針對 SharePoint 中的特定效能需求重新設計企業搜尋拓撲
適用于: 2013 2019 訂閱版本
2013 2019 訂閱版本  Microsoft 365 中的 SharePoint
Microsoft 365 中的 SharePoint
如果遵循在 SharePoint Server 2016 中規劃企業搜尋架構中的指引,但您的搜尋環境不符合特定效能需求,則解決方案是擴充企業搜尋架構的拓撲:
重新設計拓撲 (本文)
實作重新設計的拓撲 (在 SharePoint Server 中管理搜尋拓撲)
您是否熟悉 SharePoint Server 2016 中的搜尋系統元件及其互動方式? 在繼續之前,請閱讀<SharePoint Server 的搜尋架構概觀>和<SharePoint Server 2016 的搜尋架構> (或< SharePoint Server 2013 的搜尋架構>),以熟悉搜尋架構、搜尋元件、搜尋資料庫和搜尋拓撲。
在本文中,將顯示如何重新設計搜尋拓撲以符合特定效能需求的逐步指示:
遵循這些步驟之後,您會知道:
您拓撲所需之每種類型的搜尋元件和搜尋資料庫數目。
在其上部署每個搜尋元件的應用程式伺服器和資料庫伺服器。
每部應用程式伺服器和資料庫伺服器所需的硬體資源。
步驟 1:特定效能需求為何?
請確定您了解特定效能需求的商業需求。 例如,新聞和財務搜尋需要接近即時檢索全新資料,同時訴訟支援服務需要擷取只檢索一次的資料批次。 請使用下列一種或多種方法來表示效能需求:
索引項目數目。
搜尋解決方案每秒必須編目的項目數和其延遲。
搜尋解決方案每秒必須提供的查詢數和其延遲。
除了這些效能需求之外,您的環境也可能會有查詢結果關聯性以及要做為備援之搜尋拓撲的需求。 有時,您不會有特定效能需求,但識別搜尋架構中可能會影響效能的瓶頸。 我們也會涵蓋該內容。
步驟 2:應該擴充哪些搜尋元件?
若要提供較高的效能或是移除瓶頸,您可以新增更多的搜尋元件來執行工作,也可以將更多資源新增至裝載搜尋元件的伺服器。 新增更多搜尋元件稱為擴充,而將更多資源新增至伺服器則稱為垂直擴充。 要擴充的搜尋元件或要垂直擴充的伺服器,取決於要改善的效能量值或要移除的瓶頸。 以下為一些範例:
如果環境需要更高的查詢率,而用於檢索的 CPU 資源是瓶頸,請將另一個索引複本新增至索引的每個分割區。 這可讓搜尋平行提供更多查詢。
如果用於處理編目內容的 CPU 資源是瓶頸,請擴充內容處理元件數目。 您也可以垂直擴充內容處理元件,方法是在具有更多或更快 CPU 的伺服器上執行它們。 任何一種擴充方法都表示有更多 CPU 資源可處理內容。
如果分析元件完成分析的速度不夠快,請垂直擴充裝載分析元件之伺服器的處理器資源、磁碟 IOPS 或網路頻寬。
請注意,我們不支援無限制擴充搜尋元件或資料庫數目。 請查看搜尋限制中的上限,並保持在這些限制內,確保搜尋元件與資料庫之間具有及時和完善通訊。 如果必要,請減少搜尋元件數目來降低搜尋架構容量。
在下列各節中,我們提供要擴充哪些搜尋元件或資料庫以滿足每個需求的指導方針:
如何處理索引中的更多項目
如果索引項目數增加,並且以與之前相同的速率變更索引項目,請擴充這些搜尋元件和資料庫來增加搜尋拓撲容量:
| 搜尋元件或資料庫 | 指導方針 |
|---|---|
| 索引元件 | 每 2,000 萬個1索引項目會使用一個索引分割區。 每個分割區都會包含分割區的一個或多個複本。 所有分割區都必須要有相同數目的複本。 一個索引元件代表一個索引複本。 因此,如果您想要有索引的兩個複本,則索引分割區數目需要是索引元件的索引分割區數目的兩倍。 例如,具有 8,000 萬個2項目的備援索引需要四個分割區。 針對每個分割區使用兩個複本時,八個索引元件會代表四個分割區。 |
