行时执行计划都提供增强的分区信息。 现在,执行计划可以提供以下信息:
- 一个可选的
Partitioned属性,它指示对某已分区表执行某个运算符(例如seek、scan、insert、update、merge或delete)。 - 一个新增的
SeekPredicateNew元素,它带有SeekKeys子元素,其中包含PartitionID(作为第一个索引键列)和筛选条件(指定针对PartitionID的查找范围)。 如果存在两个SeekKeys子元素,则表明对PartitionID使用了跳跃扫描操作。 - 用于提供所访问分区的总计的摘要信息。 只有在运行时计划中才有此信息。
为演示此信息在图形执行计划输出和 XML 显示计划输出中的显示方式,请考虑对已分区表 fact_sales的以下查询。 此查询将更新两个分区中的数据。
UPDATE fact_sales
SET quantity = quantity - 2
WHERE date_id BETWEEN 20080802 AND 20080902;
下图显示了此查询的运行时执行计划中 Clustered Index Seek 运算符的属性。 要查看 fact_sales 表的定义和分区定义,请参阅本文中的“示例”。

已分区属性
对已分区表或已分区索引执行某个运算符(例如 Index Seek )时,Partitioned 属性将出现在编译时和运行时计划中并设置为 True (1)。 当属性设置为 False (0) 时,将不会显示该属性。
Partitioned 属性可以出现在以下物理和逻辑运算符中:
- Table Scan
- Index Scan
- Index Seek
- 插入
- 更新
- 删除
- 合并
如上图所示,该属性显示在包含其定义的运算符的属性中。 在 XML 显示计划输出中,该属性在包含其定义的运算符的 Partitioned="1" 节点中显示为 RelOp 。
新增的 Seek 谓词
在 XML 显示计划输出中, SeekPredicateNew 元素出现在包含其定义的运算符中。 它最多可以包含两个 SeekKeys 子元素实例。 第一个 SeekKeys 实例项指定位于逻辑索引的分区 ID 级别的第一级查找操作。 也就是说,该查找操作将确定为满足查询条件而必须访问的分区。 第二个 SeekKeys 实例项指定在第一级查找中所标识的每个分区中进行的跳跃扫描操作的二级查找部分。
分区摘要信息
在运行时执行计划中,分区摘要信息提供了所访问分区的计数以及所访问的实际分区的标识。 您可以使用此信息来验证查询中所访问的分区是否正确以及所有其他分区是否均排除在外。
提供以下信息: Actual Partition Count和 Partitions Accessed。
Actual Partition Count 是查询所访问的分区总数。
在 XML 显示计划输出中,Partitions Accessed是显示在新的 RuntimePartitionSummary 元素中的分区摘要信息,此元素位于包含其定义的运算符的 RelOp 节点中。 下面的示例显示了 RuntimePartitionSummary 元素的内容,它表明共访问了两个分区(分区 2 和 3)。
<RunTimePartitionSummary>
<PartitionsAccessed PartitionCount="2" >
<PartitionRange Start="2" End="3" />
</PartitionsAccessed>
</RunTimePartitionSummary>
使用其他显示计划方法来显示分区信息
显示计划方法 SHOWPLAN_ALL、SHOWPLAN_TEXT和 STATISTICS PROFILE 并不报告本文所述的分区信息,但以下情况例外。 作为 SEEK 谓词的一部分,要访问的分区由表示该分区 ID 的计算列上的范围谓词标识。 下面的示例演示 SEEK 运算符的 Clustered Index Seek 谓词。 访问的分区是分区 2 和 3,并且该查找运算符将筛选符合条件 date_id BETWEEN 20080802 AND 20080902的行。
|--Clustered Index Seek(OBJECT:([db_sales_test].[dbo].[fact_sales].[ci]),
SEEK:([PtnId1000] >= (2) AND [PtnId1000] \<= (3)
AND [db_sales_test].[dbo].[fact_sales].[date_id] >= (20080802)
AND [db_sales_test].[dbo].[fact_sales].[date_id] <= (20080902))