| 編目資料庫 | 內容主體中每 2,000 萬個項目會使用一個編目資料庫。 例如,具有 1 億個項目的索引需要五個編目資料庫。 如果增加的索引項目數表示會有較高的編目率,則您也需要更多 IOPS 資源,才能服務編目資料庫。 如果您的編目率是一秒一份文件,則編目資料庫需要大約 10 個 IOPS。 |
| 連結資料庫 | 內容主體中每 6,000 萬個項目會使用一個連結資料庫。 例如,具有 1 億個項目的索引需要兩個連結資料庫。 如果新增的內容表示會有較高的編目率,則您可能需要更多 IOPS 資源,才能服務連結資料庫。 |
| 分析報表資料庫 | 需要的分析報表資料庫數目取決於搜尋環境使用分析的方式和頻率。 分析效能開始減少時,一般會新增分析報表資料庫。 例如,啟動資料庫的晚間更新而需要更多時間時。 如果資料庫的大小達到 250 GB 或共 2,000 萬個資料列,或者每天的檢視數目達到 500,000 個唯一項目,則可能發生此情況。 |
具有SharePoint Server 2013 或 SharePoint Server 2016 的 1 千萬個專案,其資源少於 500 GB 儲存體、32 GB RAM 和八個 CPU 核心。
SharePointServer 2013 有 24000 萬個專案,或執行 SharePoint Server 2016 的專案,其資源少於 500 GB 儲存體、32 GB RAM 和八個 CPU 核心。
如何增加結果的擷取率和新鮮度
有一些狀況可能需要增加擷取率。 其中一個範例是如果您的環境需要極新鮮的結果而且內容量接近搜尋架構的項目上限,或內容頻繁地變更。 如果使用者用來封存小組網站上的檔案,但現在他們在處理檔案時將其檔案儲存在 OneDrive 上,內容可能會經常變更。 搜尋會檢索人員對其檔案進行的所有變更。
這有助於了解哪些因素影響搜尋可以多快擷取項目:
搜尋可以多快編目項目。 這取決於:
編目元件與內容來源之間的連線速度。
要編目之項目的類型和平均大小。
裝載編目資料庫之 SQL 伺服器的效能。
編目元件所具有的 CPU 和記憶體資源數量。
每個項目在檢索之前需要進行多少內容處理。
索引有多少分割區。 更多的分割區可讓搜尋分散檢索的負載。
以下是作法:
Check the freshness of the results in your farm by looking at the age distribution of the crawled items. In the SharePoint Central Administration website, go to Crawl Health Reports and select Crawl Freshness. What age distribution that's acceptable for your farm depends on your business requirements. Here's an example: If the Crawl Freshness page shows that it takes four hours to index 90% of the content, but your requirement is 30 minutes, then increase the ingestion rate.
在 [編目新鮮度] 頁面上,識別結果在該天的哪些期間不夠新鮮。
遵循指導方針來增加這些時段中的擷取速度。
| 指導方針 |
|---|
| 改善特定內容來源的新鮮度 |
| 增加用於編目的處理資源 |
| 增加編目資料庫的處理資源 |
| 增加內容處理的處理和記憶體資源 |
| 增加索引分割區數目 |
改善特定內容來源的新鮮度
檢查編目排程,以及識別搜尋在新鮮度不足的時段進行編目的內容來源。 如果特定內容來源的新鮮度不足,請考慮下列各項:
增加裝載編目元件的伺服器與該內容來源之間的連線速度。 即編目率,會從內容來源下載項目,並將項目傳遞給需要編目元件之網路頻寬的內容處理元件。
如果內容來源是 SharePoint,則該伺服器陣列可能需要更多且專用的編目目標。 請閱讀管理編目負載 (SharePoint 2010) 中的編目目標。
改善內容資料庫的效能。 了解 SharePoint Server 伺服器陣列中 SQL Server 的最佳作法中的作法。
增加用於編目的處理資源
如果編目元件經常使用 100% 的處理器資源,請考慮新增另一個編目元件或將更多處理器資源新增至裝載編目元件的伺服器。 即編目率、連結探索,以及需要處理器資源之編目的管理。 在搜尋架構 (例如 that Microsoft 評估過的小型和中型樣本搜尋架構) 中使用兩個編目元件時,編目一般會夠快。 搜尋架構 (例如大型和超大型樣本) 可能需要兩個以上的編目元件。
增加編目資料庫的處理資源
檢查裝載編目資料庫之 SQL 伺服器的資源是否足夠。 請閱讀 SharePoint Server 伺服器陣列中 SQL Server 的最佳作法中的作法。
如果所有編目資料庫使用許多處理器資源,請考慮將更多處理器資源新增至裝載資料庫的 SQL 伺服器,或新增編目資料庫數目與現有 SQL 伺服器的編目資料庫數目相同的另一部 SQL 伺服器。 例如,如果您有兩部各有三個編目資料庫的 SQL 伺服器,則請新增另一部具有三個編目資料庫的 SQL 伺服器。
If only one or a few crawl databases use a lot of processor resources, this means that the load is uneven across the crawl databases. Consider rebalancing the content across all crawl databases. Note that during rebalancing search pauses crawling, so results are less fresh while rebalancing and until crawling has caught up with the changes that took place during the pause. You trigger rebalancing with the Balance button on the Databases page. In Search Administration, go to Crawl Log and select Databases.
增加內容處理的處理和記憶體資源
如果內容處理元件使用接近 100% 的 CPU 資源,請考慮新增更多內容處理元件,或將更多 CPU 資源新增至裝載內容處理元件的伺服器。
如果您注意到記憶體經常重新啟動,請考慮增加裝載內容處理元件之伺服器上的記憶體數量。 一個 CPU 核心有 2 GB 的工作記憶體是不錯的經驗法則。
增加索引分割區數目