ORDERED FORWARD)
解释已分区堆的执行计划
已分区堆被视为分区 ID 的逻辑索引。 已分区堆的分区排除在执行计划中表示为一个 Table Scan 运算符,其中对分区 ID 使用了 SEEK 谓词。 下面的示例显示了所提供的显示计划信息:
|-- Table Scan (OBJECT: ([db].[dbo].[T]), SEEK: ([PtnId1001]=[Expr1011]) ORDERED FORWARD)
解释并置联接的执行计划
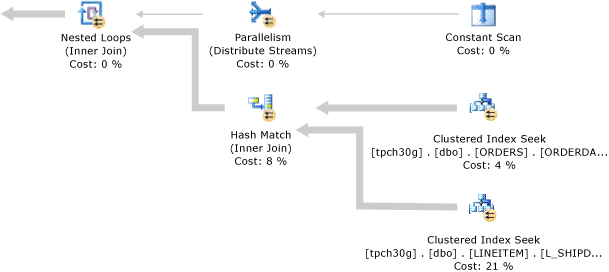
使用相同或等效的分区函数对两个表进行分区并且在查询的联接条件中指定了来自联接两侧的分区依据列时就会发生联接并置。 查询优化器可以生成一个计划,其中具有相等分区 ID 的每个表的分区将分别联接在一起。 并置联接可能比非并置联接的执行速度快,因为前者可以只需较少的内存和处理时间。 查询优化器会基于成本估计来选择非并置计划或并置计划。
在并置计划中, Nested Loops 联接从内侧读取一个或多个联接表或索引分区。 Constant Scan 运算符内的数字表示分区号。
为已分区表或已分区索引生成并置联接的并行计划时,在 Constant Scan 和 Nested Loops 联接运算符之间会出现一个 Parallelism 运算符。 在此情况下,在联接外侧的多个工作线程会各自在不同的分区上进行读取和操作。
下图显示了一个并置联接的并行查询计划。
已分区对象的并行查询执行策略
查询处理器对从已分区对象选择的查询使用查询执行策略。 作为执行策略的一部分,查询处理器会确定查询所需的表分区,以及要分配给每个分区的工作线程比例。 在大多数情况下,查询处理器会为每个分区分配数量相等或几乎相等的工作线程,然后在这些分区中并行地执行查询。 以下几段更详细地介绍了工作线程分配情况。
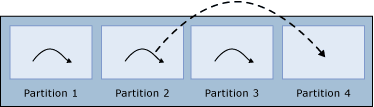
如果工作线程数小于分区数,则查询处理器会将每个工作线程分配给一个不同的分区,最初会有一个或多个分区没有获得分配的工作线程。 工作线程完成在一个分区上的执行时,查询处理器会将它分配给下一个分区,直到每个分区都分配有一个工作线程。 这是查询处理器将工作线程重新分配给其他分区的唯一情况。
显示在完成后重新分配的工作线程。 如果工作线程数与分区数相等,则查询处理器会为每个分区分配一个工作线程。 工作线程完成时,不会重新分配给另一个分区。

如果工作线程数大于分区数,则查询处理器会为每个分区分配相等数量的工作线程。 如果工作线程数并非恰好是分区数的倍数,则查询处理器会为某些分区额外分配一个工作线程,以便使用所有的可用工作线程。 如果只有一个分区,则会将所有工作线程都分配给该分区。 在下图中,有 4 个分区和 14 个工作线程。 每个分区都分配有 3 个工作线程,两个分区具有一个额外的工作线程,总共分配了 14 个工作线程。 工作线程完成时,不会重新分配给另一个分区。

尽管以上示例指出了一种分配工作线程的简单方式,但实际策略要复杂一些,并需要考虑在查询执行过程中出现的其他变化因素。 例如,如果表已分区,并在 A 列上有一个聚集索引,并且查询有谓词子句 WHERE A IN (13, 17, 25),则查询处理器将为这三个查找值(A=13、A=17 和 A=25)各分配一个或多个工作线程,而不是为每个表分区分配一个或多个工作线程。 只需在包含这些值的分区中执行查询,并且如果所有这些查找谓词都恰好在同一个表分区中,则所有工作线程都将分配给同一个表分区。
再举一个例子,假设表在 A 列上有四个分区,边界点为 (10, 20, 30),在 B 列上有一个索引,并且查询有谓词子句 WHERE B IN (50, 100, 150)。 由于表分区基于 A 的值,因此 B 的值可以出现在任何表分区中。 这样,查询处理器将分别在四个表分区中查找三个 B 值 (50, 100, 150) 中的每一个值。 查询处理器将按比例分配工作线程,以便它可以并行执行 12 个查询扫描中的每一个扫描。
| 基于 A 列的表分区 | 在每个表分区中查找 B 列 |
|---|---|
| 表分区 1:A < 10 | B=50, B=100, B=150 |
| 表分区 2:A >= 10 AND A < 20 | B=50, B=100, B=150 |
| 表分区 3:A >= 20 AND A < 30 | B=50, B=100, B=150 |
| 表分区 4:A > 30 | B=50, B=100, B=150 |
最佳实践
为提高访问来自大型已分区表和索引的大量数据的查询性能,我们建议采用以下最佳方法:
- 跨越许多磁盘创建各个条带化分区。 使用旋转型磁盘时,这一点尤为重要。
- 尽可能使用具有足够主内存的服务器以便在内存中保留频繁访问的分区或所有分区,以减少 I/O 开销。
- 如果内存容纳不下所查询的数据,请压缩表和索引。 这会减少 I/O 开销。
- 使用具有快速处理器的服务器以及尽可能多的处理器核,以充分利用并行查询处理能力。
- 确保服务器具有足够的 I/O 控制器带宽。
- 对每个大型已分区表创建聚集索引,以充分利用 B 树扫描优化。
- 向已分区的表中大容量加载数据时,请遵照白皮书 The Data Loading Performance Guide(数据加载性能指南)中的最佳做法建议操作。
示例
下面的示例创建一个测试数据库,其中包含一个带有七个分区的表。 执行本示例中的查询时请使用前面所述的工具以查看编译时计划和运行时计划的分区信息。
注意
本示例要向表中插入超过 100 万行数据。 具体取决于硬件情况,运行本示例可能需要几分钟时间。 在执行本示例之前,请确保您有超过 1.5 GB 的可用磁盘空间。
USE master;
GO
IF DB_ID (N'db_sales_test') IS NOT NULL
DROP DATABASE db_sales_test;
GO
CREATE DATABASE db_sales_test;
GO
USE db_sales_test;
GO
CREATE PARTITION FUNCTION [pf_range_fact](int) AS RANGE RIGHT FOR VALUES
(20080801, 20080901, 20081001, 20081101, 20081201, 20090101);
GO
CREATE PARTITION SCHEME [ps_fact_sales] AS PARTITION [pf_range_fact]
ALL TO ([PRIMARY]);
GO
CREATE TABLE fact_sales(date_id int, product_id int, store_id int,
quantity int, unit_price numeric(7,2), other_data char(1000))
ON ps_fact_sales(date_id);
GO
CREATE CLUSTERED INDEX ci ON fact_sales(date_id);
GO
PRINT 'Loading...';
SET NOCOUNT ON;
DECLARE @i int;
SET @i = 1;
WHILE (@i<1000000)
BEGIN
INSERT INTO fact_sales VALUES(20080800 + (@i%30) + 1, @i%10000, @i%200, RAND() - 25, (@i%3) + 1, '');
SET @i += 1;
END;
GO
DECLARE @i int;
SET @i = 1;
WHILE (@i<10000)
BEGIN
INSERT INTO fact_sales VALUES(20080900 + (@i%30) + 1, @i%10000, @i%200, RAND() - 25, (@i%3) + 1, '');
SET @i += 1;
END;
PRINT 'Done.';
GO
-- Two-partition query.
SET STATISTICS XML ON;
GO
SELECT date_id, SUM(quantity*unit_price) AS total_price
FROM fact_sales
WHERE date_id BETWEEN 20080802 AND 20080902
GROUP BY date_id ;
GO
SET STATISTICS XML OFF;
GO
-- Single-partition query.
SET STATISTICS XML ON;
GO
SELECT date_id, SUM(quantity*unit_price) AS total_price
FROM fact_sales
WHERE date_id BETWEEN 20080801 AND 20080831
GROUP BY date_id;
GO
SET STATISTICS XML OFF;
GO
相关内容
反馈
即将发布:在整个 2024 年,我们将逐步淘汰作为内容反馈机制的“GitHub 问题”,并将其取代为新的反馈系统。 有关详细信息,请参阅:https://aka.ms/ContentUserFeedback。
提交和查看相关反馈