Check the content processing activity. You find this by going to Search Administration, selecting Crawl Health Report and then selecting Content Processing Activity. If indexing is the activity that takes most time, consider dividing the index into more partitions. More index partitions lets search spread the load of indexing.
如果您在執行中安裝上新增更多分割區,則索引會重新分割它自己。 重新分割索引可能需要數個小時或數天。 需要多長的時間取決於伺服器陣列在重新分割開始時的狀態。
如何減少查詢延遲以及增加查詢輸送量
搜尋每秒可以服務的查詢數稱為查詢輸送量。 查詢輸送量取決於搜尋用來處理查詢的時間,以及查詢因處理資源無法使用而等待的任何時間。 處理和等待時間的總和稱為查詢延遲。 減少查詢延遲會增加查詢輸送量。 若要減少查詢延遲,請遵循其中一個或兩個指導方針:
| 指導方針 |
|---|
| 減少查詢的處理時間 |
| 減少查詢的等待時間 |
減少查詢的處理時間
請考慮將更多分割區新增至索引。 更多分割區表示每個分割區中有更少項目。 更少項目表示每個分割區可以回應查詢的速度更快。 但是太多分割區不夠好。 因為查詢處理元件必須合併來自每個分割區的回應以產生查詢的答案,所以索引有更多分割區時,合併會需要更多時間。 所有分割區都必須要有相同數目的複本。
在執行中安裝上新增更多分割區時,索引會重新分割它自己。 重新分割索引可能需要數個小時或數天。 需要多長的時間取決於伺服器陣列在重新分割開始時的狀態。
減少查詢的等待時間
請考慮下列動作:
新增索引的更多複本。 新增更多複本時,搜尋會將查詢分佈到複本,並平行處理它們。 一個索引元件代表一個索引複本。 所有分割區都必須要有相同數目的複本,因此將一個索引元件新增至索引的每個分割區。 將索引元件以複本形式新增至執行中安裝上的現有分割區時,搜尋會自動將索引分割區中的資料植入新複本中。 在新複本作業之前,這可能需要數個小時。
將更多記憶體新增至裝載索引元件的伺服器。
在裝載索引元件的伺服器上,針對索引,切換至更快的儲存體 (例如固態硬碟 (SSD))。
將更多處理器資源新增至裝載索引元件的伺服器。 然後,元件每秒會處理更多查詢。 例如,如果伺服器有 2 GHz 的 CPU,則一個核心可以處理:
每秒 5 個查詢 (索引中有 100 萬個項目時)。
每秒 2 個查詢 (索引中有 500 萬個項目時)。
每秒 1 個查詢 (索引中有 1,000 萬個項目時)。
將更多處理器資源新增至裝載查詢處理元件的伺服器。 然後,元件每秒會處理更多查詢,特別是查詢不常用且複雜時。 即需要查詢處理元件之處理器資源的查詢率和查詢轉換數目。 查詢處理元件一般每秒每 4 個查詢需要一個 CPU 核心。
如何減少分析處理時間
分析處理會在每個晚上進行。 分析處理元件會將中繼資料儲存至裝載元件的伺服器,並將分析結果儲存至分析報表資料庫。 如果錯誤阻礙分析處理,則這不會影響文件編目或回答查詢。 但是查詢結果不會有最佳相關性。
請考慮下列動作:
如果您的環境需要查詢結果的最佳相關性,而分析處理的速度不夠快無法滿足此要求,請新增更多磁碟 (主軸) 或更快的磁碟。
如果分析處理所花的時間高於平常,請新增分析報表資料庫。 如果資料庫的大小達到 250 GB 或共 2,000 萬個資料列,或者每天的檢視數目達到 500,000 個唯一項目,則可能會看到這類增加。
如果分析處理需要 24 個小時才能完成,請新增更多分析處理元件,或將更多處理器資源新增至裝載分析處理元件的伺服器。 即索引中的項目數,以及網站上需要處理器資源的活動。
如果分析處理從未完成,或您收到裝載分析元件之伺服器上磁碟的狀況提醒,請將更多磁碟空間新增至伺服器。 若要讓分析元件更快速地處理更大量的中繼資料,請考慮將更多分析處理元件或更多處理器資源新增至裝載分析處理元件的伺服器。
如何將搜尋元件和資料庫設為備援
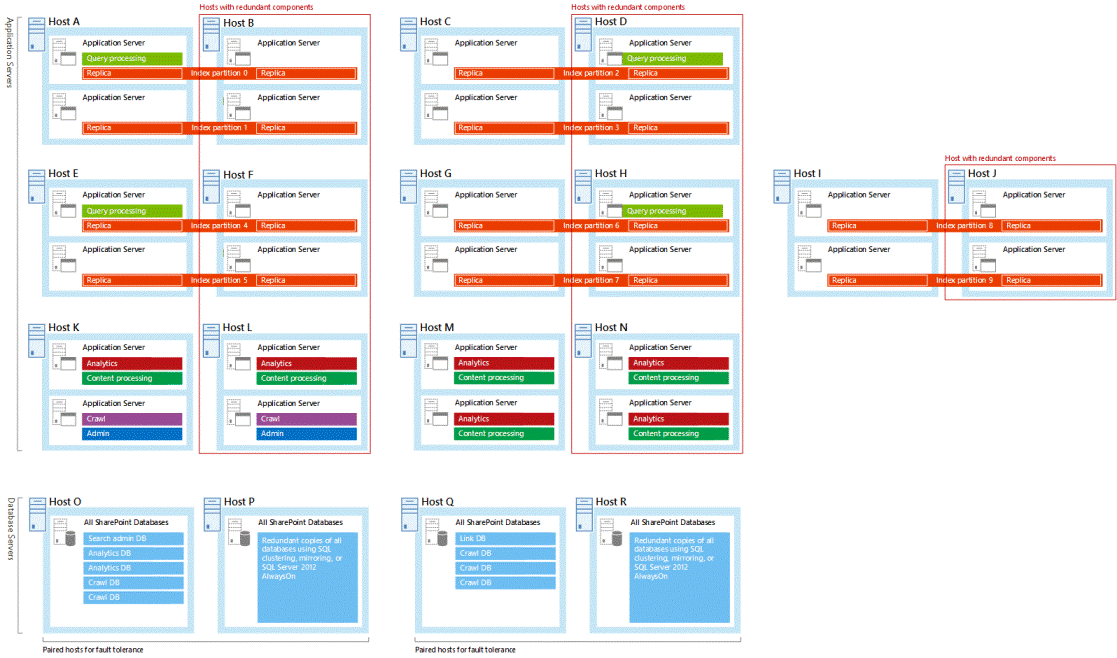
將備援的搜尋元件與資料庫裝載於不同容錯網域時,搜尋架構就可支援高可用性。 建議您設計具有備援搜尋資料庫和元件的搜尋拓撲。 因為 Microsoft 測試過的所有樣本搜尋架構都具有備援搜尋元件和資料庫,所以處理專屬拓撲時,可能會發現學習這些範例十分有用 (請參閱 SharePoint 2016 的企業搜尋架構)。
請遵循下列指導方針:
| 指導方針 |
|---|
| 將索引設為備援 |
| 將編目、內容處理、查詢處理、分析處理和搜尋管理元件設為備援 |
| 將搜尋資料庫設為備援 |
將索引設為備援
如果索引的索引分割區有兩個以上的索引複本,則索引為備援。 如果裝載索引複本的伺服器失敗,則這可能會減少效能,但是搜尋還是可以服務查詢和索引項目。 但是,如果環境隨時都需要相同的效能,則搜尋需要更多備援索引元件。 例如:您已設計每個分割區有兩個複本的搜尋拓撲來減少查詢的等待時間,而且您的環境隨時都需要較短的等待時間來進行查詢。 請增加每個分割區的索引複本數目。
所有分割區都必須要有相同數目的複本。 一個索引元件代表一個索引複本。 因此,如果您想要有索引的兩個複本,則索引分割區數目需要是索引元件的索引分割區數目的兩倍。 例如,若使用 SharePoint Server 2016,具有 8,000 萬個項目的備援索引需要四個分割區。 針對每個分割區使用兩個複本時,八個索引元件會代表四個分割區。
如果您將索引元件以複本形式新增至執行中安裝上的現有分割區,搜尋會自動將索引分割區中的資料植入新複本中。 在新複本作業之前,這可能需要數個小時。
將編目、內容處理、查詢處理、分析處理和搜尋管理元件設為備援
我們會使用編目元件做為範例。 如果您需要使用其中一部裝載編目元件的伺服器進行維護,這可能會減少結果的新鮮度,但是搜尋還是可以編目所有內容。 但是,如果環境隨時都需要相同的結果新鮮度,則搜尋需要更多備援編目元件。 例如:您已設計具有三個編目元件的搜尋拓撲,而且想要相同的結果新鮮度,即使兩部編目元件伺服器失敗也是一樣。 請新增兩個以上的編目元件。
搜尋管理元件是此原則的例外。 一個搜尋管理元件就有任何大小搜尋拓撲的足夠容量。 因此,兩個搜尋管理元件就足以進行備援。
內容處理元件會平衡彼此的負載,因此,備援內容處理元件會增加處理項目的容量。
將搜尋資料庫設為備援
若要將搜尋資料庫設為備援,請使用 SQL Server 所提供的高可用性替代方式 (請參閱為 SharePoint Server 打造高可用性架構和策略)。
步驟 3:選擇以實體或虛擬的方式執行伺服器
一開始規劃搜尋架構時,您決定使用實體伺服器或虛擬機器,或是混合使用兩者。 請考慮該決策是否仍然有效。 如果您現在有更多搜尋元件,則可能會想要使用虛擬機器更輕鬆地管理架構。 例如,取代錯誤虛擬機器會比取代實體機器容易。 另請注意,雖然虛擬環境較容易管理,但其效能層級有時可能會稍低於實體環境。 實體伺服器在同一部伺服器上可以代管的搜尋元件數量,比虛擬伺服器更多。 您可以在Overview of farm virtualization and architectures for SharePoint 2013中發現有效指引。
步驟 4:哪部伺服器要裝載哪個搜尋元件或資料庫?
現在,您已重新設計搜尋拓撲,下一個步驟是將搜尋和資料庫元件指派給實體或虛擬伺服器。 沒有一種最佳的方式可以將搜尋元件指派給實體伺服器或虛擬機器,但是我們為您提供指導方針:
一部伺服器一種搜尋元件類型
每部實體伺服器或虛擬機器都只能裝載每種類型的一個搜尋元件。 索引元件是一個例外。 實體伺服器或虛擬機器最多可以裝載四個索引元件。 您可以在搜尋限制中閱讀這些限制。
區分大量處理與即時元件
請避免在相同實體伺服器或虛擬機器上混合使用大量處理和即時處理搜尋元件。 編目、內容處理和分析處理元件會執行大量處理。 索引和查詢處理元件會執行即時處理。
不要混合使用競爭搜尋元件
如果元件將競爭相同的資源,則請避免在實體伺服器或機器上混合使用搜尋元件。 下表說明每個元件所需的相對資源數量。
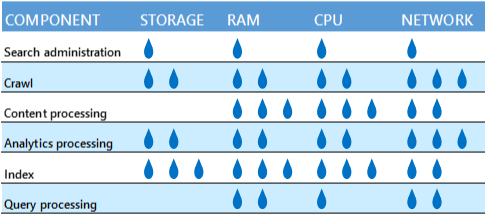
例如,可能不適合將編目和分析處理元件放在相同的伺服器上,因為它們都使用許多網路頻寬。 但是,如果實體伺服器或虛擬機器有足夠的網路容量,則元件不會競爭。
另一個範例是 Microsoft 評估過的超大型搜尋架構樣本。 我們已在此將編目和搜尋管理元件放在不同的虛擬機器上。 這有助於提升編目的速度,因為這兩個元件可能會爭用處理器資源。
使用失敗網域
將備援搜尋元件指派給個別失敗網域中的主機。
步驟 5:我應該要知道哪些硬體需求?
下一個步驟是規劃您需要的硬體:
選擇主機伺服器的硬體資源數量
每個搜尋元件和搜尋資料庫都需要主機伺服器的最少硬體資源數量,才能執行良好。 但是,您有的硬體資源越多,搜尋架構的效能會越好。 因此,數量最好高於最少硬體資源數量。 每個搜尋元件所需的資源取決於工作量,大部分是根據編目率、查詢率和索引項目數目所決定。
例如,在 Windows Server 2008 R2 Service Pack 1 (SP1) 上裝載虛擬機器時,每部虛擬機器無法使用四個以上的 CPU 核心。 使用 Windows Server 2012 或更新版本,您可以每部虛擬機器使用八個以上的 CPU 核心。 然後,您可以每部虛擬機器擴充更多 CPU 核心,而非垂直擴充更多虛擬機器。 請設定裝載相同搜尋元件的伺服器或虛擬機器,且硬體資源相同。 我們將使用索引元件做為範例。 在虛擬機器上裝載索引分割區時,效能最弱的虛擬機器會決定整體搜尋架構的效能。
一般儲存空間
確定每個主機伺服器具有足夠的磁碟空間可以容納 Windows Server 作業系統和 SharePoint Server 2016 程式檔案的基本安裝。 主機伺服器也需要可用的硬碟空間來進行日常作業和頁面檔案的診斷,例如記錄、偵錯及建立記憶體傾印。 通常 80 GB 的磁碟空間即已夠 Windows Server 作業系統和 SharePoint Server 2016 程式檔案使用。
請新增儲存體,供每部資料庫伺服器的 SQL 記錄空間使用。 如果您未設定資料庫伺服器經常備份資料庫,則 SQL 記錄空間會使用許多儲存體。 如需如何規劃 SQL 資料庫的詳細資訊,請參閱規劃及設定儲存設備與 SQL Server 容量 (SharePoint Server)。
分析報表資料庫所需的最少儲存體會不同。 原因是儲存磁碟區取決於使用者如何與 SharePoint Server 2016 互動。 使用者互動頻繁時,通常會儲存更多事件。 請檢查目前搜尋架構用於分析資料庫的儲存體數量,並至少針對已重新設計的拓撲指派此數量。
索引元件的最少資源
這些是伺服器或虛擬機器裝載一個索引元件或裝載一個索引元件和一個查詢處理元件必須要有的最少資源:
| 儲存體 | 記憶體 | 處理器 | 網路頻寬 |
| 500 GB 供索引使用1 | 32 GB1 | 64 位元,最少為 8 核心1、2. | 2 Gbps |
1使用 SharePoint Server 2013 時,資源量下限為 500 GB 儲存體、16 GB RAM 和四個 CPU 核心。
2若使用 SharePoint Server 2016,您可以使用 16 GB 的 RAM 和四個 CPU 核心,但每個索引元件最多可以保留 1,000 萬個項目 (而不是 2,000 萬個項目)。
分析處理元件的最少資源
這些是伺服器或虛擬機器裝載一個分析處理元件必須要有的最少資源:
| 儲存體 | 記憶體 | 處理器 | 網路頻寬 |
| 300 GB 供本機處理分析使用 | 8 GB | 64 位元,最少使用 4 個核心,但建議使用 8 個核心。 | 2 Gbps |
如果伺服器裝載一個分析處理元件以及一個或多個大量處理元件,請將記憶體增加為 16 GB。
編目、內容處理、查詢處理和搜尋管理元件的最少資源
這些是伺服器或虛擬機器裝載下列其中一個元件必須要有的最少資源:
| 儲存體 | 記憶體 | 處理器 | 網路頻寬 |
| 不需要 | 8 GB | 64 位元,最少使用 4 個核心,但建議使用 8 個核心。 | 2 Gbps |
如果伺服器裝載上述兩個以上的元件,請將記憶體增加為 16 GB。
查詢處理元件需要良好的網路頻寬。 即索引分割區數目以及需要網路頻寬的查詢和結果大小。 例如,針對裝載查詢處理元件的伺服器或虛擬機器,每個查詢處理元件每秒 20 個查詢 (20 QPS/QPC) 以及具有 20 個索引分割區的索引會導致 200 Mbps 連入流量以及 100 Mbps 連出流量。
搜尋資料庫的最少資源
這些是伺服器或虛擬機器裝載一或多個搜尋資料庫必須要有的最少資源:
| 儲存體 | 記憶體 | 處理器 | 網路頻寬 |
| 分析報表資料庫所需的儲存體會因下列項目而不同:搜尋環境使用分析的方式和頻率。 使用分析報表資料庫的目前儲存體數量做為指導方針。 | 小型部署需要 8 GB。 16 GB (中型部署) |
64 位元,4 核心。 | 2 Gbps |
規劃儲存效能
儲存空間的速度會影響搜尋效能。 請確定您的儲存空間速度足以處理來自搜尋元件和資料庫的流量。 磁碟速度是以每秒 I/O 作業數 (IOPS) 來測量。
您決定將搜尋元件資料與作業系統資料分散在儲存體中的方式,會影響搜尋效能。 您不妨:
將 Windows Server 作業系統檔案、SharePoint Server 2016 程式檔案和診斷記錄分割到三個具有正常效能的個別儲存磁碟區或分割區。
將搜尋元件資料另外儲存在一個高效能的儲存磁碟區或分割區。 針對索引元件,此儲存體也必須要有高效能。
注意事項
[!附註] 在主機上安裝 SharePoint Server 2016 時,您可以設定搜尋元件資料的自訂位置。 主機上需要儲存資料的任何搜尋元件都會將它儲存在此位置中。 稍後,若要變更此位置,您必須重新安裝 SharePoint Server 2016。
選擇儲存體類型
如需儲存架構和磁碟類型的詳細資訊,請參閱規劃及設定儲存設備與 SQL Server 容量 (SharePoint Server 2016)。 裝載索引、分析處理與搜尋管理元件 (或搜尋資料庫) 的伺服器所需要的儲存空間,必須可以維持低延遲,同時提供足夠每秒 I/O 作業數 (IOPS)。 下列各表顯示這每個搜尋元件和資料庫需要多少 IOPS。
如果您部署共用儲存設備 (例如 SAN/NAS),一個搜尋元件的尖峰磁碟負載通常會跟其他搜尋元件的尖峰磁碟負載同時發生。 若要得到搜尋作業需要從共用儲存設備得到的 IOPS 數,您需要將這每個元件的 IOPS 相加。
搜尋元件 IOPS 需求
| 元件名稱 | 元件詳細資料 | IOPS 需求 | 使用個別儲存磁碟區/磁碟分割 |
|---|---|---|---|
| 索引元件 | 合併索引及處理和回應查詢時使用儲存設備。 | 300 IOPS 用於 64 KB 隨機讀取。 100 IOPS 用於 256 KB 隨機寫入。 200 MB/s 用於循序讀取。 200 MB/s 用於循序寫入。 |
是 |
| 分析元件 | 在本機以大量處理方式分析資料。 | 否 | 是 |
| 編目元件 | 在將下載的內容傳送至內容處理元件之前,先將該內容儲存到本機。 儲存空間受限於網路頻寬。 | 否 | 是 |
搜尋資料庫 IOPS 需求
| 資料庫名稱 | IOPS 需求 | I/O 子系統的一般負載。 |
|---|---|---|
| 編目資料庫 | 中至高 IOPS | 每秒每文件10 IOPS (DPS) 編目率。 |
| 連結資料庫 | 中 IOPS | 搜尋索引中每 100 萬個項目 10 IOPS。 |
| 搜尋管理資料庫 | 低 IOPS | 不適用。 |
| 分析報表資料庫 | 中 IOPS | 不適用。 |
選擇您的搜尋架構如何支援高可用性
如果您不熟悉高可用性策格,則以下文章可協助您開始進行:為 SharePoint Server 打造高可用性架構和策略。 在個別錯誤網域上裝載備援搜尋元件和資料庫時,伺服器陣列的其中一部分中斷不會阻礙整個服務。 但是,因為搜尋元件無法再共用負載,所以搜尋效能會下降。 若要減少遺失單一伺服器的機會,最好改善本機備援。 針對搜尋架構中的每部主機伺服器:
在每部伺服器上使用 RAID 儲存體。
在每部伺服器上安裝多個備援網路連線。
針對每部伺服器,安裝多個配有獨立電線或不斷電供應系統 (UPS) 的備援電源供應器。
所有範例搜尋架構都會在獨立伺服器上裝載備援搜尋元件。 在範例搜尋架構中,每個主機配對中最右邊的主機都是備援。 以下是具有所述備援主機的大型搜尋架構: